想用服务器训练AI模型不少AI开发者都会陷入"看会操作、动手就崩"的困境:记混服务器连接命令、环境配置反复报错、训练时显存不足无措------纯视频学习只给流程演示,缺逻辑拆解和实操反馈,很难真正落地。我们需要通过视频内容快速提炼视频核心,为此我梳理了一套方法论:"服务器获取→连接操作→环境配置→模型训练→结果下载"。
纯看视频的3大核心痛点
- 路径模糊:视频提及云服务器与本地服务器两种途径,却未讲清适配场景,新手易盲目选型,导致显存不足、成本超支等问题。
- 命令与实操脱节:Linux命令、SSH连接、文件上传等操作一闪而过,记混参数顺序(如
scp本地与服务器路径),报错后无从排查。 - 环境与训练踩坑:AI框架版本与GPU适配、依赖冲突等细节被忽略,配置环境耗时长,训练中显存不足、程序中断等问题无应对方案。
5大学习路径
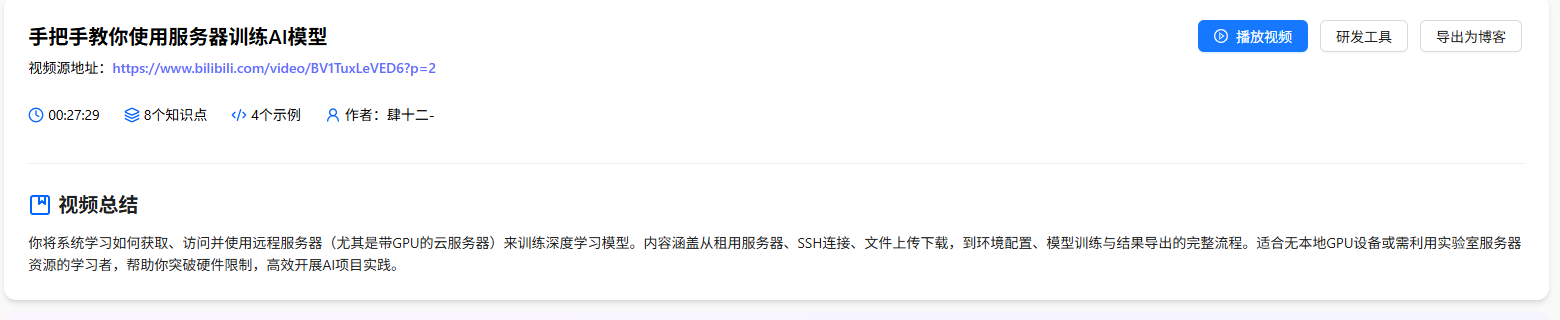
1. 服务器选型:明确适配场景
AI自动提炼视频知识点,生成精简对比表,帮你快速决策,避免盲目跟风:
|------|-------------------|-----------------------|
| 维度 | 云服务器(阿里云/腾讯云) | 本地服务器(自组装) |
| 优势 | 弹性扩容、无需硬件维护、低成本入门 | 性价比高、无网络依赖、性能自定义 |
| 适用场景 | 入门学习、小批量模型训练 | 大规模训练、长期稳定使用 |
| 入门配置 | 16GB内存+4-8GB GPU | RTX 3090(24GB)+32GB内存 |
AI还生成针对性思考题:"训练ResNet-50(需8GB显存),月预算100元内,选哪种服务器?" 并关联视频知识点给出答案,强化选型逻辑。
2. 服务器连接:在线模拟实操
AI提供模拟终端,还原SSH连接场景,实时反馈报错原因,不用真实服务器也能练熟操作:
# 核心命令(AI标注参数含义与常见坑)
ssh root@服务器IP -p 22 # -p指定端口,默认22可省略
# 报错提示:Connection refused→检查端口是否开放、SSH服务是否启动模拟环境会针对性纠错,比如输错端口时,直接关联视频知识点提示"SSH默认端口为22,非FTP的21",快速建立操作记忆。
3. 文件上传与Linux基础:场景化练习
聚焦视频核心命令,以"上传训练数据集"为任务,帮你掌握关键操作:
# 上传文件夹(AI标注-r参数必加,递归上传)
scp -r 本地路径 root@服务器IP:/目标目录
