接上篇GaussDB关键技术原理|高可用:逻辑复制从逻辑复制方面对GaussDB的高可用能力进行了介绍,本篇将从两地三中心跨Region容灾方面继续解读GaussDB高可用技术。
目录
[4 两地三中心跨Region容灾](#4 两地三中心跨Region容灾)
[4.1 概述](#4.1 概述)
[4.2 异地容灾部署示例](#4.2 异地容灾部署示例)
[4.3 总体设计](#4.3 总体设计)
[4.4 容灾搭建](#4.4 容灾搭建)
4 两地三中心跨Region容灾
4.1 概述
两地三中心,顾名思义,两地指的是两座城市,即同城和异地,三中心指的是生产中心,同城容灾中心以及异地容灾中心。近年来,国内外频繁出现自然灾害,以同城双中心加异地灾备中心的"两地三中心"的灾备模式也随之出现,这一方案兼具高可用性和灾难备份的能力。
同城双中心是指在同城或邻近城市建立两个可独立承担关键系统运行的数据中心,双中心具备基本等同的业务处理能力并通过高速链路实时同步数据,日常情况下可同时分担业务及管理系统的运行,并可切换运行;灾难情况下可在基本不丢失数据的情况下进行灾备应急切换,保持业务连续运行。
异地灾备中心是指在异地的城市建立一个备份的灾备中心,用于双中心的数据备份,当双中心出现自然灾害等原因而发生故障时,异地灾备中心可以用备份数据进行业务的恢复。数据库实例之间借助存储介质或者不借助存储介质直接实现数据的全量和增量同步。当主数据库实例(即生产数据库实例)出现地域性故障,数据完全无法恢复时,可考虑启用将灾备数据库实例升主,以接管业务。
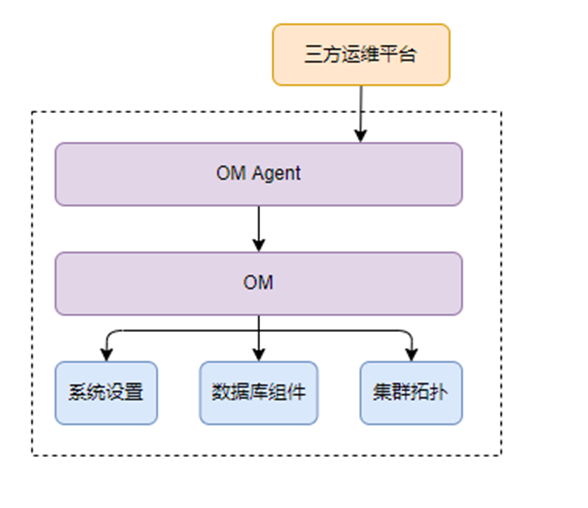
GaussDB当前提供基于流式复制的异地容灾解决方案。目前需要通过om_agent的https REST API来操控数据库实例实现异地容灾。
4.2 异地容灾部署示例
集中式
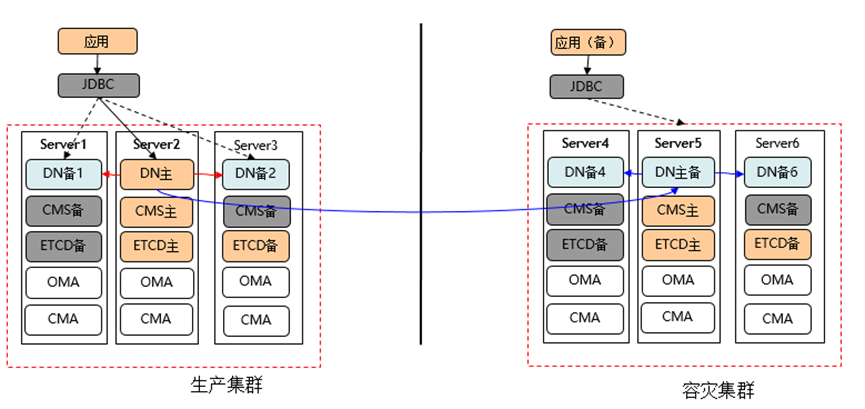
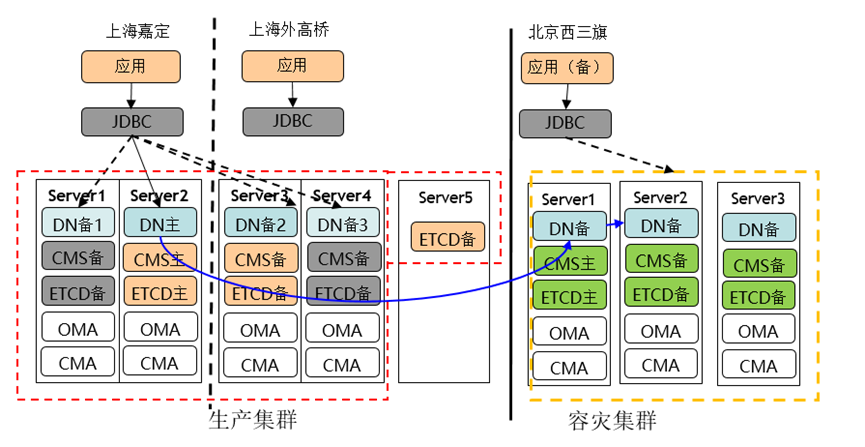
主集群是同城跨AZ的单集群,5台服务器,4副本,CMS-4副本,ETCD-5副本。Server5可以看做是仲裁副本,为上海2机房脑裂时,提供仲裁能力。
分布式:
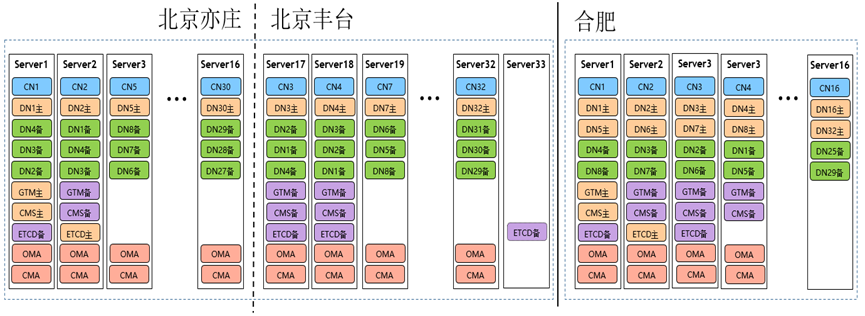
分布式示例
主集群是同城跨AZ的单集群,33台服务器,32C32D-4副本,GTM-4副本,CMS-4副本,ETCD-5副本。server33可以看做是仲裁副本,为北京2机房脑裂时,提供仲裁能力。
容灾集群为16台服务器,16C32D-2副本,需要开启最大可用模式,1个副本故障时任何对外提供服务,GTM-4副本,CMS-4副本,ETCD-3副本。由于机器数量有限,需要支持单服务器上部署2个主DN的部署方式。特别说明:图中展示的是合肥地域集群为正常集群时的组网,该集群成为灾备集群后,不会再有主DN,变为首备与级联备。
4.3 总体设计
集中式部署场景:
主实例和灾备实例副本数可不同,灾备集群最少为1副本。
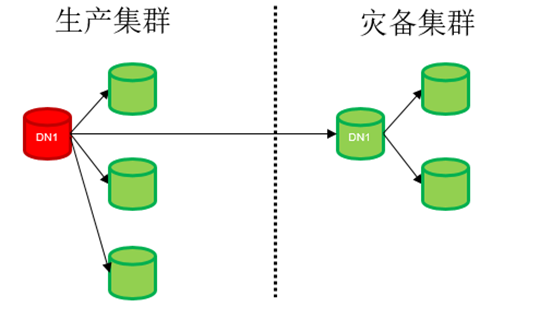
图 两地三中心异地容灾方案集中式部署场景
分布式部署场景:
支持灾备集群的CN个数和主集群CN个数不对等。
主集群和灾备集群DN分片数要求相同,DN分片内副本数可不同,灾备集群最少为1副本。
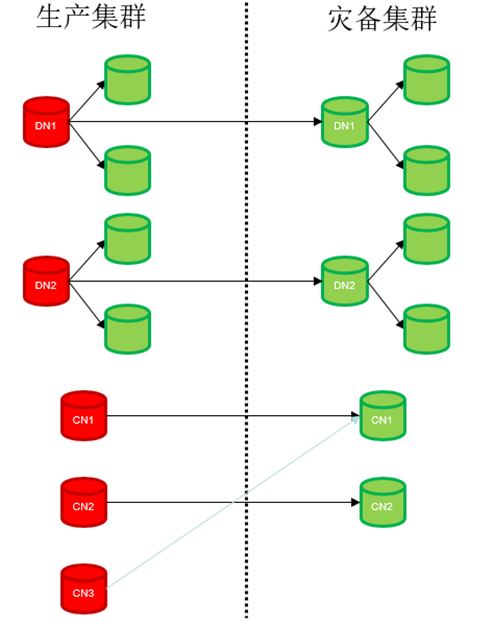
图 两地三中心异地容灾方案分布式部署场景
容灾方案提供如下操作流程:
- 容灾搭建:两个正常集群成为容灾状态下的主集群和灾备集群。
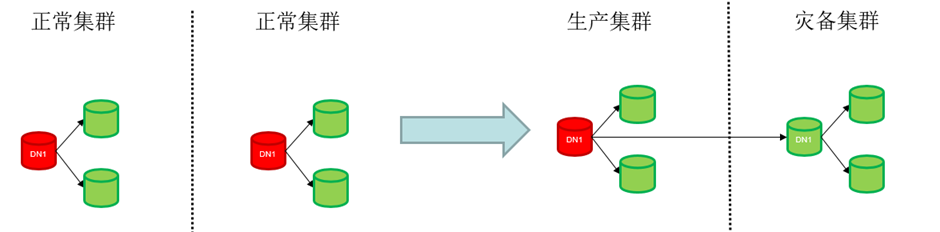
图 两地三中心异地容灾方案集中式部署容灾搭建集群变化
-
主备集群副本数可不同。
-
