基于zynq的图像视频数据采集处理项目一
文章目录
- 基于zynq的图像视频数据采集处理项目一
-
- 1.整体的架构
- 2.整体的时钟和复位设计
- 3.详细方案设计
-
- [3.1 ps端spi对摄像头的配置,数据的dvp口截断输入](#3.1 ps端spi对摄像头的配置,数据的dvp口截断输入)
- [3.2 看手册对 IMX2221080P 模式图像解析](#3.2 看手册对 IMX2221080P 模式图像解析)
- [3.3 拜耳图像格式转换为 RGB 图像](#3.3 拜耳图像格式转换为 RGB 图像)
- [3.4 灰度域的白平衡算法 white Balance 的 RTL 实现](#3.4 灰度域的白平衡算法 white Balance 的 RTL 实现)
- [3.5 dma的读写](#3.5 dma的读写)
-
- [3.5.1 设计思路](#3.5.1 设计思路)
- [3.5.2 基地址的选择](#3.5.2 基地址的选择)
- [3.6 hdmi发送器](#3.6 hdmi发送器)
- [3.7 跨时钟域的处理](#3.7 跨时钟域的处理)
-
- [3.7.1 多比特的跨时钟域](#3.7.1 多比特的跨时钟域)
-
- [3.7.1.1 fifo的理论深度设计(前提条件是fifo两边的读写带宽对等)](#3.7.1.1 fifo的理论深度设计(前提条件是fifo两边的读写带宽对等))
- [3.7.1.2 图像预处理到ddr之间的跨时钟域](#3.7.1.2 图像预处理到ddr之间的跨时钟域)
-
- [3.7.1.2.1 深度的考量](#3.7.1.2.1 深度的考量)
- [3.7.1.2.2 读写带宽对等的设置](#3.7.1.2.2 读写带宽对等的设置)
- [3.7.1.3 ddr到图像显示之间的跨时钟域](#3.7.1.3 ddr到图像显示之间的跨时钟域)
-
- [3.7.1.3.1 深度的考量](#3.7.1.3.1 深度的考量)
- [3.7.1.3.2 读写带宽对等的设置](#3.7.1.3.2 读写带宽对等的设置)
- [3.7.2 单比特的跨时钟域](#3.7.2 单比特的跨时钟域)
- [3.8 防撕裂设计](#3.8 防撕裂设计)
- [3.9 抓拍功能](#3.9 抓拍功能)
- 4.模块验证
-
- [4.1 spi配置摄像头是否成功的验证](#4.1 spi配置摄像头是否成功的验证)
- [4.2 解析图像有效数据模块的验证](#4.2 解析图像有效数据模块的验证)
- [4.3 bayer to rgb模块的验证](#4.3 bayer to rgb模块的验证)
- [4.4 灰度白均衡的模块的验证](#4.4 灰度白均衡的模块的验证)
- [4.5 axi wr的验证](#4.5 axi wr的验证)
- [4.6 axi rd的验证](#4.6 axi rd的验证)
- [4.7 hdmi发送器的验证](#4.7 hdmi发送器的验证)
- 5.遇到的困难如何解决
- 6.时序分析
- 7.小tips
-
- [7.1 ps端和pl端的联调](#7.1 ps端和pl端的联调)
- [7.2 管脚的绑定](#7.2 管脚的绑定)
- [7.3 地址分配问题](#7.3 地址分配问题)
