目录
267、pandas.Series.dt.microsecond属性
268、pandas.Series.dt.nanosecond属性
269、pandas.Series.dt.dayofweek属性
270、pandas.Series.dt.weekday属性



一、用法精讲
266、pandas.Series.dt.second属性
266-1、语法
python
# 266、pandas.Series.dt.second属性
pandas.Series.dt.second
The seconds of the datetime.266-2、参数
无
266-3、功能
用于从包含datetime对象的pandas系列中提取秒数。
266-4、返回值
返回一个包含每个datetime元素的秒数部分的Series对象。
266-5、说明
使用场景:
266-5-1、详细时间分析:需要对时间戳数据进行详细分析时,可以使用dt.second提取秒数。例如,分析每天不同秒数的分布情况。
266-5-2、时间过滤:根据秒数进行数据过滤。例如,筛选出在特定秒数发生的事件。
266-5-3、特征工程:在机器学习或数据挖掘中,将秒数作为特征之一,进行模型训练和预测。
266-5-4、性能优化:在时间序列数据处理中,提取秒数可以帮助进行更细粒度的性能分析和优化。
266-5-5、日志分析:在分析服务器日志或其他时间戳数据时,提取秒数可以帮助识别特定秒数内的访问模式或事件。
266-6、用法
266-6-1、数据准备
python
无266-6-2、代码示例
python
# 266、pandas.Series.dt.second属性
# 266-1、详细时间分析
import pandas as pd
# 创建一个包含10个时间戳的Series,每个时间戳间隔1秒
data = pd.Series(pd.date_range("2024-01-01", periods=10, freq="s"))
# 提取秒数
seconds = data.dt.second
print("详细时间分析-秒数部分:")
print(seconds, end='\n\n')
# 266-2、时间过滤
import pandas as pd
# 创建一个包含100个时间戳的Series,每个时间戳间隔1秒
data = pd.Series(pd.date_range("2024-01-01", periods=100, freq="s"))
# 筛选出在特定秒数(例如30秒)发生的事件
filtered_data = data[data.dt.second == 30]
print("时间过滤-特定秒数的时间戳:")
print(filtered_data, end='\n\n')
# 266-3、特征工程
import pandas as pd
# 创建一个包含10个时间戳的Series,每个时间戳间隔1秒
data = pd.Series(pd.date_range("2024-01-01", periods=10, freq="s"))
# 提取秒数并作为新列加入DataFrame
data = pd.DataFrame(data, columns=['datetime'])
data['second'] = data['datetime'].dt.second
print("特征工程-添加秒数特征:")
print(data, end='\n\n')
# 266-4、性能优化
import pandas as pd
# 创建一个包含100个时间戳的Series,每个时间戳间隔1分钟
start_times = pd.Series(pd.date_range("2024-01-01 12:00:00", periods=100, freq="min"))
# 提取秒数
seconds = start_times.dt.second
# 筛选出秒数为0的时间点
zero_second_times = start_times[seconds == 0]
print("性能优化-秒数为0的时间点:")
print(zero_second_times, end='\n\n')
# 266-5、日志分析
import pandas as pd
# 创建一个包含特定时间戳的Series
log_times = pd.Series(pd.to_datetime(["2024-01-01 00:00:10", "2024-01-01 00:00:20", "2024-01-01 00:00:30"]))
# 提取秒数
log_seconds = log_times.dt.second
print("日志分析-日志时间戳的秒数部分:")