灾备集群有首备+级联备概念,只有首备从主集群主DN拷贝全量数据并建立异地流式复制关系。
-
灾备集群内级联备从首备拷贝数据,并与首备建立流式复制关系。
-
**灾备集群升主failover:**无论主集群是否异常,灾备集群都可以通过升主成为正常集群对外提供服务,并脱离容灾。
-
**演练特性-主备集群switchover:**主备集群在都是正常的情况下进行倒换,主集群降为备机,备机升为主机。
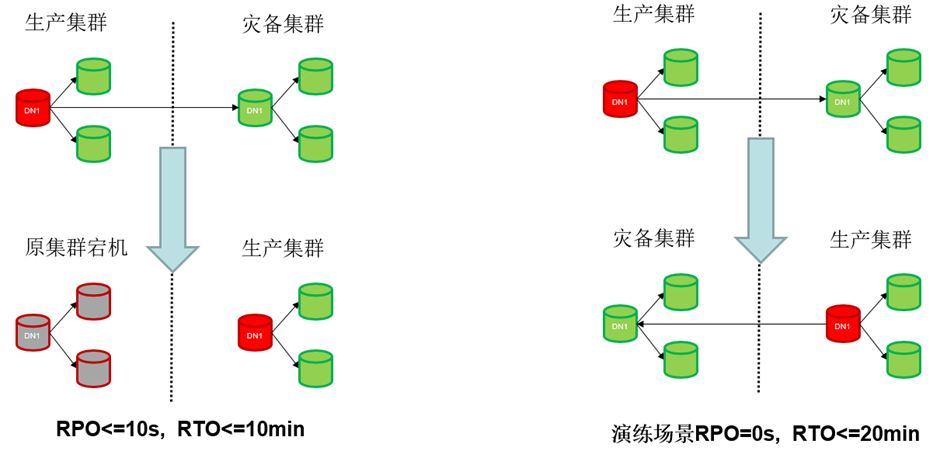
图 两地三中心异地容灾方案集中式部署failover与switchover集群变化
-
**主集群容灾解除:**用于在灾备集群升主后,主集群删除容灾信息,脱离容灾。
-
**容灾状态查询:**容灾状态日常监测,上报集群容灾状态、容灾搭建进度、failover进度、switchover进度,集群RTO,RPO实时数值。
| 上报项 | 含义 |
|---|---|
| hadr_cluster_stat (主备集群都可查到) | 参与容灾的集群状态 |
| hadr_establish_stat | 容灾搭建过程中主备集群搭建进度查询,显示进度百分比。 |
| hadr_failover_stat (备集群可查到) | 灾备集群升主过程进度,hadr_cluster_stat = promote时hadr_failover_stat中的值有效,显示进度百分比。 |
| hadr_switchover_stat (主备集群都可查到) | 计划内switchover过程进度,hadr_cluster_stat = switchover时hadr_switchover_stat中的值有效,显示进度百分比。 |
| RTO(主集群可查到) | 集群容灾RTO(所有分片的最大值) |
| RPO(主集群可查到) | 集群容灾RPO(所有分片的最大值) |
容灾状态下支持如下功能:
-
流控:通过GUC参数设置目标值,对主集群的日志产生速度进行控制,以保证RPO,RTO。
-
压缩:主备集群间日志传输可打开压缩,节约带宽,压缩比70%。
4.4 容灾搭建
容灾搭建总体流程
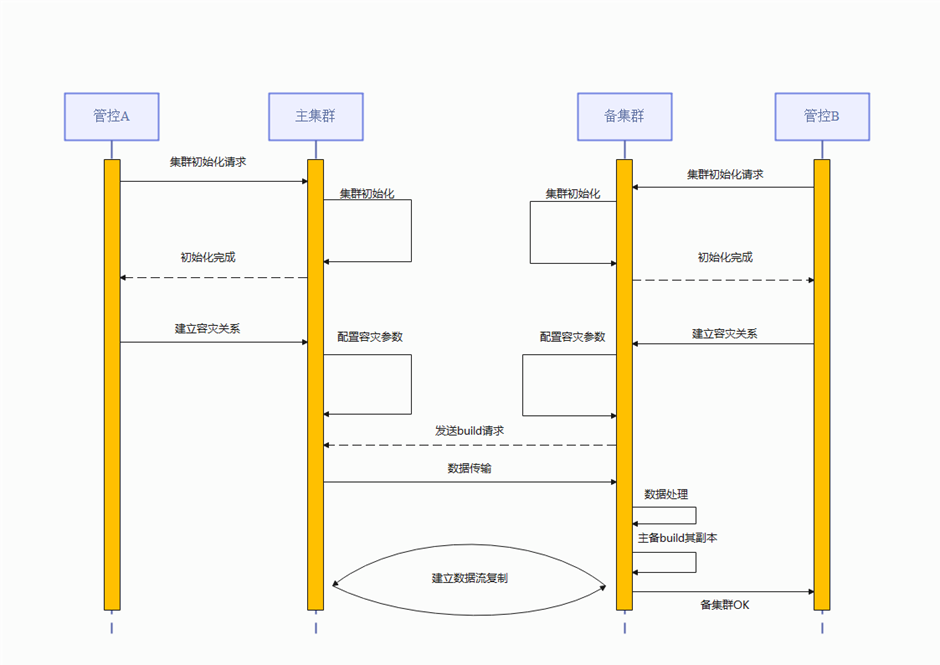
图 流式容灾集群搭建流程图
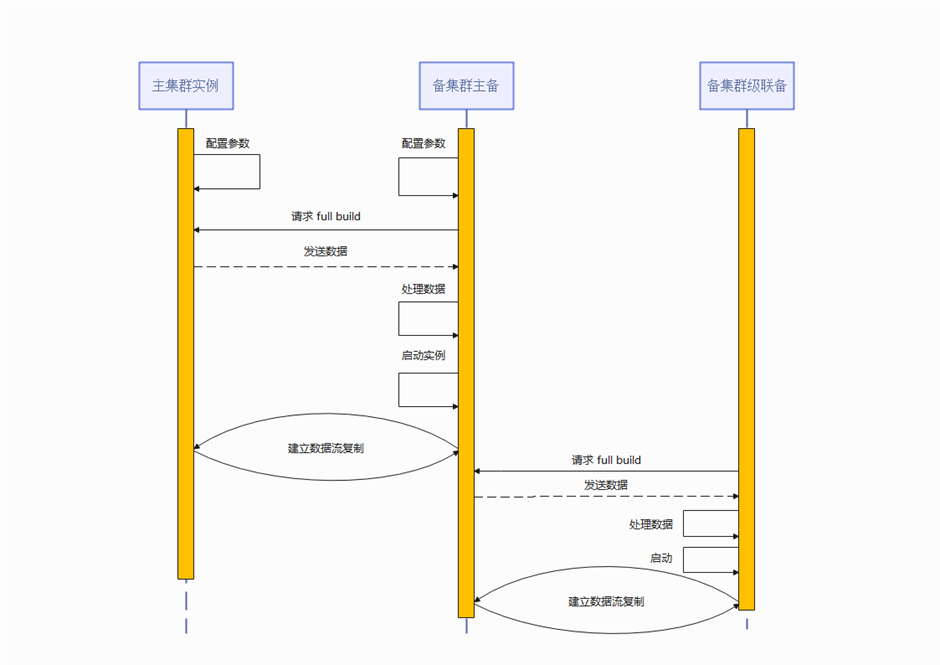
图 灾备集群搭建build备集群实例流程图
容灾流程图说明
灾备集群搭建主流程:
-
管控A下发搭建新集群A,管控B下发搭建新集群B。
-
管控A,B同时对集群下发灾备集群搭建指令,假设A为主集群,B为灾备集群。B集群中各实例配置A集群中对应节点实例的IP、PORT信息,A集群同样添加B集群中主备的IP、PORT信息。
-
选择B集群中首备实例。向B集群主备实例下发全量重建指令。
-
待B集群主备重建完成,建立A集群和B集群中主备的流复制,并下发B集群重建级联备指令。
-
待B集群所有实例重建成功,且B集群主备实例和A集群对应备机(分布式下对应分片的备机)建立流复制,其他B集群备机(分布式下同分片内)和首备建立连接成功后,返回灾备搭建成功。
容灾集群流式日志复制
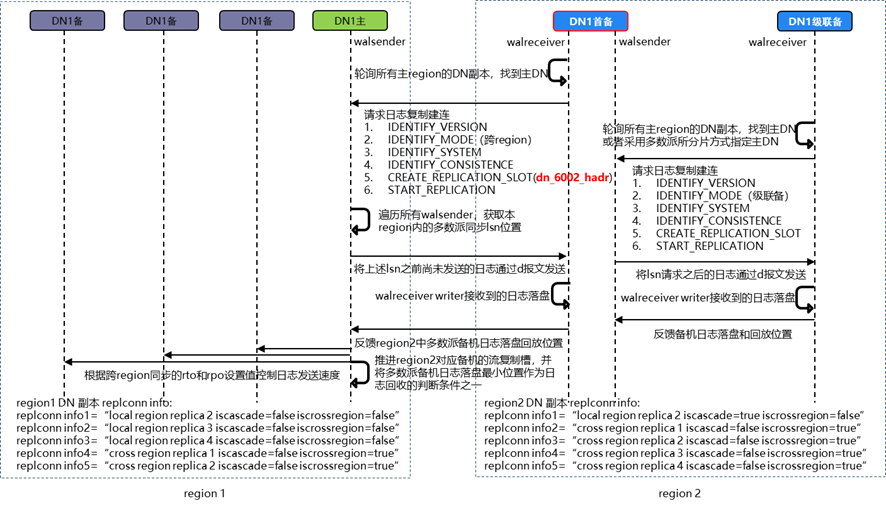
图 流式容灾灾备集群流复制复制消息序列图
-
在开启容灾阶段:在主集群每个副本上,配置replconninfo、hadr_recovery_time_target、hadr_recovery_point_target GUC参数,配置pg_hba.conf;在灾备集群的每个副本上,配置replconninfo参数。
-
CM仲裁选举灾备集群中的首备。
-
灾备集群首备轮询主集群中所有的副本,直到找到主DN。
-