- [7.4 axi interconnect和smartconnect](#7.4 axi interconnect和smartconnect)
- [7.5 复位ip的使用](#7.5 复位ip的使用)
1.整体的架构
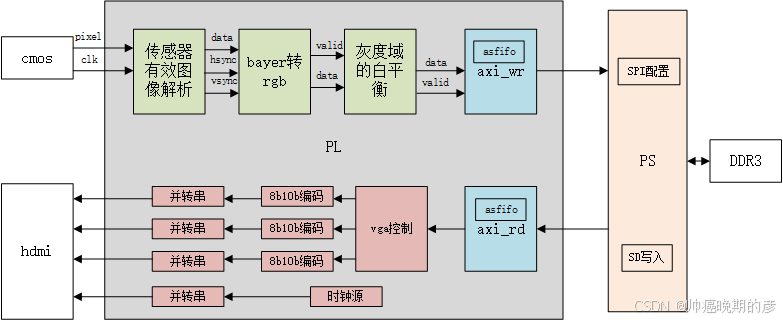
2.整体的时钟和复位设计
时钟域分为:
1.图像预处理时钟:它由外部cmos芯片源同步传递过来,作用于传感器解析模块;byer转rgb模块;灰度域白均衡模块(74.25MHz)
2.axi 读写时钟:它由ps端给出的axi时钟200MHz
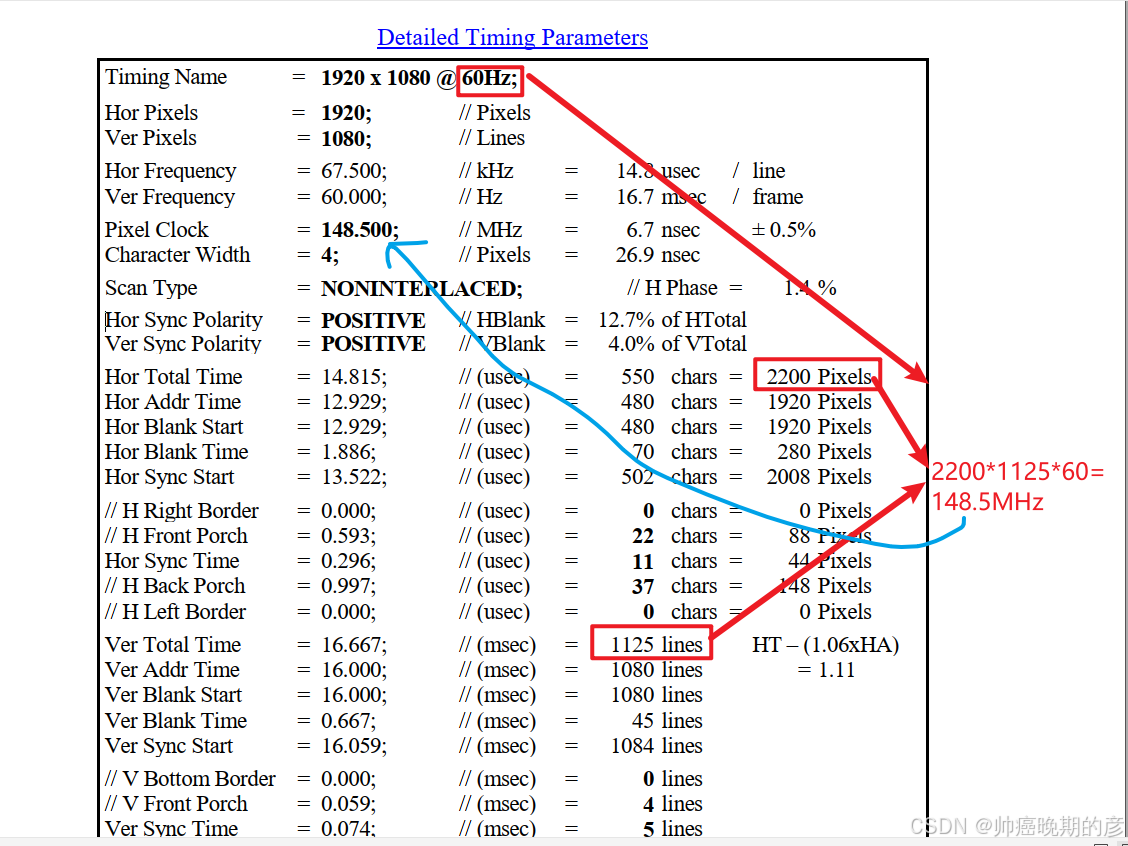
3.视频输出时钟:它由pll(clkin由ps端给出的100MHz)产生的148.5MHz(1920x1080 @60Hz)
4.给到serdes的管脚时钟:为视频输出时钟的5倍
复位分为:(都通过了异步复位同步释放)
1.图像预处理复位:它由ps通过gpio给出(与axi wr模块启动信号同源)
2.axi wr/rd复位:它由ps给出PS-PL configuration配置给出,通过复位ip核同步于ps端给出的axi时钟200MHz
3.视频输出复位:pll的locked信号
3.详细方案设计
3.1 ps端spi对摄像头的配置,数据的dvp口截断输入
fpga芯片配置imx222寄存器的接口采用spi接口协议,
spi详细解读以及配置请看我的博文
https://blog.csdn.net/weixin_45284871/article/details/141001874
主要是在vitis端用封装好的spi函数来对摄像头中的寄存器进行配置。这里 SPI 配置时序要求先发 LSB 最后发 MSB,与xilinx的zynq的PS端提供的驱动程序相反,我们再发送数据时需要进行高低位对调操作。
spi配置的是cmos模组12bit的模式,dvp并口数据(CMOS电平信号)的12根线接到FPC软排线然后再接到fpga,数据PIXEL_RGB只用12bit的高8位,PIXEL_RGB就只是绑定了高8位的管脚
3.2 看手册对 IMX2221080P 模式图像解析
图像传感器输出的是图像是那种嵌入式同步字机制(帧头或者帧尾一样的机制),要对输出的嵌入式同步字和有效行场信号进行解析。通过4个字节的无效行开始,4个字节的无效行结束,4个字节的有效行开始,4个字节的有效行结束,然后再根据相机的行场细节来解析出有效的图像1920*1080的模式。
用一个移位寄存器,高位先来,往左推箱子
verilog
always @(posedge clk) begin
shift_reg <= {shift_reg[23:0],bayer};
endshift_reg来判断当前行是不是有效行
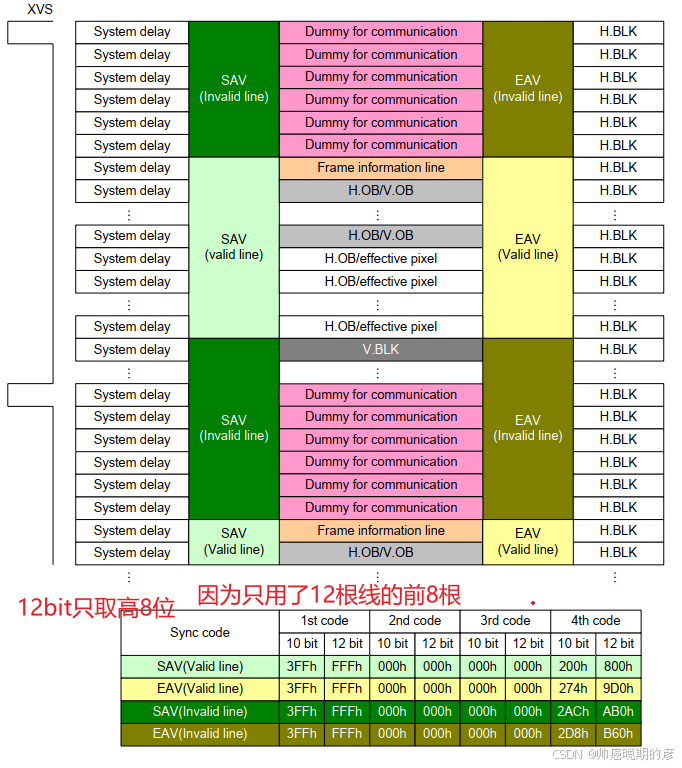
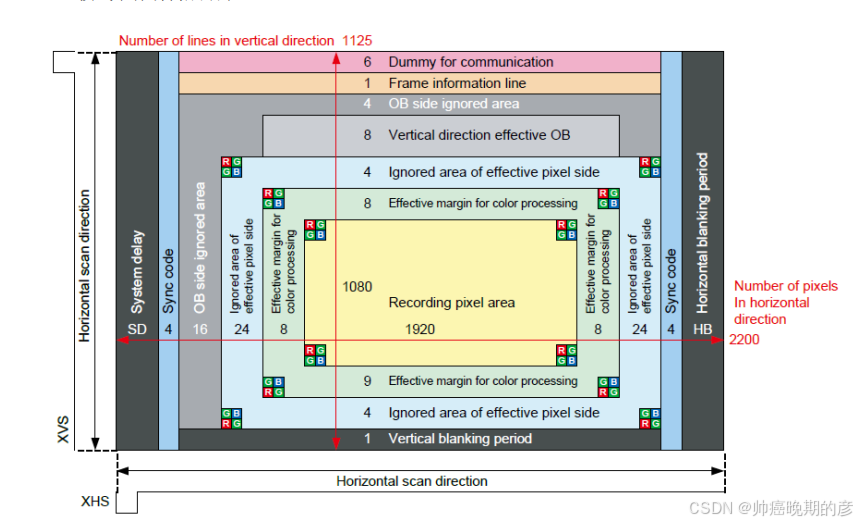
主要就是写状态机(因为事件发生有前后顺序),在不同的状态(无效行状态,有效行状态)处理图像数据。注意,为了后续的处理,需要多解析有效图像的的外围一圈像素 ,然后将有效图像的行场有效信号传递给bayer2rgb模块。

