系列文章目录
` 提示:仅用于个人学习,进行查漏补缺。
1.Linux介绍、目录结构、文件基本属性、Shell
2.Linux常用命令
3.Linux文件管理
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本章内容有:
Linux目录结构
Linux查看及检索命令
Linux压缩及解压缩文件
vim文本编辑器知识
提示:以下是本篇文章正文内容,下面案例可供参考
1.Linux目录结构
- 用CentOS7举例:登录系统后,在当前命令窗口下输入命令ls :

- 树状目录结构:
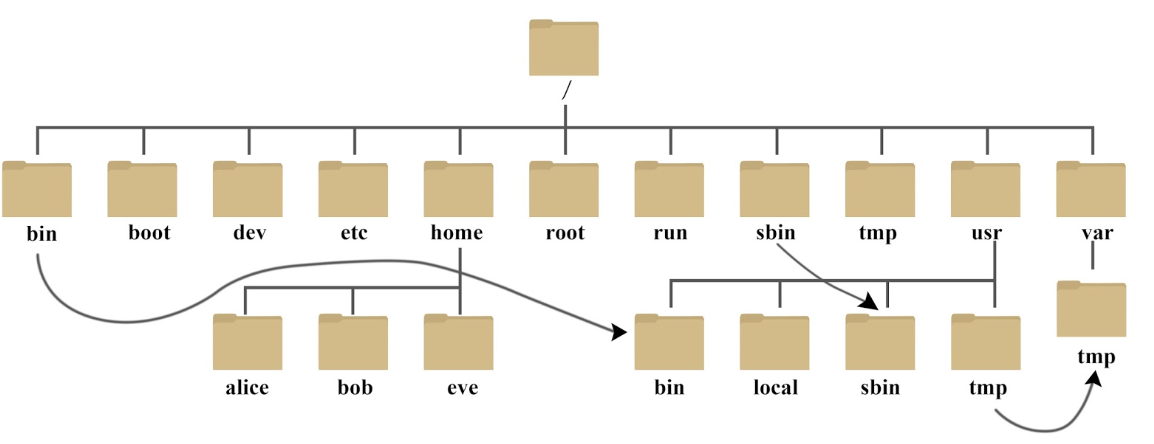
- /mnt:临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。
临时文件:
- /run:是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。
- /lost+found:一般情况下为空的,系统非法关机后,这里就存放一些文件。
- /tmp:这个目录是用来存放一些临时文件的。
账户:
- /root:系统管理员的用户主目录。
- /home:用户的主目录,以用户的账号命名的。
- /usr:用户的很多应用程序和文件都放在这个目录下,类似于windows下的program files目录。
- **/usr/bin:**系统用户使用的应用程序与指令。
- **/usr/sbin:**超级用户使用的比较高级的管理程序和系统守护程序。
- **/usr/src:**内核源代码默认的放置目录。
运行过程中要用:
- /var:存放经常修改的数据,比如程序运行的日志文件(/var/log 目录下)。
- /proc:管理**内存空间!**虚拟的目录,是系统内存的映射,我们可以直接访问这个目录来,获取系统信息。这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件来做修改。
扩展用的:
- /opt:默认是空的,我们安装额外软件可以放在这个里面。
- /srv:存放服务启动后需要提取的数据**(不用服务器就是空)**
补充:
- Linux的这种目录结构设计为系统的稳定性和可管理性提供了良好的基础。不同的目录服务于不同的目的,有助于系统的维护和故障排除。
- 在 Linux 系统中,有几个目录是比较重要的,平时需要注意不要误删除或者随意更改内部文件。
- /etc: 上边也提到了,这个是系统中的配置文件,如果你更改了该目录下的某个文件可能会导致系统不能启动。
- /bin, /sbin, /usr/bin, /usr/sbin : 这是系统预设的执行文件的放置目录,比如 ls 就是在 /bin/ls 目录下的。
值得提出的是 /bin 、/usr/bin 是给系统用户使用的指令(除 root 外的通用用户),而/sbin, /usr/sbin 则是给 root 使用的指令。
- /var: 这是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在 /var/log 目录下,另外 mail 的预设放置也是在这里。
2.查看及检索文件命令
- **cat **(用于查看文件内容或者创建、合并文件)
- 基本用法:
bash
cat [选项] [文件]...-
选项 :
-A或--show-all:显示所有字符,包括不可见的字符(如换行符、制表符等)。-b或--number-nonblank:对非空输出行编号,空白行不编号。-e:在每行结束处显示$。-E或--show-ends:在每行结束处显示$,即使该行是空的。-n或--number:对所有输出的行编号,包括空白行。-s或--squeeze-blank:当遇到连续多个空白行时,只输出一个。 --T或--show-tabs:将制表符显示为^I。-u或--show-nonprinting:显示不可打印的字符。-v或--show-nonprinting:与-u相似,但使用^和M-表示字符。
-
示例:
- **cat filename **查看文件内容
- cat file1 file2 将两个文件合并输出
- cat file1 file2 > outputfile 将输出重定向到另一个文件
- cat -n file 查看文件内容并显示行号
- cat -A file 显示不可见字符
- cat > filename 从标准输入创建文件
