
论文链接:https://arxiv.org/pdf/2407.08737
git链接:https://vader-vid.github.io/
亮点直击:
引入奖励模型梯度对齐方法:VADER通过利用奖励模型的梯度,对多种视频扩散模型进行调整和对齐,包括文本到视频和图像到视频的扩散模型。
广泛使用预训练视觉模型:该方法涵盖了多种预训练视觉模型,以提高对不同任务的适应能力和性能。
内存使用优化技巧:VADER提出了多种技巧,有效改善内存使用效率,使得可以在单个16GB VRAM的GPU上进行训练。
显著改进模型生成质量:定性可视化结果显示,VADER显著改进了基础模型在多种任务上的生成质量和效果。
超越传统对齐方法的性能:与传统方法如DPO或DDPO相比,VADER展示了更高的性能,特别是在未见过的提示上的泛化能力。
目前已经在建立基础视频扩散模型方面取得了显著进展。由于这些模型是使用大规模无监督数据进行训练的,因此将这些模型调整到特定的下游任务变得至关重要。通过监督微调来适应这些模型需要收集视频目标数据集,这是具有挑战性和繁琐的。本文利用预训练的奖励模型,通过对顶尖视觉辨别模型的偏好进行学习,来适应视频扩散模型。这些模型包含关于生成的RGB像素的密集梯度信息,这对于在复杂的搜索空间(如视频)中进行高效学习至关重要。本文展示了从这些奖励模型向视频扩散模型反向传播梯度的结果,可以实现计算和采样的高效对齐。本文展示了在多种奖励模型和视频扩散模型上的结果,表明本文的方法在奖励查询和计算方面比之前无梯度方法能够更高效地学习。
VADER: 通过奖励梯度进行视频扩散
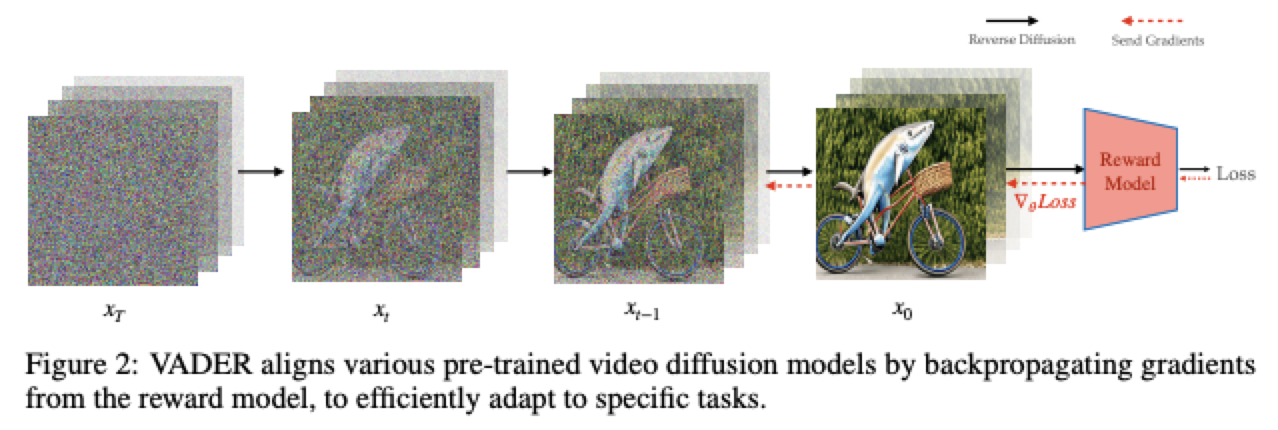
本文的方法,用于将视频扩散模型调整为执行通过奖励函数 R(.) 指定的特定任务。
给定一个视频扩散模型 θ,上下文数据集 ,以及一个奖励函数 R(.),目标是最大化以下目标函数:
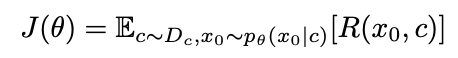
为了在奖励查询数量和计算时间方面高效学习,本文希望利用奖励函数相对于扩散模型权重 θ 的梯度结构。这适用于所有具有可微性质的奖励函数。计算这些可微奖励的梯度 ,并用它来更新扩散模型的权重 θ。梯度由以下给出:
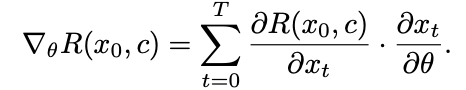
VADER在去噪进度上非常灵活,本文展示了与DDIM和EDM求解器的结果。为了防止过度优化,本文使用截断反向传播,其中梯度仅向后传播K步,其中K < T,T为总扩散时间步数。使用较小的K值还可以减少梯度向后传播的内存负担,使训练更加可行。本文在下面的算法1中提供了完整训练过程的伪代码。接下来,本文讨论用于对齐视频模型的奖励函数类型。