这里的输入的数据需要打一拍,以和解析出来的有效图像的行场有效信号,可以说是一级流水
3.3 拜耳图像格式转换为 RGB 图像
拜尔图像就是他一个点只有一个颜色通道分量的值,8bit,
主要就是用三个移位寄存器和两个fifo实现一个3X3的滑动矩形窗,矩形窗中心位置就是我们要差值出rgb三个通道的像素点,(怎么插值,需要根据像素的行列索引号来确定------奇行奇列是什么样的插值算法,偶行偶列是什么插值算法这样)

具体的过程描述
图像的第0行缓冲到fifo0,第1行缓冲到fifo1,第3行第一个有效像素来的时候,开始对fifo0和fifo1进行读出,fifo0的读出dout0送入24位的移位寄存器reg000102,fifo1的读出dout1送入24位的移位寄存器reg101112,pixel的直接送入24位的移位寄存器reg202122,与此同时pixel(第3行第一个有效像素来的时候)作为fifo1的输入,fifo1的输出dout1作为fifo0的输入,fifo0的输出dout0就扔掉不要了,直到整个一帧有效图像结束。
(这里的fifo深度就是能缓存一行图像就行)
fifo0的读写使能,和数据代码
verilog
//r_fifo_en
//第三行数据来临开始读出
always @(*) begin
if(frame_valid == 1'b1 && vcnt != 'd0 && vcnt != 'd1 && hsync)begin
r_fifo_en = 1'b1;
end
else begin
r_fifo_en =0;
end
end
//w_fifo_0_data
//先是缓存一帧图像的首行,后面缓存fifo1的输出dout1
always @(*)begin
if(frame_valid == 1'b1 && vcnt == 'd0) begin
w_fifo_0_data <= pixel;
end
else begin
w_fifo_0_data <= dout1;
end
end
//w_fifo_0_enfifo0在一帧数据pixel的0行和除了最后1行之外的时候保持写入
always @(*) begin
if(frame_valid == 1'b1 && vcnt != 'd1 && vcnt != VCNTMAX && hsync)begin
w_fifo_0_en = 1'b1;
end
else begin
w_fifo_0_en = 0;
end
end
//FIFO深度能缓存1行数据1920即可,这里是2048
sfifo_2048x8 sfifo_2048x8_0_inst (//
.clk(clk), // input wire clk
.din(w_fifo_0_data), // input wire [7 : 0] din
.wr_en(w_fifo_0_en), // input wire wr_en
.rd_en(r_fifo_en), // input wire rd_en
.dout(dout0), // output wire [7 : 0] dout
.full(), // output wire full
.empty() // output wire empty
);fifo1的读写使能,和数据代码
verilog
//w_fifo_1_data 一直让它等于输入进来的pixel即可
always @(*)begin
w_fifo_1_data <= pixel;
end
//w_fifo_1_en fifo1从一帧数据pixel的第1行和除了最后1行之外的时候保持写入
always @(*) begin
if(frame_valid == 1'b1 && vcnt != 'd0 && vcnt != VCNTMAX && hsync)begin
w_fifo_1_en = 1'b1;
end
else begin
w_fifo_1_en =0;
end
end
//rd_en和fifo0的一样
//
sfifo_2048x8 sfifo_2048x8_1_inst (
.clk(clk), // input wire clk
.din(w_fifo_1_data), // input wire [7 : 0] din
.wr_en(w_fifo_1_en), // input wire wr_en
.rd_en(r_fifo_en), // input wire rd_en
.dout(dout1), // output wire [7 : 0] dout
.full(), // output wire full
.empty() // output wire empty
);三个移位寄存器形成矩形窗
verilog
always @(posedge clk ) begin
if (r_fifo_en == 1'b1) begin
reg000102 <= {reg000102[15:0],dout0};
reg101112 <= {reg101112[15:0],dout1};
reg202122 <= {reg202122[15:0],pixel};
end
end具体的设计时序如图:

3.4 灰度域的白平衡算法 white Balance 的 RTL 实现
白平衡算法的实现:是后面加的,因为出来的图像有点偏绿,色温有问题。所以采用灰度域的白平衡算法,一般得现在c语言里面做定点化验证效果(比如写一张图像到sd卡导出来做算法的定点化验证),然后再做的RTL的设计
RTL中的设计为:计算上一帧图像的所有像素的 R, B, G通道的平均值 Ravg, Bavg, Gavg。以及上一帧图像的 R/G/B 平均值的平均值又称作灰度平均值 Kavg。在得到上一帧图像的上述四个参数后,根据这四个参数,用这4个值算出增益,来对当下的这一帧图像进行白平衡处理(所以第一帧是处理不了的)。增益计算如下:

如果红色分量的平均值大于灰度平均值的话就会使 red 分量变少,反之增大一点,当计算结果大于 255(溢出)时,固定输出为 255,由此得到白平衡处理后的图像输出数据。过程中涉及到的除法器,如果误差不太大的话+除数为固定值,就可以直接截位。这样可以节约资源。
Ravg颜色通道是将进来的8位i_data_r分量全部相加,用ri_data_r_sum来寄存,
ri_data_r_sum的位宽既是19201080 255,即29位即可,在一帧信号标志下降沿的时候清零上一帧的sum和并计算上一帧的颜色通道平均值(为了计算本帧的sum和),在有效行信号来的时候开始计算sum
代码如下:
verilog
// ri_data_r_sum
always @(posedge i_clk or posedge i_rst) begin
if (i_rst) begin
ri_data_r_sum <= 'd0;
end
else if(i_fv_flag_fall) begin//在一帧信号标志下降沿的时候清零上一帧的sum
ri_data_r_sum <= 'd0;
end
else if(i_hv_flag) begin//在有效行信号来的时候开始计算sum
ri_data_r_sum <= i_data_r + ri_data_r_sum;
end
else
ri_data_r_sum <= ri_data_r_sum;
end
// data_ravg
always @(posedge i_clk or posedge i_rst) begin
if (i_rst) begin
data_ravg <= 'd0;
end
else if(i_fv_flag_fall) begin//在一帧信号标志下降沿的时候计算上一帧的颜色通道平均值
data_ravg <= ri_data_r_sum[29:21];//这里直接截位计算,相当于除以1920*1080
end
else
data_ravg <= data_ravg;
end其他的乘除就调用ip核,调用ip核的时候都选择了只使用lut和ff资源的模式,所以最后我们可以看到项目的dsp资源使用为0

