大家好,我是程序员鱼皮。前两天模拟面试一位社招两年的老哥,由于他的表现不错,我就临时起意,跟他交流一下我们最近遇到的业务场景问题。问题如下:
最近我们不是做了个 程序员刷题网站 - 面试鸭 嘛,有很多坏人盯上了我们网站,想把我们 4,000 多道面试题、100 多个面试题库的数据都用爬虫抓下来。那我们应该如何防止这种爬虫行为?比如怎么识别出这些非法爬取数据的用户并且自动封号?
整个问题的交流过程大家可以看视频学习:https://www.bilibili.com/video/BV1b142187Tb
下面我就直接把防止爬虫的方法汇总分享给大家,总共有整整 10 种方法!最后一个方法很独特~
如何防止网站被爬虫?
1、使用协议条款
robots.txt 是一个放置在网站根目录下的文件,用于告诉搜索引擎的爬虫哪些部分不希望被抓取。
举个例子,可以在 robots.txt 文件中添加如下规则来禁止特定目录或文件被抓取:
User-agent: *
Disallow: /private/
Disallow: /important/虽然大多数合规的爬虫会遵守这些规则,但恶意爬虫可能会忽视它,所以,仅凭 robots.txt 不能完全阻止所有爬虫。但它是防护的第一步,起到一个声明和威慑的作用。
可以在网站的服务条款或使用协议中明确禁止爬虫抓取数据,并将违反这些条款的行为视为违法,如果网站内容被恶意爬虫抓取并造成了损害,robots.txt 可以作为违反这些条款的证据之一。
2、限制数据获取条件
比起直接暴露所有数据,可以要求用户登录或提供 API 密钥才能访问特定数据。还可以为关键内容设置身份验证机制,比如使用 OAuth 2.0 或 JWT(JSON Web Tokens),确保只有授权用户能够访问敏感数据,有效阻止未经授权的爬虫获取数据。
3、统计访问频率和封禁
可以利用缓存工具如 Redis 分布式缓存或 Caffeine 本地缓存来记录每个 IP 或客户端的请求次数,并设置阈值限制单个 IP 地址的访问频率。当检测到异常流量时,系统可以自动封禁该 IP 地址,或者采取其他的策略。