奖励模型: 考虑一个扩散模型,它以条件向量 作为输入,并生成长度为 的视频 ,包含一系列图像 ,对于每个时间步 从 到 。那么要最大化的目标函数如下:
本文使用多种类型的奖励函数来对齐视频扩散模型。以下是本文考虑的不同类型的奖励函数。
图像-文本相似度奖励 扩散模型生成的视频与用户提供的文本相对应。为确保视频与提供的文本对齐,本文可以定义一个奖励,用于衡量生成的视频与提供的文本之间的相似性。为了利用流行的大规模图像-文本模型如CLIP,本文可以采取以下方法。为了使整个视频能够很好地对齐,视频的每个单独帧很可能需要与上下文 c 具有高相似度。假设存在一个图像-上下文相似度模型 ,有:
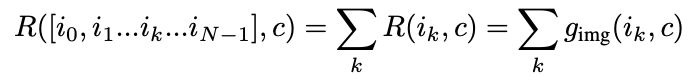
因此,有 ,在图像对齐案例中使用期望的线性性质。本文使用HPS v2和PickScore 奖励模型进行图像-文本对齐的实验。由于上述目标仅涉及单个图像,可能导致预测的图像完全相同或在时间上不一致的情况。然而,根据经验,本文并未发现这种情况发生,大家认为初始的预训练足以在微调过程中实现充分的正则化,以防止这类情况的发生。
视频-文本相似度奖励 与其使用每帧图像相似度模型 ,评估整个视频与文本之间的相似性可能更有益。这将允许模型生成一些帧与上下文不同的视频,从而产生更丰富、更多样化的表现生成。这也允许生成更多运动和移动的视频,这些特征更适合由多帧捕捉。假设存在一个视频-文本相似度模型 ,有 。在本文的实验中,使用VideoMAE在动作分类上进行了微调,作为 ,它可以将输入视频分类为一组动作文本描述之一。本文将目标类文本作为输入提供给文本到视频扩散模型,并使用从VideoMAE预测的地面真实类别概率作为奖励。
图像生成目标 虽然文本相似性是一个优化的强信号,但某些用例可能更适合仅基于生成图像的奖励模型。强大的基于图像的判别模型如对象检测器和深度预测器广泛存在。这些模型利用图像作为输入生成各种有用的图像度量指标,可以作为奖励使用。如果在每个生成帧上获得的奖励都很高,生成的视频很可能与任务更好地对齐。因此,本文在这种情况下定义奖励为每个单独帧上评估的奖励的平均值,即 。
需要注意的是,鉴于生成的帧,这与文本输入 是独立的。因此,有 ,通过期望线性性质得到,其中 是一个判别模型,接受图像作为输入生成度量,可以用来定义奖励。在实验中使用了美学奖励模型和对象检测器奖励模型。
视频生成目标 借助一个接受多个图像帧作为输入的外部模型,可以直接优化生成视频的期望质量。假设存在一个视频度量模型 ,相应的奖励为 。