最后数据有效信号传递给下一模块的即复用除法器除出来的valid信号就行

3.5 dma的读写
3.5.1 设计思路
自己根据例程修改,然后完成wr/rd 的64位宽256突发的HP口 axi dma 模块编写;
采用自己creat axi4 peripheral的axi dma 读和写模块来做dma读写;不用现的axi direct access ip核是因为这个IP是 stream转换MMP,ps要配置每次搬数据量大小 起始地址,ps初始化参与。MMP接口会,如果dma数据量很大,MMP接主动多次的 重读读和重复的写,出现outstanding不匹配的问题。ready 信号能按照要求拉高,只能复位之后才能继续工作。
vdma ip 没有什么bug,相对说需要ps的动态配置 帧buffer 和起始地址长度。
3.5.2 基地址的选择
为什么基地址要选择0x02000000
- 要给前面的c语言程序留点ddr地址空间,你在vitis里面申明的变量都要在ddr里面占用空间
- 0x02000000是基地址是4k对齐的,能整除4096
- 地址映射,HP的地址映射到ddr应该是00080000到3FFFFFFF,所以从0x02000000开始

3.6 hdmi发送器
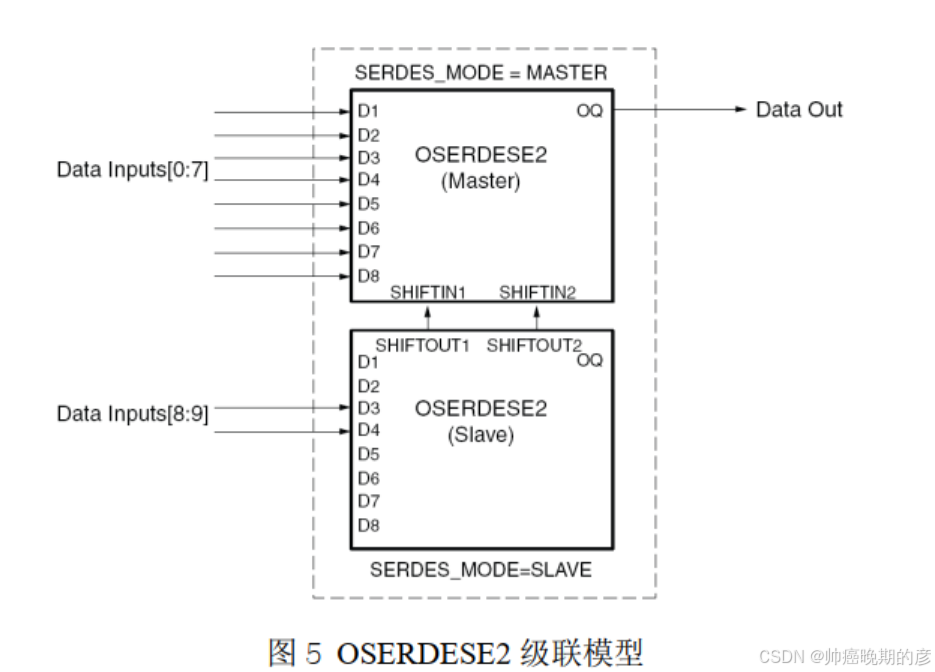
OSERDESE2原语的差分化,该模块中将会使用 Xilinx提供的原语 OSERDESE2 进行串并转化(级联两个才能串行化10bit),将并行数据时钟和串行数据时钟接到OSERDESE2上,用DDR的方式驱动数据,(减小管脚的时钟频率),把他们的SHIFTIN1和SHIFTOUT2连在一块就行,OQ只能从master里面出,不能从slave里面出来,以及原语 OBUFDS 将串行的数据转成差分信号,
verilog
OSERDESE2 #(
.DATA_RATE_OQ("DDR"), // DDR, SDR,最终输出的数据是DDR还是SDR,对应下面的OQ
.DATA_RATE_TQ("SDR"), // DDR, BUF, SDR,控制oq输出buffer是输出还是三态,设置成SDR就行
.DATA_WIDTH(10), // Parallel data width (2-8,10,14)
.INIT_OQ(1'b0), // Initial value of OQ output (1'b0,1'b1)一上电的状态
.INIT_TQ(1'b0), // Initial value of TQ output (1'b0,1'b1)
.SERDES_MODE("MASTER"), // MASTER, SLAVE
.SRVAL_OQ(1'b0), // OQ output value when SR is used (1'b0,1'b1)
.SRVAL_TQ(1'b0), // TQ output value when SR is used (1'b0,1'b1)
.TBYTE_CTL("FALSE"), // Enable tristate byte operation (FALSE, TRUE)
.TBYTE_SRC("FALSE"), // Tristate byte source (FALSE, TRUE)
.TRISTATE_WIDTH(1) // 3-state converter width (1,4)三态的控制
)
OSERDESE2_inst_master (
.OFB(), // 1-bit output: Feedback path for data回环信号
.OQ(do), // 1-bit output: Data path output输出的双沿串行信号
// SHIFTOUT1 / SHIFTOUT2: 1-bit (each) output: Data output expansion (1-bit each)
.SHIFTOUT1(),
.SHIFTOUT2(),
.TBYTEOUT(), // 1-bit output: Byte group tristate
.TFB(), // 1-bit output: 3-state control
.TQ(), // 1-bit output: 3-state control
.CLK(serclk), // 1-bit input: High speed clock
.CLKDIV(divclk), // 1-bit input: Divided clock
// D1 - D8: 1-bit (each) input: Parallel data inputs (1-bit each)
.D1(din[0]),
.D2(din[1]),
.D3(din[2]),
.D4(din[3]),
.D5(din[4]),
.D6(din[5]),
.D7(din[6]),
.D8(din[7]),
.OCE(1'b1), // 1-bit input: Output data clock enable
.RST(ini_rst), // 1-bit input: Reset这里的复位要和时钟divclk同步
// SHIFTIN1 / SHIFTIN2: 1-bit (each) input: Data input expansion (1-bit each)
.SHIFTIN1(cascade_di1),
.SHIFTIN2(cascade_di2),
// T1 - T4: 1-bit (each) input: Parallel 3-state inputs
