文章目录
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、简介
前面我们使用手动的方式来构建了一个简单的线性回归模型,如果碰到一些较大的网络设计,手动构建过于繁琐。
手动构建线性回归模型:https://xzl-tech.blog.csdn.net/article/details/140623730
所以,我们需要学会使用 PyTorch 的各个组件来搭建网络。
接下来,我们使用 PyTorch 提供的接口来定义线性回归。
- 使用 PyTorch 的 nn.MSELoss() 代替自定义的平方损失函数
- 使用 PyTorch 的 data.DataLoader 代替自定义的数据加载器
- 使用 PyTorch 的 optim.SGD 代替自定义的优化器
- 使用 PyTorch 的 nn.Linear 代替自定义的假设函数
解析如下:
数据集和数据加载器
- 构建数据集对象
TensorDataset,用于将特征x和标签y封装为一个数据集。- 构建数据加载器
DataLoader,用于按批次加载数据,批次大小为 16,并打乱数据顺序。
构建模型、损失函数和优化器
- 使用
nn.Linear构建一个线性模型,输入和输出特征数均为 1。- 使用均方误差损失函数
nn.MSELoss。- 使用随机梯度下降优化器
optim.SGD,学习率为 0.01。
训练过程
- 外层循环控制训练轮数
epochs。- 内层循环通过数据加载器
dataloader按批次加载训练数据。- 每个批次中:
- 将训练数据送入模型,计算预测值
y_pred。- 计算预测值与真实值之间的损失
loss。- 梯度清零,防止梯度累积。
- 反向传播计算梯度。
- 使用优化器更新模型参数。
我们接下来使用 PyTorch 来构建线性回归
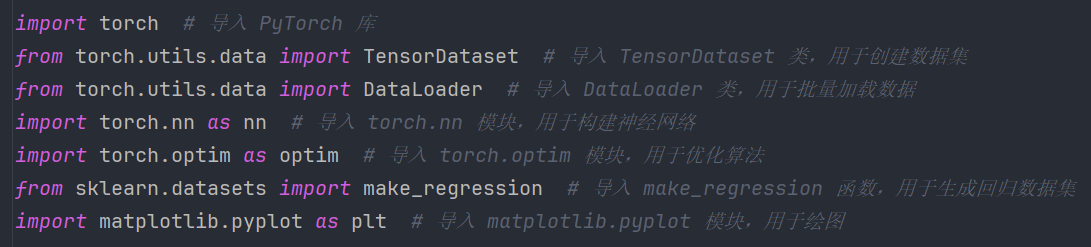
2、导包
3、设置属性

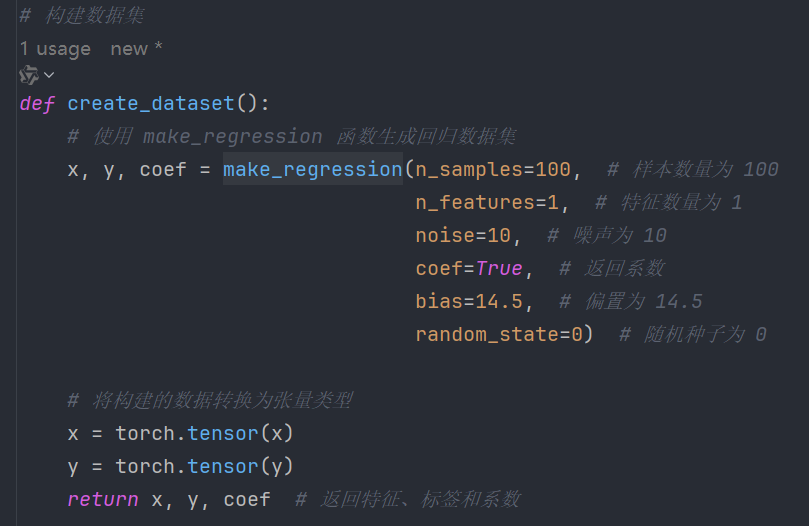
4、构建数据集
5、训练函数
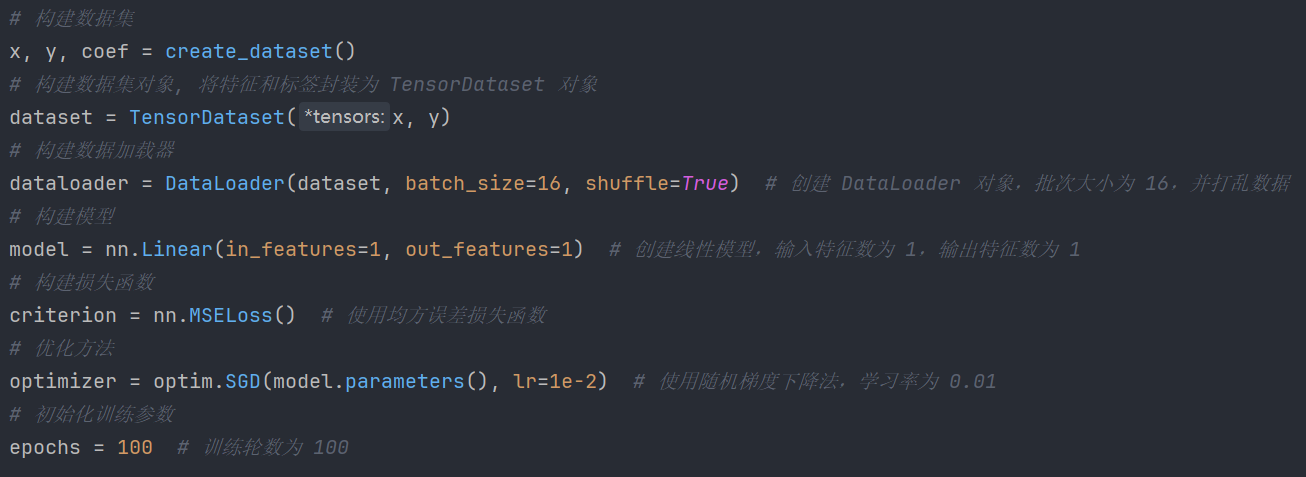
5.1、初始准备
5.2、训练过程

