计算机视觉指计算机看待和理解世界的方式。最广泛使用的方法是CNN卷积神经网络
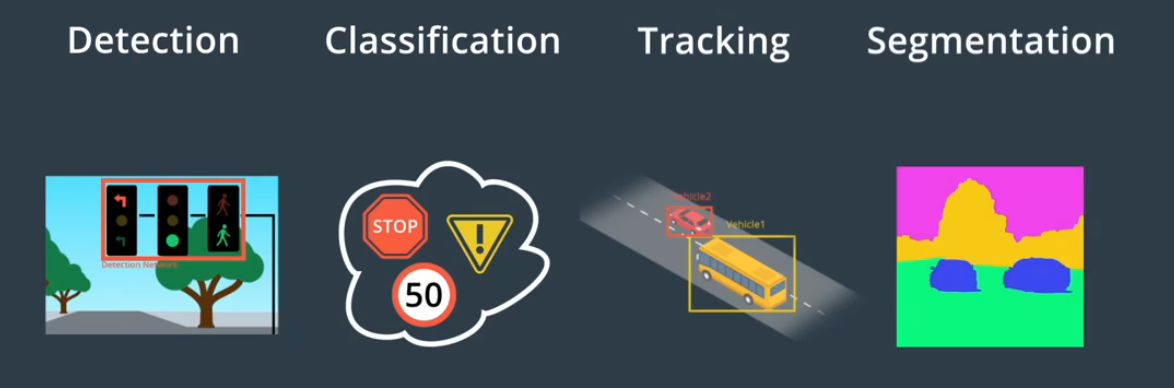
四个核心任务
检测 找出物体在环境中的位置
分类 明确对象是什么
跟踪 随时间推移观察移动物体
语义分割 将图像中的每个像素与语义类别进行匹配
分类器可以 使用特征选择图像类别

模型时帮助计算机了解图像内容的工具,无论经过训练的模型执行什么任务 ,开始时将摄像头图像作为输入
激光雷达传感器创建环境的点云特征,提供了难以通过摄像头图像获得的信息,比如距离和高度。点云中的每个点代表反射回传感器的激光束,提供用于构建世界视觉表征的足够空间信息
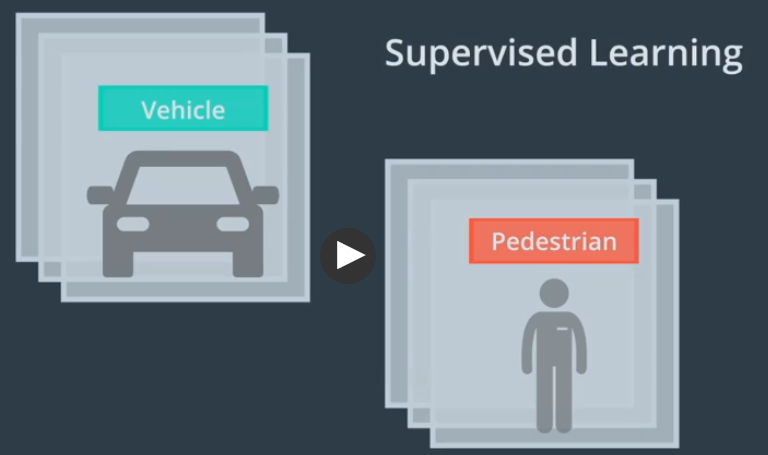
机器学习
学习结果存放在一种被称为模型的数据结构中,模型只是一种用于理解和预测世界的数据结构
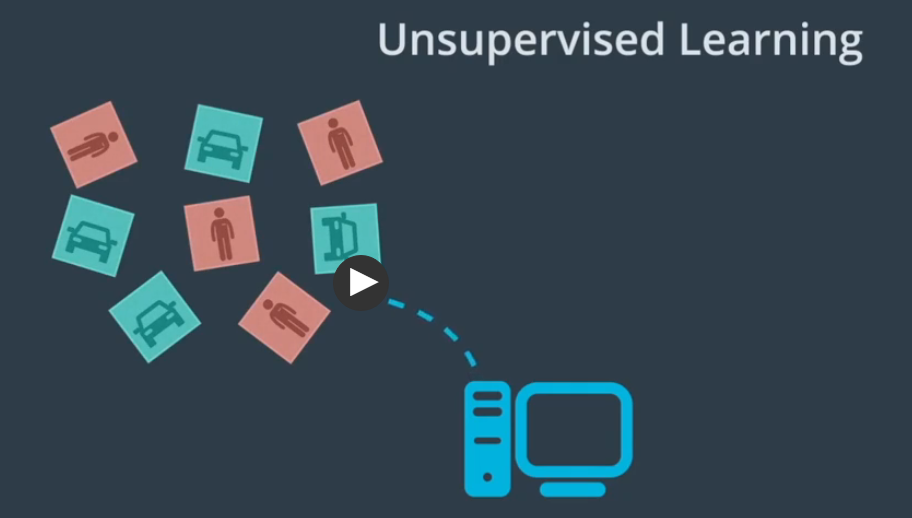
