文本到 SQL
让我们构建一个简单的应用程序,帮助用户使用自然语言创建 SQL 查询。
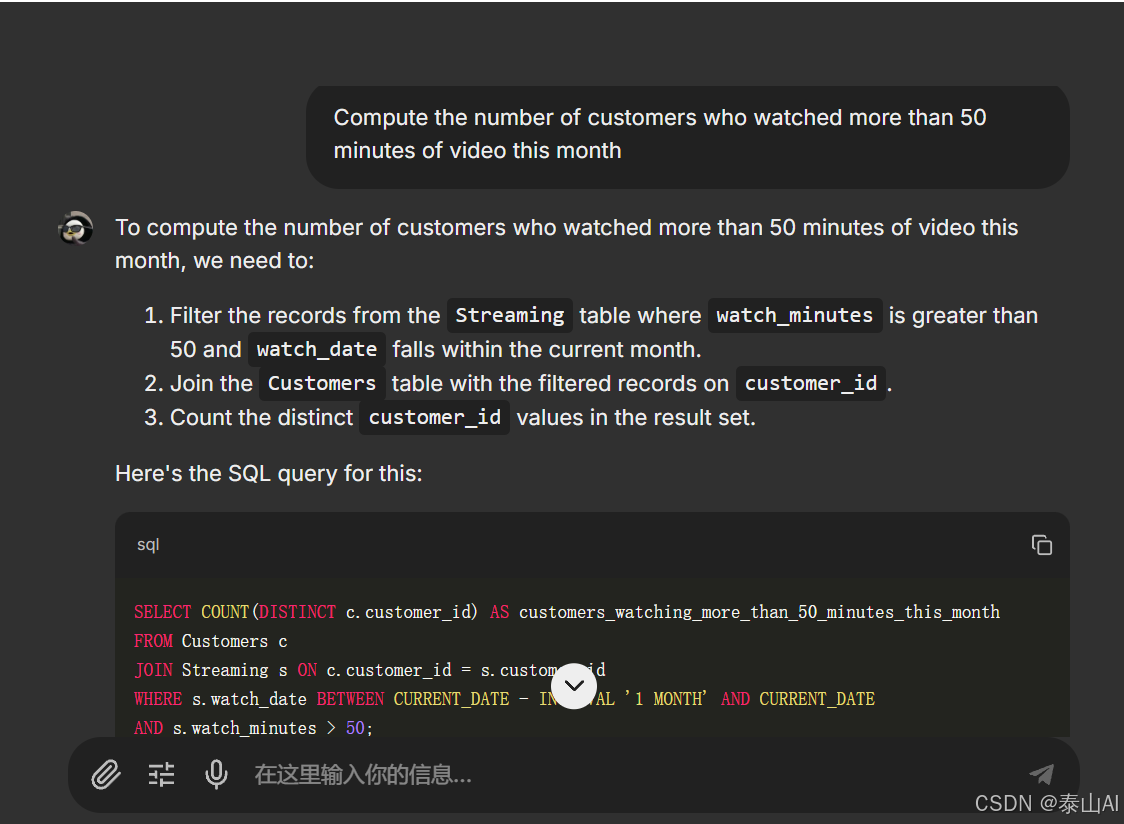
最终结果预览
先决条件
此示例有额外的依赖项。你可以使用以下命令安装它们:
bash
pip install chainlit openai
导入
应用程序
bash
from openai import AsyncOpenAI
import chainlit as cl
cl.instrument_openai()
client = AsyncOpenAI(api_key="YOUR_OPENAI_API_KEY")
定义提示模板和 LLM 设置
代码
bash
template = """SQL tables (and columns):
* Customers(customer_id, signup_date)
* Streaming(customer_id, video_id, watch_date, watch_minutes)
A well-written SQL query that {input}:
```"""
settings = {
"model": "gpt-3.5-turbo",
"temperature": 0,
"max_tokens": 500,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"stop": ["```"],
}添加辅助逻辑
在这里,我们用@on_message main装饰器装饰该函数,以告诉 Chainlit在每次用户发送消息时运行该main函数。
然后,我们在步骤中将文本包装到 SQL 逻辑中。
应用程序
bash
@cl.set_starters
async def starters():
return [
cl.Starter(
label=">50 minutes watched",
message="Compute the number of customers who watched more than 50 minutes of video this month."
