论文地址:https://arxiv.org/abs/2407.08223
RAG 将 LLM 的生成能力与外部知识源相结合,以提供更准确和最新的响应。最近的 RAG 进展侧重于通过迭代 LLM 完善或通过 LLM 的额外指令调整获得自我批判能力来改进检索结果。在这项工作中,作者介绍了 SPECULATIVE RAG,一种利用较大、通用 LLM 高效验证由较小、经过提炼的专业 LLM 并行生成的多个 RAG 草案的框架。每个草稿都是从检索到的文件中的一个不同子集生成的,从而为证据提供了不同的视角,同时减少了每个草稿的输入 tokens。这种方法增强了对每个子集的理解,并减轻了 long context 中潜在的立场偏差。该方法将起草工作委托给较小的专家 LM,由较大的通用 LM 对草稿进行一次验证,从而加快了 RAG 的速度。
广泛的实验证明,SPECULATIVE RAG 在 TriviaQA、MuSiQue、PubHealth 和 ARC-Challenge 基准测试中实现了最先进的性能,同时降低了延迟。与 PubHealth 上的传统 RAG 系统相比,它显著提高了 12.97% 的准确率,同时减少了 51% 的延迟。
方法介绍
在知识密集型任务中,每个条目都可以表示为 (Q, D, A),其中 Q 是一个需要额外知识的问题或语句; D = { d 1 , ... , d n } D = \{d_1, \ldots, d_n\} D={d1,...,dn} 是一组从数据库中检索到的 n 个文档;A 是预期答案。RAG 系统的目标是根据检索到的辅助文档提供的上下文,生成包含预期答案的流畅回复,或从提供的选项中选出预期答案。
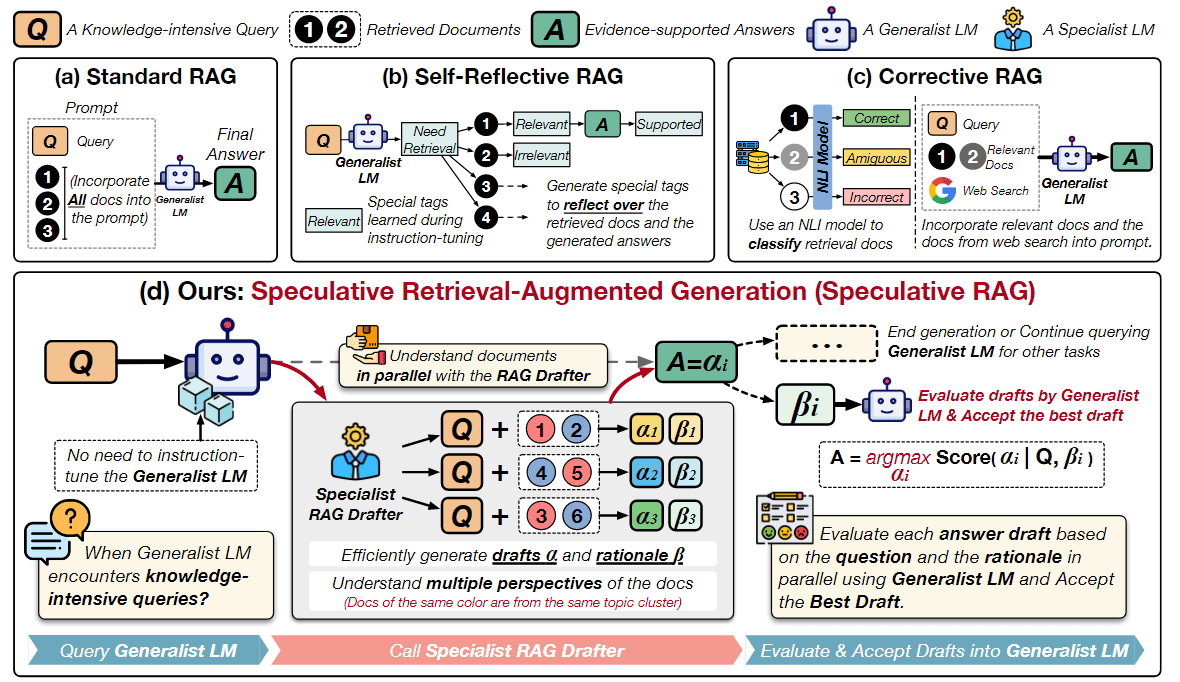
图 1:不同 RAG 方法的说明。给定一个知识密集型查询 Q 和检索到的文档,(a) 标准 RAG 将所有文档都纳入提示,从而增加了输入长度并减慢了推理速度;(b) Self-Reflective RAG(Asai 等人,2023 年)需要对通用语言模型(LM)进行专门的指令调整,以生成用于自反思的特定 token;© Corrective RAG(Yan 等人,2024 年)采用外部检索评估器来改进文档质量,只关注上下文信息,而不增强推理能力;(d) 相比之下,SPECULATIVE RAG 利用较大的通用 LM 来有效验证由较小的专用 LM 并行生成的多个 RAG 草案。每个草案都是从检索到的文档的一个不同子集生成的,从而为证据提供了不同的视角,同时最大限度地减少了每个草案的输入 tokens。
如图 1 所示,作者引入了推测性检索增强生成(SPECULATIVE RAG),目标是在不影响处理速度的情况下,增强 LLM 对检索文档的推理能力。提出了一种"分而治之"的方法,而不是依靠强行调整参数或指令调整整个 LM 来处理知识密集型任务。作者利用一个较小的专业 LM(RAG drafter),根据检索结果快速生成多个答案草案。然后,一个较大的通用 LM(RAG verifier)会对这些草稿进行评估,根据其合理性选择最佳草稿,并将其整合到生成结果中。
具体来说,如算法 1 所示。

- 首先,将检索到的文档按照它们与所提问题的关系进行聚类,其中每个聚类代表检索结果中的一个视角(第 2 行)。
- 然后,从每个聚类中抽取一个文档到一个子集中,这样子集中的文档就涵盖了检索结果中的多个视角。目标是尽量减少冗余并增加文档的多样性(第 5 至第 8 行)。将一个子集记为 δ ⊂ D,它包含了检索结果中具有不同内容和多个视角的检索文档。