不提供真值标记,而是通过分析输入的数据,计算机凭借自行学习找到区别
另一种方式称为半监督学习,使用少量的标记数据和大量未标记数据来训练模型
强化学习是另一种机器学习,允许模型通过尝试许多不同的方法来解决问题,然后衡量哪种方法最成功
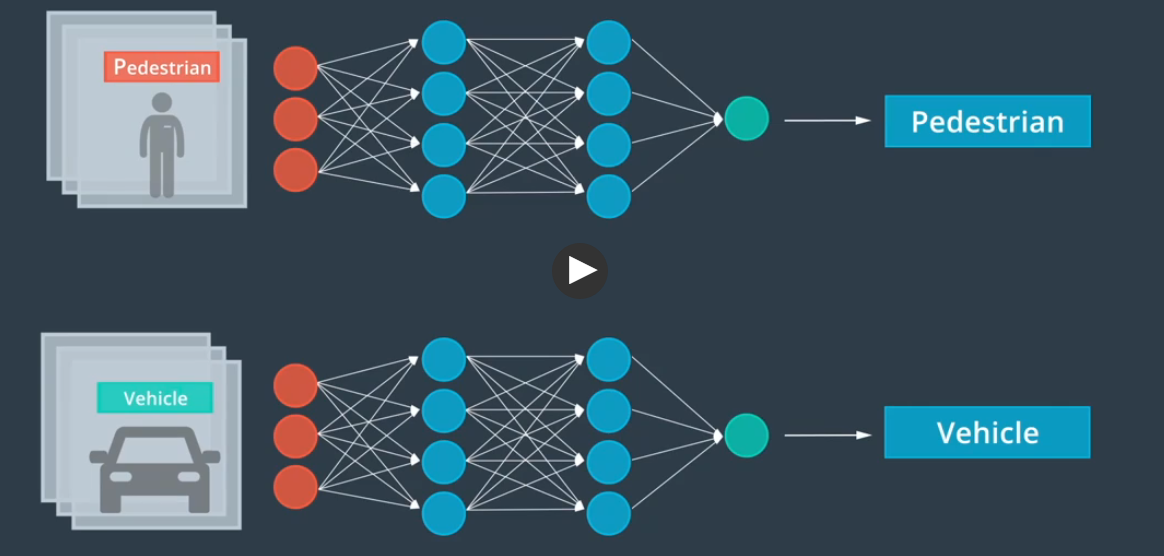
神经网络
识别汽车时,大脑会将权重放在其他特征,并降低颜色的重要性

计算机提取的特征可能是我们无法描述或无法理解的特征,计算机将调整这些特征的权重,完成神经网络的最终任务。
反向传播算法
训练分为三步,前馈,误差测定和反向传播。
首先随机分配初始权重
称为前馈
下一步是误差测定,误差是真值和前馈过程所产生输出之间的偏差。
最后一步通过神经网络反向发送误差,类似前馈过程,每个神经元都对他的权重进行微调,这是基于神经网络后向传播的误差。
为了训练网络,通常需要数千个这样的周期,最终结果应该是模型能够根据数据做出准确预测
卷积神经网络CNN