灾备首备发起日志复制请求,包括:版本校验、对端状态校验、系统一致性校验、日志一致性校验;灾备首备创建和继续流复制槽,流复制槽名称采用application_name + _hadr方式拼接,以便和主集群同名副本进行区分。
-
主集群主DN遍历所有主集群walsender,获取多数派副本已经同步的日志LSN位置的最小值,并将首备请求LSN位置到该LSN位置之间的日志发送给首备。
-
灾备集群首备接受到日志之后,由walreceiver writer下盘。
-
灾备集群其他副本对首备发起级联复制请求,首备将上述请求LSN位置到本地下盘日志LSN位置之间的日志,级联发送到各个级联副本。
-
级联副本接受到日志之后,将本地的日志下盘位置和日志回放位置反馈给首备。
-
首备将灾备集群中所有副本中日志下盘的多数派LSN位置和日志回放的多数派LSN位置反馈给主集群的主DN。
-
主集群主DN将首备反馈的灾备集群多数派日志下盘位置,作为日志回收以及灾备RPO流控的判断条件(之一)。
-
主集群主DN将首备反馈的灾备集群多数派回放下盘位置,作为灾备RTO流控的判断条件(之一)。
容灾集群流式日志复制的高可用
主集群少数派副本故障
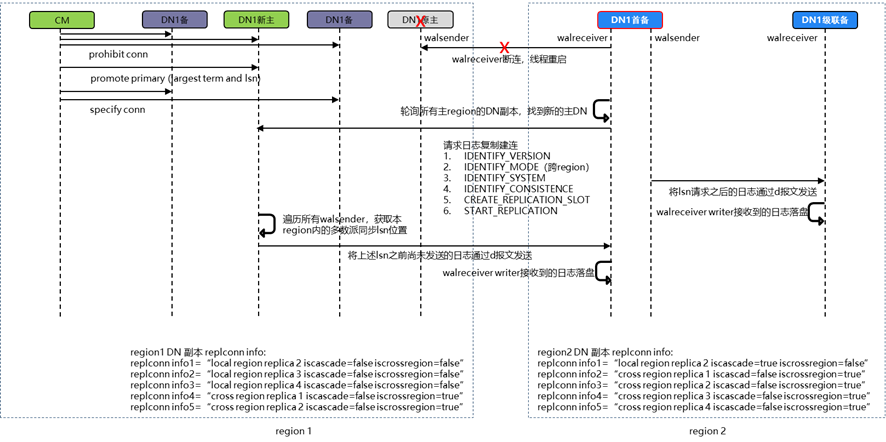
图 主集群发生少数派副本消息序列图
-
主集群CM发起锁分片和重新选主。
-
灾备集群首备的复制链接中断,wal receiver线程退出,重新开始轮询主集群各个副本。
-
主集群新主选主成功。
-
灾备集群轮询到新主,再次开始流式日志复制。
-
由于发送给灾备集群首备的日志都是在主集群已经达成多数派的,因此不会发生日志分叉的问题。
灾备集群少数派故障:
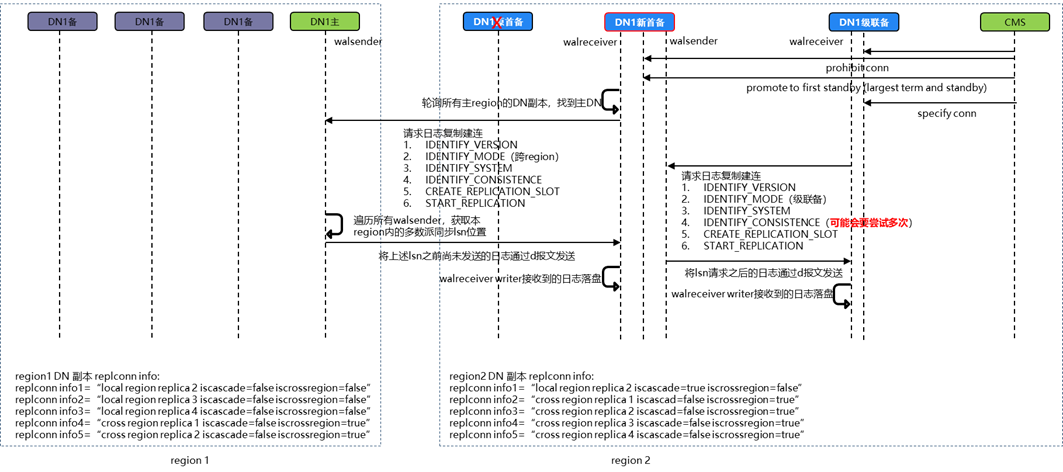
图 灾备集群发生少数派副本消息序列图
-
灾备首备故障,跨region复制中断。
-
灾备CMS发起首备重新选举,类似主集群选主:首先锁分片,然后从剩余备副本中找到本地日志term最大、日志最大的那个副本,选为首备,最后再给剩余级联备副本下发连接新首备的命名。
-
先首备轮询主集群各个副本,请求跨region日志复制,流程同上。
-
灾备集群中,其他副本在从新首备请求日志复制时,可能会出现本地日志大于新首备的情况(故障再加回场景),由于日志不会发生分叉,因此在这种情况下,该日志较多的级联备只需要在日志一致性校验阶段等待新首备的日志超过本地日志即可。
CN支持流复制机制
根据上述分布式容灾搭建的对应关系,备集群CN需要和主集群的CN建立一对一的流式容灾关系以保证日志的持续拷贝和回放。该设计的基本思路同集群内的主备关系,但是不要求CN间复制是强同步的,所以修改CN的synchronous_commit = off,不阻塞主集群CN的提交。在备集群的CN和备机一样,以standby模式启动,当本地日志回放结束后0启动walreceiver线程通过解析replconninfo参数建立和主集群CN walsender的连接。由主集群CN walsender开始持续发送xlog日志,再由备集群CN本地回放日志使数据和主集群CN保证一致。故障处理和原集群内主备一致。当备CN未连接主CN时,备CN标记为disconnected状态;当日志crc校验不一致时备集群CN将自己的build reason标记为wal segments removed状态;当主备断连时标记为connecting状态。主要交互流程如图所示。
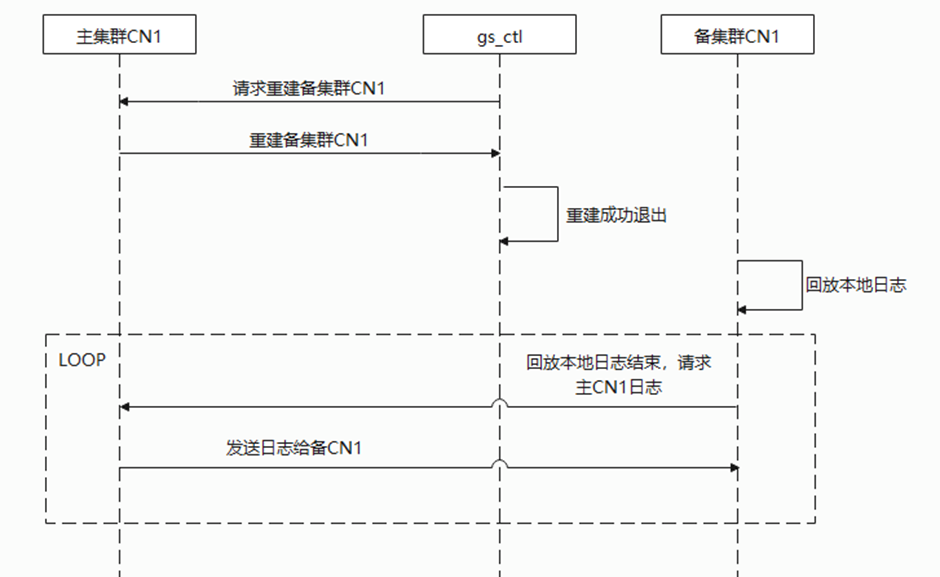
图 灾备集群搭建备集群CN实例build流程图
同时对于新增的CN流复制应考虑日志回收的逻辑。日志回收总体方案和原DN主备逻辑一致,先参考本地日志是否大于wal_keep_segments参数,若大于则主集群CN参考对应流复制槽,(目前只有备CN的槽位)日志落盘位置,保证正向场景下备CN所需日志不会被主CN回收。考虑到异常的备CN断连场景,主CN的日志回收应参考最大日志保留量max_size_for_xlog_prune参数,保证在不影响主集群CN可用性下,为备CN保留最多的日志,减少全量build的可能。