- cat file1 file2 | cat -E > outputfile 合并多个文件到一个文件,并在输出行后添加
$
-
**more **(一个文本文件的分页查看器,它允许用户以一页一页的形式逐页浏览文件内容)
- 基本用法:
bash
more [选项] [文件]...-
选项:
-d或--debug:打印调试信息。-f或--file=文件:从指定文件中读取输入。-l或--literal:按字面意思显示特殊字符,而不进行转义。-p或--prompt=提示符:使用指定的提示符而不是默认的 "more> "。-s或--ignore-case:忽略大小写的搜索。-u或--scroll=行数:当文件内容超过指定行数时,自动滚动到下一页。-w或--width=行数:将屏幕分割成指定行数的宽度。
-
示例 :
- more file: 逐页查看文件内容:
- **more --prompt='==> ' file **使用特定的提示符
- **cat file | more ** 从标准输入读取内容
- more -u 10 file 自动滚动,当内容超过10行
-
注意 :
more命令在文件结束时自动退出。- 如果文件内容超过屏幕的可见行数,可以使用
空格键向下滚动,使用b键向上滚动。 more命令不支持在文件中直接进行编辑操作。
-
** less **(一个文本文件的分页查看器,它提供了比
more命令更丰富的导航和搜索功能,允许用户以一页一页的形式逐页浏览文件内容,或者向下滚动查看文件)- 基本用法:
bash
less [选项] [文件]...-
选项:
-d或--debug:打印调试信息。-f或--quit-if-one-screen:如果文件内容不超过一屏,则退出。-i或--ignore-case:忽略大小写的搜索。-N或--line-numbers:显示行号。-o或--output=文件:将输出发送到指定文件而不是标准输出。-s或--squeeze-repeats:合并连续重复的行。-S或--ignore-space:将长的行分割成多行显示,而不是截断。-t或--initial-title=标题:设置初始窗口标题。-v或--version:显示版本信息。
-
快捷键:
空格键:向下滚动一页。b:向上滚动一页。f:向前移动一页。d或/:向下搜索特定字符串。n:搜索下一个匹配项。N:搜索上一个匹配项。q或x:退出less。G:跳转到文件末尾。g:跳转到文件开头。
-
示例:
- ** less file **逐页查看内容
- ** less -N file** 显示行号
- cat file | less 从标准输入读取内容
- less -t "My File" file 使用特定的标题
-
补充:
less命令在文件结束时不会自动退出,用户需要按q键或x键退出。less命令支持在文件中直接进行编辑操作,如使用:w命令保存文件。less命令比more命令提供更多的导航和搜索功能,更适合处理大型文件。
-
** head **(用于显示文件的开头部分)
- 基本用法:
bash
head [选项] [文件]...-
选项:
-c或--bytes=字节数:显示前n个字节。-n或--lines=行数:显示前n行。-q或--quiet:不显示文件名。-v或--verbose:显示文件名和字节数。-z或--zero:将空字节视为字符NUL。
-
示例:
- head -n 10 file 显示文件的前 10 行
- head -c 500 file 显示文件的前 500 个字节
- ** head -q file ** 不显示文件名,只显示内容
-
补充:
- 如果没有任何文件名作为参数,
head命令将从标准输入读取,并显示该输入的前n行或n个字节。 head命令默认显示前 10 行。- 使用
-n选项时,如果不指定行数,head将显示所有行。
- 如果没有任何文件名作为参数,
-
** tail(用于显示文件的最后部分。与
head命令相反,tail命令可以用来查看文件的最新内容,尤其是在 处理日志文件 时非常有用)**- 基本用法:
bash
tail [选项] [文件]...-
选项:
**-c**或--bytes=字节数:显示最后n个字节。**-f**或--follow:实时跟踪文件的最新变化。**-n**或--lines=行数:显示最后n行。**-q**或--quiet:不显示文件名。**-v**或--verbose:显示文件名和字节数。**-k**或--kilobytes=KB数:显示指定KB数的最后内容。
-