对感知问题特别有效,接受多维输入
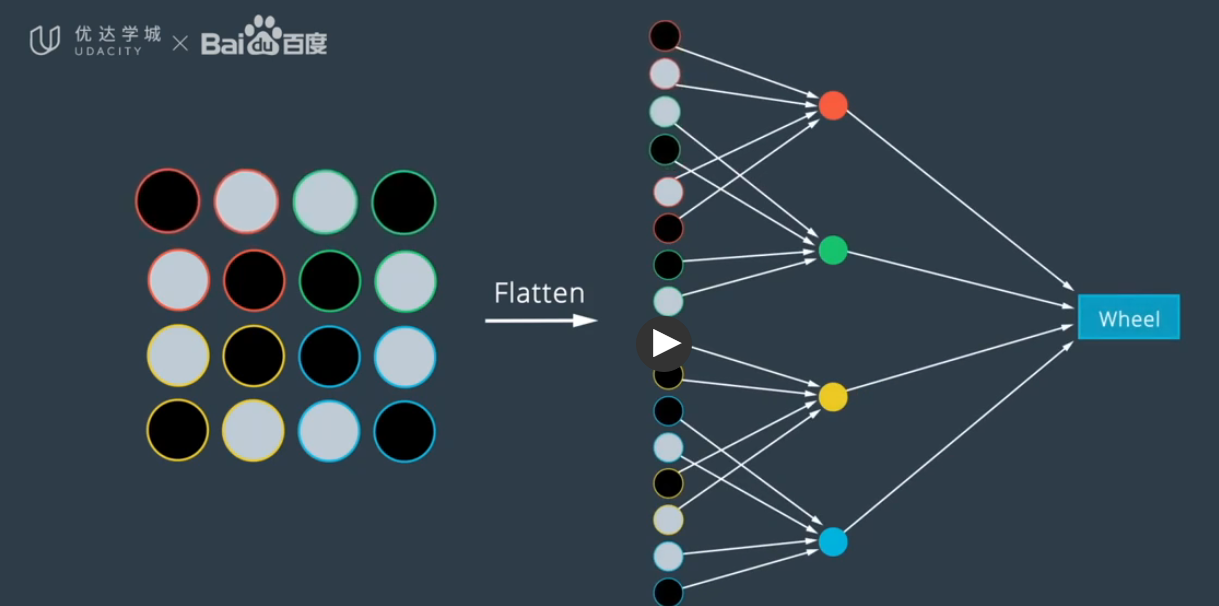
标准做法是通过将图像矩阵重塑为一个矢量,然而这种方法破坏了图像中嵌入的空间信息。
CNN通过维持输入像素之间的空间关系来解决这个问题。
CNN通过将过滤器连续滑过图像来收集信息,每次只对图像的一小部分区域进行分析,这个过程称为卷积
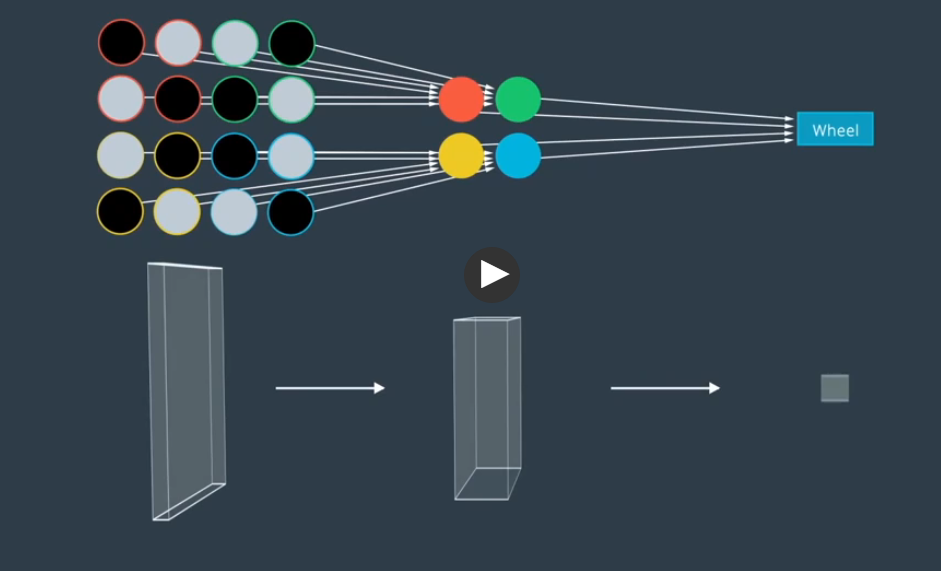

CNN根据他的任务查找真正需要的特征
检测与分类
障碍物检测,静态障碍物,动态障碍物。计算机需要首先知道这些障碍物进行分类
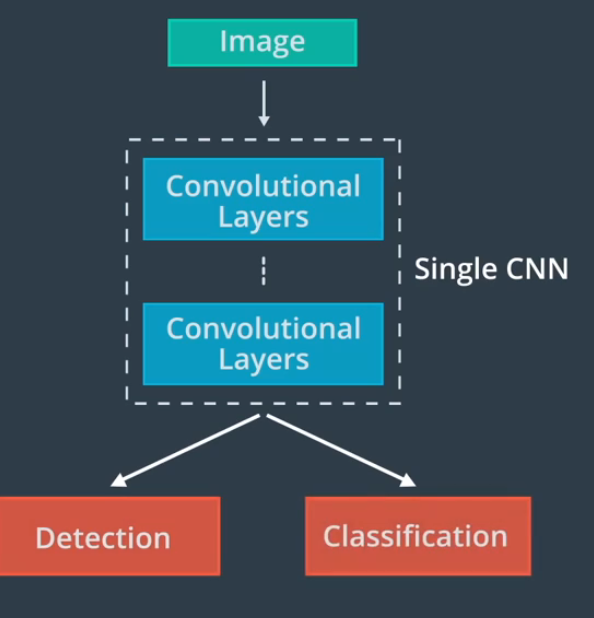
我们可以先使用检测CNN来查找图像中对象的位置,定位后将图像发送给另一个CNN进行分类,也可以使用单一CNN体系结构对对象进行检测和分类
通常做法是在单个网络体系结构的末端附加几个不同的头
