
引言
蛋白质语言模型 (Protein Language Models, PLM) 已成为蛋白质结构与功能预测及设计的有力工具。在 2023 年国际机器学习会议 (ICML) 上,MILA 和英特尔实验室联合发布了ProtST模型,该模型是个可基于文本提示设计蛋白质的多模态模型。此后,ProtST 在研究界广受好评,不到一年的时间就积累了 40 多次引用,彰显了该工作的影响力。
- ProtSThttps://proceedings.mlr.press/v202/xu23t.html
PLM 最常见的任务之一是预测氨基酸序列的亚细胞位置。此时,用户输入一个氨基酸序列给模型,模型会输出一个标签,以指示该序列所处的亚细胞位置。论文表明,ProtST-ESM-1b 的零样本亚细胞定位性能优于最先进的少样本分类器 (如下图)。
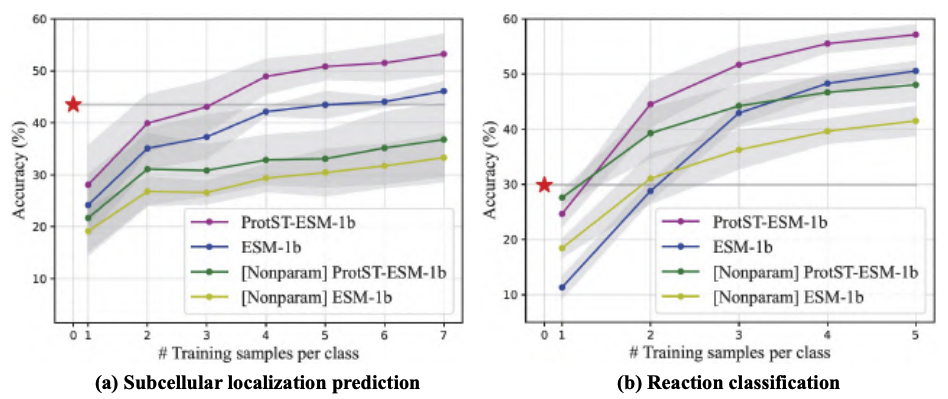
为了使 ProtST 更民主化,英特尔和 MILA 对模型进行了重写,以使大家可以通过 Hugging Face Hub 来使用模型。大家可于此处下载模型及数据集。
本文将展示如何使用英特尔 Gaudi 2 加速卡及 optimum-habana 开源库高效运行 ProtST 推理和微调。英特尔 Gaudi 2是英特尔设计的第二代 AI 加速卡。感兴趣的读者可参阅我们之前的博文,以深入了解该加速卡以及如何通过英特尔开发者云使用它。得益于optimum-habana,仅需少量的代码更改,用户即可将基于 transformers 的代码移植至 Gaudi 2。
-
英特尔 Gaudi 2https://habana.ai/products/gaudi2/
-
大语言模型快速推理:在 Habana Gaudi2 上推理 BLOOMZhttps://hf.co/blog/zh/habana-gaudi-2-bloom
-
英特尔开发者云https://cloud.intel.com
-
optimum-habanahttps://github.com/huggingface/optimum-habana
对 ProtST 进行推理
常见的亚细胞位置包括细胞核、细胞膜、细胞质、线粒体等,你可从此数据集中获取全面详细的位置介绍。
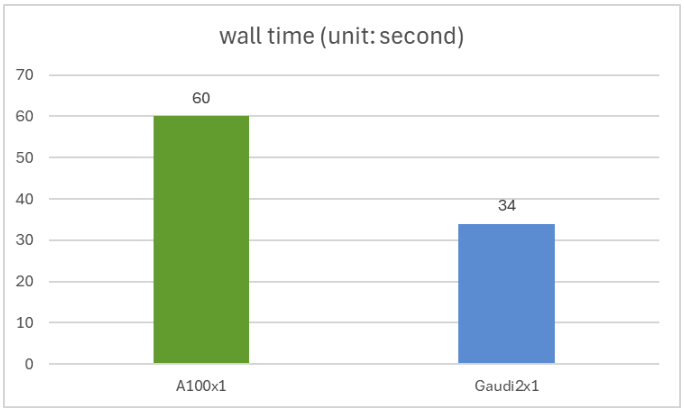
我们使用 ProtST-SubcellularLocalization 数据集的测试子集来比较 ProtST 在英伟达 A100 80GB PCIe 和 Gaudi 2 两种加速卡上的推理性能。该测试集包含 2772 个氨基酸序列,序列长度范围为 79 至 1999。
你可以使用此脚本重现我们的实验,我们以 bfloat16 精度和 batch size 1 运行模型。在英伟达 A100 和英特尔 Gaudi 2 上,我们获得了相同的准确率 (0.44),但 Gaudi 2 的推理速度比 A100 快 1.76 倍。单张 A100 和单张 Gaudi 2 的运行时间如下图所示。