长时间一致的生成: 在本文的实验中,采用这种表述来实现一个对许多开源视频扩散模型来说非常具有挑战性的特性 - 生成长度更长的剪辑。为了完成这个任务,本文使用了Stable Video Diffusion,这是一个图像到视频的扩散模型。本文通过使其自回归来将Stable Video Diffusion的上下文长度增加了3倍。具体来说,本文将模型生成的最后一帧作为输入,用于生成下一个视频序列。然而,本文发现这种方法效果不佳,因为模型从未针对其自身的生成进行训练,导致分布偏移。为了改善生成效果,本文使用了一个视频度量模型 ,它针对一组帧生成一个关于帧之间预测性的分数。本文将这个模型应用于自回归生成的视频序列,以鼓励这些序列与先前的帧保持一致。以这种方式训练模型能够使视频剪辑在时间和空间上保持连贯性。
减少内存开销: 训练视频扩散模型非常消耗内存,因为内存使用量与生成帧的数量成线性关系。虽然VADER显著提高了微调这些模型的样本效率,但却增加了内存的消耗。这是因为可微奖励是在生成的帧上计算的,而这些帧是通过顺序去噪步骤生成的。
-
常规技巧:为了减少内存使用, 本文使用 LoRA只更新模型参数的子集,此外使用混合精度(mixed precision),将不可训练参数存储为 fp16。在反向传播过程中,为了减少内存使用,使用梯度检查点(gradient checkpointing),对于长时间跨度的任务,将反向计算图的存储从GPU内存转移到CPU内存。
-
截断反向传播:此外,在本文的实验中,仅通过扩散模型进行一步时间步长的反向传播,而不是通过多个时间步长进行反向传播,本文发现这种方法在需要更少内存的同时能够获得竞争力的结果。
-
帧子采样:由于本文考虑的所有视频扩散模型都是潜在扩散模型,本文进一步通过不将所有帧解码为RGB像素来减少内存使用。相反,随机对帧进行子采样,仅对子采样的帧解码并应用损失。
本文在2块A6000显卡(每块48GB VRAM)上进行实验,本文的模型平均需要12小时进行训练。然而,本文的代码库支持在单块16GB VRAM的GPU上进行训练。
结果
这项工作专注于通过一系列针对图像和视频定制的奖励模型,对各种条件视频扩散模型进行微调,包括 VideoCrafter, Open-Sora, Stable Video Diffusion 和 ModelScope。这些奖励模型包括图像美学模型,用于图像文本对齐的 HPSv2 和 PickScore,用于物体移除的 YOLOS,用于动作分类的 VideoMAE,以及用于时序一致性的自监督损失 V-JEPA。本文的实验旨在回答以下问题:
-
VADER在样本效率和计算需求上与无梯度技术(如DDPO或DPO)相比如何?
-
模型在多大程度上能够推广到训练过程中未见的提示?
-
经过人类评估者评判,微调的模型彼此之间如何比较?
-
VADER在各种图像和视频奖励模型上的表现如何?