一个经典的体系结构为R-CNN及其变体Fast R-CNN和Faster R-CNN
yolo 和 SSD是具有类似形式的不同体系结构
R-CNN及其变体(Fast R-CNN和Faster R-CNN)以及YOLO和SSD是计算机视觉领域中用于目标检测的几种重要的深度学习体系结构
1. R-CNN(Regions with CNN features)
-
主要概念:R-CNN使用选择性搜索算法来提取图像中的一系列提议区域(region proposals),然后对每个区域使用卷积神经网络(CNN)提取特征,最后通过支持向量机(SVM)进行分类。
-
优点:能够准确地定位和识别对象。
-
缺点:计算成本高,处理速度慢,因为需要对每个提议区域单独进行特征提取和分类。
2. Fast R-CNN
-
改进:在R-CNN的基础上改进,通过整个图像只进行一次前向传播来提取特征,然后将这些特征映射到每个提议区域上。
-
优点:比R-CNN快得多,因为它减少了需要的卷积操作数量。
-
缺点:虽然比原始的R-CNN快,但生成提议区域的速度仍然限制了整体速度。
3. Faster R-CNN
-
改进:引入区域建议网络(Region Proposal Network, RPN),用于从特征图中直接生成提议区域,这样可以进一步提高速度。
-
优点:实现了提议区域的生成和特征提取的端到端训练,大大加快了处理速度。
-
缺点:尽管速度比Fast R-CNN快,但在处理非常大的图像库时仍可能存在效率问题。
4. YOLO(You Only Look Once)
-
主要概念:不使用区域提议的方式,而是将图像分割成多个格子,每个格子直接预测边界框和分类概率。
-
优点:非常快,可以实现实时目标检测。YOLO将整个目标检测作为一个单一的回归问题处理,从而可以直接在全图上预测目标。
-
缺点:可能在小对象的检测上表现不佳,因为每个格子只预测一个对象。
5. SSD(Single Shot MultiBox Detector)
-