.T1(1'b0),
.T2(1'b0),
.T3(1'b0),
.T4(1'b0),
.TBYTEIN(1'b0), // 1-bit input: Byte group tristate
.TCE(1'b0) // 1-bit input: 3-state clock enable
);
OSERDESE2 #(
.DATA_RATE_OQ("DDR"), // DDR, SDR
.DATA_RATE_TQ("SDR"), // DDR, BUF, SDR
.DATA_WIDTH(10), // Parallel data width (2-8,10,14)
.INIT_OQ(1'b0), // Initial value of OQ output (1'b0,1'b1)
.INIT_TQ(1'b0), // Initial value of TQ output (1'b0,1'b1)
.SERDES_MODE("SLAVE"), // MASTER, SLAVE
.SRVAL_OQ(1'b0), // OQ output value when SR is used (1'b0,1'b1)
.SRVAL_TQ(1'b0), // TQ output value when SR is used (1'b0,1'b1)
.TBYTE_CTL("FALSE"), // Enable tristate byte operation (FALSE, TRUE)
.TBYTE_SRC("FALSE"), // Tristate byte source (FALSE, TRUE)
.TRISTATE_WIDTH(1) // 3-state converter width (1,4)
)
OSERDESE2_inst_slave (
.OFB(), // 1-bit output: Feedback path for data
.OQ(), // 1-bit output: Data path output
// SHIFTOUT1 / SHIFTOUT2: 1-bit (each) output: Data output expansion (1-bit each)
.SHIFTOUT1(cascade_di1),
.SHIFTOUT2(cascade_di2),
.TBYTEOUT(), // 1-bit output: Byte group tristate
.TFB(), // 1-bit output: 3-state control
.TQ(), // 1-bit output: 3-state control
.CLK(serclk), // 1-bit input: High speed clock
.CLKDIV(divclk), // 1-bit input: Divided clock
// D1 - D8: 1-bit (each) input: Parallel data inputs (1-bit each)
.D1(),
.D2(),
.D3(din[8]),
.D4(din[9]),
.D5(1'b0),
.D6(1'b0),
.D7(1'b0),
.D8(1'b0),
.OCE(1'b1), // 1-bit input: Output data clock enable
.RST(ini_rst), // 1-bit input: Reset
// SHIFTIN1 / SHIFTIN2: 1-bit (each) input: Data input expansion (1-bit each)
.SHIFTIN1(),
.SHIFTIN2(),
// T1 - T4: 1-bit (each) input: Parallel 3-state inputs
.T1(1'b0),
.T2(1'b0),
.T3(1'b0),
.T4(1'b0),
.TBYTEIN(1'b0), // 1-bit input: Byte group tristate
.TCE(1'b0) // 1-bit input: 3-state clock enable
);
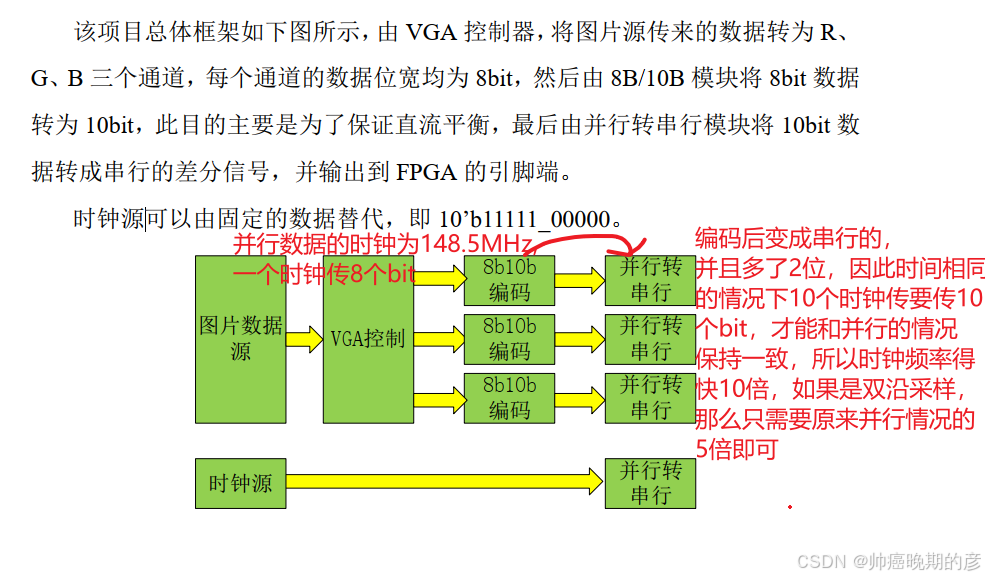
3.7 跨时钟域的处理
3.7.1 多比特的跨时钟域
DDR的HP口用于传输高速数据流,最大位宽 64bit,xi_full 可支持最大256突发,时钟最大可以支持到250MHz(这里选择200MHz,害怕出现时序违例),图像预处理模块时钟为外部输入时钟74.25MHz,hdmi显示模块的时钟是148.5MHz(1920108060HZ),读写时钟不同步+axi不能随时随刻读写数据,所以需要两个地方的多bit数据流跨时钟域操作------采用异步fifo的模式做buffer,设计相应的读写条件,以满buffer两边读写带宽对等,即为满足读写流畅不卡顿(数据不丢失),实现数据流的跨时钟操作
3.7.1.1 fifo的理论深度设计(前提条件是fifo两边的读写带宽对等)
宏观看,整个时间域上,"写数据=读数据",这个是异步FIFO正常工作最基本的要求,是大前提。由于写快读慢,在发送方"突发传输"的发送数据的T内,是很有可能发送方写数据量>接收方读取的数据量,那么剩下未读取的数据必定需要存储共接收方继续读取并不能丢弃,因此FIFO的深度要能够保证,在这段时间T内,如果接收方未能将发送方发送的数据接收完毕的话,剩下的数据都是可以存储在FIFO内部而且不会溢出的,那么在发送方停止发送数据的"空闲时隙"内,接收方可以从容地接收剩下来的数据。
这里有两篇讲深度设计的博文写的很好
- https://blog.csdn.net/qq_26652069/article/details/90720568
- https://blog.csdn.net/wuzhikaidetb/article/details/121659618
当读时钟小于写时钟(读带宽>=写带宽)常规的公式主要就是要满足:
d e p t h max v w r − min v r d > max ( l e n g t h b a c k t o b a c k ) max v w r \frac{depth}{\max v_{wr}-\min v_{rd}}>\frac{\max \left( length_{back\,\,to\,\,back} \right)}{\max v_{wr}} maxvwr−minvrddepth>maxvwrmax(lengthbacktoback)
所谓最坏情况,就是使得写速率最大,读速率最小;通常是考虑猝发传输。
FIFO被填满的时间 > 背靠背最长数据包写入时间
(全部写入的数据量 - 已经被读走的数据量 = 需要缓存到FIFO的数据量,即异步FIFO的最小深度)
3.7.1.2 图像预处理到ddr之间的跨时钟域
3.7.1.2.1 深度的考量
这里的写带宽为74.25MHz * 32bit,而读时钟即axi的时钟设计的是200MHz,突发长度是256,突发位宽是64bit,理论的带宽为200MHz乘以64bit(axi的实际带宽和outstanding的个数的设计,单个地址的访问时延,axi的突发长度,突发位宽有关系,需要具体测试)。
由于理论上读的带宽是远远大于写带宽的,如果读写不间断连续的话,按照理论可以设置fifo深度为1,
但是读写是间断的(写fifo在解析出的图像数据有效的时候再写入;读fifo的axi不能随时随刻读写数据),再加上设置的axi wr模块是256突发,一旦axi wr写模块启动一次突发操作wvalid会持续拉高,直到和ddr controller返回的wready握手满256次,wvalid && wready作为fifo的读使能,fifo在一次突发读的时候,读带宽远远大于写带宽,所以fifo在启动一次第突发操作时,为防止读空,fifo里面至少要有一次突发长度的数据。
为了安全起见,我选择采用公式,使得写速率最大,读速率最小(直接上0),fifo的深度即------back to back最大突发的数据长度是一行图像数据1920x32bit,所以我的fifo深度设置为2048x32bit(fifo深度为2的n次方)
(其实可以再优化一下资源------设置FIFO的深度为2次axi突发读长度,读条件不变)
3.7.1.2.2 读写带宽对等的设置
由于读带宽大于写带宽,自定义的axi 256突发模块连续对fifo进行突发读操作的话,会读空,为防止读空,读fifo的条件为当fifo里面data_count >= 一次axi突发长度的数据时就开始执行一次256突发的axi读操作,以一定频率的突发操作,使得fifo两边的带宽对等。
3.7.1.3 ddr到图像显示之间的跨时钟域
3.7.1.3.1 深度的考量
这里的读带宽是148.5MHz * 32bit而写时钟即axi的时钟设计的是200MHz,突发长度是256,突发位宽是64bit,理论的带宽为200MHz乘以64bit(axi的实际带宽和outstanding的个数的设计,单个地址的访问时延,axi的突发长度,突发位宽有关系,需要具体测试)。
由于理论上写的带宽是远远大于读带宽的,如果读写不间断连续的话,fifo就会爆掉,
但是读写是间断的(读fifo在HDMI行场信号有效的时候读出;写fifo的axi不能随时随刻读写数据),
所以要以一定频率的突发操作,使得fifo两边的带宽对等。因为我的axi rd模块启动一次读突发操作时,rready会一直拉高,直到和ddr controller返回过来的arvalid和rlast握手后才会拉低,rready && arvalid作为fifo的写使能,fifo在一次突发写的时候,写带宽远远大于读带宽,所以fifo在启动一次第突发操作时,为防止写满,fifo的深度至少要有一次突发长度的数据。
再加上考虑hdmi模块读fifo的back to back最大数据长度是一行1920 x 32bit,想到fifo里面存储到一行数据的时候,才启动hdmi模块读,显示更能流畅,FIFO里面不足一行数据的时候,通过axi rd模块从ddr里面突发一次数据,以满足fifo随时都有一行数据的缓存(显示不会卡顿)。由于突发一次数据写入到FIFO的带宽大于hdmi读数据的带宽,所以fifo深度设置为((1920 + 256 * 2)* 32bit)------------4096 x 32bit
(其实可以再优化一下资源------设置FIFO的深度为2次axi突发读长度,写条件改为<1次突发长度启动突发操作)
3.7.1.3.2 读写带宽对等的设置
由于写带宽大于读带宽,自定义的axi 256突发模块连续对fifo进行突发写操作的话,会写满,为防止写满,写fifo的条件为当fifo里面data_count < 一行数据时就开始执行一次256突发的axi写操作,以一定频率的突发操作,使得fifo两边的带宽对等。
3.7.2 单比特的跨时钟域
手册UG585里面有关于ZYNQ 的时钟树的介绍,这里有篇博文是速览版本可以参考下:
https://blog.csdn.net/zhoutaopower/article/details/105819623