print(log_seconds)266-6-3、结果输出
python
# 266、pandas.Series.dt.second属性
# 266-1、详细时间分析
# 详细时间分析-秒数部分:
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
# 5 5
# 6 6
# 7 7
# 8 8
# 9 9
# dtype: int32
# 266-2、时间过滤
# 时间过滤-特定秒数的时间戳:
# 30 2024-01-01 00:00:30
# 90 2024-01-01 00:01:30
# dtype: datetime64[ns]
# 266-3、特征工程
# 特征工程-添加秒数特征:
# datetime second
# 0 2024-01-01 00:00:00 0
# 1 2024-01-01 00:00:01 1
# 2 2024-01-01 00:00:02 2
# 3 2024-01-01 00:00:03 3
# 4 2024-01-01 00:00:04 4
# 5 2024-01-01 00:00:05 5
# 6 2024-01-01 00:00:06 6
# 7 2024-01-01 00:00:07 7
# 8 2024-01-01 00:00:08 8
# 9 2024-01-01 00:00:09 9
# 266-4、性能优化
# 性能优化-秒数为0的时间点:
# 0 2024-01-01 12:00:00
# 1 2024-01-01 12:01:00
# 2 2024-01-01 12:02:00
# 3 2024-01-01 12:03:00
# 4 2024-01-01 12:04:00
# ...
# 95 2024-01-01 13:35:00
# 96 2024-01-01 13:36:00
# 97 2024-01-01 13:37:00
# 98 2024-01-01 13:38:00
# 99 2024-01-01 13:39:00
# Length: 100, dtype: datetime64[ns]
# 266-5、日志分析
# 日志分析-日志时间戳的秒数部分:
# 0 10
# 1 20
# 2 30
# dtype: int32267、pandas.Series.dt.microsecond属性
267-1、语法
python
# 267、pandas.Series.dt.microsecond属性
pandas.Series.dt.microsecond
The microseconds of the datetime.267-2、参数
无
267-3、功能
用于提取时间序列数据中微秒部分的值。
267-4、返回值
返回一个包含时间序列中每个时间戳的微秒值的Series。
267-5、说明
无
267-6、用法
267-6-1、数据准备
python
无267-6-2、代码示例
python
# 267、pandas.Series.dt.microsecond属性
# 267-1、提取微秒值
import pandas as pd
# 创建一个包含微秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=5, freq="333333us"))
# 提取微秒部分
microseconds = time_series.dt.microsecond
print("微秒值:")
print(microseconds, end='\n\n')
# 267-2、筛选特定微秒值的时间戳
import pandas as pd
# 创建一个包含微秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=10, freq="333333us"))
# 提取微秒部分
microseconds = time_series.dt.microsecond
# 筛选出微秒部分为333333的时间戳
filtered_time_series = time_series[microseconds == 333333]
print("微秒部分为333333的时间戳:")
print(filtered_time_series, end='\n\n')
# 267-3、添加微秒列到DataFrame
import pandas as pd
# 创建一个包含微秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=5, freq="333333us"))
# 创建DataFrame并添加微秒列
df = pd.DataFrame(time_series, columns=['datetime'])
df['microsecond'] = df['datetime'].dt.microsecond
print("添加微秒列的DataFrame:")
print(df, end='\n\n')
# 267-4、详细时间分析-微秒部分
import pandas as pd
# 创建一个包含微秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=10, freq="333333us"))
# 提取微秒部分
microseconds = time_series.dt.microsecond
print("详细时间分析-微秒部分:")
print(microseconds)267-6-3、结果输出
python
