深入理解Eureka核心原理
Eureka整体设计
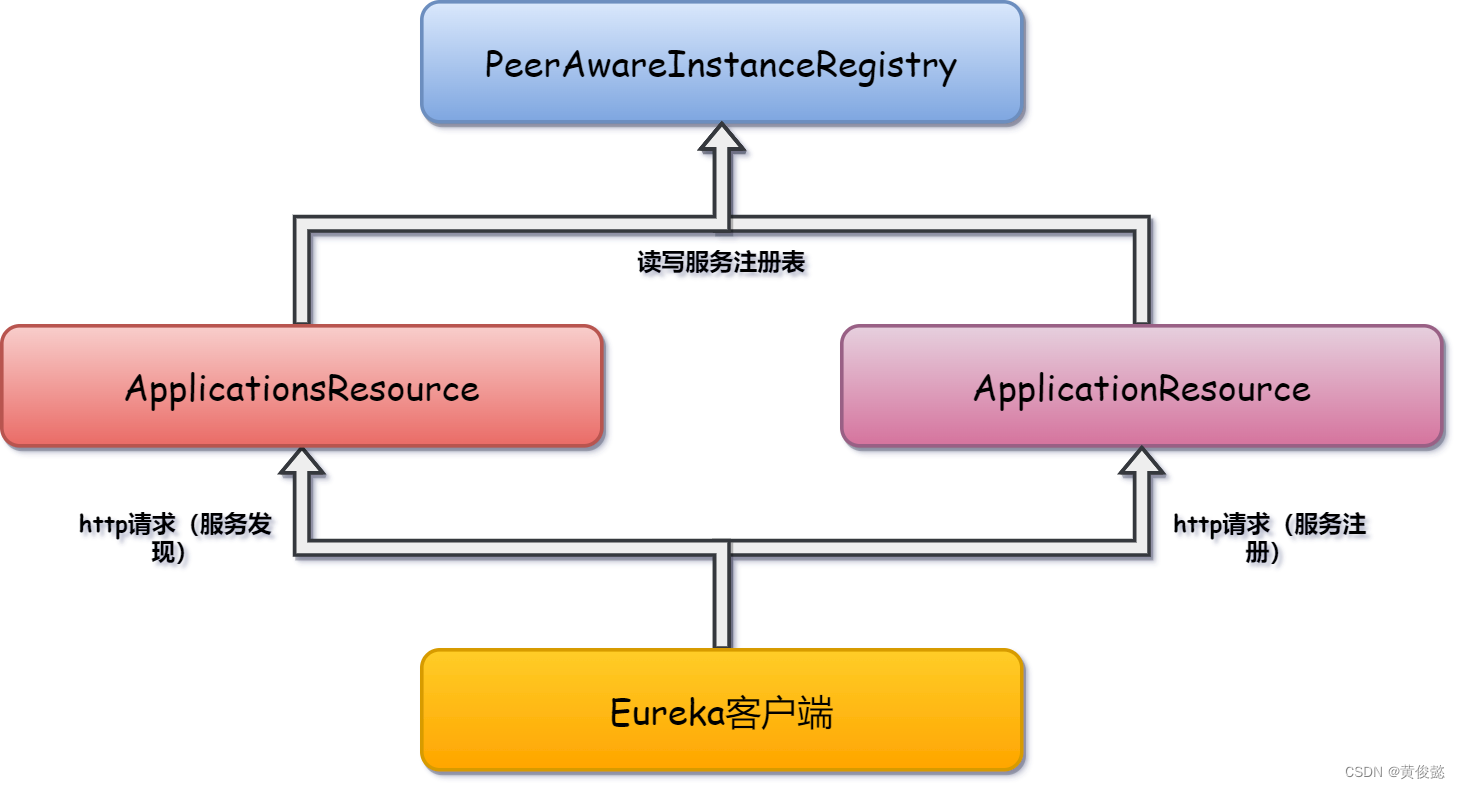
Eureka是一个经典的注册中心,通过http接收客户端的服务发现和服务注册请求,使用内存注册表保存客户端注册上来的实例信息。
Eureka服务端接收的是http请求,通过ApplicationResource 接收服务注册请求,通过ApplicationsResource 接收服务发现请求,这两个类相当于Spring MVC中的Controller ,Eureka使用的不是Spring MVC,而是Jersey,我们直接把他们当成Controller即可。
然后Eureka用一个内存实例注册表PeerAwareInstanceRegistry保存服务提供者注册上来的实例信息,当ApplicationResource接收到服务注册请求时,会把服务实例信息存入PeerAwareInstanceRegistry;当ApplicationsResource接收到服务发现请求时,会从PeerAwareInstanceRegistry拉取服务实例信息返回给客户端
java
public class ApplicationsResource {
private final PeerAwareInstanceRegistry registry;
...