需要注意的是,虽然 Map 也能够统计请求频率,但是由于请求是不断累加的,占用的内存也会持续增长,所以不建议使用 Map 这种无法自动释放资源的数据结构。如果一定要使用内存进行请求频率统计,可以使用 Caffeine 这种具有数据淘汰机制的缓存技术。
4、多级处理策略
为了防止 "误伤",比起直接对非法爬虫的客户端进行封号,可以设定一个更灵活的多级处理策略来应对爬虫。比如,当检测到异常流量时,先发出警告;如果爬虫行为继续存在,则采取更严厉的措施,如暂时封禁 IP 地址;如果解封后继续爬虫,再进行永久封禁等处罚。
具体的处理策略可以根据实际情况来定制,也不建议搞的太复杂,别因此加重了系统的负担。
5、自动告警 + 人工介入
可以实现自动告警能力,比如在检测到异常流量或爬虫行为时,系统能自动发出企业微信消息通知。然后网站的管理员就可以及时介入,对爬虫的请求进行进一步分析和处理。
这点之前也给大家分享过,不止是针对爬虫,企业的线上系统最好接入全方面的告警,比如接口错误、CPU / 内存占用率过高之类的。
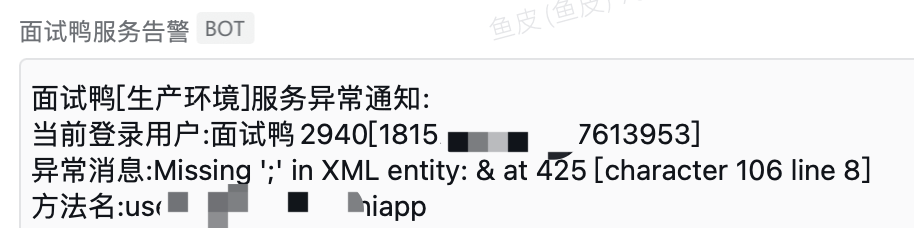
6、爬虫行为分析
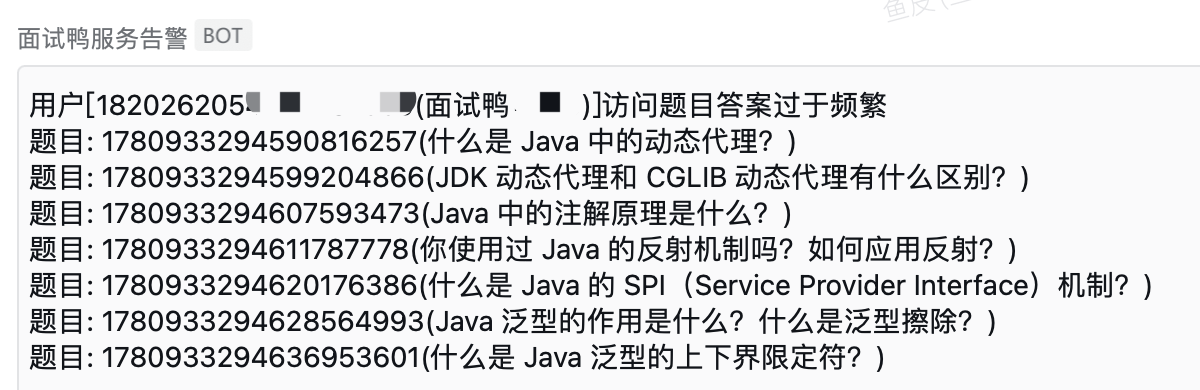
非法爬虫和正常用户的行为一般是有区别的,爬虫往往遵循特定的访问模式。比如正常用户每道题目都要看一会儿、看的时间也不一样,而爬虫一般是按照固定的顺序、固定的频率来获取题目,很明显就能识别出来。
比如下面这种情况,有可能就是爬虫:
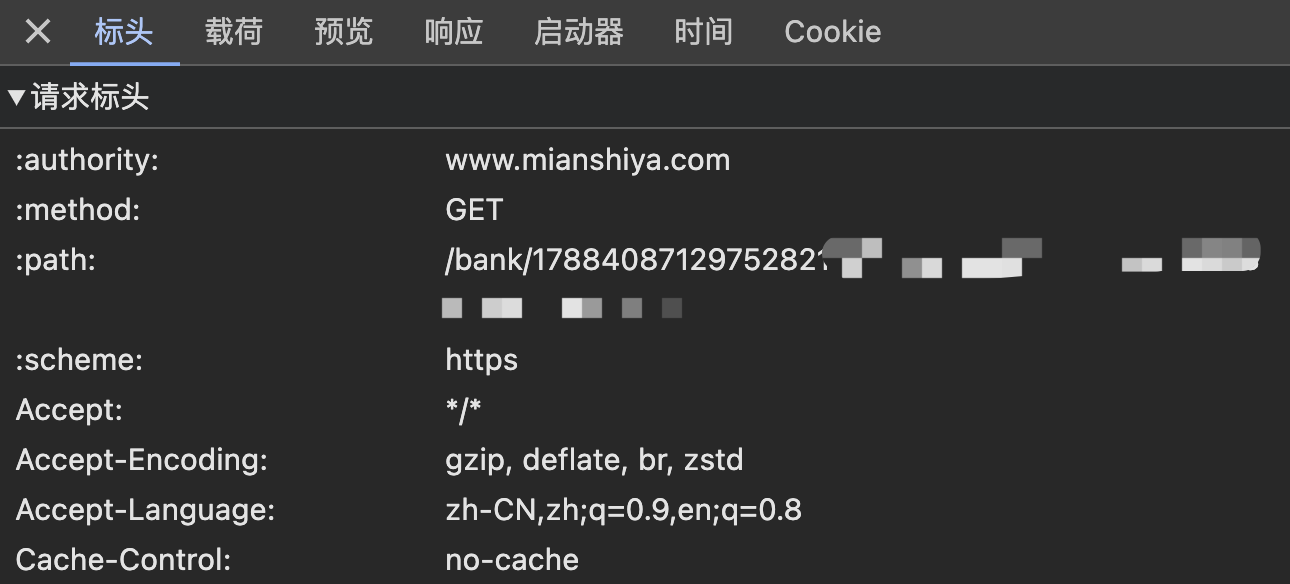
7、请求头检测
每个发送到服务器的请求都有请求头信息,可以通过检查请求头中的 User-Agent 和 Referer 等标识符,对爬虫请求进行拦截。
