文章目录
- 详细配置(boot)
-
- 一、模式配置&数据源配置
-
- [1.1 模式配置](#1.1 模式配置)
- [1.2 数据源配置](#1.2 数据源配置)
- [1.3 默认数据源的配置](#1.3 默认数据源的配置)
- 二、基础属性配置
-
- [2.1 在日志中打印 SQL](#2.1 在日志中打印 SQL)
- [2.2 在程序启动和更新时,是否检查分片元数据的结构一致性](#2.2 在程序启动和更新时,是否检查分片元数据的结构一致性)
详细配置(boot)
一、模式配置&数据源配置
1.1 模式配置
官方推荐开发环境使用单机模式,正式部署环境推荐使用zookepper(结合官方文档尝试)
相关参考
- ZooKeeper 注册中心安装与使用
- 持久化仓库类型的详情,请参见内置持久化仓库类型列表。
单机模式的配置如下
yml
spring:
shardingsphere:
mode:
type: Standalone
repository:
type: JDBC1.2 数据源配置
数据源的配置详细可以看上面的快速开始和官方文档,这里梳理一下数据源配置需要注意的点
- 本文示例的数据是postgresql数据库,官方文档是mysql,具体需要根据实际场景配置
- 配置真实数据源时可以使用
groovy语法,写法类似ds${0...10}来快速声明多个数据源 - IDE编辑器可能会无法识别数据源的配置信息。
- 注意根据项目实际使用的数据库连接池来配置(springboot内置的是hikariCP连接池,如果需要使用duird需要进行额外的配置,可以参考文章https://www.cnblogs.com/architectforest/p/13531448.html
数据源参考示例
yml
spring:
shardingsphere:
mode:
type: Standalone
repository:
type: JDBC
props:
# 禁用执行SQL用于获取表元数据
sql-show: true
# 禁用执行SQL用于获取数据库元数据
# check-table-metadata-enabled: false
datasource:
# 配置真实数据源 相当于ds0,ds1
names: ds0,ds1
ds0:
# 数据库连接池全类名
type: com.zaxxer.hikari.HikariDataSource
# 数据库驱动类名,以数据库连接池自身配置为准
driver-class-name: org.postgresql.Driver
# 数据库 URL 连接,以数据库连接池自身配置为准
jdbc-url: jdbc:postgresql://localhost:5432/sd0
username: postgres
password: root
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: org.postgresql.Driver
jdbc-url: jdbc:postgresql://localhost:5432/sd1
username: postgres
password: root1.3 默认数据源的配置
在实际业务场景中,比较常见的场景是一个库中100张表只有2张表要分库分表,而其余的表则继续访问默认数据源;在5.0.0之前的版本官方支持直接配置默认数据源,目前并没有找到对应的配置说明, 自己尝试解决。
- 准备一个damain的库,创建一张表
tb_class
**测试一:**不配置该表的策略,配置一个数据源defaultds,该数据源汇总有tb_class表,观察默认情况下ss选择那个数据源。
配置数据源如下
yml
#...
datasource:
names: ds${0..1},defaultds
ds0:
# ...
defaultds:
# ...
ds1:
# ...测试结果
-
ss自动指定 了defaultds作为
tb_class表指定的库。 -
疑问:如果配置了多个库且都有同一个表
tb_class,ss会指定哪个库作为默认库?
测试二 :不配置改变测试,再配置一个数据源,里面也有该表tb_class。观察该情况下ss选择那个数据源。
配置数据源如下
yml
#...