灾备集群的CN个数和主集群CN个数不对等场景下建立容灾关系
图中主备集群CN对应关系的处理说明:
受限于replconninfo配置个数的上限,集群达到一定规模后不可能将对端所有的节点链接信息都配上,所以OM在主备集群搭建容灾关系时CN依据如下计算方式进行对应。
当前使用CN instance id从小到大排序后的normal CN id list进行主备集群CN配对,比如主集群有M个normal CN,灾备集群有N的normal CN,对M,N中较小的值取模对应。可能出现的情况分析如下:
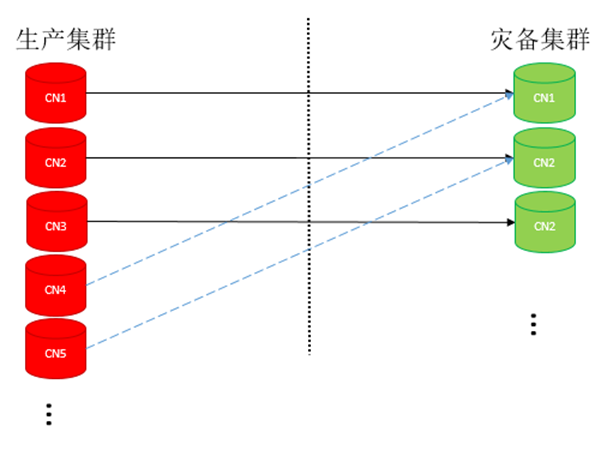
图 主集群CN多于灾备集群CN容灾搭建示例
(1)、如果主集群的CN多(上图M=5),灾备集群的CN少(上图N=3),以灾备集群的CN数量为准, 一对一进行build之后建立replication;主集群多出来的CN没有灾备CN对应,配置有容灾信息replconninfo,但不发生作用。灾备集群的CN会配置多条容灾使用的replconninfo,比如主集群的CN1挂了,灾备CN1可以连到CN4上触发build。
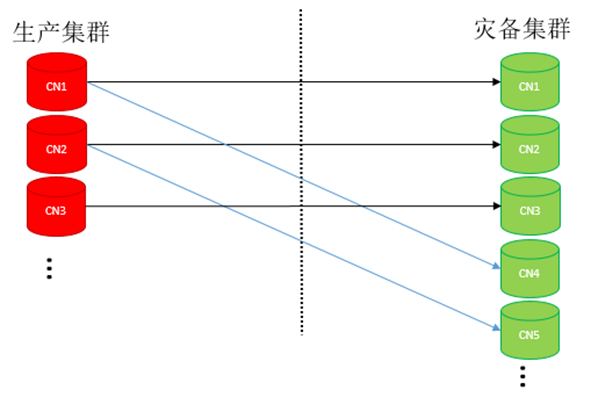
图 主集群CN少于灾备集群CN容灾搭建示例
(2)、如果灾备集群的CN多(上图N=5),主集群的CN少(上图M=3)(主要出现场景为计划内switchover、灾备集群升主后反向搭建容灾关系),此时灾备集群会有多个灾备CN同时和主集群相同CN建立流式复制的关系,比如上图上CN1和CN4都是与主集群的CN1建立容灾关系。
容灾过程中灾备故障CN的处理
1. 主集群CN故障导致灾备CN故障的处理机制
主集群处于容灾的CN发生剔除,或者主备集群间网络断链导致灾备CN处于故障状态,CN采用Need_repair(<build_reason>)上报机制,灾备CM对这一状态的CN不做剔除处理。
-
主集群处于容灾的CN发生剔除或者网络断链状态,灾备集群对应的CN感知到断连,将上报Need_repair(Disconnected)状态,并由CM显示。
-
主集群CN因为修复等操作发生build,灾备CN试图同步的日志和本地xlog日志不一致,灾备CN需要上报Need_repair(wal segment removed)等状态,灾备CMS感知后,会通知CN所在CMA下发CN全量build(从主集群对应cn build,build完成后自动拉起),build完成后CN恢复Normal状态。
-
相关命令gs_ctl build -b cross_cluster_full -Z coordinator -D <dir_path> -M standby。
-
灾备CN build期间,显示building状态,不参与barrier推进,也不参与备机只读的接入。
-
灾备集群的CN会将当前连接成功的生产集群CN的序号持久化到文件里边,重启后会从文件读取最近一次的CN序号,优先连接最近一次连接的成功的对端CN。在尝试连接失败次数达到一个阈值(当前阈值设定为3000次)时候,才会尝试连接下一个replication info里边的CN。
2. 灾备集群CN故障的处理机制
-
灾备的CN故障同主集群有所不同:灾备集群的CN是按standby起的,不会和其他CN/DN联系,满足条件(CN心跳超时25s、CN反复重启)会被剔除,置Deleted状态。Deleted状态的CN不参与barrier推进,也不参与备机只读的接入。
-