因为有从ps端给到axi wr和axi rd模块的gpio启动信号,是以ps端c语言代码语句形式给出的拉高拉低信号,

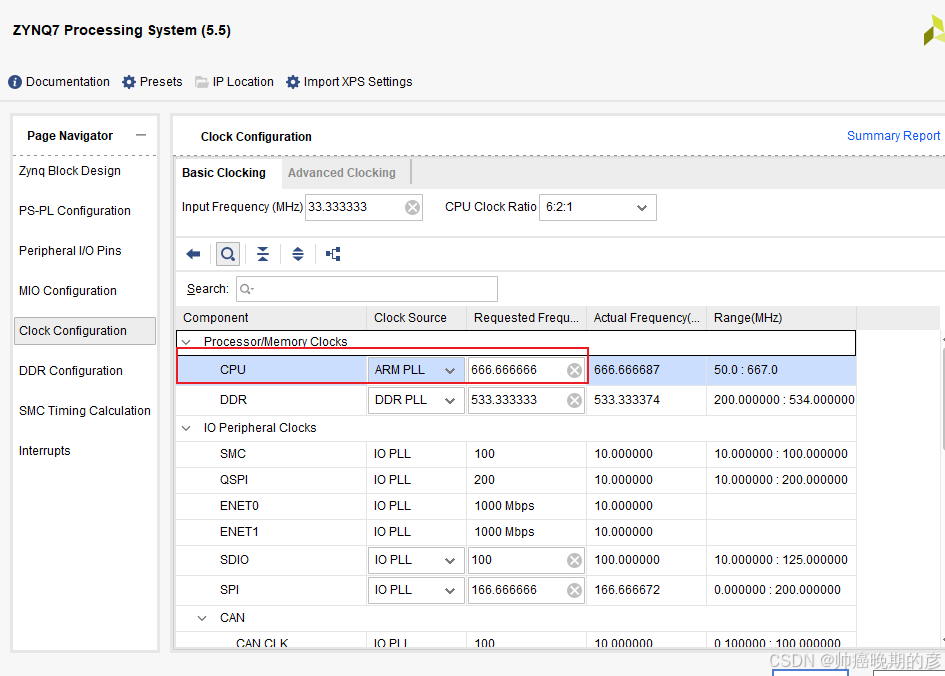
可以看到这里的cpu的频率是600MHz多,一条c语言代码的执行大概有几十个指令周期,axi wr和axi rd模块采集启动信号时,属于是快时钟采集慢时钟域的信号(满足三时钟沿原则),直接打3拍,去识别axi的时钟域下识别启动信号的上升沿,为了安全最好在c语言代码加个延迟这样可以让时间可控,以实现百分百axi时钟能抓到ps端启动信号上身沿。
3.8 防撕裂设计
首先读写在ddr同一个区域,摄像头是30帧往里面写,hdmi是60帧往往外面读。因为读比写快,有可能存在写新图像到上一半的时候,读已经跑到下一半,也就是显示出的图像上半帧为新图像,下半帧为老图像,就会出现图像撕裂。
思路就是在ddr中建立两倍分辨率大小的缓冲区,将BUF分为A区和B区。在数据写入模块中引出一个标志信号frame_flag给到显示模块,当摄像头正在填充A区时,此标志信号为0,当摄像头正在填充 B 区时此标志信号为1,读取数据源数据时判断标志信号为 0 读取区域 B,标志信号为 1 读取区域 A,避开读写同一个区域所以不会出现正在读取的这帧图像被写输入数据追赶上,因此能显示的图像为一整帧图像不会垮帧显示,解决帧不同步问题。
verilog
//读模块
// axi_araddr;
always @(posedge M_AXI_ACLK)
begin
if (M_AXI_ARESETN == 0) begin
axi_araddr <= 'd8294400;
end
else if((num_burst_cnt == 'd4049 && M_AXI_RLAST == 1'b1) && (i_frame_flag == 0)) begin
axi_araddr <= 'd8294400;
end
else if((num_burst_cnt == 'd4049 && M_AXI_RLAST == 1'b1) && (i_frame_flag == 1)) begin
axi_araddr <= 'd0;
end
else if(axi_arvalid && M_AXI_ARREADY ) begin
axi_araddr <= axi_araddr + 'd2048;
end
else
axi_araddr <= axi_araddr;
end
//写模块
// o_rd_flag
always @(posedge M_AXI_ACLK)
begin
if (M_AXI_ARESETN == 1'b0)begin
ro_frame_flag <= 1'b0;
end
else if(axi_awaddr == 'd0 && M_AXI_AWREADY == 1'b1 && axi_awvalid == 1'b1)begin
ro_frame_flag <= 1'b0; //一次突发为256个64bit的数,偏移地址的单位为byte,所以256*64/8=2048
end
else if (axi_awaddr == 'd8294400 && M_AXI_AWREADY == 1'b1 && axi_awvalid == 1'b1) begin
ro_frame_flag <= 1'b1;
end
else
ro_frame_flag <= ro_frame_flag;
end 3.9 抓拍功能
根据模板使用C语言创建BMP 24位的带有文件结构的文件, 例如文件头如何构成, 结构体初始化文件头等功能。我们需要调用 FAT32 的协议栈, 完成对 SD 卡的读写,协议栈将 SD 卡读写擦除都封装为标准的函数, 只需要学会使用函数即可。
4.模块验证
4.1 spi配置摄像头是否成功的验证
在pl端配置好zynq后,export hardware platform(要include bitstream),然后launch vitis,选择之前的export的platform,debug as后指针会先跳到main的初始处,单步的调试,然后看发送过去的reg寄存器的值是否正确,然后看spi发送函数返回的status值是不是正确的,即可完成验证。
4.2 解析图像有效数据模块的验证
直接上板抓,没有用modelsim仿真,添加ila,ps端配置好之后,相机的数据给到pl端的图像解析模块,然后触发ila中的信号,看看能不能抓到那些信号,包括状态的跳转之类正不正确(ila的时钟为外部相机给过来的时钟)
4.3 bayer to rgb模块的验证
也是通过ila去抓标志信号,一些计数器特殊值,以及解析出的3个通道rgb信号(然后用手把摄像头蒙上,rgb的值变小了)
4.4 灰度白均衡的模块的验证
直接看视频的效果。
4.5 axi wr的验证
先按照0------255的突发数据做实验,pl端加入axi的ila,生成bit,launch vitis,然后ps dubug as,逐步debug,当执行到启动axi wr 模块时,观察pl 端的ila的写情况满不满足写时序,然后在ps端观察相应地址里面的数据(这里需要关掉cache------Xil_DCacheDisable();Xil_ICacheDisable();或者在写进去之后ps端用Xil_DCacheInvalidateRange,使得cache重新加载ddr里面的数,从而解决一致性问题),是不是等于pl端给过来的0到255的数据
然后再把相机过来的数据和跨时钟域的fifo加上,重复上述步骤,看看ila抓的axi时序对不对,用手遮挡相机,看看wdata的数值为不会变小,然后看看ps端的内存访问的区域是不是对的(看地址的范围里面的数据24------31位是不是0)因为,我把24位的rgb数据高位补了8个0,变成32位数据写入到fifo中,axi 又以64的位宽从fifo里面读,写道ddr中