)
]
@cl.on_message
async def main(message: cl.Message):
stream = await client.chat.completions.create(
messages=[
{
"role": "user",
"content": template.format(input=message.content),
}
], stream=True, **settings
)
msg = await cl.Message(content="", language="sql").send()
async for part in stream:
if token := part.choices[0].delta.content or "":
await msg.stream_token(token)
await msg.update()完整代码如下:
bash
import base64
from io import BytesIO
from pathlib import Path
import chainlit as cl
from chainlit.element import ElementBased
from chainlit.input_widget import Select, Slider, Switch, TextInput
from openai import AsyncOpenAI
client = AsyncOpenAI()
author = "Tarzan"
template = """SQL tables (and columns):
* Customers(customer_id, signup_date)
* Streaming(customer_id, video_id, watch_date, watch_minutes)
A well-written SQL query that {input}:
```"""
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
@cl.on_settings_update
async def on_settings_update(settings: cl.chat_settings):
cl.user_session.set("settings", settings)
@cl.step(type="tool")
async def tool():
# Simulate a running task
await cl.sleep(2)
return "Response from the tool!"
@cl.on_chat_start
async def start_chat():
settings = await cl.ChatSettings(
[TextInput(id="SystemPrompt", label="System Prompt", initial="You are a helpful assistant."),
Select(
id="Model",
label="Model",
values=["qwen-turbo", "qwen-plus", "qwen-max", "qwen-long"],
initial_index=0,
),
Slider(
id="Temperature",
label="Temperature",
initial=1,
min=0,
max=2,
step=0.1,
),
Slider(
id="MaxTokens",
label="MaxTokens",
initial=1000,
min=1000,
max=3000,
step=100,
),
Switch(id="Streaming", label="Stream Tokens", initial=True),
]
).send()
cl.user_session.set("settings", settings)
cl.user_session.set(
"message_history",
[{"role": "system", "content": settings["SystemPrompt"]}],
)
content = "你好,我是泰山AI智能客服,有什么可以帮助您吗?"
msg = cl.Message(content=content, author=author)
await msg.send()
@cl.on_message
async def on_message(message: cl.Message):
settings = cl.user_session.get("settings")
print('settings', settings)
streaming = settings['Streaming']
model = settings['Model']
images = [file for file in message.elements if "image" in file.mime]
files = [file for file in message.elements if "application" in file.mime]
messages = cl.user_session.get("message_history")
if files:
files = files[:3]
file_ids = []
for file in files:
file_object = await client.files.create(file=Path(file.path), purpose="file-extract")
file_ids.append(f"fileid://{file_object.id}")
flies_content = {
"role": "system",
"content": ",".join(file_ids)
}
messages.append(flies_content)
if images and model in ["qwen-plus", "qwen-max"]:
# Only process the first 3 images
images = images[:3]
images_content = [
{
"type": "image_url",
"image_url": {
"url": f"data:{image.mime};base64,{encode_image(image.path)}"
},
}
for image in images
]
model = "qwen-vl" + model[4:]
img_message = [
{
"role": "user",
"content": [{"type": "text", "text": message.content}, *images_content],
}
]
messages = messages + img_message
msg = cl.Message(content="", author=author)
await msg.send()
# Call the tool
# tool_res = await tool
messages.append({"role": "user", "content": template.format(input=message.content)})
print('messages', messages)
response = await client.chat.completions.create(
model=model,
messages=messages,
temperature=settings['Temperature'],
max_tokens=int(settings['MaxTokens']),
stream=streaming
)
if streaming:
async for part in response:
if token := part.choices[0].delta.content or "":
await msg.stream_token(token)
else:
if token := response.choices[0].message.content or "":
await msg.stream_token(token)
print('messages', messages)
messages.append({"role": "assistant", "content": msg.content})
cl.user_session.set("message_history", messages)
await msg.update()试试看
bash
chainlit run .\text2sql.py -w您可以提出类似这样的问题Compute the number of customers who watched more than 50 minutes of video this month。