我们通过手动应答处理了在消费者出故障消息丢失的情况,但是如何保障当 RabbitMQ 服务停掉以后消息生产者发送过来的消息不丢失。默认情况下 RabbitMQ 退出或由于某种原因崩溃时,它会清空队列和消息,除非告知它不要这样做。确保消息不会丢失可以做三件事:我们需要将交换机、队列和消息都标记为持久化。
交换器持久化
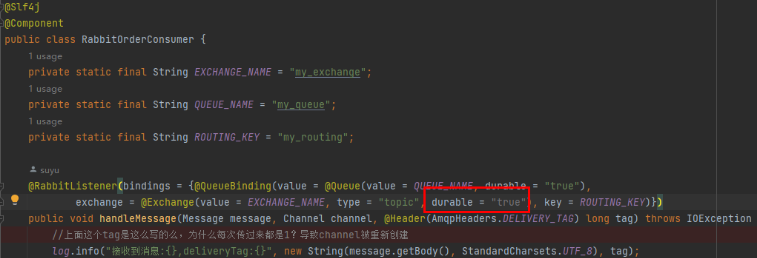
- 交换器的持久化是通过在声明交换器时, 指定Durability参数为durable实现的。
- 若交换器不设置持久化,在rabbitmq服务重启之后,相关的交换器元数据会丢失,但消息不会丢失,只是不能将消息发送到这个交换器中。所以在声明交换器时,都要设置持久化。
- 在web监控创建时,默认也是持久化模式,指定持久化模式带有标识"D"。
队列持久化
- 队列的持久化是通过在声明队列时, 指定Durability参数为durable实现的。
- 若队列不设置持久化,在rabbitmq服务重启之后,相关队列的元数据和消息数据同时丢失。
- 若队列设置持久化,只能保证队列本身的元数据不会因异常情况而丢失,但是并不能保证内部所存储的消息不会丢失。要确保消息不会丢失,需要将消息设置为持久化。
- 在web监控创建时,默认也是持久化模式,指定持久化模式带有标识"D"。
消息持久化
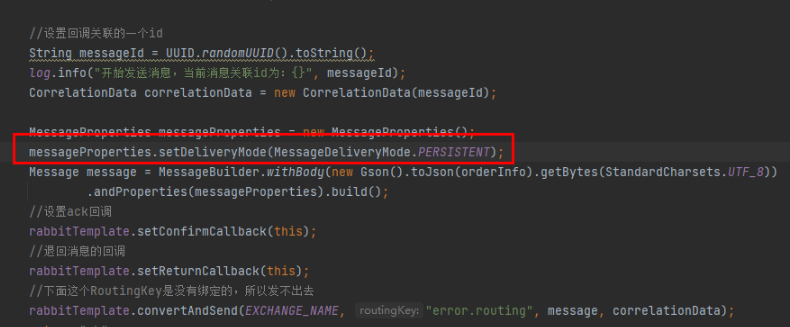
- 消息的持久化可以通过消息的投递模式来实现,属于代码层面上的。可以控制每一条消息是否久化。
- 但是将所有消息都设置为持久化,会严重影响rabbitmq服务器性能,写入磁盘的速度比写入内存的速度慢得不只一点点。所以对于可靠性不是那么高的消息可以不采用持久化处理以提高整体的吞吐量。在选择是否要将消息持久化时,需要在可靠性和吐吞量之间做一个权衡。
总结
将交换器、队列、消息都设置了持久化之后能百分之百保证数据不丢失吗?答案是不能?
- 从消费者来说,如果在订阅消费队列时将 autoAck 参数设置为 true,那么当消费者接收到相关消息之后,还没来得及处理就宕机了,这样也算数据丢失。这种情况很好解决,将autoAck 参数设置为 false,并进行手动确认。
- 在持久化的消息正确存入rabbitmq之后,还需要有一段时间(虽然很短,但是不可忽视) 才能存入磁盘之中。如果在这段时间内rabbitmq服务节点发生了宕机、重启等异常情况,消息保存还没来得及落盘,那么这些消息将会丢失。这种情况可以使用镜像队列来解决。