# 267、pandas.Series.dt.microsecond属性
# 267-1、提取微秒值
# 微秒值:
# 0 0
# 1 333333
# 2 666666
# 3 999999
# 4 333332
# dtype: int32
# 267-2、筛选特定微秒值的时间戳
# 微秒部分为333333的时间戳:
# 1 2024-01-01 00:00:00.333333
# dtype: datetime64[ns]
# 267-3、添加微秒列到DataFrame
# 添加微秒列的DataFrame:
# datetime microsecond
# 0 2024-01-01 00:00:00.000000 0
# 1 2024-01-01 00:00:00.333333 333333
# 2 2024-01-01 00:00:00.666666 666666
# 3 2024-01-01 00:00:00.999999 999999
# 4 2024-01-01 00:00:01.333332 333332
# 267-4、详细时间分析-微秒部分
# 详细时间分析-微秒部分:
# 0 0
# 1 333333
# 2 666666
# 3 999999
# 4 333332
# 5 666665
# 6 999998
# 7 333331
# 8 666664
# 9 999997
# dtype: int32268、pandas.Series.dt.nanosecond属性
268-1、语法
python
# 268、pandas.Series.dt.nanosecond属性
pandas.Series.dt.nanosecond
The nanoseconds of the datetime.268-2、参数
无
268-3、功能
用于提取时间序列数据中纳秒部分的值。
268-4、返回值
返回一个包含时间序列中每个时间戳的纳秒值的Series。
268-5、说明
无
268-6、用法
268-6-1、数据准备
python
无268-6-2、代码示例
python
# 268、pandas.Series.dt.nanosecond属性
# 268-1、提取纳秒值
import pandas as pd
# 创建一个包含纳秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=5, freq="333333333ns"))
# 提取纳秒部分
nanoseconds = time_series.dt.nanosecond
print("纳秒值:")
print(nanoseconds, end='\n\n')
# 268-2、筛选特定纳秒值的时间戳
import pandas as pd
# 创建一个包含纳秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=10, freq="333333333ns"))
# 提取纳秒部分
nanoseconds = time_series.dt.nanosecond
# 筛选出纳秒部分为333333333的时间戳
filtered_time_series = time_series[nanoseconds == 333333333]
print("纳秒部分为333333333的时间戳:")
print(filtered_time_series, end='\n\n')
# 268-3、添加纳秒列到DataFrame
import pandas as pd
# 创建一个包含纳秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=5, freq="333333333ns"))
# 创建DataFrame并添加纳秒列
df = pd.DataFrame(time_series, columns=['datetime'])
df['nanosecond'] = df['datetime'].dt.nanosecond
print("添加纳秒列的DataFrame:")
print(df, end='\n\n')
# 268-4、详细时间分析-纳秒部分
import pandas as pd
# 创建一个包含纳秒部分的时间戳的Series
time_series = pd.Series(pd.date_range("2024-01-01 00:00:00", periods=10, freq="333333333ns"))
# 提取纳秒部分
nanoseconds = time_series.dt.nanosecond
print("详细时间分析-纳秒部分:")
print(nanoseconds)268-6-3、结果输出
python
# 268、pandas.Series.dt.nanosecond属性
# 268-1、提取纳秒值
# 纳秒值:
# 0 0
# 1 333
# 2 666
# 3 999
# 4 332
# dtype: int32
# 268-2、筛选特定纳秒值的时间戳
# 纳秒部分为333333333的时间戳:
# Series([], dtype: datetime64[ns])
# 268-3、添加纳秒列到DataFrame
# 添加纳秒列的DataFrame:
# datetime nanosecond
# 0 2024-01-01 00:00:00.000000000 0
# 1 2024-01-01 00:00:00.333333333 333
# 2 2024-01-01 00:00:00.666666666 666
# 3 2024-01-01 00:00:00.999999999 999
# 4 2024-01-01 00:00:01.333333332 332
# 268-4、详细时间分析-纳秒部分
# 详细时间分析-纳秒部分:
# 0 0
# 1 333
# 2 666
# 3 999
# 4 332
# 5 665
# 6 998
# 7 331
# 8 664
# 9 997
# dtype: int32269、pandas.Series.dt.dayofweek属性
269-1、语法
python
# 269、pandas.Series.dt.dayofweek属性
pandas.Series.dt.dayofweek
The day of the week with Monday=0, Sunday=6.
Return the day of the week. It is assumed the week starts on Monday, which is denoted by 0 and ends on Sunday which is denoted by 6. This method is available on both Series with datetime values (using the dt accessor) or DatetimeIndex.