被剔除CN由CMA检测满足自动加回条件后进行自动修复,或手动进行CN修复。修复期间会触发全量build。修复完成后CN恢复Normal状态。要保证最后一个非超前状态的CN不触发build,否则会出现容灾集群无CN可用的暂态。
3. 灾备集群CN故障的告警
在容灾状态下,灾备集群CN如果出现Need_repair(Disconnected),上报容灾实例断连告警,并在Detail信息中体现本端实例id与对端实例id的容灾关联性。该告警信息上报管控。详见《3.3.8系统外部接口(和其他产品)》
4. 灾备集群CN状态转化汇总
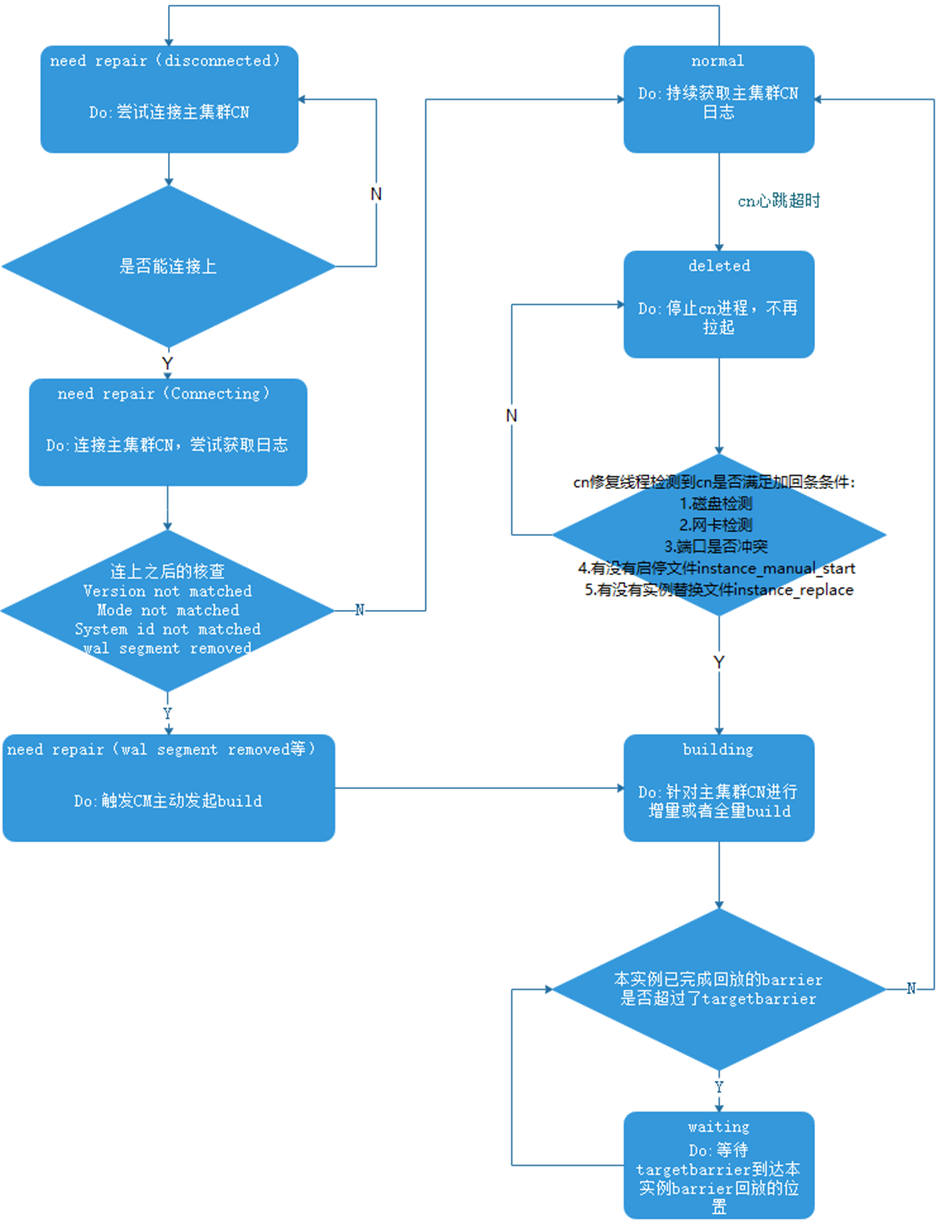
图 灾备集群CN状态转换
约束
-
对应集群只要有一个CN还活着,就能提供服务:容灾状态的集群同样保证最后一个CN不做剔除。
-
灾备集群需要始终保持至少一个CN不处于waiting或者deleted状态。
异地容灾集群间日志传输需要支持日志压缩
受客户场景跨集群间的网络带宽限制,将跨集群的xlog日志在发送端压缩,接收端解压,以提高传输效率。
1. 功能实现:
添加控制xlog压缩启停的guc参数enable_wal_shipping_compression,描述如下:
|-------------------------------------------------------------------------------------------------------------------------------------------------------------|
| enable_wal_shipping_compression **参数说明:**在流式容灾模式下设置启动跨集群日志压缩功能。 该参数属于SIGHUP类型参数。 取值范围:布尔型 该参数仅作用于跨集群传输的一对walsender与walreceiver中,作用于主集群DN。 **默认值:**false |
添加日志类型type 'C'用于表示被压缩的wal类型,在处理前会执行解压操作。
采用了已在Gauss库中的lz4无损压缩算法进行日志压缩,使用默认压缩级别LZ4_compress_default(),具体实现如下:
日志发送方的Walsender.cpp:
XLogSendPhysical()中,在XLogRead()函数将数据传入t_thrd.walsender_cxt.output_xlog_message前先进行压缩,并更改类型表示为'C',之后将压缩后的数据传入output_xlog_message,同时更改pq_putmessage_noblock中数据长度为压缩后的大小。
日志接收方的walreceiver.cpp:
XLogWalRcvProcessMsg()中,type='C'时,将buf中的数据先进行解压,用解压后的decompressBuf继续之后的逻辑。
为了减少cpu在压缩/解压上的性能损失,仅对异地容灾的流式复制开启压缩功能,集群内的流式复制不开启压缩功能。
2. 压缩率
在流式容灾集中式场景开发环境自测中,使用8核虚拟机tpcc 50仓 64并发进行tpcc测试,带宽充足场景下,tpcc执行中测得xlog压缩率平均在64.8%左右。
异地容灾的流控机制
流式容灾在集中式场景已经添加了流控参数,描述如下:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| hadr_recovery_time_target **参数说明:**在流式容灾模式下设置hadr_recovery_time_target能够让备集群完成日志写入和回放。 该参数属于SIGHUP类型参数。 取值范围:整型,0~3600 (秒) 0是指不开启日志流控,1~3600是指备机能够在hadr_recovery_time_target时间内完成日志的写入和回放,可以保证主集群与备集群切换时能够在hadr_recovery_time_target秒完成日志写入和回放,保证备集群能够快速升主。hadr_recovery_time_target设置时间过小会影响主机的性能,设置过大会失去流控效果。 **默认值:**0 |
| hadr_recovery_point_target **参数说明:**在流式容灾模式下设置hadr_recovery_point_target能够让备集群完成日志刷盘的rpo时间。 该参数属于SIGHUP类型参数。 取值范围:整型,0~3600 (秒) 0是指不开启日志流控,1~3600是指备机能够在hadr_recovery_point_target时间内完成日志的刷盘,可以保证主集群与备集群切换时日志差距能够在hadr_recovery_point_target秒内,保障备集群升主日志量。hadr_recovery_point_target设置时间过小会影响主机的性能,设置过大会失去流控效果。 **默认值:**0 |
这两个参数在客户对于异地容灾RPO,RTO有强烈需求的情况下,可以进行配置用于保证在任何时刻RPO,RTO都能达到客户要求。在分布式部署场景下,打开流控,流控机制会在分片级别上生效。
比如RPO目标是10s,hadr_recovery_point_target可配置为10s,超过这个值的时候,流控生效,会对主集群日志写入速率进行反压,降低业务性能来保证RPO达标。
比如RTO目标是10min,hadr_recovery_time_target可以配置60s,超过这个值的时候,流控生效,会对日志写入速率进行反压,降低业务性能来保证RTO达标。这里hadr_recovery_time_target控制灾备升主期间日志回放的耗时,是整个灾备集群升主流程耗时的一部分。
针对异地容灾的RPO需求,新增了RPO流控与原有的RTO流控共同作用,对应修改了系统视图global_streaming_hadr_rto_and_rpo_stat与gs_hadr_local_rto_and_rpo_stat中的current_sleep_time列为rto_sleep_time和rpo_sleep_time。
global_streaming_hadr_rto_and_rpo_stat参数说明:
| 参数 | 类型 | 描述 |
|---|---|---|
| hadr_sender_node_name | text | 节点的名称,包含主集群和备集群首备。 |
| hadr_receiver_node_name | text | 备集群首备名称。 |
| current_rto | int | 流控的信息,当前主备集群的日志rto时间(单位:秒)。 |
| target_rto | int | 流控的信息,目标主备集群间的rto时间(单位:秒)。 |
| current_rpo | int | 流控的信息,当前主备集群的日志rpo时间(单位:秒)。 |
| target_rpo | int | 流控的信息,目标主备集群间的rpo时间(单位:秒)。 |
| rto_sleep_time | int | RTO流控信息,为了达到target_rto这一预期,主机日志发送所需要的睡眠时间(单位:微秒) |
| rpo_sleep_time | int | RPO流控信息,为了达到target_rpo这一预期,主机日志生成所需要的睡眠时间(单位:微秒) |
gs_hadr_local_rto_and_rpo_stat参数说明:
| 参数 | 类型 | 描述 |
|---|---|---|
| hadr_sender_node_name | text | 节点的名称,包含主集群和备集群首备。 |
| hadr_receiver_node_name | text | 备集群首备名称。 |
| source_ip | text | 主集群主DN IP地址。 |
