Today we show the full process of sentiment analysis using imdb dataset/
get data
python
# the saving path is home_path/.mindspore_examples
cache_dir = Path.home() / '.mindspore_examples'
def http_get(url:str, temp_file:IO)
req = requests.get(url, stream=True)
content_length = req.headers.get('Content-Length')
total = int(content_length) if content_length is not None else None
process = tqdm(unit ='B', total= total)
for chunk in req.iter_content(chunk_size =1024):
if chunk:
progress.update(len(chunk))
temp_file.write(chunk)
progress.close()
def download(file_name:str, url:str):
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
cache_path = os.path.join(cache_dir, file_name)
cache_exist = os.path.exists(cache_path)
if not cache_exist:
with tempfile.NameTemporaryFile() as temp_file:
http_get(url, temp_file)
temp_file.flush()
temp_file.seek(0)
with open(cache_path, 'wb') as cache_file:
shutil.copyfileobj(temp_file, cache_file)
return cache_path
imdb_path = download('aclImdb_v1.tar.gz','https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/aclImdb_v1.tar.gz')we load the pretrained word vector .
we use Glove to pretrain word vector.
python
def load_glove(glove_path):
glove_100d_path = os.path.join(cache_dir, 'glove.6B.100d.txt')
if not os.path.exists(glove_100d_path):
glove_zip = zipfile.ZipFile(glove_path)
glove_zip.extractall(cache_dir)
embeddings = []
tokens = []
with open(glove_100d_path, encoding='utf-8',)as gf:
for glove in gf:
word, embedding = glove.split(maxsplit = 1)
tokens.append(word)
embeddings.append(np.fromstring(embedding, dtype= np.float32, sep = ''))
#the <unk> and <pad>
embeddings.append(np.random.rand(100))
embeddings.append(np.zeros((100,),np.float32)
vocab = ds.text.Vocab.from_list(tokens, special_tokens = ['<unk>','<pad>'], special_first = False)
embeddings = np.array(embeddings).astype(np.float32)
return vocab, embeddings
glove_path = download('glove.6B.zip', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/glove.6B.zip')
vocab, embeddings = load_glove(glove_path)
#here an example to show how to transform the word to idx and query the corresponding word vector
#idx = vocab.tokens_to_ids('the')
#embedding = embeddings[idx]
#next we just process the dataset
lookup_op = ds.text.Lookup(vocab, unknown_token='<unk>')
pad_op = ds.transforms.PadEnd([500],pad_value = vocab.tokens_to_ids('<pad>'))