Returns:
Series or Index
Containing integers indicating the day number.269-2、参数
无
269-3、功能
用于获取日期时间序列中每个日期的星期几的属性,具备此功能的还有pandas.Series.dt.day_of_week属性。
269-4、返回值
返回一个整数值,表示一周中的星期几,其中0代表星期一,6代表星期天。
269-5、说明
使用场景:
**269-5-1、工作日和周末分析:**在进行销售、流量或其他业务指标的分析时,可以使用该属性来区分工作日和周末,从而更好地理解客户行为模式。
**269-5-2、时间序列数据的聚合:**可以根据星期几对数据进行分组,从而计算每个星期几的平均值、总和或其他统计信息。例如,分析每周的销售额变化趋势。
**269-5-3、调度和排班:**在员工排班或资源调度中,可以利用该属性来确定哪些日期是工作日,进而制定合理的工作安排。
**269-5-4、季节性趋势分析:**在一些行业(如零售、旅游等),不同星期几的销售或用户活动可能存在显著差异,通过分析这些差异可以帮助制定更有效的营销策略。
**269-5-5、数据清洗和预处理:**在处理时间序列数据时,可以利用该属性筛选出特定的日期,例如只保留工作日的数据,去除周末的数据。
**269-5-6、事件驱动分析:**对于特定事件(如假期、促销活动等)的影响分析,可以使用星期几信息来比较这些事件在不同日期的效果。
269-6、用法
269-6-1、数据准备
python
无269-6-2、代码示例
python
# 269、pandas.Series.dt.dayofweek属性
# 269-1、工作日和周末分析
import pandas as pd
# 创建一个包含日期的数据
data = {'date': pd.date_range(start='2024-08-01', periods=10)}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 标记工作日和周末
df['is_weekend'] = df['day_of_week'] >= 5
print(df, end='\n\n')
# 269-2、时间序列数据的聚合
import pandas as pd
# 创建一个示例数据框
data = {'date': pd.date_range(start='2024-08-01', periods=30),
'sales': range(30)}
df = pd.DataFrame(data)
# 提取星期几并进行分组
df['day_of_week'] = df['date'].dt.dayofweek
weekly_sales = df.groupby('day_of_week')['sales'].sum()
print(weekly_sales, end='\n\n')
# 269-3、调度和排班
import pandas as pd
# 创建一个包含日期的数据
data = {'date': pd.date_range(start='2024-08-01', periods=10)}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 根据星期几制定排班计划
df['shift'] = df['day_of_week'].apply(lambda x: 'Morning' if x < 5 else 'Day Off')
print(df, end='\n\n')
# 269-4、季节性趋势分析
import pandas as pd
import numpy as np
# 创建一个包含日期和销售额的数据
np.random.seed(0)
data = {'date': pd.date_range(start='2024-01-01', periods=365),
'sales': np.random.randint(100, 1000, size=365)}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 计算每个星期几的平均销售额
weekly_avg_sales = df.groupby('day_of_week')['sales'].mean()
print(weekly_avg_sales, end='\n\n')
# 269-5、数据清洗和预处理
import pandas as pd
# 创建一个包含日期和数据的示例
data = {'date': pd.date_range(start='2024-01-01', periods=10),