这个评估框架评估了VADER在从各种输入条件生成高质量、对齐的视频内容方面的效果。
基准方法。 本文将VADER与以下方法进行比较:
-
VideoCrafter, Open-Sora 1.2 和 ModelScope 是当前公开的文本到视频扩散模型,被用作微调和比较的基础模型。
-
Stable Video Diffusion 是当前公开的图像到视频扩散模型,在所有图像到视频空间的实验中,使用它们的基础模型进行微调和比较。
-
DDPO 是一种最近的图像扩散对齐方法,使用策略梯度来调整扩散模型的权重。具体地,它应用了PPO算法到扩散去噪过程中。研究者们扩展了他们的代码来适应视频扩散模型。
-
Diffusion-DPO 扩展了最近在LLM空间中开发的直接偏好优化(DPO)到图像扩散模型。他们表明,直接使用偏好数据来建模似然性可以减少对奖励模型的需求。作者扩展了他们的实现来对齐视频扩散模型,其中使用奖励模型来获得所需的偏好数据。
**奖励模型。**本文使用以下奖励模型来微调视频扩散模型:
-
美学奖励模型:本文使用LAION美学预测器V2,它以图像作为输入并输出其在1-10范围内的美学评分。该模型基于CLIP图像嵌入进行训练,使用包含17.6万张图像评分的数据集,评分从1到10不等,其中评分为10的图像被分类为艺术品。
-
人类偏好奖励模型:本文使用HPSv2和PickScore,它们以图像-文本对作为输入,并预测人类对生成图像的偏好。HPSv2通过对CLIP模型进行微调,使用包含约79.8万个人类偏好排名的数据集,涵盖了43.376万对图像。而PickScore则通过对CLIP模型进行微调,使用了58.4万个人类偏好示例的数据集。这些数据集在领域内属于最广泛的,为增强图像-文本对齐提供了坚实的基础。
-
物体移除奖励模型:本文设计了基于YOLOS的奖励模型,YOLOS是基于Vision Transformer的物体检测模型,训练数据包括11.8万个注释图像。奖励是目标物体类别置信度分数的反数,通过该奖励模型,视频模型学习从视频中移除目标物体类别。
-
视频动作分类奖励模型:虽然以上奖励模型作用于单个图像,作者采用一个奖励模型,将整个视频作为输入。这有助于获取视频生成的时间方面的梯度。具体而言,考虑了VideoMAE,它在Kinetics数据集上进行了动作分类任务的微调。奖励是动作分类器为期望行为预测的概率。
-
时间一致性奖励模型:虽然动作分类模型仅限于固定的动作标签集,但考虑了一个更通用的奖励函数。具体来说,使用自监督的遮蔽预测目标作为奖励函数,以提高时间一致性。本文使用V-JEPA作为奖励模型,奖励是在V-JEPA特征空间中遮蔽自编码损失的负值。
提示数据集。 本文考虑以下一组提示数据集,用于对文本到视频和图像到视频扩散模型进行奖励微调:
-
活动提示(文本):考虑来自DDPO的活动提示。每个提示结构化为"a(n) 动物 活动",使用了包含45种常见动物的集合。每个提示的活动来自三个选项之一:"骑自行车"、"下棋"和"洗碗"。