- 接着,将每个子集 δ 分配给带有所提问题 Q 的 RAG drafter端点 M D r a f t e r M_{Drafter} MDrafter,以并行生成答案草稿 α 和理由说明 β(第 12 行)。RAG drafter 经过指令调整,可成为理解检索文档的专家,并生成忠实于输入文档的理由。它比通用 LM 更小,其并行处理进一步确保了高效率。对于 M D r a f t e r M_{Drafter} MDrafter 中的每一对草案-理由(α, β),都会根据问题 Q 和相应的理由 β,用通用 LM M V e r i f i e r M_{Verifier} MVerifier 计算置信度得分(第 13 行)。值得一提的是, M V e r i f i e r M_{Verifier} MVerifier 不需要进行指令调整,因为我们利用的是其在预训练中已经学到的语言建模能力。同时, M V e r i f i e r M_{Verifier} MVerifier 可以根据 M D r a f t e r M_{Drafter} MDrafter 提供的信息理由验证草稿,而不是处理繁琐或可能多余的检索文档。
- 最后,选择置信度最高的答案草稿作为最终答案,并将其整合到通用 LM 的生成结果中(第 15 行)。
模块:专业 RAG Drafter
作者使用较小的专业 LM( M D r a f t e r M_{Drafter} MDrafter)来理解检索到的文档。通过训练 M D r a f t e r M_{Drafter} MDrafter生成答案草稿和理由,来更好地理解上下文文档。在解决知识密集型任务时,可以作为通用 LM 的 RAG 模块。

图 4:在 Gemini-Ultra 上生成理由 E 的 prompt。
我们可以用强 LLM 为每个三元组(查询,响应,文档)生成合理的理由 E。然后,使用标准的语言建模目标训练 M D r a f t e r M_{Drafter} MDrafter,让 M D r a f t e r M_{Drafter} MDrafter 可以学习在查询和相关文档的基础上生成有理有据的响应和理由。
多视角抽样和答案生成
对于每个知识密集型问题,以提出的问题作为检索查询,从数据库中检索出一组文档。由于查询本身的模糊性,这些文档可能包含不同的内容。为了尽量减少冗余并提高用于生成答案草案的文档子集的多样性,作者采用了多视角抽样策略。
- 首先,使用指令感知嵌入模型(Peng 等人,2024 年)和 K-Means 聚类算法将文档聚类为几个主题。
- 然后,从每个聚类中抽取一份文档到文档子集中,因此每个子集包含 k(聚类簇的个数)份不同内容的文档。总共构建了 m 个子集。

图 5:RAG drafter 生成答案的 prompt。
对 m 个文档自己运行 RAG drafter 并行推理,生成相应的答案草稿。将每个文档自己纳入 prompt,查询 RAG drafter 获得响应。我们会得到 m 份答案草稿(基于检索结果中的多个视角)作为候选答案。除了答案草稿 α \alpha α外,还有理由说明 β \beta β。作者将条件生成概率记为 p D r a f t , j = P ( β j ∣ Q , d j 1 , ... , d j k ) + P ( α j ∣ Q , d j 1 , ... , d j k , β j ) p_{Draft, j} = P(\beta_j | Q, d_{j1}, \ldots, d_{jk}) + P(\alpha_j | Q, d_{j1}, \ldots, d_{jk}, \beta_j) pDraft,j=P(βj∣Q,dj1,...,djk)+P(αj∣Q,dj1,...,djk,βj),衡量了生成理由的可靠性和生成答案草稿的可信度。