主要概念:同样避免使用区域提议,SSD在不同尺度的特征图上直接进行边界框的预测和分类。
-
优点:速度快,而且能够较好地处理不同尺寸的对象。
-
缺点:在某些复杂背景或小对象的检测上可能不如基于区域提议的方法精确。
这些体系结构各有优势和局限,选择哪一个往往取决于具体的应用需求,如速度、精度和可处理的对象大小。
跟踪
跟踪可以解决遮挡问题,障碍物检测的输出包含对象的边界框,单独使用对象检测,计算机不知道一个帧中的哪些对象与下一帧的哪些图像对应
第一步是确认身份,通过查找特征相似度最高的对象,将在之前帧中检测到的所有对象与当前的帧中检测到的对象进行匹配。计算机视觉算法可以计算出复杂的图像特征。如局部二值模式和方向梯度直方图
分割
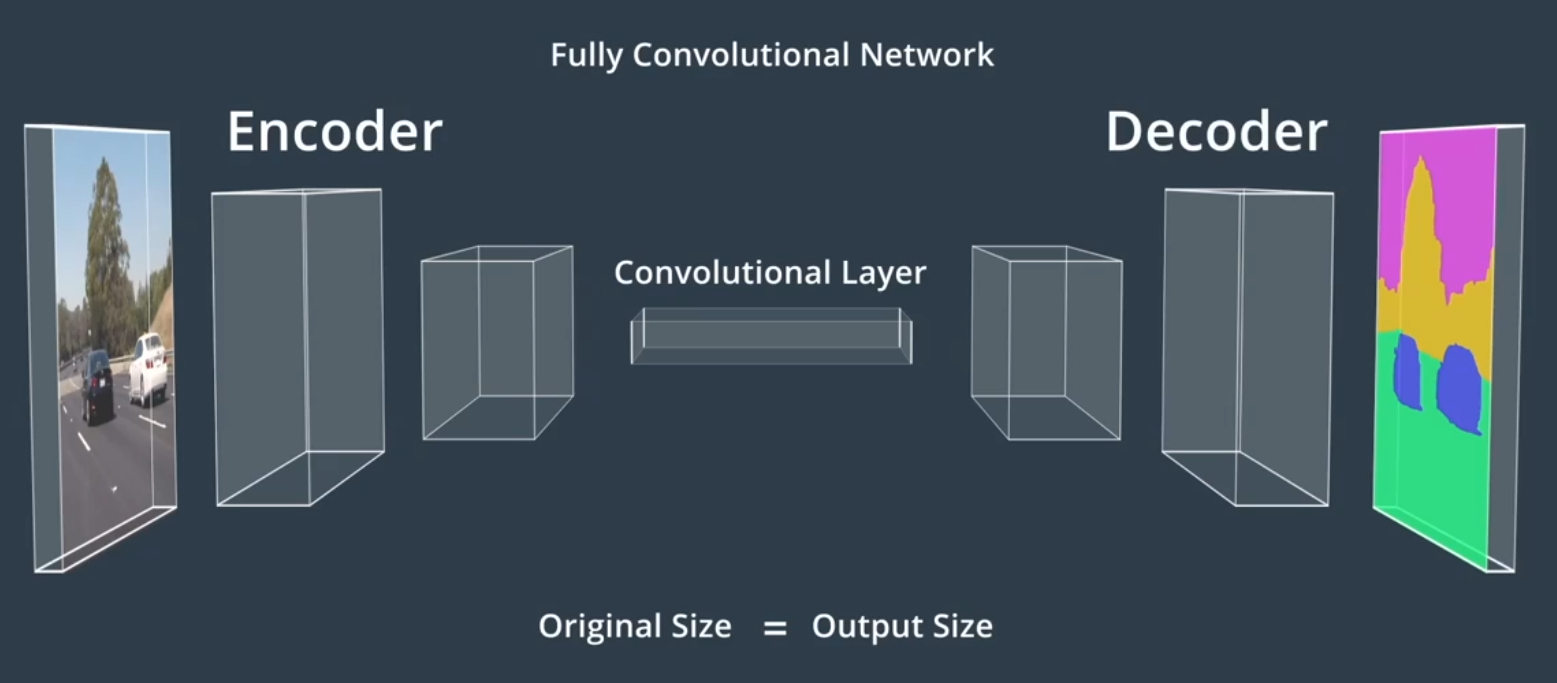
依赖于一种特殊的CNN,称为全卷积网络或FCN。FCN用卷积层来替代传统CNN体系结构末端的平坦层。这样网络中的每一层都是卷积层,所以叫全卷积网络