示例:
- ** tail -n 10 file **显示文件的最后 10 行
- ** tail -f file **实时跟踪文件的最新变化
- ** tail -c 500 file 显示文件的最后 500 个字节 **
- ** tail -q file **不显示文件名,只显示内容
- ** tail -n 100 file **显示最后 100 行
-
补充:
- 如果没有任何文件名作为参数,
tail命令将从标准输入读取,并显示该输入的最后n行或n个字节。 tail命令默认显示最后 10 行。- 使用
-f选项时,tail将实时监控文件变化,并在文件被修改后自动刷新内容。 - 在使用
-f选项时,可以通过Ctrl+C组合键来终止实时监控。 tail命令是一个非常实用的工具,尤其是在监控日志文件或查看文件的最新变化时。通过它,可以快速查看文件的最新内容,而不必浏览整个文件。
- 如果没有任何文件名作为参数,
-
** grep**(一个非常强大的文本搜索工具,用于在文件中搜索与指定模式匹配的行。
grep支持正则表达式,并且可以应用于单个文件或一组文件,甚至标准输入)- 基本用法:
bash
grep [选项] 模式 [文件...]- 选项:【正则表达式中三剑客之一】
**-c**:只显示匹配模式的行数,不显示实际的行。**-i**:忽略大小写差异。 【默认】**-v**:反转匹配,显示不匹配模式的行。**-n**:显示匹配行的行号。**-l**:只列出包含匹配模式的文件名。**-r**或-R:递归搜索目录。-H:即使只搜索一个文件,也在输出前加上文件名。-A 数字:显示匹配行之后的额外数字行。-B 数字:显示匹配行之前的额外数字行。-C 数字或--context数字:显示匹配行以及前后各数字行。-e:指定一个模式。如果有多个模式,可以多次使用-e。**-f**:从文件中读取模式列表。**-E**:启用扩展正则表达式。-F:将模式视为固定字符串,而不是正则表达式。-m 数字:找到数字次匹配后停止。-w:匹配整个单词,模式必须与整个单词匹配,而不仅仅是单词的一部分。
- 示例:
- **grep "example" file.txt **搜索文件中的模式,搜索
file.txt文件中包含 "example" 这个文本的行,并显示匹配的行 - **grep -i "example" file.txt **忽略大小写,将搜索
file.txt中的"example"、"Example"等所有大小写组合 - **grep -n "example" file.txt ** 显示匹配行的行号,每个匹配的行前面都会显示其行号。
- grep "example" file1.txt file2.txt file3.txt 在多个文件中搜索,在
file1.txt、file2.txt和file3.txt这三个文件中搜索包含 "example" 的行,并将所有匹配的行显示出来 - **grep -r "example" /path/to/directory **递归搜索目录中的文件,显示目录中所有匹配 "example" 的文件和行
- **grep -E "exaa-z" file.txt **使用正则表达式搜索,模式 "exaa-z" 会匹配以 "exa" 开头,后跟一个或多个小写字母的文本。例如,这会匹配 "example"、"exact"、"examine" 等
- **grep "example" file.txt **搜索文件中的模式,搜索
- 查找条件设置:
- 要查找的字符串以双引号括起来
- "^..." 表示以...开头
- "...$" 表示以...结尾
- "^$" 表示空行
- 举例:
- **grep -ie "^listen" -e "80$" /etc/httpd/conf/httpd.conf **
- 要查找的字符串以双引号括起来
在 /etc/httpd/conf/httpd.conf 文件中,grep 会搜索所有以 "listen" 开头的行,以及所有以 "80" 结尾的行,并且在搜索时忽略字母的大小写。匹配的行会被 grep 输出到标准输出(通常是终端屏幕)。
- 补充:
grep命令默认不区分大小写,如果需要区分大小写,需要明确指定-i选项。- 正则表达式在
grep中的应用非常广泛,可以根据需要灵活地匹配文本模式。 grep命令是文本处理中的一个重要工具,可以通过组合使用不同的选项和正则表达式来执行复杂的文本搜索任务。grep命令在文本处理和日志分析中非常常用,它能够帮助用户快速地找到文件中的特定内容。
