目录
前言
博主身为一个农批,当然要尝试爬取王者荣耀的东西啦。
将进酒,杯莫停!
一、浇给
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.edge.options import Options
if __name__ == '__main__':
# 无头模式
opt = Options()
opt.add_argument("--headless")
driver = webdriver.Edge(options=opt)
# 创建一个可以通过 Selenium 控制的 Microsoft Edge 浏览器实例,并将其赋值给变量 driver
# driver = webdriver.Edge()
# 获取url并发送请求
driver.get("https://pvp.qq.com/web201605/herolist.shtml")
# time.sleep(3)
WebDriverWait(driver, 10).until( # 等待程序运行10s,定位到英雄列表的位置则继续运行,未定位到则报错
EC.presence_of_element_located((By.XPATH, "//ul[@class='herolist clearfix']"))
)
# find_elements获取ul标签下的所有li标签 find_element获取该标签下第一个标签的内容
li_list = driver.find_elements(By.XPATH, "//ul[@class='herolist clearfix']/li")
for i in li_list:
img_url = i.find_element(By.XPATH, "a/img").get_attribute("src")
name = i.find_element(By.XPATH, "a/img").get_attribute("alt")
print(img_url, name)
driver.close()输出 :太多了,就不复制进代码里展示了,获取了所有英雄的图片和名字。

二、前摇
1.导入selenium库
按win + r打开命令提示符,输入cmd,按回车进入,安装selenium库
安装不了的可以先给pip换个源,这篇文章开头即有:python-快速上手爬虫-CSDN博客
python
pip install selenium2.下载浏览器驱动
我用的edge的浏览器,所以在这介绍的就是下载edge浏览器的驱动。
打开浏览器设置,点击最下面的关于浏览器,记住浏览器的版本号。
搜索edge驱动。
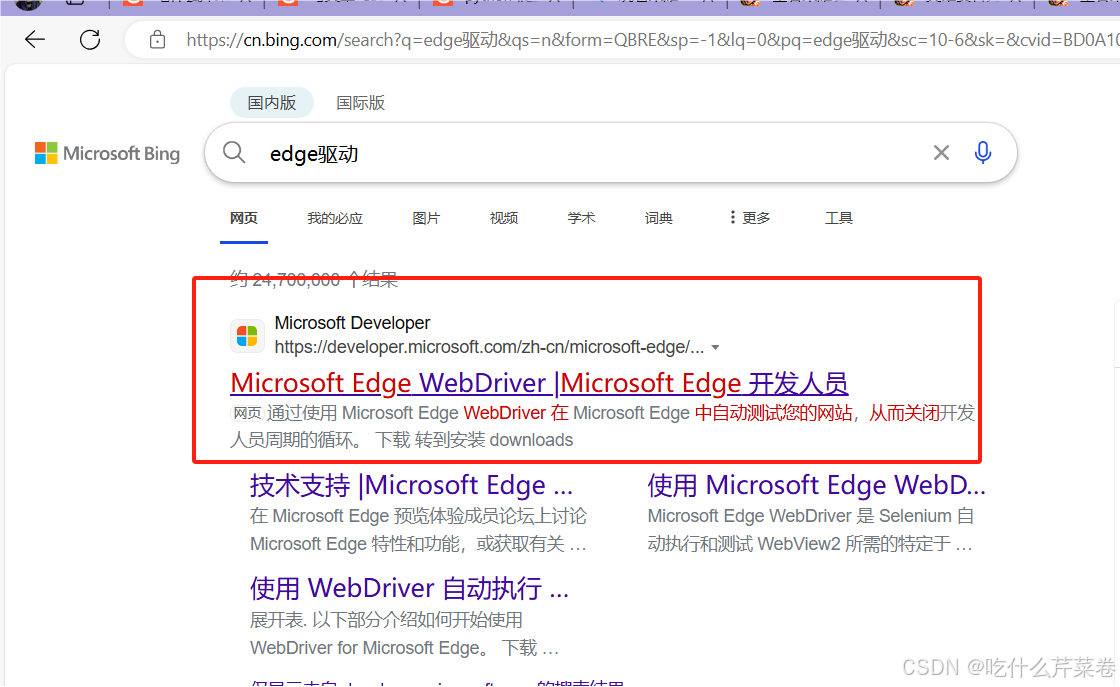
点进去,往下翻找到驱动的版本,找到自己浏览器对应的版本下载,安装x64的。
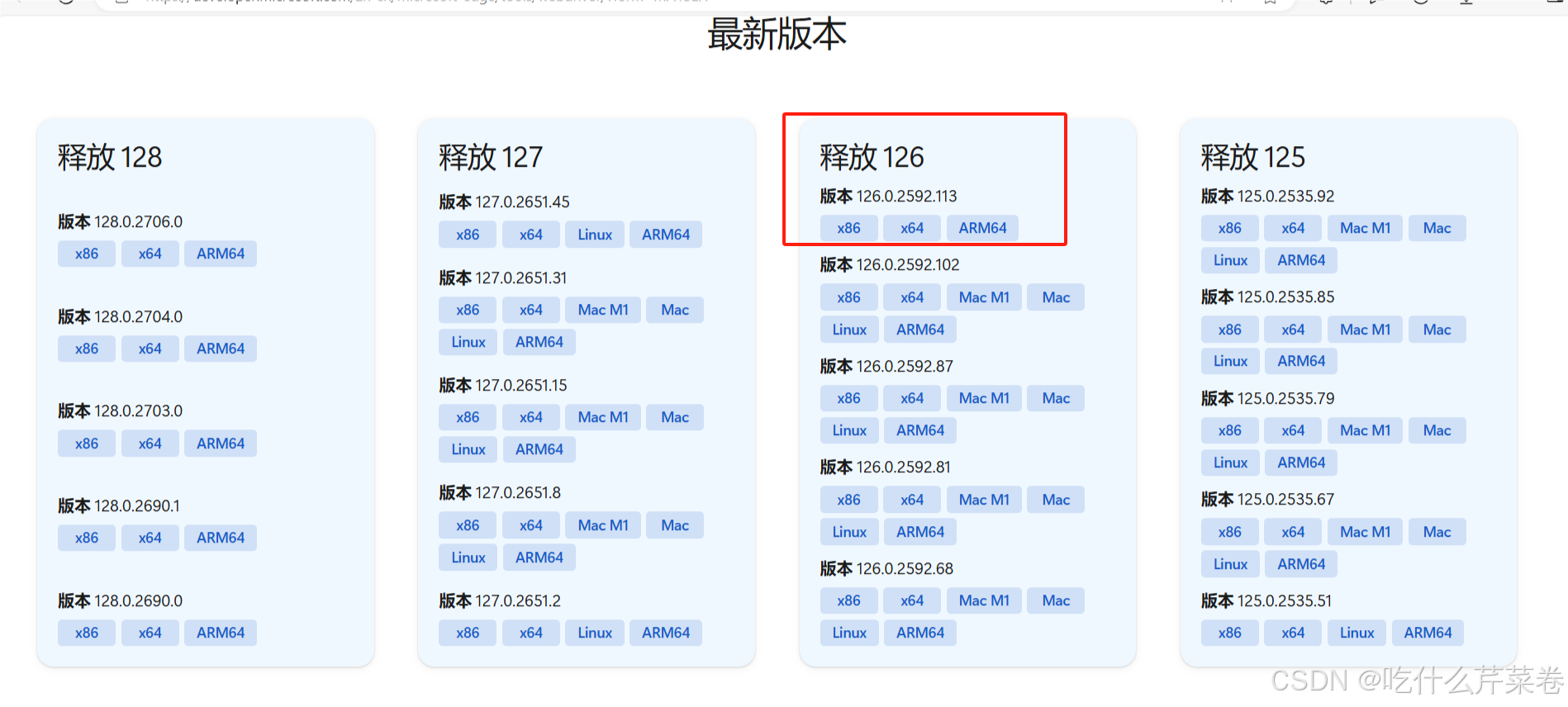
下载完之后将文件解压并移至python解释器所在的文件夹,上面的就是浏览器的驱动,下面的是python解释器。如果python解释器下载时环境变量没有配置好的可以看:0基础学python-1:python解释器的安装及环境配置-CSDN博客
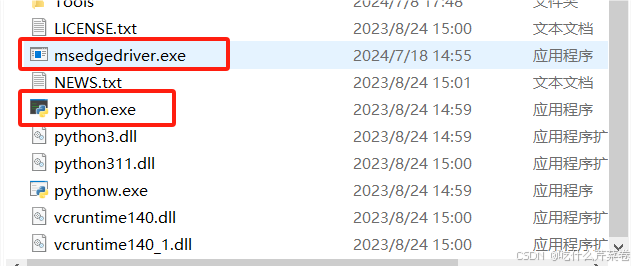
至此,技能前摇已完成。
三、爬虫四步走
1.UA伪装
这一次不用进行UA伪装,虚晃一枪,哈哈哈。实际原因是selenium请求是驱动浏览器自己进行操作,所以不需要UA伪装,但是有一些网站可能还是能检测到。
2.获取url
进入王者荣耀英雄列表的界面,按f12进入检查,刷新页面,然后获取url。
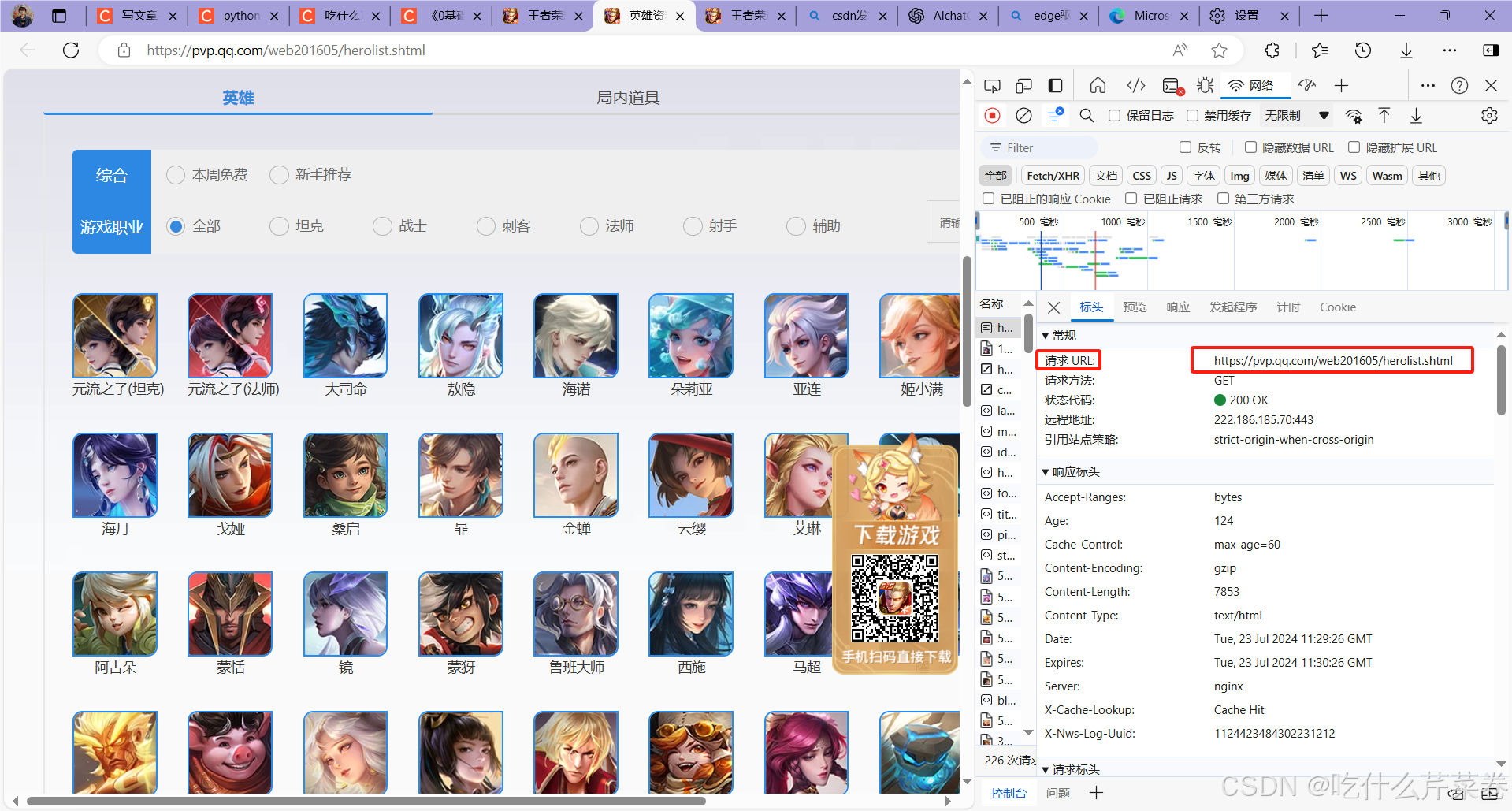
先展示一段selenium请求的效果,selenium会驱动浏览器自己去打开给定的url界面。这就意味着我们可以使用这种方式让浏览器自己进行更多的操作。
3.发送请求
流水的url,铁打的发送请求。不过这俩可以合并使用。
python
# 获取url并发送请求
driver.get("https://pvp.qq.com/web201605/herolist.shtml")4.获取响应数据进行解析并保存
- 睡眠三秒是为了等界面渲染完再获取信息,不然界面未渲染完就获取信息,会导致找不到信息,然后报错。
- WebDriverWait(driver, 10).until 的作用也是如此,前一个参数是等待的程序,后一个是等待的时间。
- EC.presence_of_element_located里是期望定位到的内容。定位到了就继续运行,未定位或者超出等待时间会报错。
- selenium里定位标签的方法是By,这里是通过XPATH进行定位,还有其他的参数可以进行定位,例如ID,ClASS_NAME之类的信息。
- find_elements获取ul标签下的所有li标签 ,find_element获取ul标签下第一个li标签。
- 然后就是熟悉的遍历li标签取值,在这里不需要用"./"来表示当前目录,而是直接写li标签下的标签。
- 还有一点不同的是,取标签里的属性这里不使用@属性名,而是用.get_attribute(''属性名'')来进行取值。
- 最后要关闭这个运行程序,使用.close()进行关闭
python
time.sleep(3)
WebDriverWait(driver, 10).until( # 等待程序运行10s,定位到英雄列表的位置则继续运行,未定位到则报错
EC.presence_of_element_located((By.XPATH, "//ul[@class='herolist clearfix']"))
)
# find_elements获取ul标签下的所有li标签 find_element获取该标签下第一个标签的内容
li_list = driver.find_elements(By.XPATH, "//ul[@class='herolist clearfix']/li")
for i in li_list:
img_url = i.find_element(By.XPATH, "a/img").get_attribute("src")
name = i.find_element(By.XPATH, "a/img").get_attribute("alt")
print(img_url, name)
driver.close()这样进行操作的时候,浏览器会打开王者荣耀英雄列表的界面,这样会占用一定资源。
那我们可以使用"无头模式"进行操作。更快更有效的利用资源
将这段代码
python
# 创建一个可以通过 Selenium 控制的 Microsoft Edge 浏览器实例,并将其赋值给变量 driver
driver = webdriver.Edge()替换成这样即可
python
from selenium.webdriver.edge.options import Options
# 无头模式
opt = Options()
opt.add_argument("--headless")
driver = webdriver.Edge(options=opt)总结
博主作为李白十年老玩家,就使用了李白的《行路难》里的一句诗当文章题目。
将进酒,杯莫停!
这句真的很帅啊!
希望大家使用我这个方法都能成功,如果有什么问题可以私信交流,或者直接在评论区询问即可。一起加油!