-
HPSv2动作提示(文本):本文从HPSv2数据集中的一组提示中筛选出了50个提示。筛选这些提示以确保它们包含动作或运动信息。
-
ChatGPT生成的提示(文本):本文提示ChatGPT生成一些生动且创意设计的文本描述,涵盖各种场景,例如书籍放在杯子旁边,动物穿着衣服,以及动物演奏乐器。
-
ImageNet狗类别(图像):对于图像到视频扩散模型,本文考虑ImageNet中拉布拉多犬和马尔济斯犬类别的图像作为提示集。
-
Stable Diffusion图像(图像):这里本文考虑Stable Diffusion在线演示网页中的全部25张图像作为提示数据集。
样本和计算效率
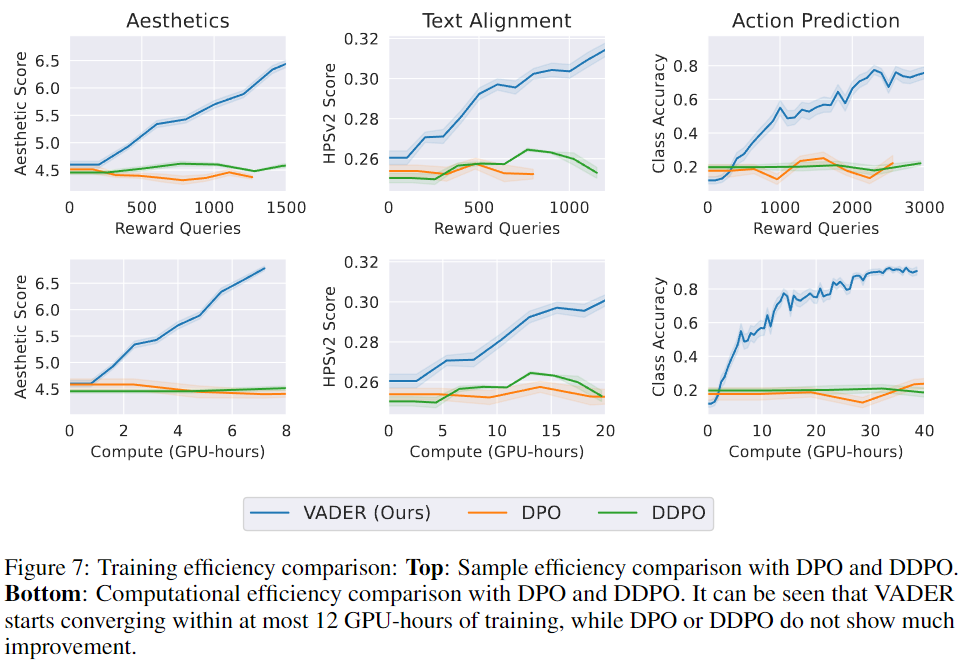
大规模视频扩散模型的训练由少数拥有大量计算资源的实体完成;然而,这些模型的微调却由许多拥有有限计算资源的实体完成。因此,拥有既能提升样本效率又能提升计算效率的微调方法变得至关重要。
在本节中,将比较VADER在样本和计算效率上与其他强化学习方法如DDPO和DPO的表现。在下图7中,可视化了训练过程中的奖励曲线,图中上半部分的x轴是奖励查询次数,下半部分的x轴是GPU小时数。从图中可以看出,与DDPO或DPO相比,VADER在样本和计算效率上显著更高。这主要是因为将来自奖励模型的密集梯度发送到扩散模型的权重中,而基线方法只是反向传播标量反馈。
通用化能力
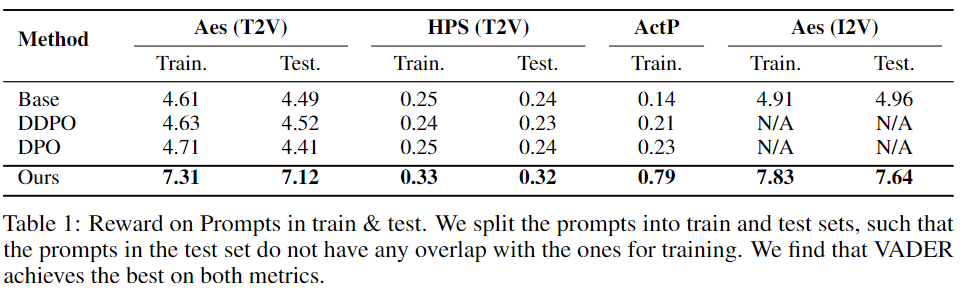
微调的一个期望属性是泛化能力,即在有限提示集上微调的模型能够泛化到未见过的提示上。在本节中,通过多个奖励模型和基准模型广泛评估这一属性。在训练文本到视频(T2V)模型时,在训练集中使用了HPSv2行动提示,而在测试集中使用了活动提示。对于训练图像到视频(I2V)模型,在训练集中使用了拉布拉多犬类别,而马耳他犬类别则形成了本文的测试集。下表1展示了VADER的泛化能力。
人类评估
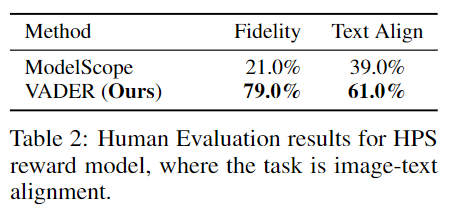
研究者们进行了一项研究,通过Amazon Mechanical Turk评估人类偏好。测试包括VADER和ModelScope之间的并排比较。为了测试从这两种模型生成的视频如何与它们的文本提示对齐,向参与者展示了由VADER和基线方法生成的两个视频,并要求他们选择哪个视频更符合给定的文本。为了评估视频质量,研究者们要求参与者比较以相同提示生成的两个视频,一个来自VADER,另一个来自基线方法,并决定哪个视频的质量更高。每个比较收集了100个回复。下表2中的结果显示,相比基线方法,人们更偏好VADER。
定性可视化
本节将展示VADER生成的视频及其相应的基准模型。将在各种基础模型上,通过所有考虑的奖励函数进行广泛的可视化展示。
