资源包地址
链接:百度网盘 请输入提取码
提取码:6666
步骤
导入库
import numpy as np
import pandas as pd
首先导入文件,并查看数据样本
# 州的全称和州名称简写对应关系表
abb = pd.read_csv('./data/state-abbrevs.csv')
# 州的全称和面积表
areas = pd.read_csv('./data/state-areas.csv')
# 州名称的简写和面积表,包括年龄和年份信息
population = pd.read_csv('./data/state-population.csv')
display(abb.head(), areas.head(), population.head())
合并pop与abbrevs两个DataFrame,分别依据state/region列和abbreviation列来合并。
为了保留所有信息,使用外合并。# 根据某一列或几列来合并
# 默认合并的规则是查找字段名称相同的列
# 合并的列在内容上,要存在一对一、一对多、多对多的关系
pd.merge(left=population, right=abb, left_on='state/region', right_on='abbreviation', how='inner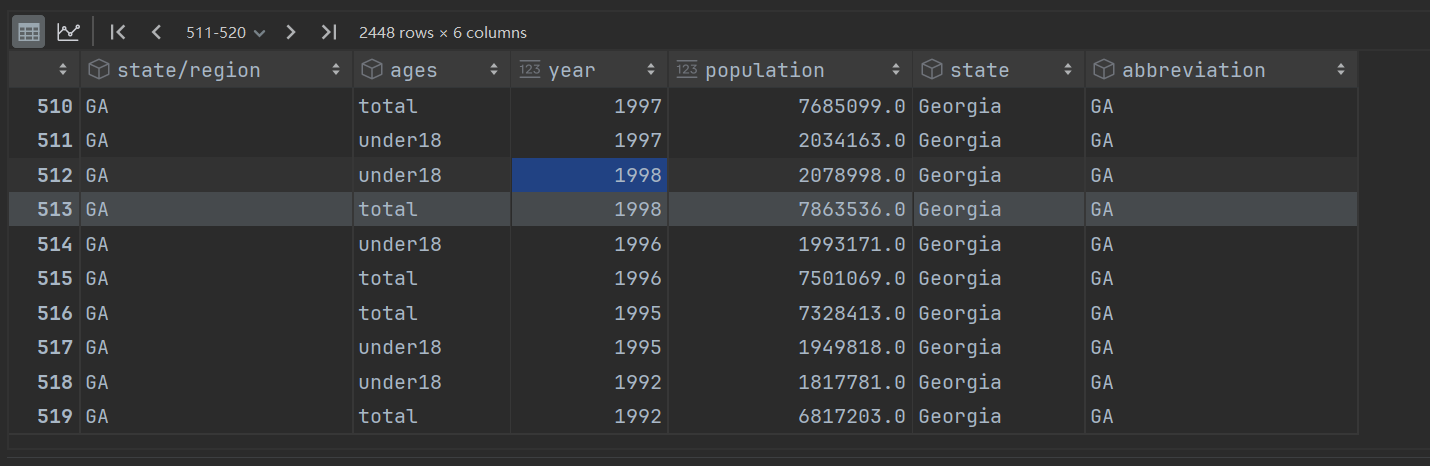
看数据是否缺少
abb.abbreviation.unique()
population['state/region'].unique()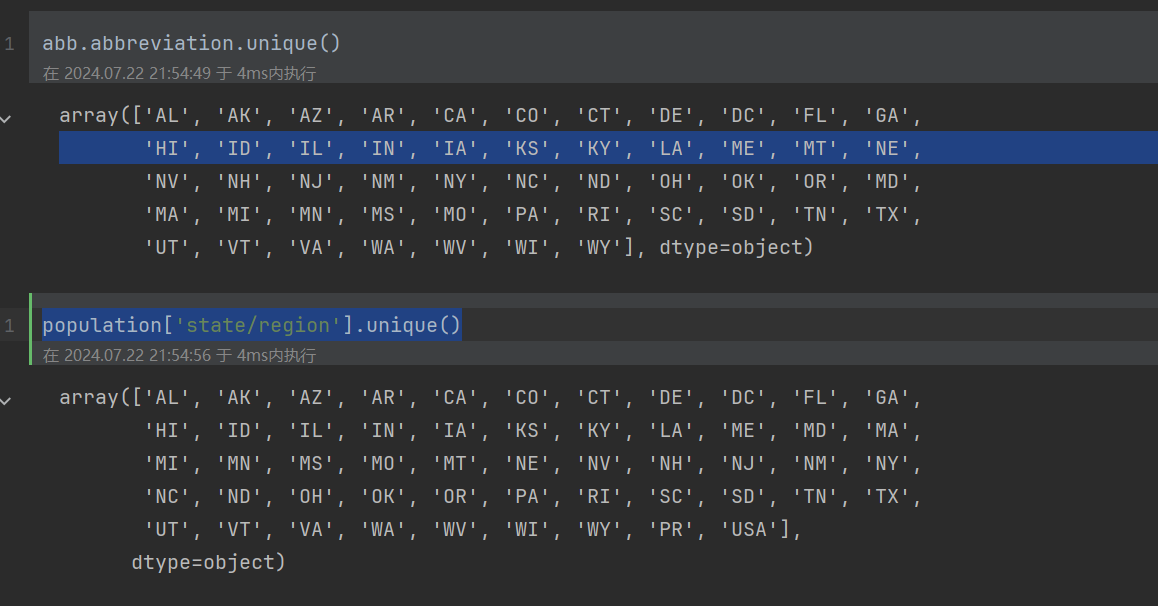
# PR USA这两个简称,在abb表中,是不存在的
set(population['state/region'].unique()) - set(abb.abbreviation.unique()) {'PR', 'USA'}
内合并没有,外合并有
temp = pd.merge(left=population, right=abb, left_on='state/region', right_on='abbreviation', how='outer')