}
java
public class ApplicationResource {
private final PeerAwareInstanceRegistry registry;
...
}Eureka服务端启动
Eureka服务端启动时会初始化PeerAwareInstanceRegistry接口的实现类以及其他核心类,除了初始化PeerAwareInstanceRegistry等一些核心类之外,还会做两件事:
- 从集群中的其他Eureka拉取服务实例列表,注册到自己本地的服务注册表
- 开启服务剔除定时任务,定时扫描超过一定期限没有续约的服务实例,把它剔除出内存注册表

初始化PeerAwareInstanceRegistry的代码在EurekaServerAutoConfiguration中,通过@Bean往Spring容器注册一个InstanceRegistry对象,这个InstanceRegistry就是peerAwareInstanceRegistry的实现类。
java
@Bean
public PeerAwareInstanceRegistry peerAwareInstanceRegistry(
ServerCodecs serverCodecs) {
...
return new InstanceRegistry(...);
}EurekaServerAutoConfiguration还会通过@Import注解导入一个EurekaServerInitializerConfiguration,这个EurekaServerInitializerConfiguration的start()方法会触发集群同步和启动服务剔除定时任务。
java
@Override
public void start() {
new Thread(new Runnable() {
@Override
public void run() {
try {
// EurekaServerAutoConfiguration导入的EurekaServerBootstrap
// 启动Eureka服务
eurekaServerBootstrap.contextInitialized(
EurekaServerInitializerConfiguration.this.servletContext);
...
}
catch (...) {...}
}
}).start();
}
java
public void contextInitialized(ServletContext context) {
try {
//初始化Eureka运行环境
initEurekaEnvironment();
//初始化Eureka服务上下文
initEurekaServerContext();
...
}
catch (...) {...}
}重点是initEurekaServerContext()方法:
java
protected void initEurekaServerContext() throws Exception {
...
// 集群同步(从集群中的其他Eureka实例拉取服务实例列表)
int registryCount = this.registry.syncUp();
// 启动服务提测定时任务
this.registry.openForTraffic(this.applicationInfoManager, registryCount);
...
}Eureka三级缓存
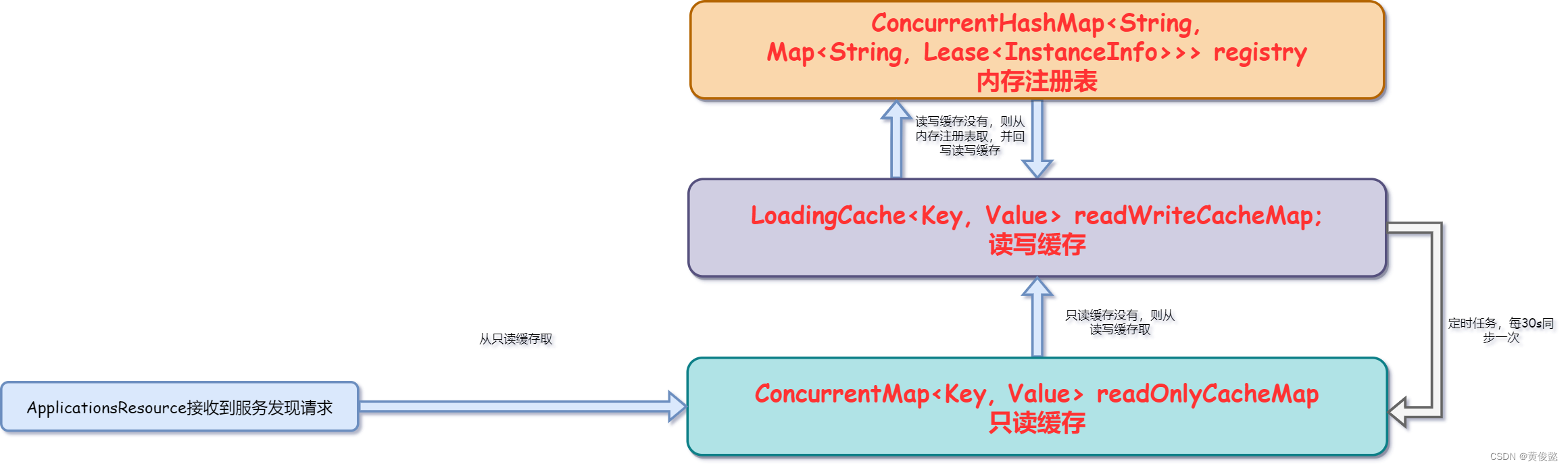
Eureka处理服务发现请求时,其实并不是直接读取内存注册表的,而是读的缓存。Eureka除了内存注册表以外,还有两个缓存,一个是读写缓存readWriteCacheMap,一个是只读缓存readOnlyCacheMap。内存注册表、readWriteCacheMap、readOnlyCacheMap三个组成了Eureka的三级缓存。其中readWriteCacheMap和readOnlyCacheMap被包装在一个ResponseCache对象中。整个三级缓存的结果就是这样:

java
public class PeerAwareInstanceRegistryImpl extends AbstractInstanceRegistry implements PeerAwareInstanceRegistry {
...