| source_port | int | 主集群主DN通信端口。 |
| dest_ip | text | 备集群首备DN IP地址。 |
| dest_port | int | 备集群首备DN通信端口。 |
| current_rto | int | 流控的信息,当前主备集群的日志rto时间(单位:秒)。 |
| target_rto | int | 流控的信息,目标主备集群间的rto时间(单位:秒)。 |
| current_rpo | int | 流控的信息,当前主备集群的日志rpo时间(单位:秒)。 |
| target_rpo | int | 流控的信息,目标主备集群间的rpo时间(单位:秒)。 |
| rto_sleep_time | int | RTO流控信息,为了达到target_rto这一预期,主机日志发送所需要的睡眠时间(单位:微秒) |
| rpo_sleep_time | int | RPO流控信息,为了达到target_rpo这一预期,主机日志生成所需要的睡眠时间(单位:微秒) |
集中式场景流控逻辑
rto计算逻辑是:
通过备机每次返回的最新落盘、回放lsn,计算备机日志落盘和回放的速度,估算当前备机所有已接收日志全部完成落盘、回放需要的时间,作为RTO。
rpo计算逻辑是:
通过主机新生成日志的速度,结合主备落盘日志量差值,估算当前主备日志差相当于主机多少秒的新增,作为RPO。
分布式场景流控逻辑
在分布式流式容灾中,为了保证分布式一致性采用全局一致性打点,对备机回放做了限制,即每个节点回放到全局targetBarrier点后会停止回放,等待下一个targetBarrier更新。
而灾备集群升主时,targetBarrier后的日志会被丢弃,因此不能与普通集群一样按flush点计算RTO/RPO
RTO新增逻辑是:
在集中式逻辑的基础上,因为灾备集群升主时,targetBarrier后的日志会被丢弃,所以当节点日志回放到targetBarrier后即可视为回放完成,RTO=0。
灾备集群各节点会将当前是否回放到targetBarrier点,返回给对应的主集群节点,标记此时rto=0。
RPO计算逻辑是:
由于targetBarrier后的日志灾备升主时会被丢弃,所以应该以备机targetBarrier点与主机最新日志计算RPO。
barrierId的最后13位为其生成时的时间信息,RPO算法利用这个时间戳,由灾备返回targetBarrierID,与主机最新生成的currentBarrierID比较,时间差即是灾备升主时丢失日志的时间长度。
周期性全局一致性打点与推进
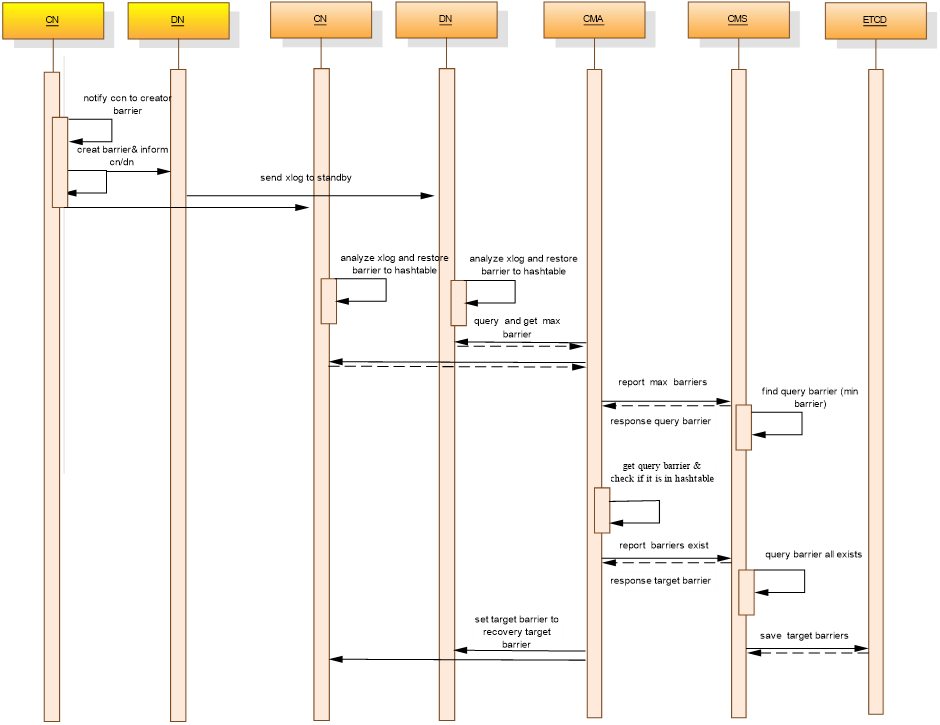
图 barrier处理消息序列图
消息序列图说明
如上图所示是一个barrier点从生成到删除的整个过程,大致可以分为四个部分:barrier生成、barrier解析存储、barrier推进、barrier删除。其中barrier推进是最重要的一环,有它来确定各备节点恢复的位置来达到一致性要求。
详细设计
Barrier生成
Barrier生成是Barrier一致性的前提。Barrier点任一CN都可以发起,但由第一个CN负责生成。若发起barrier生成的CN不是第一个CN,则通知第一个CN进行生成。生成后CN与DN将其落到xlog日志中。
负责打点的CN会启动barrier_crearor线程从GTM获取CSN,来生成barrier,格式如下:
生成的CSN类型barrier信息格式为 "csn_%021lu_%013ld",头部信息固定为csn_,中间21位为得到的csn号,最后13位为时间信息,当前仅用于RPO计算。
Barrier解析存储