# USA不是一个州,是美国的全称
temp.loc[temp['state/region'] == 'USA']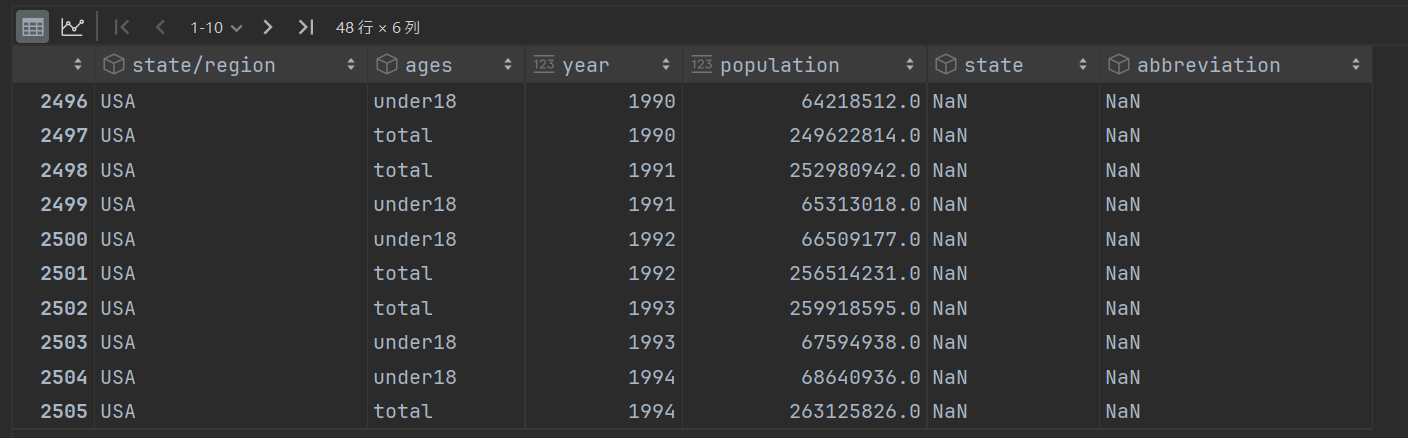
### 查看存在缺失数据的列。
使用.isnull().any(),只有某一列存在一个缺失数据,就会显示True。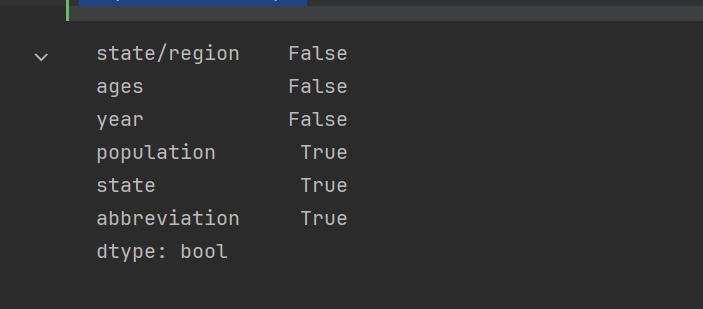
### 根据数据是否缺失情况显示数据,如果缺失为True,那么显示
temp.loc[temp.isnull().any(axis=1)]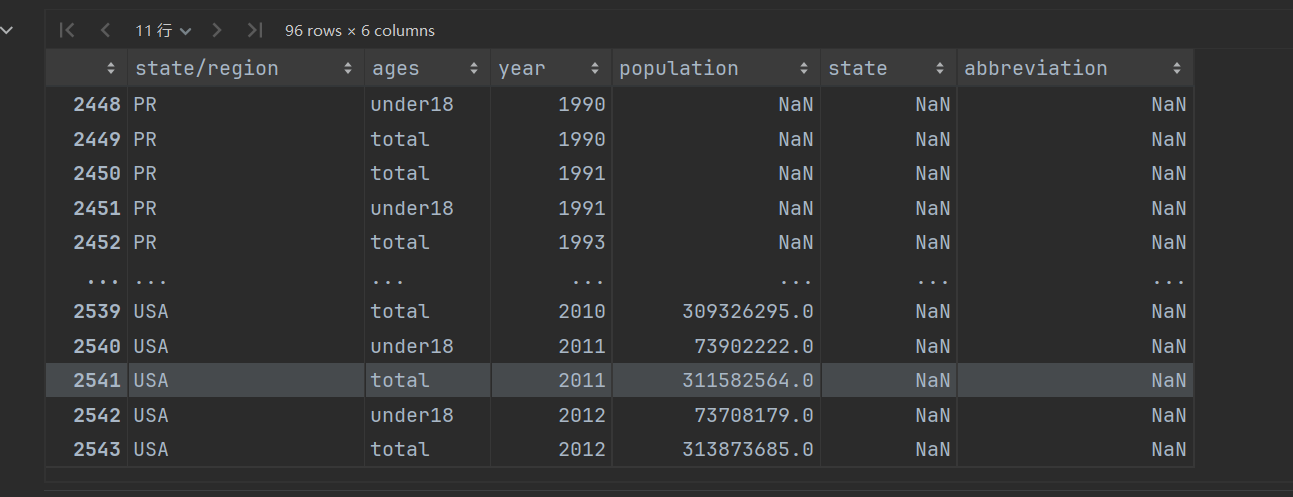
### 找到有哪些state/region使得state的值为NaN,使用unique()查看非重复值
temp.loc[temp.isnull().any(axis=1), 'state/region'].unique()