HPS奖励模型: 在下图3中,可视化了使用HPSv2.1和美学奖励函数对VideoCrafter进行微调前后的结果,前三行展示了这些结果。在微调前,浣熊没有拿着雪球,狐狸也没有戴帽子,这与文本描述不一致;然而,从VADER生成的视频中不会出现这些不一致之处。此外,如图3的第三行所示,VADER成功地泛化到未见过的提示,狗的爪子看起来不像左侧视频中的人类手那样。类似的改进也可以在使用Open-Sora V1.2和ModelScope生成的视频中观察到,如下图6的第二和第三行所示。


美学奖励模型: 在上图3中,前三行可视化了使用美学奖励函数和HPSv2.1模型组合微调ModelScope前后的结果。此外,还通过美学奖励函数微调了ModelScope,并在上图6的最后一行展示了其生成的视频。观察到,美学微调使得生成的视频更具艺术感。
PickScore模型: 在上图3的最后三行,展示了通过PickScore微调的VideoCrafter生成的视频。VADER显示出比基准模型更好的文本到视频对齐效果。在最后一行,测试了两个模型对在训练时未见过的提示的响应。此外,通过PickScore微调的Open-Sora生成的视频显示在上图6的第一行。
对象移除: 在下图5中,显示了经过使用基于YOLOS的对象移除奖励函数微调后,由VideoCrafter生成的视频。在这个例子中,书籍是要移除的目标对象。这些视频展示了成功将书籍替换为其他物体,比如毯子或面包。

视频动作分类: 在下图8中,展示了ModelScope和VADER的视频生成结果。在这种情况下,使用动作分类目标对VADER进行微调,以符合提示中指定的动作。对于提示中的"一个人在吃甜甜圈",发现VADER使人脸更加明显,并在甜甜圈上添加了彩色的糖珠。之前的生成通常被错误分类为烘烤饼干,这是Kinetics数据集中的另一个动作类别。向甜甜圈添加颜色和糖珠使其与饼干更易于区分,从而获得更高的奖励。

V-JEPA 奖励模型: 在下图9中,展示了通过Stable Video Diffusion(SVD)增加视频长度的结果。为了在SVD上生成长距离视频,使用自回归推理,其中由SVD生成的最后一帧作为条件输入,用于生成下一组图像。进行了三步推理,因此将SVD的上下文长度扩展了三倍。然而,正如在红色边框中可以看到的那样,在进行一步推理后,SVD开始在预测中累积错误。这导致了泰迪熊的变形,或者影响了运动中的火箭。VADER使用V-JEPA目标的掩码编码,以强制生成的视频自一致性。如下图9所示,这成功解决了生成中的时间和空间差异问题。

结论
本文介绍了VADER,这是一个通过奖励梯度对预训练视频扩散模型进行微调的样本和计算高效框架。本文利用在图像或视频上评估的各种奖励函数来微调视频扩散模型。此外,展示了本文的框架对条件无关,并且可以在文本到视频和图像到视频扩散模型上都能工作。希望本文的工作能够引起更多人对调整视频扩散模型的兴趣。
参考文献
1 Video Diffusion Alignment via Reward Gradients