# 服务器端基础操作
mkdir /home/ai/logs # 创建日志文件夹
rm -rf /tmp/无用文件 # 强制删除冗余文件练习中漏加参数或路径错误,AI会即时提示解决方案,避免记混用法。
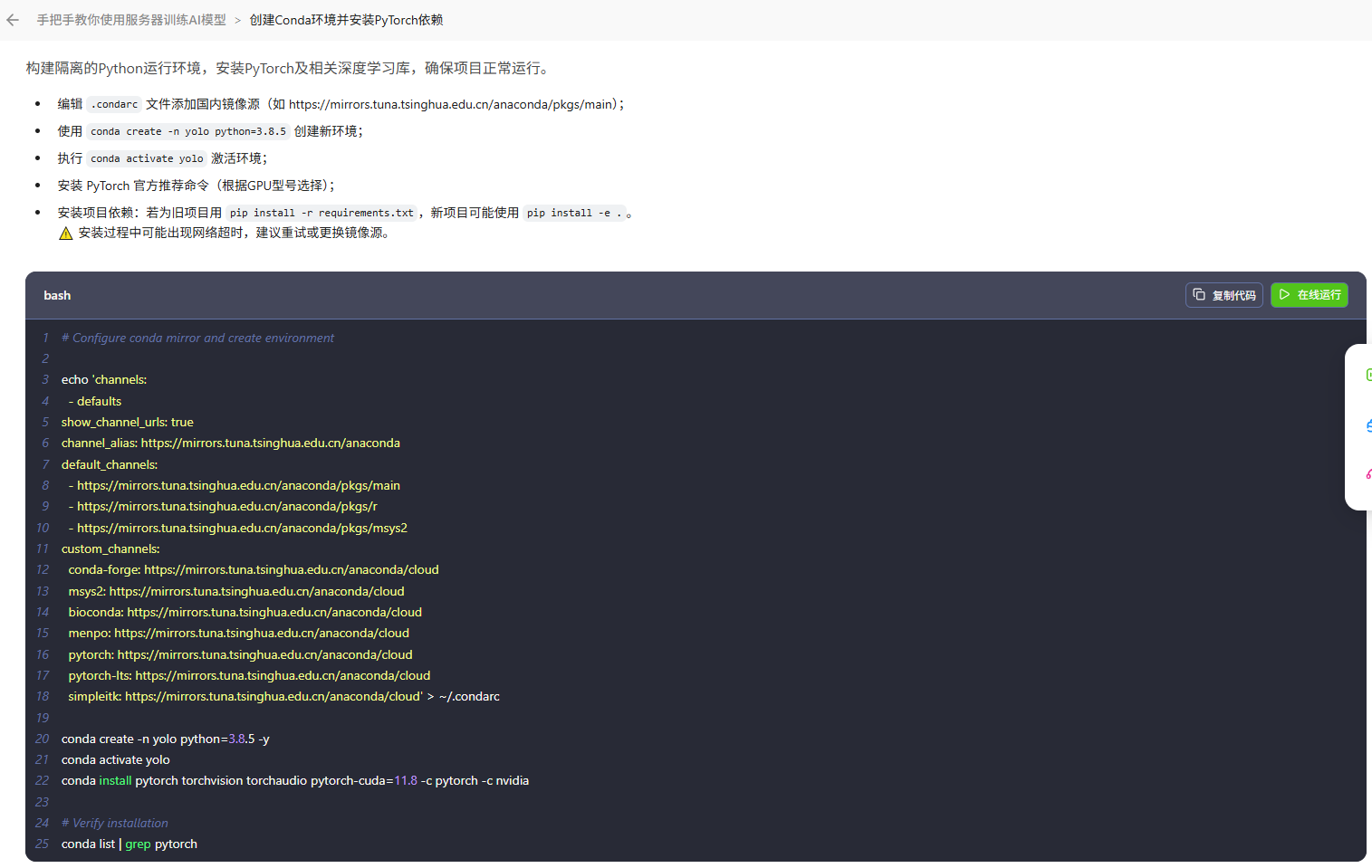
4. 环境配置:规避依赖与GPU适配坑
AI模拟服务器环境,简化配置流程,自动处理版本适配问题:
# 创建虚拟环境
conda create -n ai_train python=3.8
conda activate ai_train
# 安装PyTorch(AI先提示查看CUDA版本,再给出对应命令)
nvidia-smi # 查看CUDA版本
pip install torch==1.10.1+cu113 # 适配CUDA 11.3,避免版本冲突若误装CPU版本,AI会提示"CUDA不可用,建议安装对应GPU版本",并给出精准命令,省去手动排查时间。
5. 模型训练与结果下载:全流程简化实操
AI提供精简训练代码,模拟常见报错场景,给出解决方案:
# 核心训练逻辑(AI标注关键优化点)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleModel().to(device)
dataloader = DataLoader(dataset, batch_size=8) # 标注:显存不足可调小batch_size
# 训练循环与模型保存
torch.save(model.state_dict(), "/home/ai/logs/model.pth")训练中报显存不足时,AI直接提示"调小batch_size至4,或用torch.cuda.empty_cache()释放显存";训练结束后,同步演示结果下载命令,形成闭环。
总结:学服务器训练,"轻实操+强反馈"才高效
纯视频学习的核心问题的是"缺逻辑、无反馈、难落地",而AI学习助理通过结构化路径提炼、在线模拟实操、针对性报错指引,把复杂流程拆成可逐步突破的小目标,不用死记硬背命令,也能快速掌握服务器训练AI模型的核心能力。对AI入门者来说,这种"学一点、练一点、吃透一点"的模式,能大幅降低试错成本,让服务器训练从"看似复杂"变得"触手可及"。
- 我学习用的原视频:https://www.bilibili.com/video/BV1TuxLeVED6?p=2
- 我学习视频用的AI视频学习助理(PC免费版):https://t.cloudlab.top/2IvdLC