### 为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN!
经过分析,只有PR和USA对应的state有空值,所以只需要填写这两组数据即可
USA --> USA
PR --> 
# 面积表中存在PR州对应的全称 Puerto Rico
# 简写和全称对应不上关系的时候的处理逻辑?? 业务方确认
set(areas['state']) - set(abb['state']){'Puerto Rico'}
temp.loc[temp['state/region'] == 'PR', 'state'] = 'Puerto Rico'
# 查看使得state为空的州还有哪些
temp.loc[temp['state'].isnull(), 'state/region'].unique()
# 由于USA是全美国的数据,不需要保留,可以删除
# 把sate/region == USA的数据删除usa_index = temp.loc[temp['state/region'] == 'USA'].index
pop_abb = temp.drop(labels=usa_index).copy()
pop_abb.isnull().any()
pop_abb = pop_abb.drop(labels=['abbreviation'], axis=1)
### 继续寻找存在缺失数据的列# 由于2000年之前,并没有统计过PR州的人口数据,所以删除
pop_abb.loc[pop_abb.population.isnull()]
pop_abb.isnull().any()
pop_abb.dropna().isnull().any()
# 删除人口为空的所有行pop_abb.dropna(inplace=True)
pop_abb.head()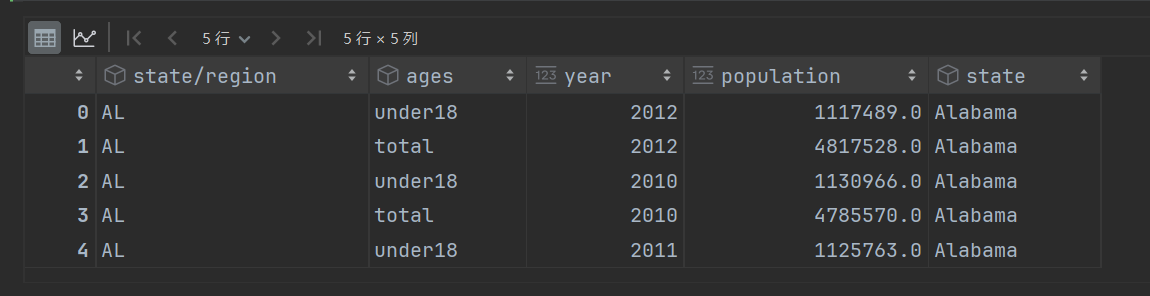
areas.head()
# 使用外合并,保证数据的完整total = pd.merge(left=pop_abb, right=areas, how='outer')
### 找出2010年的全民人口数据,df.query(查询语句)
pop_2010_total = total.query('year == 2010 & ages == "total"')
或者
con1 = total.year == 2010
con2 = total.ages == 'total'
total.loc[con1 & con2]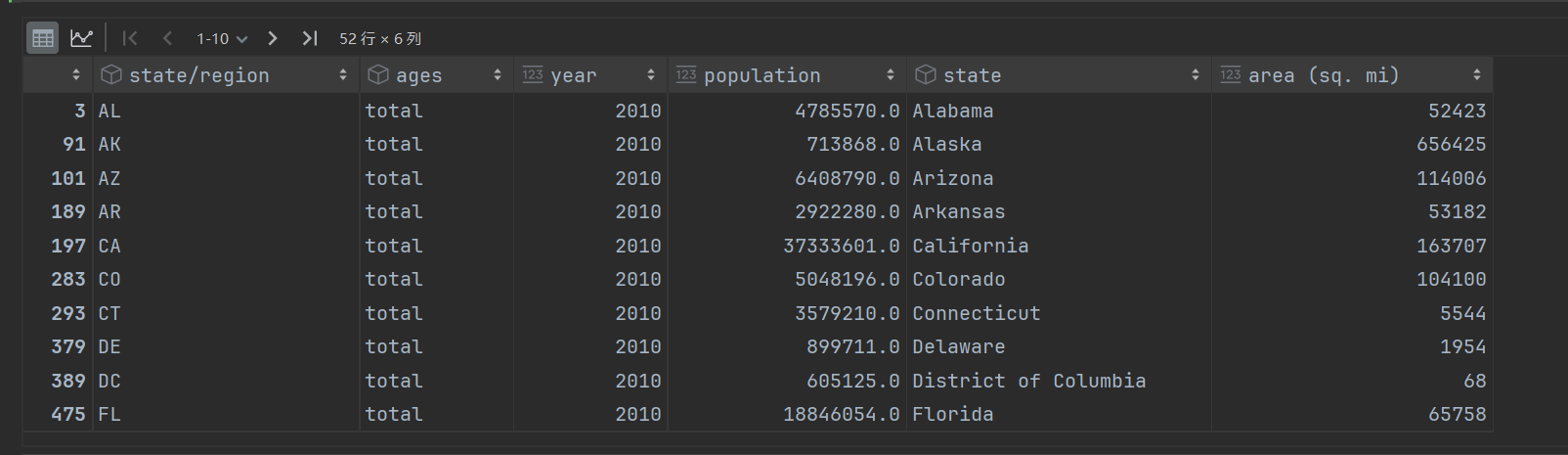
### 对查询结果进行处理,以state列作为新的行索引:set_indextotal['density'] = total['population']/total['area (sq. mi)']
total
density_df = total.query('year == 2012 & ages == "total"').sort_values('density', ascending=False)
density_df.set_index('state').head()