当然,这招只能防防菜鸟,因为请求头是可以很轻松地伪造的,只要通过浏览器自带的网络控制台获取到响应正常的请求头信息,就可以绕过检测了。
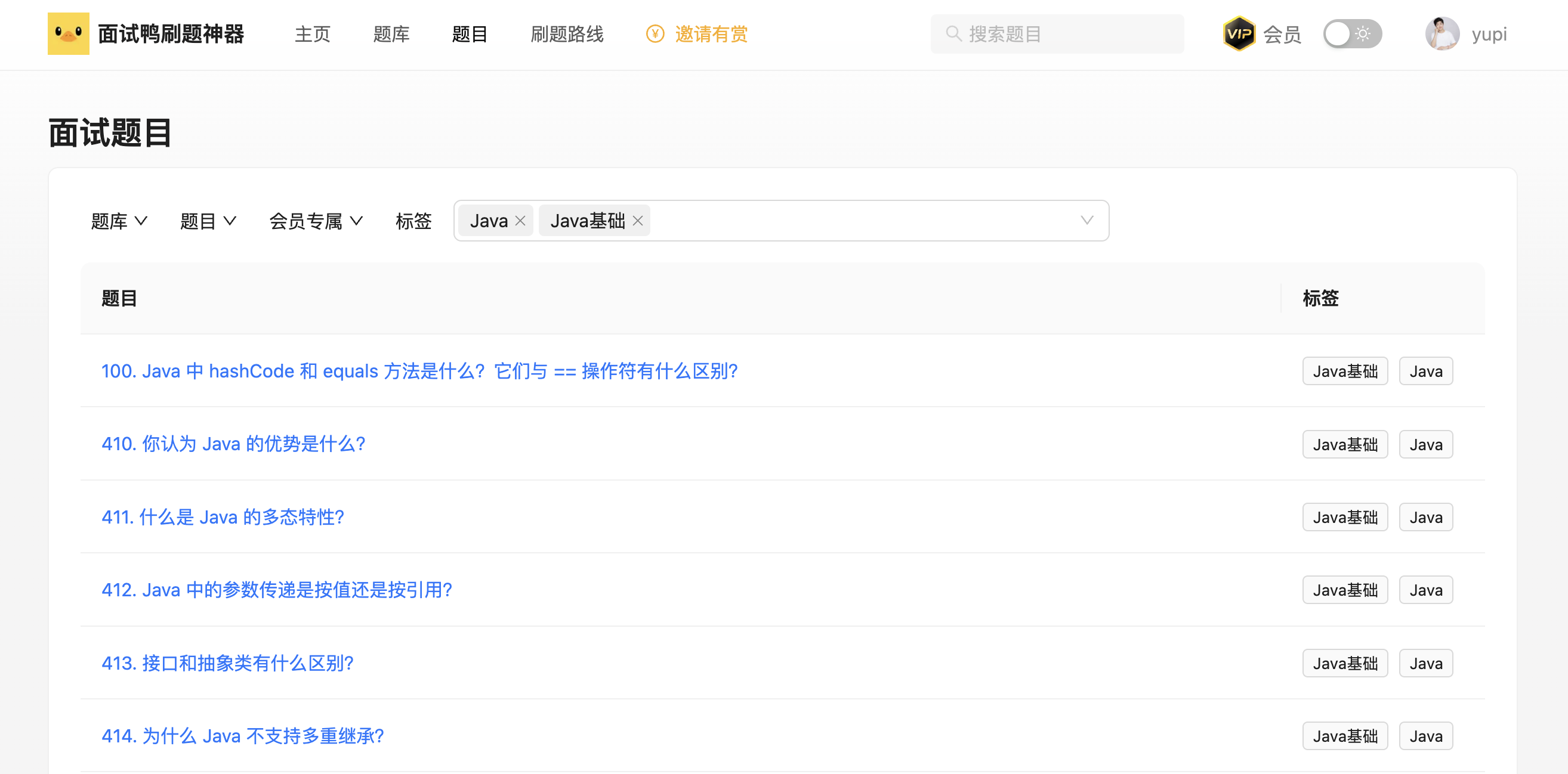
8、自主公开数据
记得大学上信息安全课的时候,学到一个知识点:防止网络攻击的一种方法是,让攻击者的成本大于实际的收益。比如密码 10 分钟有效,破解密码要花 15 分钟,就不会有人去破解。
用到爬虫场景上,我们的做法是,不做任何限制,直接让所有人不登录也能查看到我们网站的题目数据!而且还提供了题目的各种筛选功能、收藏功能。大多数同学只是为了自己学习,这样一来,就没有必要花时间去爬数据了~
9、溯源技术
虽然题目都是公开的,但有些我们专门请大厂大佬们来写的优质题解是仅会员可见的。如果有用户使用爬虫抓取了这部分数据,可就要小心了!一般来说,只要你在一个网站登录了,就一定会有访问记录,如果你泄露了网站登录后才可见的内容、尤其是付费内容,网站管理员一定有办法追溯到你是谁。
比较常用的溯源技术就是水印、盲水印等。对于我们的面试鸭,本身就是通过微信登录的,而且如果你是会员,肯定还有支付记录。这些技术不仅帮助标记数据源,还可以在数据被滥用时追踪其来源,从而增强数据的保护。
10、科普法律
除了上面这些方法外,还可以通过接入反爬服务、接入验证码、增加动态时间戳等方式进一步限制爬虫。但是要记住,爬虫是没有办法完美防御的!因为你无法限制真实的用户,攻击者完全可以模拟真实用户的访问方式来获取你的网站数据,比如找 10 个用户,每人获取几百题。
所以我的最后一个方法是 ------ 科普法律。可以在网站上发布明确的法律声明,告知用户未经授权的抓取行为是违法的,可以对爬虫行为起到一定的威慑作用。并且还通过发布视频和文章的方式,让广大程序员朋友们提高法律意识。爬虫是有一定风险的,自己学习倒没问题,但是千万别给人家的网站造成压力了,搞不好就有破坏计算机系统的嫌疑了!

更多
💻 编程学习交流:编程导航
📃 简历快速制作:老鱼简历
✏️ 面试刷题神器:面试鸭