微调 ProtST
针对下游任务对 ProtST 模型进行微调是提高模型准确性的简单且公认的方法。在本实验中,我们专门研究了针对二元定位任务的微调,其是亚细胞定位的简单版,任务用二元标签指示蛋白质是膜结合的还是可溶的。
你可使用此脚本重现我们的实验。其中,我们在ProtST-BinaryLocalization数据集上以 bfloat16 精度微调ProtST-ESM1b-for-sequential-classification。下表展示了不同硬件配置下测试子集的模型准确率,可以发现它们均与论文中发布的准确率 (~92.5%) 相当。
-
ProtST-BinaryLocalizationhttps://hf.co/datasets/mila-intel/ProtST-BinaryLocalization
-
ProtST-ESM1b-for-sequential-classificationhttps://hf.co/mila-intel/protst-esm1b-for-sequential-classification

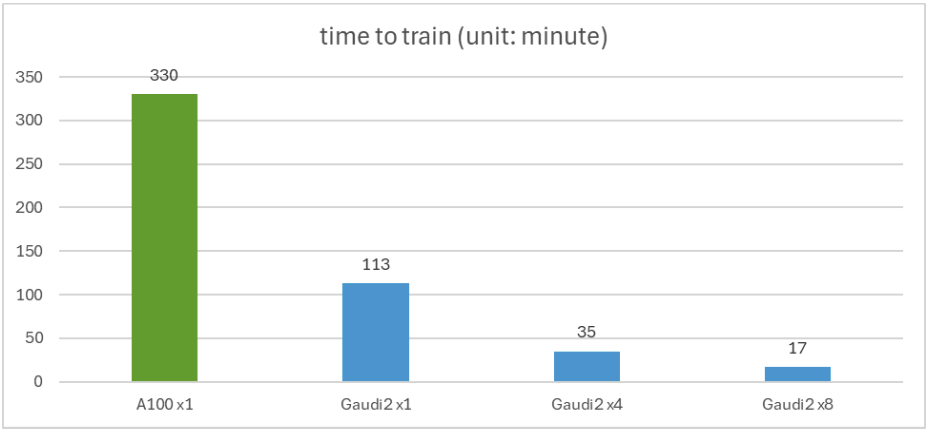
下图显示了微调所用的时间。可以看到,单张 Gaudi 2 比单张 A100 快 2.92 倍。该图还表明,在 4 张或 8 张 Gaudi 2 加速卡上使用分布式训练可以实现近线性扩展。
总结
本文,我们展示了如何基于 optimum-habana 轻松在 Gaudi 2 上部署 ProtST 推理和微调。此外,我们的结果还表明,与 A100 相比,Gaudi 2 在这些任务上的性能颇具竞争力: 推理速度提高了 1.76 倍,微调速度提高了 2.92 倍。
如你你想在英特尔 Gaudi 2 加速卡上开始一段模型之旅,以下资源可助你一臂之力:
-
optimum-habana代码库https://github.com/huggingface/optimum-habana
-
英特尔 Gaudi文档https://docs.habana.ai/en/latest/index.html
感谢垂阅!我们期待看到英特尔 Gaudi 2 加速的 ProtST 能助你创新。
英文原文: https://hf.co/blog/intel-protein-language-model-protst
原文作者: Julien Simon,Jiqing Feng,Santiago Miret,Xinyu Yuan,Yi Wang,Matrix Yao,Minghao Xu,Ke Ding
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。