'value': range(10)}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 只保留工作日的数据
df_weekdays = df[df['day_of_week'] < 5]
print(df_weekdays, end='\n\n')
# 269-6、事件驱动分析
import pandas as pd
# 创建一个包含日期和事件的数据
data = {'date': pd.date_range(start='2024-01-01', periods=10),
'event': ['Promotion', 'Regular', 'Promotion', 'Regular', 'Promotion', 'Regular', 'Regular', 'Promotion', 'Regular', 'Promotion']}
df = pd.DataFrame(data)
# 提取星期几
df['day_of_week'] = df['date'].dt.dayofweek
# 按照星期几和事件类型进行聚合
event_analysis = df.groupby(['day_of_week', 'event']).size().unstack(fill_value=0)
print(event_analysis)269-6-3、结果输出
python
# 269、pandas.Series.dt.dayofweek属性
# 269-1、工作日和周末分析
# date day_of_week is_weekend
# 0 2024-08-01 3 False
# 1 2024-08-02 4 False
# 2 2024-08-03 5 True
# 3 2024-08-04 6 True
# 4 2024-08-05 0 False
# 5 2024-08-06 1 False
# 6 2024-08-07 2 False
# 7 2024-08-08 3 False
# 8 2024-08-09 4 False
# 9 2024-08-10 5 True
# 269-2、时间序列数据的聚合
# day_of_week
# 0 58
# 1 62
# 2 66
# 3 70
# 4 75
# 5 50
# 6 54
# Name: sales, dtype: int64
# 269-3、调度和排班
# date day_of_week shift
# 0 2024-08-01 3 Morning
# 1 2024-08-02 4 Morning
# 2 2024-08-03 5 Day Off
# 3 2024-08-04 6 Day Off
# 4 2024-08-05 0 Morning
# 5 2024-08-06 1 Morning
# 6 2024-08-07 2 Morning
# 7 2024-08-08 3 Morning
# 8 2024-08-09 4 Morning
# 9 2024-08-10 5 Day Off
# 269-4、季节性趋势分析
# day_of_week
# 0 580.943396
# 1 493.384615
# 2 630.538462
# 3 484.019231
# 4 548.192308
# 5 583.346154
# 6 547.403846
# Name: sales, dtype: float64
# 269-5、数据清洗和预处理
# date value day_of_week
# 0 2024-01-01 0 0
# 1 2024-01-02 1 1
# 2 2024-01-03 2 2
# 3 2024-01-04 3 3
# 4 2024-01-05 4 4
# 7 2024-01-08 7 0
# 8 2024-01-09 8 1
# 9 2024-01-10 9 2
# 269-6、事件驱动分析
# event Promotion Regular
# day_of_week
# 0 2 0
# 1 0 2
# 2 2 0
# 3 0 1
# 4 1 0
# 5 0 1
# 6 0 1270、pandas.Series.dt.weekday属性
270-1、语法
python
# 270、pandas.Series.dt.weekday属性
pandas.Series.dt.weekday
The day of the week with Monday=0, Sunday=6.
Return the day of the week. It is assumed the week starts on Monday, which is denoted by 0 and ends on Sunday which is denoted by 6. This method is available on both Series with datetime values (using the dt accessor) or DatetimeIndex.