type_cast_op = ds.transform.TypeCast(ms.float32)
imdb_train = imdb_train.map(operations= [lookup_op, pad_op], input_columns=['text'])
imdb_train = imdb_train.map(operations= [type_cast_op], input_columns = ['label'])
imdb_test = imdb_test.map(operations = [lookup_op, pad_op], input_columns = ['text'])
imdb_test = imdb_test.map(operations = [type_cast_op], input_columns = ['label'])
#we seperate the dataset into training and validating parts
imdb_train, imdb_test = imdb_train.split([0.7,0.3])
imdb_train = imdb_train.batch(64,drop_remainder = True)
imdb_valid = imdb_valid.batch(64,drop_remainder = True)model:
nn.Embedding -> nn.RNN -> nn.Dense
Embedding layer : input as a vector but process it to get a matrix
RNN: recurrent neural network,
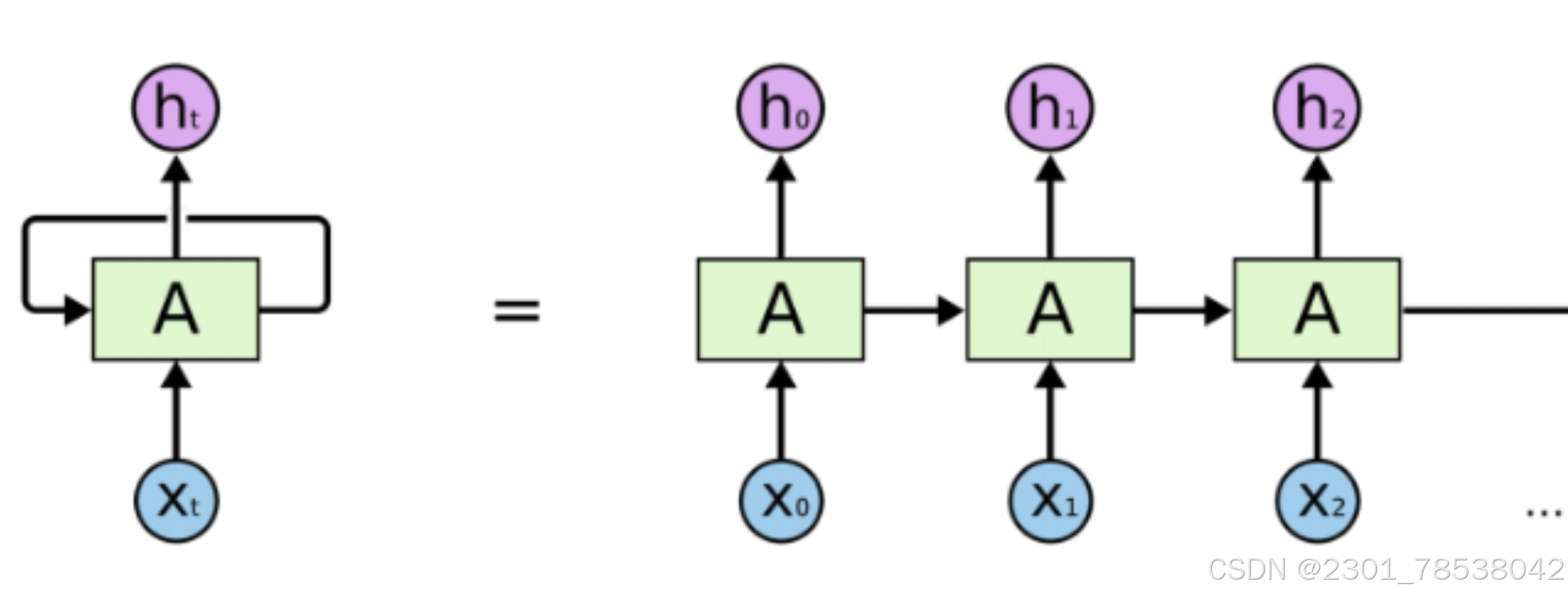
Problem: Gradient Vanishing means that the start of the sequence is missing after we arrive at the end
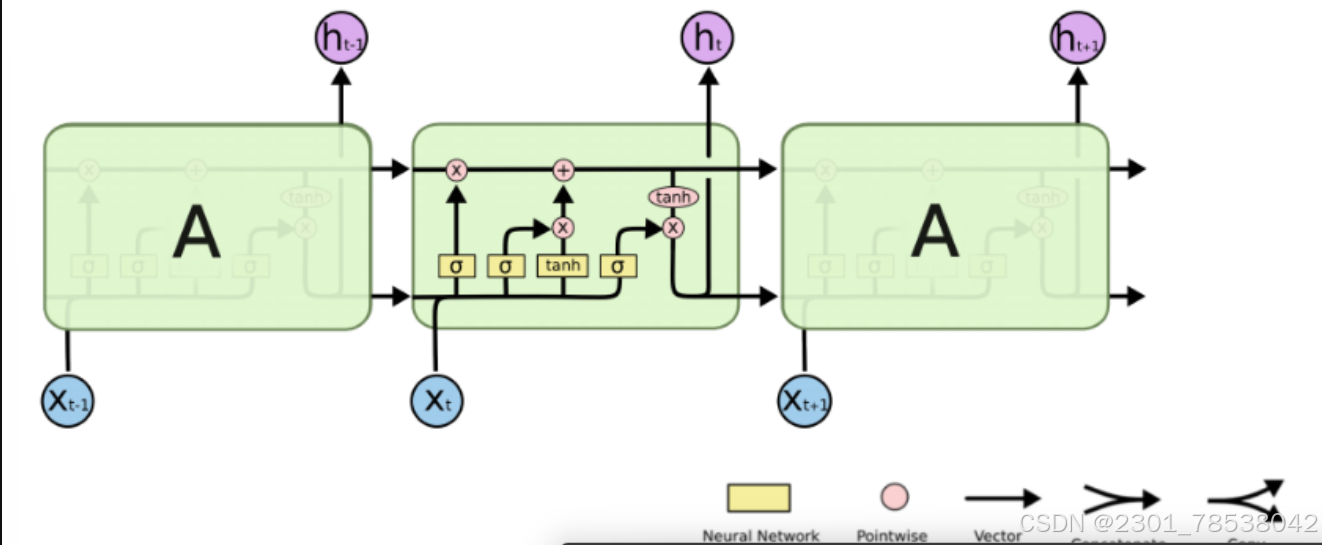
Solution: Gating Mechanism :control the dropping out and preserving of the information, called LSTM
python
class RNN(nn.Cell):
def __init__(self, embeddings, hidden_dim, output_dim, n_layers,
bidirection, pad_idx):
super().__init__()
vocab_size, embedding_dim = embeddings.shape
self.embedding = nn.Embedding(vocab_size, embedding_dim, embedding_table= ms.Temsor(embeddings), padding_idx = pax_idx)
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers = n_layers, bidirectional=bidirectional, batch_first = True)
weight_init = HeUniform(math.sqrt(5))
bias_init = Uniform(1/math.sqrt(hidden_dim*2))
self.fc = nn.Dense(hidden_dim * 2, output_dim, weight_init = weight_init, bias_init = bias_init)
def construct(self, inputs):
embedded = self.embedding(inputs)
_, (hidden,_) = self.rnn(embedded)
hidden = ops.concat((hidden[-2, :,:], hidden[-1:,:,:]), axis = 1)
return output
python
hidden_size = 256
output_size = 1
num_layers = 2
bidirectional = True
lr = 0.001
pad_idx = vocab.tokens_to_idx('<pad>')
model = RNN(embeddings, hidden_size, output_size, num_layers, bidirectional, pad_idx)
loss_fn = nn.BCEWithLogitsLoss(reduction = 'mean')
optimizer = nn.Adam(model.trainable_params(),learning_rate = lr)Below we define the train process.
python
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)
def train_step(data, label):
loss, grads = grad_fn(data,label)