5.3、绘制图像

6、运行效果

从程序运行结果来看,我们绘制一条拟合的直线,和原始数据的直线基本吻合,说明我们训练的还不错。
7、完整代码
python
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/7/23 4:08
import torch # 导入 PyTorch 库
from torch.utils.data import TensorDataset # 导入 TensorDataset 类,用于创建数据集
from torch.utils.data import DataLoader # 导入 DataLoader 类,用于批量加载数据
import torch.nn as nn # 导入 torch.nn 模块,用于构建神经网络
import torch.optim as optim # 导入 torch.optim 模块,用于优化算法
from sklearn.datasets import make_regression # 导入 make_regression 函数,用于生成回归数据集
import matplotlib.pyplot as plt # 导入 matplotlib.pyplot 模块,用于绘图
# 设置 Matplotlib 的字体和显示属性,用来正常显示中文标签和负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为 SimHei,用于显示中文
plt.rcParams['axes.unicode_minus'] = False # 允许显示负号
# 构建数据集
def create_dataset():
# 使用 make_regression 函数生成回归数据集
x, y, coef = make_regression(n_samples=100, # 样本数量为 100
n_features=1, # 特征数量为 1
noise=10, # 噪声为 10
coef=True, # 返回系数
bias=14.5, # 偏置为 14.5
random_state=0) # 随机种子为 0
# 将构建的数据转换为张量类型
x = torch.tensor(x)
y = torch.tensor(y)
return x, y, coef # 返回特征、标签和系数
# 定义训练函数
def train():
# 构建数据集
x, y, coef = create_dataset()
# 构建数据集对象, 将特征和标签封装为 TensorDataset 对象
dataset = TensorDataset(x, y)
# 构建数据加载器
dataloader = DataLoader(dataset, batch_size=16, shuffle=True) # 创建 DataLoader 对象,批次大小为 16,并打乱数据
# 构建模型
model = nn.Linear(in_features=1, out_features=1) # 创建线性模型,输入特征数为 1,输出特征数为 1
# 构建损失函数
criterion = nn.MSELoss() # 使用均方误差损失函数
# 优化方法
optimizer = optim.SGD(model.parameters(), lr=1e-2) # 使用随机梯度下降法,学习率为 0.01
# 初始化训练参数
epochs = 100 # 训练轮数为 100
# 训练过程
for _ in range(epochs): # 训练 epochs 轮
for train_x, train_y in dataloader: # 遍历每个批次的数据
# 将一个批次的训练数据送入模型
y_pred = model(train_x.type(torch.float32)) # 计算模型的预测值
# 计算损失值
loss = criterion(y_pred, train_y.reshape(-1, 1).type(torch.float32)) # 计算批次损失值
# 梯度清零
optimizer.zero_grad() # 清零优化器中的梯度
# 自动微分(反向传播)
loss.backward() # 反向传播计算梯度
# 更新参数
optimizer.step() # 使用优化器更新模型参数
# 绘制拟合直线
plt.scatter(x, y) # 绘制散点图
x_vals = torch.linspace(x.min(), x.max(), 1000) # 生成从 x 的最小值到最大值的等间距点
y1 = torch.tensor([v * model.weight + model.bias for v in x_vals]) # 计算训练得到的拟合直线
y2 = torch.tensor([v * coef + 14.5 for v in x_vals]) # 计算真实的直线
plt.plot(x_vals, y1, label='训练') # 绘制训练得到的拟合直线
plt.plot(x_vals, y2, label='真实') # 绘制真实直线
plt.grid() # 显示网格
plt.legend() # 显示图例
plt.show() # 显示图形
# 主程序入口
if __name__ == '__main__':
train() # 调用 train 函数开始训练