Returns:
Series or Index
Containing integers indicating the day number.270-2、参数
无
270-3、功能
用于提取datetime对象的星期几。
270-4、返回值
返回值是一个整数,其中0表示星期一,1表示星期二,以此类推,6表示星期日。
270-5、说明
使用场景:
270-5-1、数据分析:在进行数据分析时,了解某些事件发生的星期几可以帮助识别趋势。例如,某些销售数据可能在周末更高,而其他业务则可能在工作日更繁忙。
270-5-2、数据可视化:在绘制图表时,可以根据星期几对数据进行分组,从而更清晰地展示不同时间段的行为模式。例如,使用条形图展示每周各天的销售额。
270-5-3、业务决策:在制定营销策略时,了解客户行为与星期几的关系可以帮助优化广告投放时间和促销活动。例如,可以在特定的日子进行促销,以吸引更多顾客。
270-5-4、调度与规划:在项目管理或人力资源调度中,可以根据工作日和休息日来安排任务或人员,确保工作效率最大化。
270-5-5、时间序列分析:在时间序列数据分析中,提取星期几信息可以作为特征之一,帮助构建更精准的预测模型。
270-5-6、事件记录与跟踪:在记录事件发生时间时,可以使用星期几来分析事件的发生频率与特定日期的关系,比如员工请假、客户投诉等。
270-6、用法
270-6-1、数据准备
python
无270-6-2、代码示例
python
# 270、pandas.Series.dt.weekday属性
# 270-1、数据分析:识别销售趋势
import pandas as pd
# 创建示例销售数据
data = {
'date': pd.date_range(start='2024-01-01', periods=30),
'sales': [200, 220, 210, 230, 250, 270, 300, 320, 310, 330, 340, 350,
360, 370, 380, 390, 400, 410, 420, 430, 440, 450, 460, 470,
480, 490, 500, 510, 520, 530]
}
df = pd.DataFrame(data)
# 提取星期几
df['weekday'] = df['date'].dt.weekday
# 计算每天的平均销售额
average_sales_by_weekday = df.groupby('weekday')['sales'].mean()
print(average_sales_by_weekday, end='\n\n')
# 270-2、数据可视化:展示每周各天的销售额
import pandas as pd
import matplotlib.pyplot as plt
# 创建示例销售数据
data = {
'date': pd.date_range(start='2024-01-01', periods=30),
'sales': [200, 220, 210, 230, 250, 270, 300, 320, 310, 330, 340, 350,
360, 370, 380, 390, 400, 410, 420, 430, 440, 450, 460, 470,
480, 490, 500, 510, 520, 530]
}
df = pd.DataFrame(data)
df['weekday'] = df['date'].dt.weekday
# 按星期几分组并计算总销售额
total_sales_by_weekday = df.groupby('weekday')['sales'].sum()
# 绘制条形图
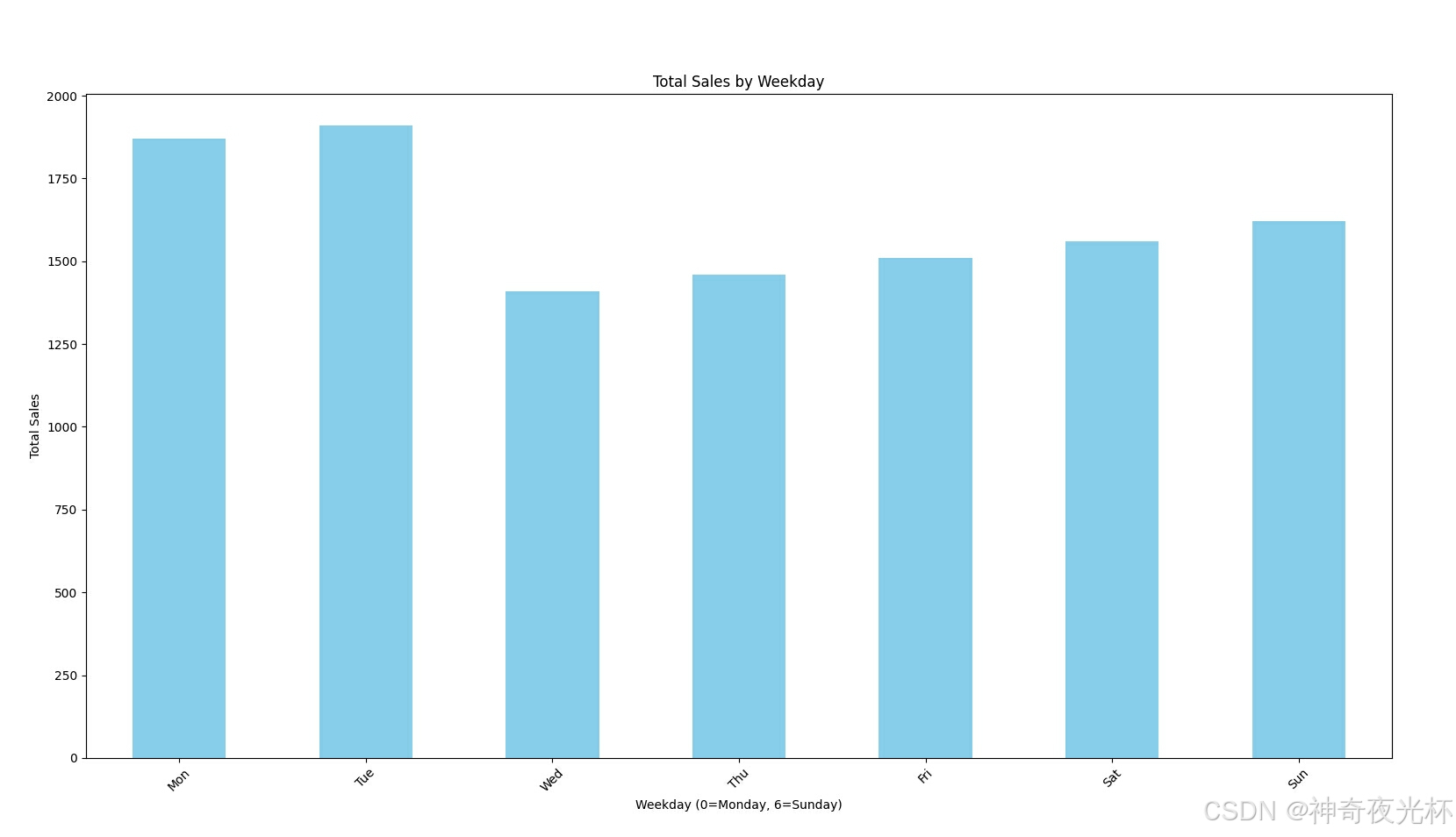
total_sales_by_weekday.plot(kind='bar', color='skyblue')
plt.xlabel('Weekday (0=Monday, 6=Sunday)')
plt.ylabel('Total Sales')
plt.title('Total Sales by Weekday')
plt.xticks(ticks=range(7), labels=['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'], rotation=45)
plt.show()
# 270-3、业务决策:优化广告投放时间
import pandas as pd
# 创建示例广告投放数据
data = {
