无服务器函数非常适合小任务
使用无服务器功能的云计算已广受欢迎。它们对实现新功能的吸引力源于无服务器计算 的简单性。您可以使用无服务器功能来分析传入的照片或处理来自 IoT 设备的事件。它快速、简单且可扩展。您不必分配和维护计算资源 - 只需部署应用程序代码。主要的云供应商,包括AWS、 Microsoft和 Google,都提供无服务器功能。
对于简单或临时的应用程序,无服务器功能非常有意义。但它们是否适合读取和更新持久的关键任务数据集的复杂工作流?考虑一家每天管理数千个航班的航空公司。可扩展的 NO-SQL 数据存储(如 Amazon Dynamo DB 或 Azure Cosmos DB)可以存储描述航班、乘客、行李、登机口分配、飞行员调度等的数据。虽然无服务器功能可以访问这些数据存储来处理事件(例如航班取消和乘客重新预订),但它们是实现航空公司所依赖的大量事件处理的最佳方式吗?

问题和限制
无服务器函数的优势在于它是无服务器的,这也带来了内在限制。就其本质而言,调用时需要开销来分配计算资源。此外,它们是无状态的,必须从外部数据存储中检索数据。这进一步降低了它们的速度。它们无法利用本地内存缓存来避免数据移动;数据必须始终通过云网络流向无服务器函数运行的位置。
在构建大型系统时,无服务器函数也无法提供用于实现复杂工作流的清晰软件架构。开发人员需要在每个函数运行的代码中强制执行清晰的"关注点分离"。在创建多个无服务器函数时,很容易陷入重复功能的陷阱,并产生复杂且难以管理的代码库。此外,无服务器函数可能会产生不寻常的异常,例如超时和配额限制,这些异常必须由应用程序逻辑处理。
替代方案:将代码移至数据
我们可以通过相反的做法来避免无服务器函数的局限性:将代码移到数据中。考虑使用可扩展的内存计算来运行无服务器函数实现的代码。内存计算将对象存储在分布在服务器集群中的主内存中。它可以通过接收消息来调用这些对象上的函数。它还可以检索数据并将更改保存到数据存储(例如 NO-SQL 存储)中。
我们无需定义一个无服务器函数来操作远程存储的数据,只需向内存计算平台中的对象发送一条消息来执行该函数即可。这种方法无需重复访问数据存储,从而加快了处理速度,减少了必须通过网络传输的数据量。由于内存数据计算具有高度可扩展性,因此它可以处理涉及大量对象的超大工作负载。此外,高可用性消息处理避免了应用程序代码处理环境异常的需要。
内存计算通过结合数据结构存储(如 Redis)和参与者模型的优势,为定义复杂工作流的结构化代码提供了关键优势。与无服务器函数不同,内存数据网格可以将对象的处理限制为其数据类型定义的方法。这有助于开发人员避免在多个无服务器函数中部署重复的代码。它还避免了实现对象锁定的需要,这对于持久数据存储来说可能是有问题的。
基准测试示例
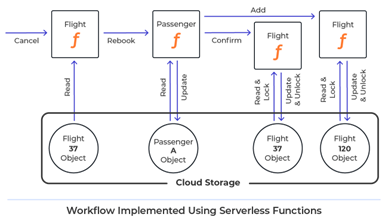
为了衡量无服务器函数和内存计算之间的性能差异,我们将使用 AWS Lambda 函数实现的简单工作流与使用 ScaleOut Digital Twins(一种可扩展的内存计算架构)构建的相同工作流进行了比较。此工作流代表航空公司可能用来取消航班并重新预订其他航班的所有乘客的事件处理。它使用两种数据类型,即航班和乘客对象,并将所有实例存储在 Dynamo DB 中。事件控制器触发一组航班的取消并测量完成所有重新预订所需的时间。
在无服务器实施中,事件控制器触发 lambda 函数来取消每个航班。每个"乘客 lambda"通过选择其他航班并更新乘客信息来重新预订乘客。然后,它触发无服务器函数,确认从原始航班中删除乘客并将乘客添加到新航班。这些功能需要使用锁定来同步对 Dynamo DB 对象的访问。
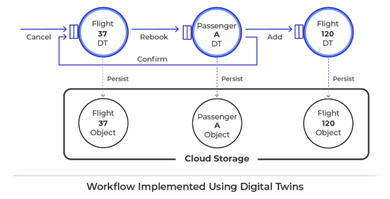
当从 Dynamo DB 访问这些对象时,数字孪生实现会为所有航班和乘客动态创建内存对象。航班对象从事件控制器接收取消消息,并向乘客数字孪生对象发送消息。乘客数字孪生通过选择其他航班并向新旧航班发送消息来重新预订。应用程序代码不需要使用锁定,内存平台会自动将更新保存回 Dynamo DB。
性能测量表明,数字孪生处理 25 个航班取消(每个航班有 100 名乘客)的速度比无服务器功能快 11 倍以上。我们无法扩展无服务器功能来运行取消 250 个航班(每个航班有 250 名乘客)的目标工作负载,但 ScaleOut 数字孪生可以轻松处理 500 个航班的两倍目标工作负载。
总结
虽然无服务器函数非常适合小型和临时应用程序,但在构建必须管理许多数据对象并扩展以处理大量工作负载的复杂工作流时,它们可能不是最佳选择。使用内存计算将代码移动到数据中可能是更好的选择。它通过最小化数据移动来提高性能,并提供高可扩展性。它还通过利用结构化数据访问来简化应用程序设计。