}
java
public abstract class AbstractInstanceRegistry implements InstanceRegistry {
...
protected volatile ResponseCache responseCache;
...当ApplicationsResource接收到服务发现请求时:
- 先从只读缓存中取
- 如果只读缓存中没有,则从读写缓存获取并且回写只读缓存
- 如果读写缓存中也没有,则从内存注册表中获取并回写到读写缓存。
Eureka会开启一个定时任务,每隔30s从读写缓存同步数据到只读缓存。
ResponseCacheImpl#getValue:
java
Value getValue(final Key key, boolean useReadOnlyCache) {
Value payload = null;
try {
if (useReadOnlyCache) {
// 从只读缓存取
final Value currentPayload = readOnlyCacheMap.get(key);
if (currentPayload != null) {
payload = currentPayload;
} else {
// 只读缓存没有,则从读写缓存取,回写只读缓存
payload = readWriteCacheMap.get(key);
readOnlyCacheMap.put(key, payload);
}
} else {
payload = readWriteCacheMap.get(key);
}
} catch (...) {...}
return payload;
}readWriteCacheMap的类型是LoadingCache,LoadingCache是Guava库提供的一个本地缓存实现。当LoadingCache缓存缺失时,LoadingCache会触发CacheLoader的load方法,加载数据到缓存中,此时就会从内存注册表中加载数据到readWriteCacheMap中。关于LoadingCache的使用、作用、原理等知识,可以参考讲解Guava缓存相关的资料。
当ApplicationResource接收到服务注册请求时,会把服务实例信息写入内存注册表,并失效掉读写缓存,然后把新注册上来的实例信息异步同步到集群中的其他Eureka节点。

PeerAwareInstanceRegistryImpl#register
java
@Override
public void register(final InstanceInfo info, final boolean isReplication) {
...
super.register(info, leaseDuration, isReplication);
// 同步到集群中的其他Eureka节点
replicateToPeers(Action.Register, info.getAppName(), info.getId(), info, null, isReplication);
}AbstractInstanceRegistry#register:
java
public void register(InstanceInfo registrant, ...) {
try {
...
// 失效读写缓存
invalidateCache(registrant.getAppName(), registrant.getVIPAddress(), registrant.getSecureVipAddress());
...
} finally {
...
}
}
private void invalidateCache(String appName, @Nullable String vipAddress, @Nullable String secureVipAddress) {
// invalidate cache
responseCache.invalidate(appName, vipAddress, secureVipAddress);
}Eureka客户端启动
Eureka的客户端启动时会创建一个DiscoveryClient对象,它是Eureka的客户端对象,它会创建两个定时任务,一个异步延时任务。
两个定时任务:
- 定时拉取服务实例列表(服务发现)
- 定时发送心跳(服务续约)
一个延时任务:服务注册。
DiscoveryClient的构造方法:
java
@Inject
DiscoveryClient(...) {
...
initScheduledTasks();
...
}DiscoveryClient#initScheduledTasks
java
private void initScheduledTasks() {
if (clientConfig.shouldFetchRegistry()) {
...
// 开启服务发现定时任务
scheduler.schedule(
new TimedSupervisorTask(
...
new CacheRefreshThread()
),
registryFetchIntervalSeconds, TimeUnit.SECONDS);
}
if (clientConfig.shouldRegisterWithEureka()) {
...
// 开启服务续约(定时发送心跳)定时任务
scheduler.schedule(
new TimedSupervisorTask(
...
new HeartbeatThread()
),
renewalIntervalInSecs, TimeUnit.SECONDS);
instanceInfoReplicator = new InstanceInfoReplicator(...);
...
// 服务注册
instanceInfoReplicator.start(...);
} else {...}
}它们都是通过Jersey客户端向Eureka服务端发起http请求。
其中服务发现的定时任务在首次拉取是会全量拉取,后续会进行增量拉取。增量拉取返回的服务实例列表会合并到Eureka客户端的本地缓存中,然后根据本地缓存的服务实例列表计算一个hashCode,与Eureka服务端返回的hashCode进行比较,如果不一致,还要再进行一次全量拉取。

以上就是Eureka全部的核心原理,下面放一张源码图,对源码有兴趣的可以跟一跟,没有兴趣的可以直接忽略。