datasource:
names: ds${0..1},defaultds,defaultds2
ds0:
# ...
defaultds:
# ...
defaultds2:
# ...
ds1:
# ...测试结果
- ss依然自动指定 了defaultds作为
tb_class表指定的库。 - 调换顺序配置改为
ds${0..1},defaultds2,defaultds,ss则会指定 了defaultds2作为tb_class表指定的库。 - 初步得出结论:ss会依据数据源声明的顺序,指定没有配置策略的表的数据源
测试三 :验证结论。在ds0数据源中也创建一个tb_class表,数据源声明顺序不变,即ds${0..1},defaultds,defaultds2。如果tb_class表是调用ds0数据源,则说明结论正确。
测试结果:符合预期
默认数据源配置结论
- ss会自动识别没有分库分表的表格。在官方FAQ中也有提到
- 而且是根据数据源的声明先后顺序实现,因此在实际配置过程中,只需要将默认数据源配置在第一个即可,比如
name: defaultds,ds${0..10}

二、基础属性配置
Apache ShardingSphere 提供属性配置的方式配置系统级配置。官方文档:https://shardingsphere.apache.org/document/5.2.1/cn/user-manual/common-config/props/
常用的几个配置:
yml
props:
# 开启打印SQL
sql-show: true
# 简化打印SQL语句
sql-simple: true
# 禁用执行SQL用于获取数据库元数据
check-table-metadata-enabled: true2.1 在日志中打印 SQL
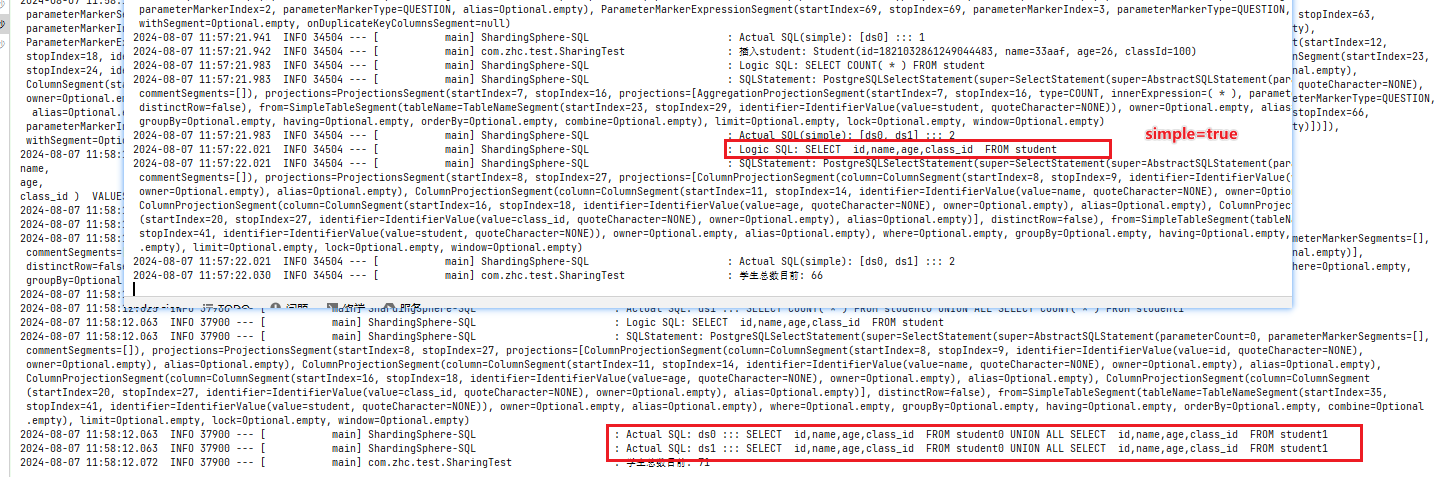
打印 SQL 可以帮助开发者快速定位系统问题。日志内容包含:逻辑 SQL,真实 SQL 和 SQL 解析结果。
配置参数包含
sql-show开启后会打印SQLsql-simple,简化了真实SQL的输出,根据实际情况可以选择是否开启,差别如下
2.2 在程序启动和更新时,是否检查分片元数据的结构一致性
也是一个常用的功能,让服务启动时会检查每个分片的数据/表结构是否一致,建议开启,可以解决一些潜在的bug
-
当检查到异常时,服务会抛出InconsistentShardingTableMetaDataException(分片不一致异常)