FCN提供了可在原始输入图像之上叠加的逐像素输出
编码器encoder对输入图像特征进行了提取和编码,后半部分称为解码器,它对这些特征进行了解码,并将其应用于输出
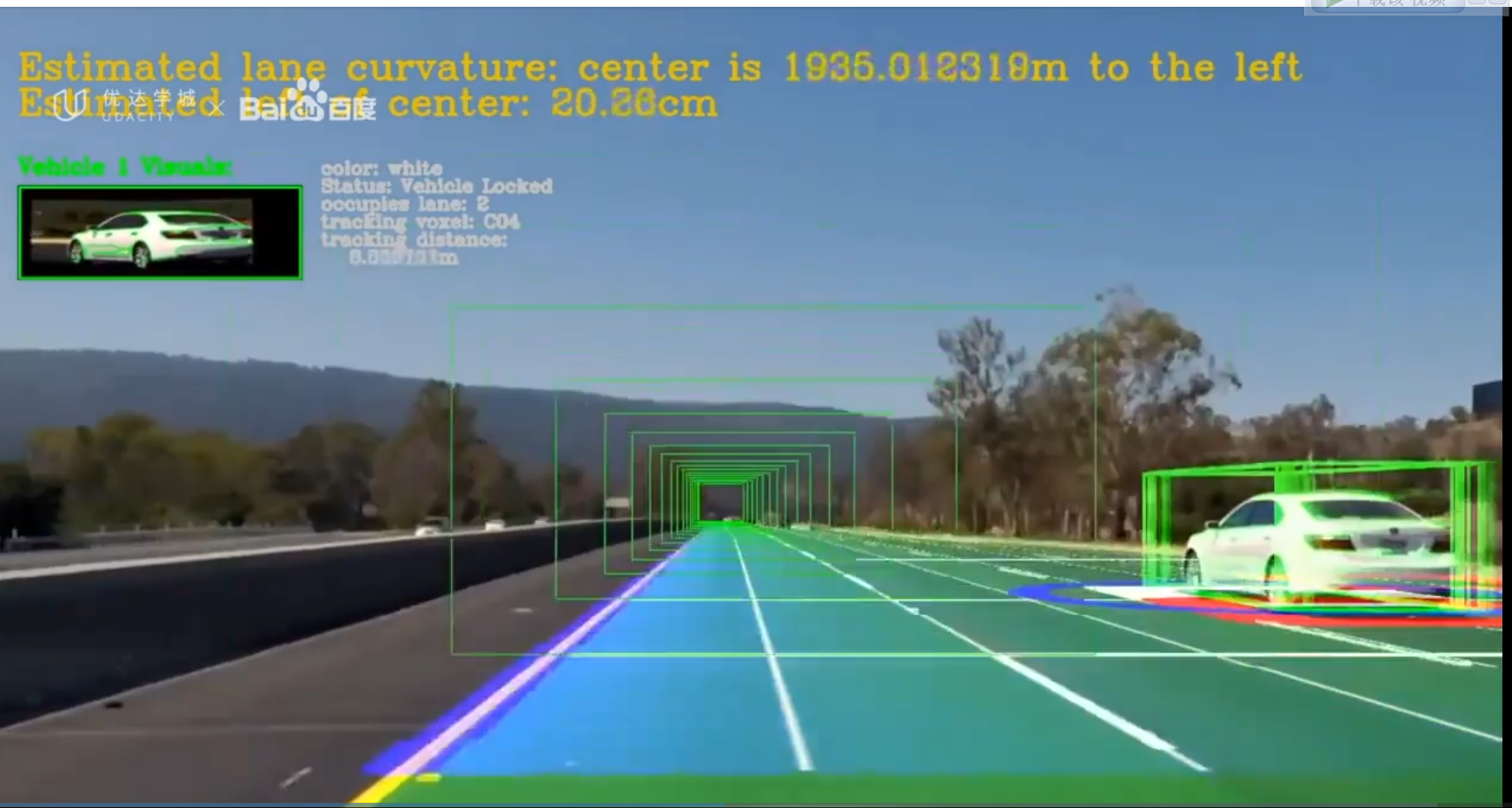
apollo感知
使用ROI来重点关注相关对象,缩小范围来加快感知,通过检测网络馈送已过滤的点云,输出用于构建围绕对象的三维边界
最后使用检测跟踪关联的算法来跨时间识别单个对象。该算法先保留每个时间步要跟踪的对象列表,然后在下一步时间步中找到每个对象的最佳匹配
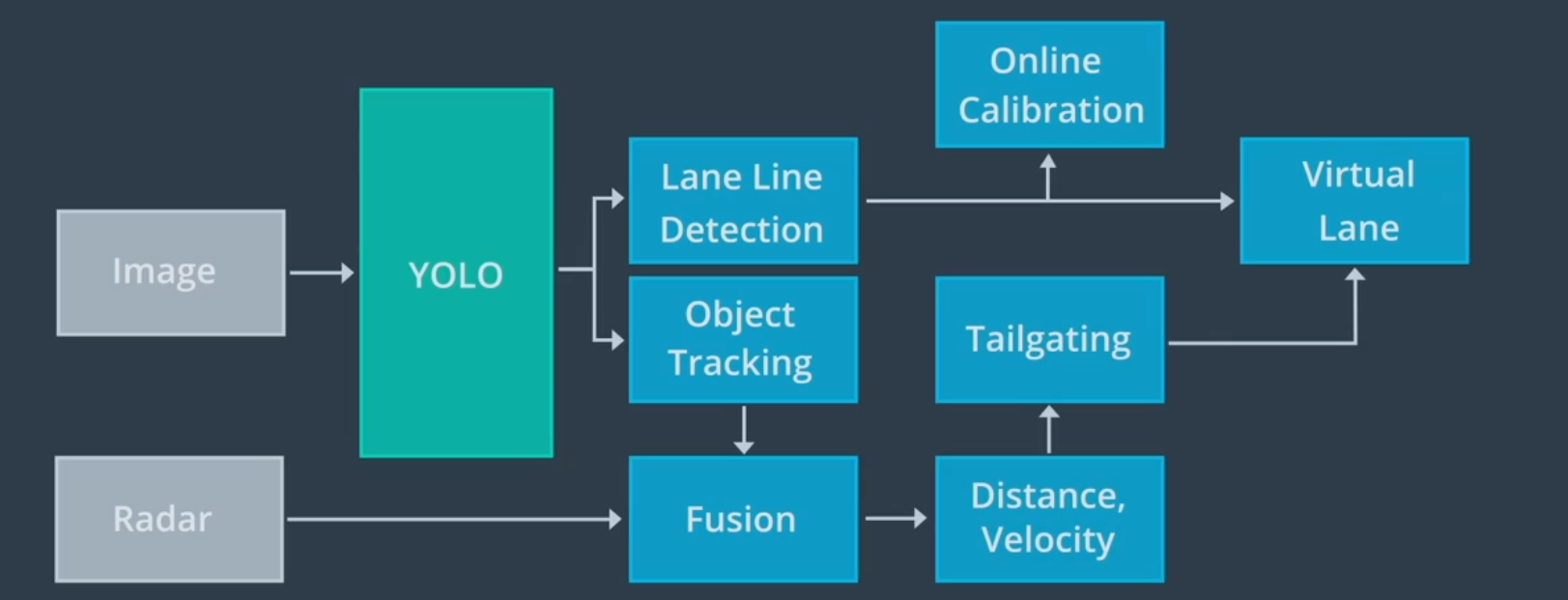
apollo使用yolo网络检测车道线和动态物体,在经过yolo网络检测后,在线检测模块会并入其他传感器的数据对车道线预测进行调整。车道线最终被并入名为虚拟车道的单一数据结构中 。同样,也通过其他传感器的数据,对yolo网络所检测到的动态对象进行调整,以获得每个对象的类型,位置,速度,和前进方向。虚拟通道和动态对象,均被传递到规划和控制模块