'ad_date': pd.date_range(start='2024-01-01', periods=30),
'ad_cost': [1000, 1200, 1100, 1300, 1500, 1600, 1700, 1800, 1750, 1900,
2000, 2100, 2200, 2300, 2400, 2500, 2600, 2700, 2800, 2900,
3000, 3100, 3200, 3300, 3400, 3500, 3600, 3700, 3800, 3900]
}
df = pd.DataFrame(data)
# 提取星期几
df['weekday'] = df['ad_date'].dt.weekday
# 计算广告成本按星期几的总和
ad_cost_by_weekday = df.groupby('weekday')['ad_cost'].sum()
print(ad_cost_by_weekday, end='\n\n')
# 270-4、调度与规划:安排任务或人员
import pandas as pd
# 创建示例任务数据
tasks = {
'task_date': pd.date_range(start='2024-01-01', periods=30),
'task': ['Task {}'.format(i) for i in range(30)]
}
df = pd.DataFrame(tasks)
# 提取星期几
df['weekday'] = df['task_date'].dt.weekday
# 按星期几分配任务
tasks_by_weekday = df.groupby('weekday')['task'].count()
print(tasks_by_weekday, end='\n\n')
# 270-5、时间序列分析:构建预测模型特征
import pandas as pd
# 创建示例时间序列数据
data = {
'date': pd.date_range(start='2024-01-01', periods=100),
'value': range(100)
}
df = pd.DataFrame(data)
# 提取星期几作为特征
df['weekday'] = df['date'].dt.weekday
print(df.head(), end='\n\n')
# 270-6、事件记录与跟踪:分析事件发生频率
import pandas as pd
# 创建示例事件数据
events = {
'event_date': pd.date_range(start='2024-01-01', periods=50),
'event_type': ['Type {}'.format(i % 5) for i in range(50)]
}
df = pd.DataFrame(events)
# 提取星期几
df['weekday'] = df['event_date'].dt.weekday
# 统计每星期几的事件数量
events_by_weekday = df.groupby('weekday').size()
print(events_by_weekday)270-6-3、结果输出
python
# 270、pandas.Series.dt.weekday属性
# 270-1、数据分析:识别销售趋势
# weekday
# 0 374.0
# 1 382.0
# 2 352.5
# 3 365.0
# 4 377.5
# 5 390.0
# 6 405.0
# Name: sales, dtype: float64
# 270-2、数据可视化:展示每周各天的销售额
# 见图1
# 270-3、业务决策:优化广告投放时间
# weekday
# 0 12100
# 1 12550
# 2 8900
# 3 9400
# 4 9900
# 5 10300
# 6 10700
# Name: ad_cost, dtype: int64
# 270-4、调度与规划:安排任务或人员
# weekday
# 0 5
# 1 5
# 2 4
# 3 4
# 4 4
# 5 4
# 6 4
# Name: task, dtype: int64
# 270-5、时间序列分析:构建预测模型特征
# date value weekday
# 0 2024-01-01 0 0
# 1 2024-01-02 1 1
# 2 2024-01-03 2 2
# 3 2024-01-04 3 3
# 4 2024-01-05 4 4
# 270-6、事件记录与跟踪:分析事件发生频率
# weekday
# 0 8
# 1 7
# 2 7
# 3 7
# 4 7
# 5 7
# 6 7
# dtype: int64图1: