在分类问题中,一个常见的难题是决定输出为数字时各类别之间的切分点。例如,一个神经网络的输出是介于0到1之间的数字,比如0.7,这是对应于正类(1)还是负类(0)?常识告诉我们使用0.5作为决策标记,但如果低估正类的风险较高怎么办?或者如果类别不平衡呢?

在这些情况下,正确估计切分点需要复审概率和贝叶斯理论。谈到概率时,有三条规则在后续过程中占据中心地位:

在考虑x和y作为两个事件时,x的概率是x与y的每个选项共同发生的概率之和。

这意味着x和y一起发生的概率等于在x发生的情况下y发生的概率乘以x发生的概率。

贝叶斯定理是一个非常强大的工具,它提供了一种在获得一些新信息后更新事件概率的方法(在本例中为事件y),这里的新信息用p(x|y)表示。更新后的概率为p(y|x)。
具体来说,p(y)被称为先验概率,即在获得新信息之前的y的概率;p(x|y)是在y存在的条件下发生新事件x的概率,这是关于系统的新数据或信息;而p(x)是事件x的边际概率,不考虑y的值。
贝叶斯定理可以用以下任何形式表达,这些形式都是从原始方程和上述两条规则衍生出来的:

为了说明贝叶斯定理的强大作用,我将用一个例子来展示。假设有一种疾病是事件Y(没有这种疾病是Y0,不幸患病是Y1);进行血液测试检测这种疾病并得到阳性结果是事件X。在整个人群中,患病的概率是一个很小的数字p(y)。关于这个测试,患病的人检测为阳性的概率是p(x|y);而无论是否真的患病,检测为阳性的人群比例是p(x),这包括了真正的阳性和假阳性。
我们来使用一些数字进行说明:
p(y) = 患病的概率,即整个人群中患病的人数:1/10,000 = 0.0001
p(x|y) = 如果有疾病,获得阳性测试的概率(测试本身的有效性):0.9 / 测试在90%的情况下能找到疾病
p(x) = 阳性测试的概率 / 这是接受测试并得到阳性结果的人数,不管他们是否真的生病:1/1000
应用贝叶斯定理后:p(y|x) = (0.9*0.0001)/(0.001) = 9%
这意味着即使测试结果为阳性,实际上患病的机会仍然很低,需要更多的测试来做出诊断。
应用贝叶斯定理后,这个个体患病的概率已经从1/10,000更新到了几乎1/10。

在现实中,这些测试,就像神经网络中回归和分类问题的数值结果一样,不是二元的,而是由一个连续变量组成。在这种情况下,问题在于如何"切割"结果并为结果分配正值或负值。常识是使用中点(例如,如果最后一层是softmax,就使用0.5),但这不是唯一的选择,也忽略了诸如不同风险或不平衡训练变量等问题。
在上面使用的例子中,考虑风险非常重要,因为得到假阳性(测试结果为阳性但实际上没有生病)只会带来进一步测试的小风险,但假阴性(实际生病但测试结果为阴性)意味着疾病的进一步传播和未能得到治疗。
接下来的图表显示了分布情况,蓝色代表健康个体的分布,红色代表患病个体的分布。X轴是测试结果(例如血液中的某种蛋白质xxx的值),Y轴是代表数量的值。由于这些是概率分布,它们被规范化,使得它们下面的面积总和为1。
importnumpyasnp
importmatplotlib.pyplotasplt
importscipy
#define mean and standard dev
mu, sg=10, 1
#serie of 100000 points
s=np.random.normal(mu, sigma, 100000)
#plot the histogram and create bins
count, bins, ignored=plt.hist(s, 500, density=True)
#standard distribution formula
defstandardDistribution(mu,sg,x):
y= (1/np.sqrt(2*np.pi*sg**2))*np.exp(-((x-mu)**2)/(2*sg**2))
returny
#prob distribution of negative test and values of test (x)
#for negative test
mu0, sg0=50, 15
x=np.arange(0.0, 150.0, 0.01)
probY0_X=standardDistribution(mu0,sg0,x)
#for positive test
mu1, sg1=100, 20
x=np.arange(0.0, 150.0, 0.01)
probY1_X=standardDistribution(mu1,sg1,x)
fig, (ax1, ax2) =plt.subplots(1, 2,sharex=True, sharey=True, figsize=(15,5))
ax1.plot(x, probY0_X, linewidth=2, color='b')
ax1.plot(x, probY1_X, linewidth=2, color='r')
ax1.set_title('The joined Y0 and Y1 with X')
ax2.plot(x, probY1_X+probY0_X, linewidth=2, color='g')
ax2.set_title('Probability of X')
如果我们对个体是否患病一无所知,将只看到绿色图表,这是测试结果的概率分布。我们可以直觉地看出有两个峰值,这对应于患病或健康情况的中位数。
在此过程中,我将假设两个分布都是正态的或接近正态,这将是大量随机样本的平均值的情况(中心极限定理)。
让我们详细回顾第一个图表,这会看到四个在我们的案例中感兴趣的区域:

真阳性:TP -> 好!准确识别类别
真阴性:TN -> 好!准确识别类别
假阴性:FN -> 坏!结果被归为类别0(在我们的例子中没有疾病),而实际上是类别1
假阳性:FP -> 坏!结果被归为类别1,而实际上属于类别0第3和第4区域的面积衡量结果的错误程度,因此,最小化这个错误函数是获得模型最佳结果的一个好方法:

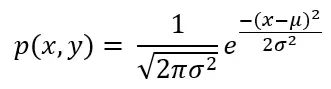
最后一个方程仅需要记住这些联合概率是高斯分布的。对于超过两个结果的情况,错误区域被推广为:

在这一点上,很容易引入偏差到错误中。比如在我们的例子中,对于"坏"结果,我们希望对假阴性进行惩罚。我们引入错误计算因子Rfn和Rfp来考虑它们各自的惩罚。

到这里,我们面临一个优化问题,需要找到错误区域函数的最小值。


积分的导数是高斯函数。
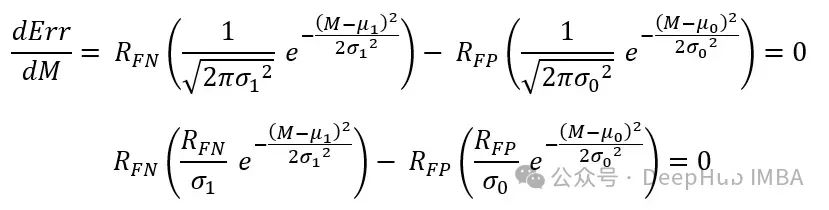
M 是切割点,它根据我们给每种错误类型分配的风险定义,最小化了错误。
下一步是解决这个最后的方程在 Python 中进行操作如下:
#formula to solve
#for negative test
mu0, sg0=50, 15
#for positive test
mu1, sg1=100, 20
deffunc(w):
r= (rFN/sg1)*(np.exp(-((w-mu1)**2)/(2*sg1**2))) - (rFP/sg0)*(np.exp(-((w-mu0)**2)/(2*sg0**2)))
returnr
#sol no penalty
rFN, rFP=1, 1
sol0=scipy.optimize.fsolve(func,x0=60)
#sol penalty 5:1
rFN, rFP=5, 1
sol1=scipy.optimize.fsolve(func,x0=60)
#sol penalty 10:1
rFN, rFP=10, 1
sol2=scipy.optimize.fsolve(func,x0=60)
#plot with the solutions
plt.figure(figsize=(12, 10))
plt.plot(x, probY0_X, linewidth=1, color='b', label='Y0 -> healthy')
plt.plot(x, probY1_X, linewidth=1, color='r', label='Y1 -> disease')
plt.axvline(x=sol0, color='black', ls='--', label='Cut, no penalty')
plt.axvline(x=sol1, color='gray', ls='--', label='Cut, penalty 1:5')
plt.axvline(x=sol2, color='brown', ls='--', label='Cut, penalty 1:10')
plt.legend(bbox_to_anchor=(1.0, 1), loc='upper left')
plt.show()
垂直线代表了不同权重或惩罚条件下最佳点M的不同解决方案;这说明了手动引入类别之间差异的影响。
应用贝叶斯定理,这些都是后验函数p(Y|X)上的相同结果:
#plot of p(Y|x) for Y0 and Y1
plt.figure(figsize=(12, 10))
plt.plot(x, probY0_X/(probY1_X+probY0_X), linewidth=1, color='b', label='Y0 -> healthy')
plt.plot(x, probY1_X/(probY1_X+probY0_X), linewidth=1, color='r', label='Y1 -> disease')
plt.axvline(x=sol0, color='black', ls='--', label='Cut, no penalty')
plt.axvline(x=sol1, color='gray', ls='--', label='Cut, penalty 1:5')
plt.axvline(x=sol2, color='brown', ls='--', label='Cut, penalty 1:10')
plt.legend(bbox_to_anchor=(1.0, 1), loc='upper left')
plt.show()
在现实生活中,对于机器学习,我们可以用三种不同的方式来处理这类优化问题:
- 使用 p(y,x),即 y 和 x 同时发生的概率,正如我上面所做的那样(这是两个分布:值为 x 时有病和没病的概率),用于训练集。然后确定最佳切割点。
- 使用后验概率 p(Y|X);这是给定测试结果后有病的概率,作为数据。切割点同样作为一个优化问题来确定。
- 训练一个直接输出二元结果的分类模型,在训练集中确保标签考虑到不同的风险,或者在类别不平衡的情况下进行重采样。这种方法可能更快,但它有几个缺点,例如,它不能提供关于可能因素的多信息(现实生活中的问题通常是多变量的),去除了手动考虑风险的可能性,也无法拒绝置信度低的结果(接近决策点的结果)。
在机器学习中,解决分类问题和优化决策阈值是一个复杂但至关重要的任务。通过应用贝叶斯定理和考虑不同的优化方法,我们可以更有效地处理这些挑战。在这篇文章中,我们探讨了使用联合概率p(y,x)和后验概率p(Y|X)来确定最佳切割点的两种方法,以及直接训练二元输出分类模型的方法。
每种方法都有其优势和局限性。使用p(y,x)和p(Y|X)可以让我们更精确地根据实际数据和模型的特定需求调整分类阈值,但这需要复杂的统计处理和对概率理论的深入理解。直接训练分类模型则操作简单快速,但可能缺乏灵活性,特别是在处理不平衡数据集和评估风险时。是在需要快速反馈的应用中非常实用。不过,这种快速和便捷可能会以牺牲深入分析和全面理解为代价。
因此,选择最合适的方法应基于具体问题的需求、数据的特性以及预期的应用场景。在实际操作中,可能还需要综合多种方法,以达到最佳的性能和准确度。在决定最佳方法时,考虑到风险和类别不平衡的因素也是至关重要的。这样的多维度考虑,可以帮助研究者和工程师们在现实世界的复杂问题中找到最有效的解决策略。
https://avoid.overfit.cn/post/5890a105ddf94dcd8ee3388283b8f112
作者:Greg Postalian-Yrausquin