模块:通用 RAG Verifier
从 RAG drafter 生成答案草稿和理由后,通过通用 LM M V e r f i e r M_{Verfier} MVerfier(可以是任意现成的预训练 LM)对其进行评估,过滤掉可靠性较低的草稿并选出最佳答案。因为只考虑答案草稿-理由对 ( α , β ) (\alpha, \beta) (α,β),跳过了繁琐冗余的检索结果,从而提升了处理效率。
评估方式
- self-contain 分数 :通过答案草稿-理由对的条件概率来计算自我一致性分数,即 p s e l f − c o n t a i n = P ( α , β ∣ Q ) p_{self-contain} = P(\alpha, \beta | Q) pself−contain=P(α,β∣Q)。自我一致性分数可以评估答案草稿和理由在问题的上下文中是否一致和流畅。
- self-reflection 分数 :此外,作者还加入 self-reflection 语句 R,以提示 M V e r f i e r M_{Verfier} MVerfier 评估答案草稿的可靠性(例如,"您认为理由是否支持答案,是或否?"),将 self-reflection 分数定义为 p s e l f − r e f l e c t i o n = P ( " Y e s " ∣ Q , α , β , R ) p_{self-reflection} = P("Yes" | Q, \alpha, \beta, R) pself−reflection=P("Yes"∣Q,α,β,R)。
我们可以在 M V e r i f i e r M_{Verifier} MVerifier 的一次前向传递中高效计算自我一致性和 self-reflection 分数。给定问题 Q 和答案草稿-理由对 ( α , β ) (\alpha, \beta) (α,β),构建一个 prompt Q , α , β , R , " Y e s " Q, \\alpha, \\beta, R, "Yes" Q,α,β,R,"Yes"。用 M V e r i f i e r M_{Verifier} MVerifier 对 prompt 进行编码,并根据下图所示的数学公式进行计算。
→ α , β ⏞ ρ S C , R , "Yes" ⏞ ρ S R ⇒ { ρ S S = ∏ t i ∈ α P ( t i ∣ t < i ) ⋅ ∏ t i ∈ β P ( t i ∣ t < i ) ρ S R = ∏ t i ∈ "Yes" P ( t i ∣ t < i ) \xrightarrow{\overbrace{\alpha, \beta}^{\rho_{\mathrm{SC}}}, R, \overbrace{\text { "Yes" }}^{\rho_{\mathrm{SR}}}} \Rightarrow\left\{\begin{array}{l}\rho_{\mathrm{SS}}=\prod_{t_{i} \in \alpha} P\left(t_{i} \mid t_{<i}\right) \cdot \prod_{t_{i} \in \beta} P\left(t_{i} \mid t_{<i}\right) \\ \rho_{\mathrm{SR}}=\prod_{t_{i} \in \text { "Yes" }} P\left(t_{i} \mid t_{<i}\right)\end{array}\right. α,β ρSC,R, "Yes" ρSR ⇒{ρSS=∏ti∈αP(ti∣t<i)⋅∏ti∈βP(ti∣t<i)ρSR=∏ti∈ "Yes" P(ti∣t<i)