optimier(grads)
return loss
def train_one_epoch(model, train_dataset, epoch = 0):
model.set_train()
total = train_dataset.get_dataset_size()
loss_total = 0
step_total = 0
with tqdm(total = total) as t:
t.set_description('Epoch %i' %epoch)
for i in train_dataset.create_tuple_iterator():
loss = train_step(*i)
loss_total += loss.asnumpy()
step_total += 1
t.set_postfix(loss=loss_total/ step_total)
t.update(1)evalute the accuracy of validation.
python
def binary_accuarcy(preds, y):
rounded_preds = np.around(ops.sigmoid(preds).asnumpy())
correct = (rounded_preds == y).astype(nn.float32)
acc = correct.sum()/len(correct)
return accthe validation process:
python
def evaluate(model, test_dataset, crierion, epoch = 0):
total = test_dataset.get_dataset_size()
epoch_loss = 0
epoch_acc = 0
step_total = 0
model.set_train(False)
with tqdm(total=total) as t:
t.set_description('Epoch %i' % epoch)
for i in test_dataset.create_tuple_iterator():
predictions = model(i[0])
loss = criterion(predicitons, i[1])
epoch_loss += loss.asnumpy()
acc = binary_accuarcy(predictions, i[1])
epoch_acc += acc
step_total += 1
t.set_postfix (loss = epoch_loss/step_total, acc = epoch_acc/step_total)
t.update(1)
return epoch_loss/totalokay.some routines:model saving and loading.
python
num_epochs = 2
best_valid_loss = float('inf')
ckpt_file_name = os.path.join(cache_dir, 'sentiment-analysis.ckpt')
for epoch in range(num_epochs):
train_one_epoch(model, imdb_train, epoch) #the imdb_train we defined previously
valid_loss = evaluate(model, imdb_valid, loss_fn, epoch)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
ms.save_checkpoint(model, ckpt_file_name)
param_dict = ms.load_checkpoint(ckpt_file_name)
ms.load_param_into_net(model, param_dict)Besides, we cam evaluate by the previous function.
python
imdb_test = imdb_test.batch(64)
evaluate(model, imdb_test, loss_fn)
socre_map = {
1: 'Positive',
0: 'Negative'
}
def predict_sentiment(model, vocab, sentence):
model.set_train(False)
tokenized = sentence.lower().split()
indexed = vocab.tokens_to_ids (tokenized)
tensor = ms.Tensor(indexed, ms.int32)
tensor = tensor.expand_dims(0)
prediction = model(tensor)
return score_map[int(np.round(ops.sigmoid(prediction).asnumpy()))]
##using the prediction func
predict_sentiment(model, vocab, 'This film is terrible')
#hope to get 'Negative'