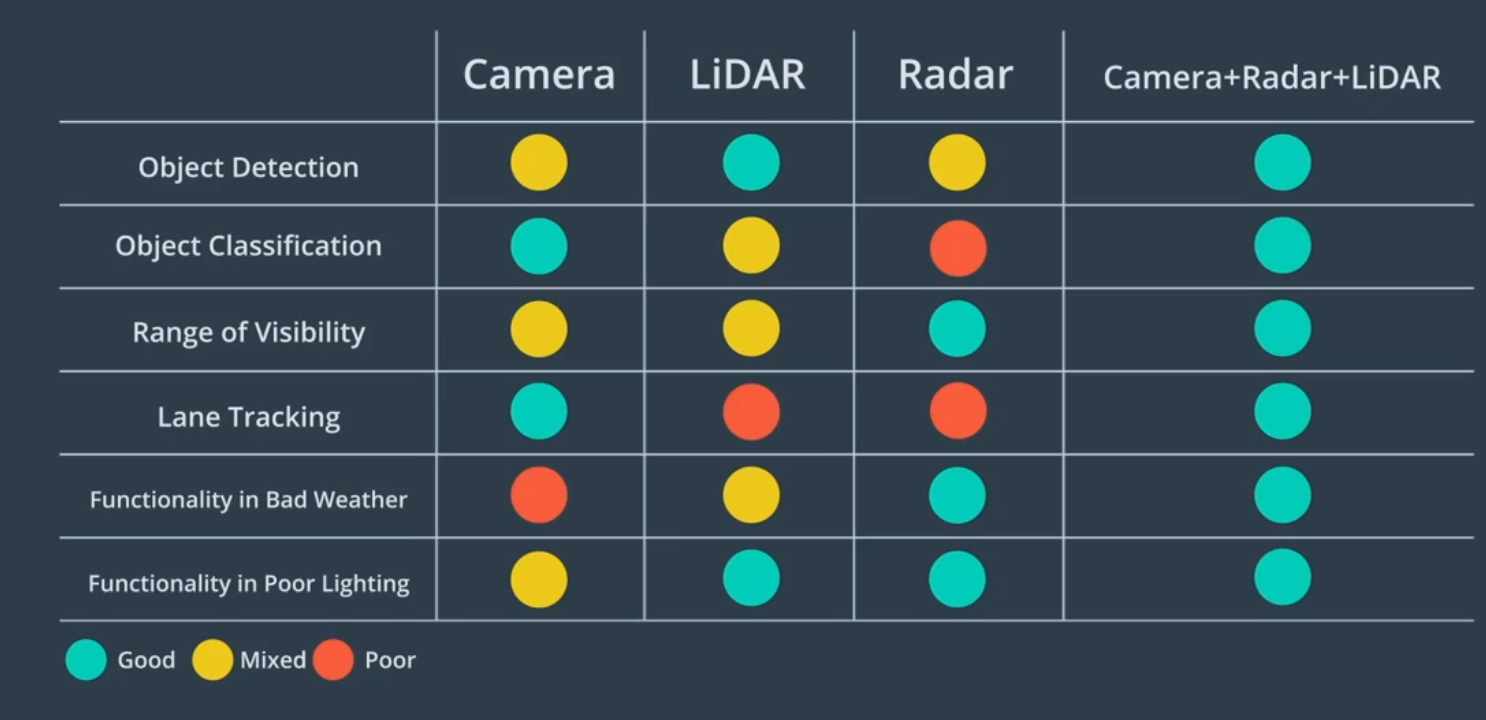
传感器数据比较
摄像头适用于分类,主要用于信号灯分类和车道检测。激光雷达LiDar优势在于障碍物检测。Radar在恶劣环境有优势,融合三种传感器可实现最佳聚合性能,这称为传感器融合
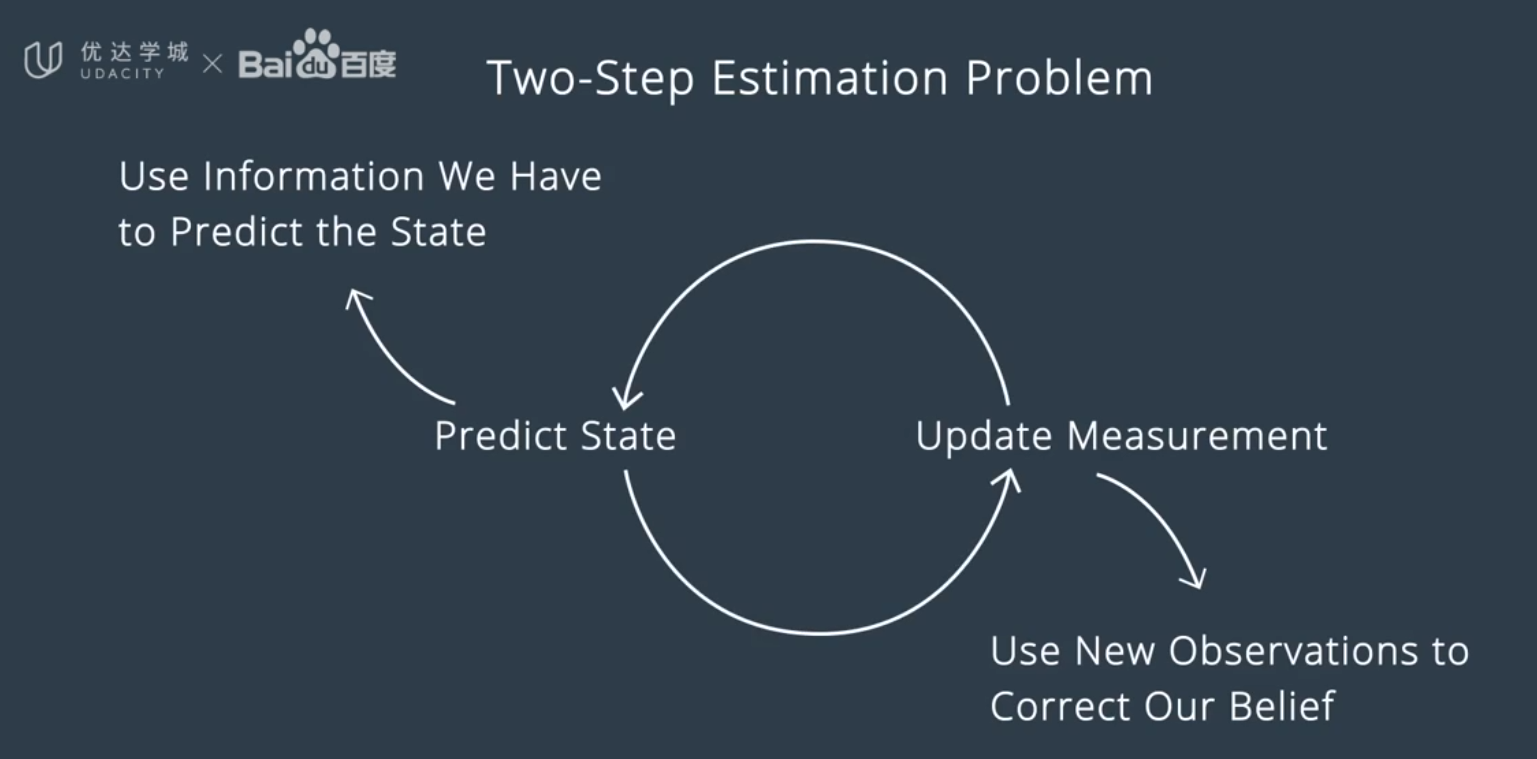
用于融合输出的主要算法为卡尔曼滤波
分为两个状态,预测状态和更新测量结果
两种测量结果更新方法:同步和异步,同步融合同时更新来自不同传感器的测量结果
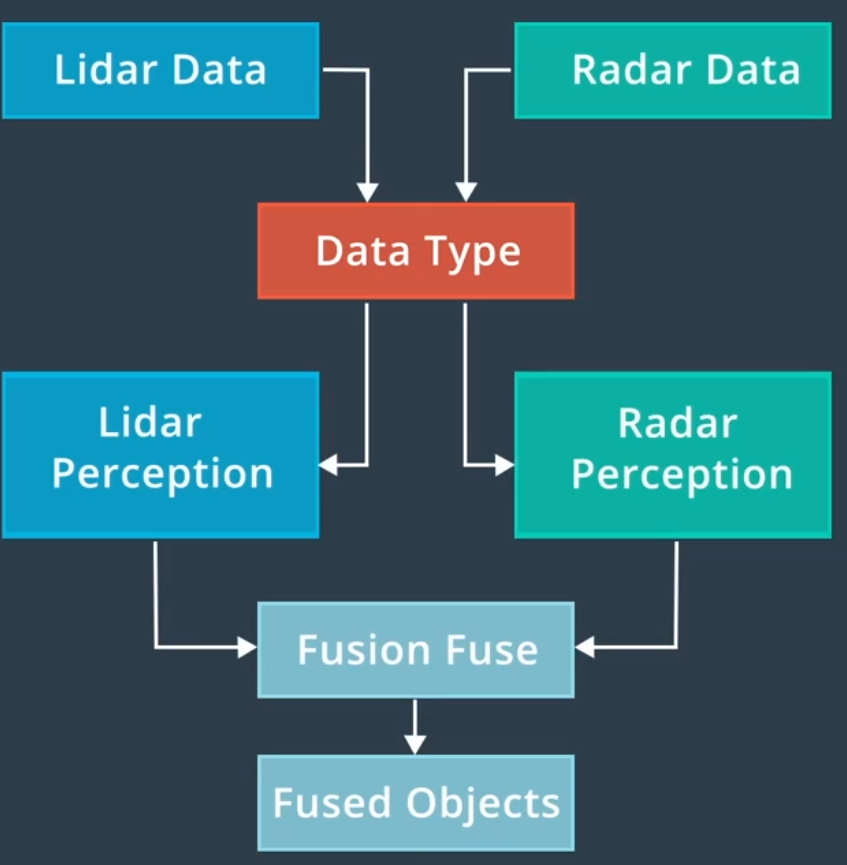
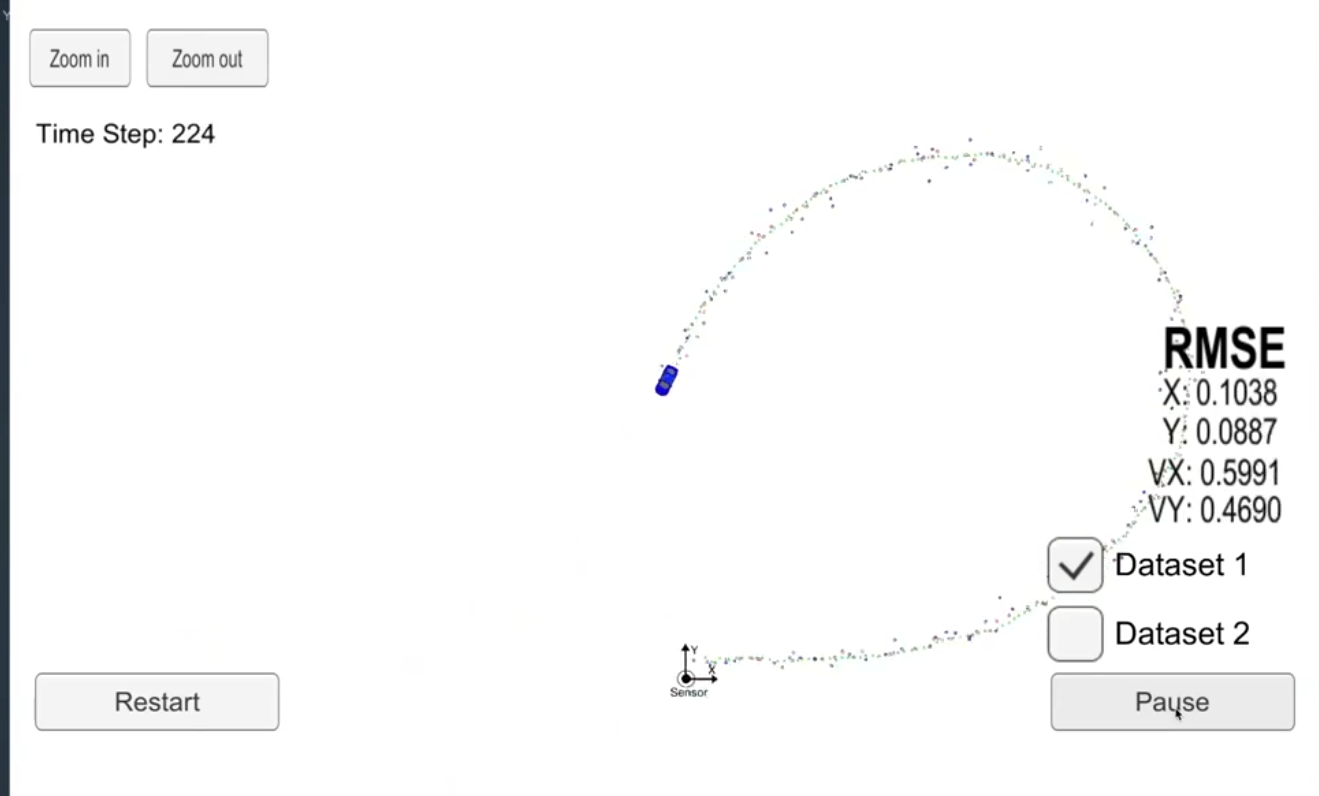
扩展型卡尔曼滤波器融合了噪杂的非线性数据
总结
感知任务大部分依赖于卷积神经网络,结合传感器融合技术实现感知