4.6 axi rd的验证
ps端在指定范围里面写入256个递增数据,然后在通过ps端通过gpio启动axi rd模块,在pl端抓相应的信号,看看是否能抓到正确的时序和数据(注意要么把cache关掉;要么在ps端c代码写好代码后用Xil_DCacheFlushRange将cache的数刷到ddr里面)

4.7 hdmi发送器的验证
先测试彩条是否显示成功,hdmi发送器是否正常工作

5.遇到的困难如何解决
最开始项目的显示图像是有偏移的,一帧一帧的往下刷,所以按照以下思路来debug
1.先验证axi rd模+hdmi显示模块有没有问题。先在PS端往内存ddr里面初始化一张图像,不使用cmos传过来的图像数据,如果正确显示,表示axi rd模块+hdmi显示模块没问题

2.检验axi wr写模块是不是有问题
因为之前验证过,而且整体的逻辑比较清晰,所以我直接检查的预处理模块,这里直接跳过
3.检验图像的预处理模块是不是有问题
预处理模块包括 图像解析模块+bayer2rgb模块,将图像解析模块解析出的数据同时赋值给rgb三个通道(rgb三个通道值一样是灰度图像),观察输出图像是否正确来验证图像解析模块,结果表示确实没问题,那么就是bayer2rgb模块出现了问题
bayer2rgb模块的修改:发现开始计算的标志信号出现了问题,在0行和1行的时候拉高了,(多拉高了两行多了两行的计算结果导致图像下移)实际不应该拉高,在第二行进来才拉高,
改完之后在测试显示,颜色不对,检查计算是否有溢出,发现计算的时候等式右边是加法操作,左边的位宽不正确,应该扩展左边变量的位宽

全部改正之后,没有问题了
6.时序分析
整个项目跨时钟域单比特和多比特都做了跨时钟预处理,复位也是异步复位同步释放在各自的时钟域下做了同步、或者时用复位ip核和相应的时钟进行了同步,布局布线后,发现axi的时序有点违例(200MHz有点高),

如上图所示,通过加入axi_register_slice ip核来优化axi的时序。
最终的时序是满足要求的,没有违例的情况

7.小tips
7.1 ps端和pl端的联调
pl导出包含(bitstream)硬件平台,ps端在平台上完成设计后,进入debug ,然后一步一步步进,或者跳到断点处之类的,然后在pl端的ila中观察对应的信号
7.2 管脚的绑定
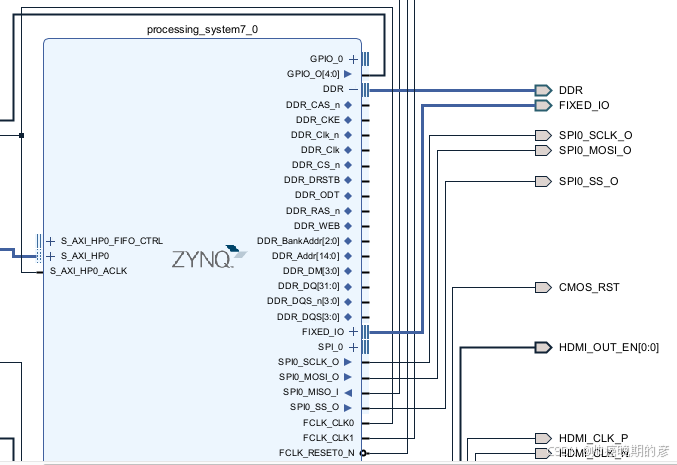
zynq的ddr和fix io是不需要区绑定管脚的,这些是PS端的信号
7.3 地址分配问题
https://www.cnblogs.com/Ariza123/p/9086026.html
https://blog.csdn.net/Lily_9/article/details/88783605
address editor是什么?
(一个是地址分配master address就是主机要访问的地址,谁是主端口谁是主机,主动通过这个地址去访问,pl通过HP口去访问ddr,地址应该是00080000到3FFFFFFF,这里是0x0000_0000到0x1FFF FFFF,一是ddr为512g的,而是包含了ocm的地址,就是整个zynq的芯片,整个开发板,都是属于同一套物理地址分配系统所以vivado界面address editor的时候master base address和slave base address是一直是相同,slave base address就是被访问的从机的地址DDR,这里的)

这里用interconnect两主机访问一个HP口(访问DDR同一个地址),没有问题

这里用interconnect两主机访问两个HP口(访问DDR同一个地址),会有地址冲突
7.4 axi interconnect和smartconnect
为什么要用interconnect?
- zynq的是axi3,我们写的是axi4,要协议转换一下
- 仲裁
- 位宽的转换
- 跨时钟域的处理
AXI Interconnect简明使用方法记录:
- https://hellocode.blog.csdn.net/article/details/108365170?spm=1001.2101.3001.6650.5\&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-5-108365170-blog-112597054.235^v43^pc_blog_bottom_relevance_base3\&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-5-108365170-blog-112597054.235^v43^pc_blog_bottom_relevance_base3\&utm_relevant_index=10
- https://support.xilinx.com/s/question/0D52E00006hpoIYSAY/axi-interconnect-ip核使用问题求教?language=en_US
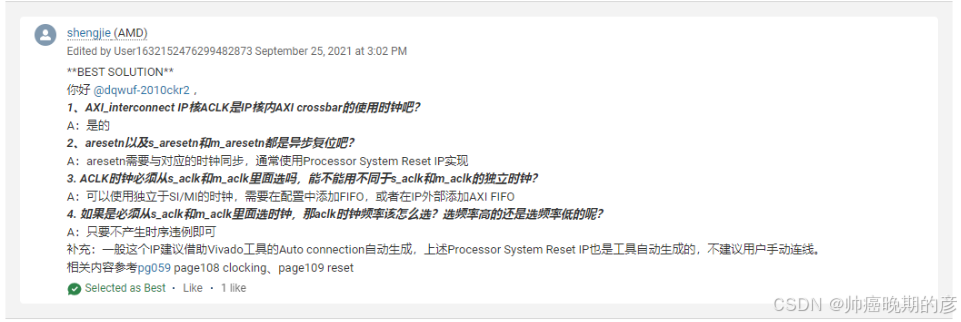
7.5 复位ip的使用
https://blog.csdn.net/weixin_42837669/article/details/116853566