Barrier解析存储是Barrier一致性的基础,备集群上对应的备节点通过walreciever收到xlog日志后,将日志落盘。通过新添加barrier解析线程对新落盘的日志进行预解析,并将解析到的barrier存储在hash table中,并保存当前收到的最大barrier。Hash table在创建日志解析线程前进行创建,在集群卸载时进行释放。Hash table中储存着解析出来的barrier,这些barrier将在回放xlog日志时进行删除。
Barrier推进
Barrier解析存储是Barrier一致性的关键,这部分稍微复杂一些,需要CN、DN、CMA、CMS、ETCD相互配合进行。barrier一致性点的推进需要五步:
-
CMA通过sql函数查询CN、DN的barrier最大值上报至CMS。此处的barrier为预解析结果,日志实际还未回放;
-
CMS通过收齐各个实例上报的barrier,将其中的最小值作为query barrier;
-
CMA从CMS获取到query barrier,调用sql函数对CN、DN进行查询,确认是否存在该barrier点,将结果上报给CMS。CMS收齐后判断,若该query barrier已达到多数派条件,则作为target barrier点,否则舍弃;
-
CMA读取CMS里存放的target barrier,更新CMA本地的target barrier;
-
CMA通过sql函数设置CN,DN实例的recovery barrier设置为targer barrier。
在一次上报中,CMA需要查询执行barrier最大值的上报、本地查询querybarrier是否存在,更新targetbarrier这三步;CMS需要执行querybarrier的更新和targetbarrier的更新。
其他说明:
-
Querybarrier达到多数派成为target barrier的条件。
-
单一DN分片内多数派已上报该barrier。
-
所有DN分片都已上报该barrier。
-
CN多数派已经上报该barrier。
CN多数派数目动态调整策略:由于主集群允许cn剔除到只有一个cn,所以在故障场景下cn多数派的数目要随时调整,策略为:
-
CN多数派初始值为n_cn=init_cn_number/2 +1。
-
当发现barrier在1分钟内因为达不成cn多数派无法推进,n_cn--;极限值n_cn>=1。
-
当发现barrier可以有大于 n_cn个数的cn参与推进barrier,n_cn++;极限值n_cn<=init_cn_number/2 +1。
灾备集群CN不同状态参与barrier推进的情况
容灾过程中灾备集群中被Deleted,building的CN对CM的barrier查询请求不会有响应。
由于灾备集群CN发生build导致barrier超前推进,它处于等待其他CN的waiting状态,或者容灾过程中灾备集群中处于need repair态的CN是有可能查到CM请求的barrier的,会参与barrier推进。
灾备集群CN处于waiting状态的条件
改造基于OBS异地容灾方案中增加的sql函数gs_get_local_barrier_status()查询得到当前CN实例redo的barrier。CM通过该函数获得CN实例当前redo的localbarrier,与targetbarrier进行比较,localbarrier>targetbarrier时,该CN置为waiting状态。该状态与CN其他状态的转化参见《3.3.6.3容灾过程中灾备故障CN的处理》。
Barrier删除
Barrier删除是barrier一致性的终点,Barrier删除发生在xlog日志回放中,在日志回放时,回放到barrier会对回放位置recoverybarrier进行更新,并在hash table将该barrier点删除,完成barrier从生成到删除的全过程。
- END -