最后,得出最终分数 p j = p D r a f t , j ⋅ p S C , j ⋅ p S R , j p_j = p_{Draft, j} \cdot p_{SC, j} \cdot p_{SR, j} pj=pDraft,j⋅pSC,j⋅pSR,j,然后选择最可靠的答案作为问题的最终答案。
相关实验
主要结果
在 TriviaQA、MuSiQue、PubHealth 和 ARC-Challenge 这四个数据集上比较 SPECULATIVE RAG 与标准 RAG 方法,以及更先进的 Self-Refleective RAG 和 Corrective RAG。作者报告了 M D r a f t e r − 7 B M_{Drafter-7B} MDrafter−7B单独使用或与 RAG 校验器(如 M V e r i f i e r − 7 B M_{Verifier-7B} MVerifier−7B、 M V e r i f i e r − 8 x 7 B M_{Verifier-8x7B} MVerifier−8x7B)搭配使用时的性能。作者同之前的工作,将准确性作为性能指标。
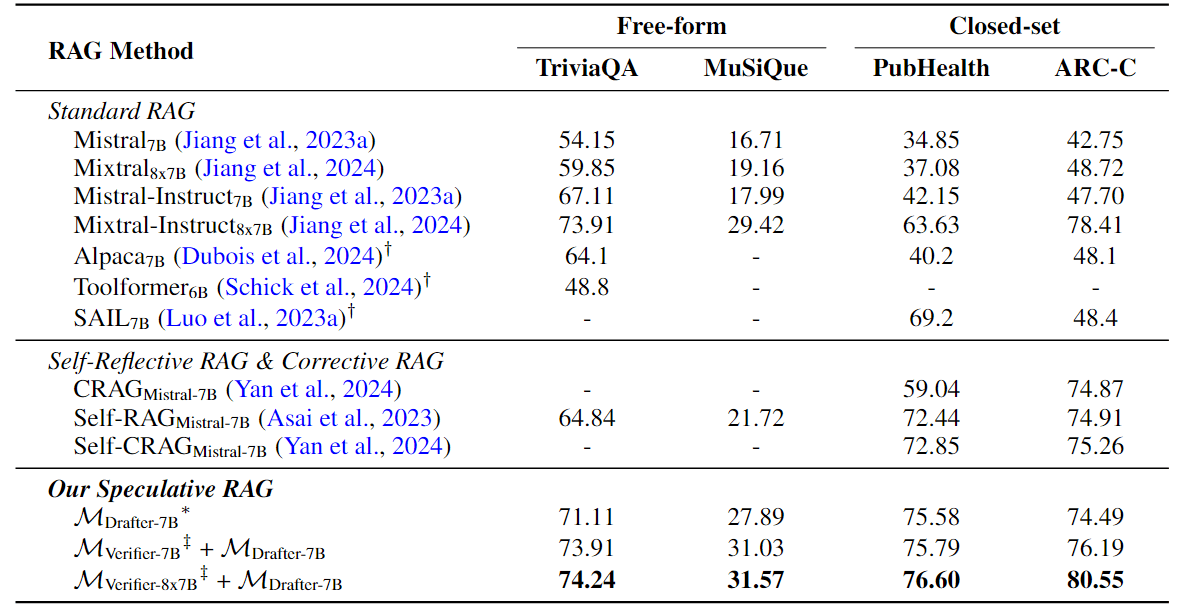
表 1: TriviaQA、MuSiQue、PubHealth 和 ARCChallenge (ARC-C) 的检索增强生成结果。(使用 RAG 草稿生成概率 ρ D r a f t ρ_{Draft} ρDraft 作为单独使用时选择草稿的置信度;"†"表示 Asai 等人(2023 年)报告的数字;"-"表示原始论文未报告或不适用的数字;"‡"使用 Mistral7B 或 Mixtral8x7B 作为 RAG 校验器,并将其表示为 M V e r i f i e r − 7 B M_{Verifier-7B} MVerifier−7B 或 M V e r i f i e r − 8 x 7 B M_{Verifier-8x7B} MVerifier−8x7B)。
表 1 显示,在所有四个基准测试中,SPECULATIVE RAG 的性能始终优于所有基线。特别是, M V e r i f i e r − 8 x 7 B M_{Verifier-8x7B} MVerifier−8x7B+ M D r a f t e r − 7 B M_{Drafter-7B} MDrafter−7B 在 TriviaQA 上超过最具竞争力的标准 RAG 模型 Mixtral-Instruct8x7B 0.33%,在 MuSiQue 上超过 2.15%,在 PubHealth 上超过 12.97%,在 ARC-Challenge 上超过 2.14%。在指令调整参数数量相当的情况下, M V e r i f i e r − 7 B M_{Verifier-7B} MVerifier−7B + M D r a f t e r − 7 B M_{Drafter-7B} MDrafter−7B 的表现优于所有 Self-Reflective 和 Corrective RAG 方法,而 M D r a f t e r M_{Drafter} MDrafter 本身在大多数情况下也能超过这些基线。
RAG Drafter 的有效指令调整
指令调整有效地提高了草稿模型的推理能力,此外,当 Mixtral 8x7B 与经过指令调整的 RAG M D r a f t e r − 7 B M_{Drafter-7B} MDrafter−7B 配对时,其性能显著提高,在 TriviaQA 上提高了 14.39%,在 MuSiQue 上提高了 12.41%,在 PubHealth 上提高了 39.52%,在 ARCChallenge 上提高了 31.83%。Mistral7B 也有类似的改进。在 Mistral7B 中,观察到 TriviaQA 提高了 19.76%,MuSiQue 提高了 14.32%,PubHealth 提高了 40.94%,ARC-Challenge 提高了 33.44%。作者将这些改进归功于 RAG drafter 对 SPECULATIVE RAG 中检索文档的卓越推理能力。通过最大限度地减少采样文档中的冗余,RAG drafter 根据检索结果中的不同观点生成了更高质量的答案草案。
延迟分析
作者分析了标准 RAG 和 SPECULATIVE RAG 在 TriviaQA、MuSiQue、PubHealth 和 ARC-Challenge 上的延迟。从每个数据集中随机抽取 100 个示例,并报告每个示例的平均时间成本,如图 2 所示。

图 2:标准 RAG 和 SPECULATIVE RAG 的延迟差异以红色标出(+x%)。TP 表示标准 RAG 运行 Mixtral-Instruct 8x7B 时的张量并行大小。由于检索文档的长度不同,不同数据集的延迟也不同。
为了模拟真实世界的应用场景,在不分批的情况下单独处理示例。作为代表性示例,在 SPECULATIVE RAG 和 Standard RAG 中分别运行了 M V e r i f i e r − 8 x 7 B + M D r a f t e r − 7 B M_{Verifier-8x7B} + M_{Drafter-7B} MVerifier−8x7B+MDrafter−7B 和 Mixtral-Instruct8x7B,因为它们在具有竞争力的基线中表现出了最高的性能(见表 1)。
为 TriviaQA、PubHealth 和 ARC-Challenge 启动了 5 个 M D r a f t e r − 7 B M_{Drafter-7B} MDrafter−7B 端点,用于并行生成答案草稿。由于答案草稿数量较多,作者为 MuSiQue 启动了 10 个端点。使用张量并行技术将 Mixtral-Instruct 8x7B 装入 GPU 内存。在图 2 报告了Mixtral-Instruct 8x7B在张量并行度为4、8、16时的延迟情况。由于张量聚合和通信的开销,增加张量并行度并不能提高效率。相比之下,SPECULATIVE RAG 采用了较小的 RAG drafter 和并行答案草稿生成技术,在所有数据集上始终实现了最低的延迟。特别是,它在 TriviaQA 上将延迟降低了 23.41%,在 MuSiQue 上降低了 17.28%,在 PubHealth 上降低了 51.25%,在 ARC-Challenge 上降低了 26.73%。这凸显了 SPECULATIVE RAG 在保持高性能的同时缩短处理时间的优势。
总结
提出的 SPECULATIVE RAG 将 RAG 任务分解为两个独立的步骤:起草和验证。SPECULATIVE RAG 将繁重的起草工作委托给小型专业 RAG drafter,而验证工作则由大型通用 LM 完成。从不同的文档子集并行生成多个草稿,既能提供高质量的候选答案,又能减少输入 tokens 和位置偏差超过 long context 的潜在风险,从而大幅提高最终输出生成的质量和速度。作者证明了 SPECULATIVE RAG 的有效性,与传统 RAG 系统相比,其准确率提高了 12.97%,延迟时间缩短了 51%。SPECULATIVE RAG 为协作架构通过任务分解提高 RAG 性能的潜力提供了新的启示。