3.压缩及解压缩文件
- **tar命令 **
- 作用:
- 通常用于_打包文件_,但它也可以与压缩工具结合使用来压缩文件。
- tar命令本身并不压缩数据,但可以通过添加相应的选项与gzip、bzip2或xz等压缩工具配合使用。
- 压缩语法:
- 作用:
abap
tar [-cvzf] 文件名.tar.gz 需要压缩的文件或目录
tar [-cvjf] 文件名.tar.bz2 需要压缩的文件或目录
tar [-cvJf] 文件名.tar.xz 需要压缩的文件或目录 - `-c` 表示创建压缩文件
- `-v` 表示在压缩时显示详细信息
- `-z` 表示使用gzip进行压缩
- `-j` 表示使用bzip2进行压缩
- `-J` 表示使用xz进行压缩
- `-f` 表示指定压缩后的文件名(归档)
- **tar -cvzf backup.tar.gz ./test/** 将当前目录下的`test`文件夹压缩为`backup.tar.gz`
- **解压缩语法:**
tar [-xzvf] 文件名.tar.gz
tar [-xjf] 文件名.tar.bz2
tar [-xJf] 文件名.tar.xz
- `-x` 表示解压缩
- `-z`、`-j`、`-J` 分别对应gzip、bzip2、xz的解压缩选项
- `-v` 表示在解压缩时显示详细信息
- `-f` 表示指定压缩文件名
- **tar -xzvf backup.tar.gz **解压缩`backup.tar.gz`文件-
gzi命令
-
作用: gzip是一个单独的压缩工具,通常用于压缩单个文件。
-
语法:
gzip [-c] 文件名
- `-c` 表示将压缩结果输出到标准输出而不改变源文件 - **gzip test.txt **压缩`test.txt`文件 - **gunzip test.txt.gz **解压缩`test.txt.gz`文件
-
-
bzip2命令
-
**作用:**bzip2命令 bzip2与gzip类似,但通常提供更好的压缩率。
-
语法:
bzip2 [-c] 文件名
- ** bzip2 test.txt **压缩`test.txt`文件 - **bunzip2 test.txt.bz2 **解压缩`test.txt.bz2`文件 <br /> 
-
-
补充:
- **压缩级别:**许多压缩工具都允许指定压缩级别,通常是一个从1(最快,压缩比最低)到9(最慢,压缩比最高)的数字。例如,gzip可以用
-1到-9的选项指定压缩级别。 - **压缩后的文件处理:**一些工具允许在压缩后删除原始文件,例如gzip可以使用
-f选项。 - **分卷压缩:**对于非常大的文件,可以使用分卷压缩。例如,gzip可以用
-c选项将输出重定向到分卷文件。
- **压缩级别:**许多压缩工具都允许指定压缩级别,通常是一个从1(最快,压缩比最低)到9(最慢,压缩比最高)的数字。例如,gzip可以用
文本编辑器
概述
- Vim 是一种改进版的 Vi 编辑器,它是一个非常强大的文本编辑器,广泛用于程序开发、脚本编写和配置文件编辑。模式
1. **正常模式**(Normal mode):这是 Vim 启动时的默认模式,用户可以在这个模式下使用快捷键导航文本、删除字符或行、复制和粘贴文本等。
2. **插入模式**(Insert mode):在这个模式下,用户可以插入新文本。可以通过按 `i`(插入)、`I`(插入到行首)、`a`(追加)、`A`(追加到行尾)等键进入插入模式。
3. **命令行模式**(Command-line mode):按下 `:` 进入命令行模式,这里可以执行各种命令,如保存(`:w`)、退出(`:q`)、搜索(`:search_pattern`)等。
4. **可视模式**(Visual mode):按下 `v` 或 `V` 进入可视模式,可以选择文本块进行操作。快捷键和命令
- 移动 :
h、j、k、l:左、下、上、右移动。^:移动到行首。$:移动到行尾。G:移动到文件末尾。gg:移动到文件开头。
- 编辑 :
x:删除光标下的字符。dd:删除整行。p:粘贴文本。u:撤销操作。Ctrl + r:重做撤销。
- 搜索 :
/pattern:搜索pattern。n:搜索下一个匹配项。N:搜索上一个匹配项。
- 保存和退出 :
:w:保存文件。:q:退出编辑器。:wq:保存并退出编辑器。:q!:强制退出,不保存更改。
- 文本内容替换:
