
引言
作为一款高性能的 OLAP 数据库,ClickHouse 被用于多种应用场景,包括 时间序列(time series)数据的实时分析。其多样化的应用场景推动了大量分析函数的发展,这些函数有助于查询大多数类型的数据。这些查询特性加上高压缩率使得越来越多的用户开始利用 ClickHouse 来存储可观测性数据。这类数据通常以三种常见形式存在:日志(logs)、指标(metrics) 和 跟踪(traces) 记录。在这系列的博客文章中,我们将探讨如何收集、最优地存储、查询以及可视化这些 "支柱(pillars)"。
在本篇文章中,我们从日志开始,探讨日志的收集与查询的可能性。我们尽量确保提供的示例是可以复现的。同时需要注意的是,ClickHouse 对于特定数据类型的代理支持一直在不断进化,本文代表了截至 2023 年 1 月 的生态系统现状。因此,我们总是建议用户查看最新的文档和相关问题。
虽然我们的示例假设了一个现代架构,即用户需要从 Kubernetes 集群中收集日志,但我们的建议和指导并不依赖于Kubernetes,同样适用于自管理服务器或其他容器编排系统。我们在开发云环境中进行了测试,大约 20 个节点每天产生约 100GB 的日志。请注意,我们没有对代理进行调优,也没有测量它们的资源开销------这是我们在生产部署前推荐用户研究或执行的任务。本文主要关注数据收集,提出了一个 数据模型(data model)和 模式(schema)设计,而优化方面留待后续的文章讨论。
为了演示,我们将数据存储在一个 ClickHouse Cloud 服务中,在这里你可以几分钟内启动一个免费试用集群,无需担心基础设施的问题,即可开始查询!
注意:本文中所有可复现的配置示例都可以在这个仓库中查阅。
架构
大多数代理采用一种通用的架构模式来大规模收集可观测性数据,推广了 代理(agent)和 聚合器(aggregator) 的概念。对于小型部署来说,可以忽略聚合器的概念,代理部署在其数据源附近,负责处理并直接通过 HTTP 或原生协议将数据发送到 ClickHouse。在 Kubernetes 环境中,这意味着将代理作为 Daemonset 部署。这会在每个 k8s 节点上部署一个 agent pod,负责收集其他容器的日志(通常是从磁盘读取)。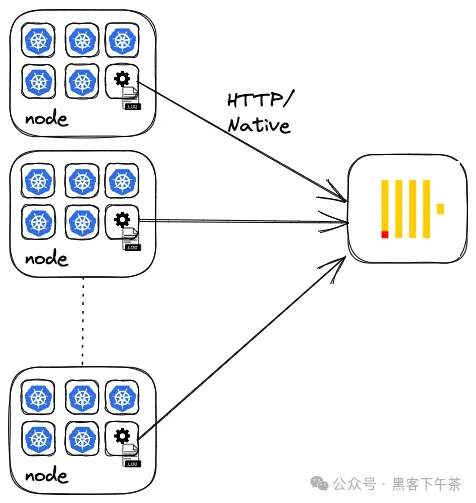
- https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/
- https://kubernetes.io/docs/concepts/workloads/pods/
这种架构对于不需要高持久性和可用性的用户以及少量代理且配置更改成本低的情况是足够的。然而,用户应该意识到这可能会导致许多小批量插入,特别是如果代理被配置为频繁刷新数据的话,例如因为需要数据能够及时提供以供分析和问题识别。在这种情况下,用户应考虑配置代理使用异步插入,以避免因过多的分片而导致的常见问题。
- https://clickhouse.com/docs/en/cloud/bestpractices/asynchronous-inserts/
- https://clickhouse.com/blog/common-getting-started-issues-with-clickhouse
大型部署引入了 聚合器(aggregator)或 网关(gateway)的概念。这一概念旨在配置轻量级的代理靠近其数据源,仅负责将数据转发给聚合器。这样减少了干扰现有服务的可能性。聚合器负责处理步骤,如 丰富数据(enrichment)、过滤(filtering)、确保应用了 模式(schema),以及批处理和可靠地将数据传送到 ClickHouse。聚合器通常作为Deployment 或 Statefulset 部署,并可以根据需要创建多个副本以实现高可用性。

- https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
- https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
除了减少数据源潜在关键服务上的负载外,这种架构还允许数据以更大的块的形式批处理并插入到 ClickHouse 中。这一特性非常重要,因为它符合 ClickHouse 的最佳插入实践。
上述架构简化了企业架构,实际上还需要考虑数据缓冲的位置、负载均衡、高可用性、复杂路由以及记录(归档)系统和分析系统的分离。这些概念在 Vector 文档中有详细的介绍。虽然这些内容是针对 Vector 的,但其中的原则同样适用于其他讨论过的代理。这些架构的一个重要特点是代理和聚合器也可以是异构的,混合使用不同的技术是很常见的,尤其是在收集不同类型的数据时,因为某些代理在不同的可观测性支柱方面表现出色。
- https://vector.dev/docs/setup/going-to-prod/
- https://vector.dev/docs/setup/going-to-prod/architecting/#choosing-agents
Agents(代理)
在 ClickHouse,我们的用户倾向于使用四种主要的代理技术:Open Telemetry Collector、Vector、FluentBit 和 Fluentd。后两者具有相同的起源和很多相同的概念。为了简洁起见,我们探讨 FluentBit,它更轻量级且足以满足Kubernetes 中的日志收集需求,但使用 Fluentd 也是一种有效的方法。这些代理可以承担聚合器(aggregator)或收集器(collector)的角色,并且可以在一定程度上一起使用。尽管它们使用的术语不同,但都采用了插件式的输入(inputs)、过滤器(filters)/处理器(processors)和输出(outputs)的通用架构。ClickHouse 要么作为官方输出得到支持,要么通过通用 HTTP 支持实现集成。
然而,在下面的初始示例中,我们将每个代理(agent)都部署为聚合器(aggregator)和收集器(collector)角色。我们使用每个代理的官方 Helm chart 来获得简单的入门体验,记录重要的配置更改,并分享 values.yaml 文件。
我们的示例使用单个副本(replica)作为聚合器(aggregator),尽管这些聚合器可以很容易地部署多个副本并通过负载均衡提高性能和容错能力。所有的代理都支持使用 Kubernetes 元数据丰富日志,这对于未来的分析至关重要,例如 pod 名称、容器 id 和日志来源的节点。日志条目还可以包含注解(Annotations)和标签(labels)(FluentBit 和 Vector 默认启用)。这些通常是稀疏的,但可能数量众多(数百个);生产架构应该评估它们的价值并对其进行过滤。我们建议使用 Map 类型来存储这些元数据,以避免列爆炸问题,这对查询有影响。
所有代理在作为聚合器部署时都需要通过 resources YAML 键进行调优,以避免内存溢出(OOM)问题,并跟上我们的吞吐量(每天大约100GB)。根据聚合器的数量和日志吞吐量的不同,您的情况可能会有所不同,但在大型环境中几乎总是需要调整资源。
Open Telemetry (OTEL) Collector (alpha)
OpenTelemetry 是一套工具、API 和 SDK 的集合,用于仪器化(instrumenting)、生成、收集和导出可观测性数据。除了在大多数流行的编程语言中提供代理之外,还有一个使用 Golang 编写的 Collector 组件,提供了接收、处理和导出可观测性数据的供应商无关实现。通过支持多种输入格式,如 Prometheus 和 OTLP,以及广泛的导出目标,包括 ClickHouse,OTEL Collector 可以提供一个集中的处理网关。Collector 使用 receiver(接收器)、processor(处理器)和 exporter(导出器)这三个术语来表示其三个阶段,并使用 gateway(网关)来指代聚合器实例。
- https://opentelemetry.io/docs/collector/
- https://opentelemetry.io/docs/collector/configuration/#receivers
- https://opentelemetry.io/docs/collector/configuration/#processors
- https://opentelemetry.io/docs/collector/configuration/#exporters
- https://opentelemetry.io/docs/collector/deployment/
虽然更常被用作网关/聚合器,处理诸如批处理和重试等任务,但 Collector 也可以作为代理本身部署。OTLP 代表了 Open Telemetry 的数据标准,用于网关和代理实例之间的通信,可以通过 gRPC 或 HTTP 发生。正如我们将在下面看到的,这种协议也得到了 Vector 和 FluentBit 的支持。
- https://opentelemetry.io/docs/collector/deployment/
- https://opentelemetry.io/docs/reference/specification/protocol/
- https://opentelemetry.io/docs/reference/specification/protocol/design-goals/
ClickHouse 支持
ClickHouse 在 OTEL 导出器中通过社区贡献得到了支持,支持日志和跟踪(对于指标的支持正在审查一个 PR)。与 ClickHouse 的通信通过优化的原生格式和协议,使用官方 Go 客户端进行。
- https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/clickhouseexporter
- https://github.com/open-telemetry/opentelemetry-collector-contrib/pull/16477
在使用 Open Telemetry Collector 之前,用户应考虑以下几点:
-
代理使用的 ClickHouse 数据模型和模式是硬编码的。截至撰写本文时,没有能力更改所使用的类型或编解码器。解决这个问题的一种方法是在部署 connector(连接器)之前创建表,从而强制执行您的 schema(模式)。
-
Exporter 不是与核心 OTEL 发行版一起发布的,而是作为
contrib镜像中的扩展。实际上这意味着在 Helm chart 中使用正确的 docker 镜像。 -
Exporter 处于 alpha 阶段,尽管我们在收集超过 1TB 的日志时没有遇到问题,但用户应遵循 Open Telemetry 提供的建议。OTEL 的日志用例相对较新,不如 Fluent Bit 或 Vector 成熟。
-
https://github.com/open-telemetry/opentelemetry-collector#alpha
Kubernetes 部署
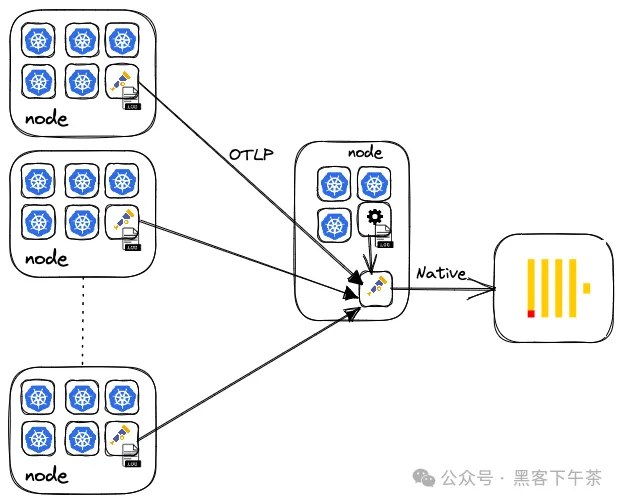
如果仅收集日志,则官方 Helm charts代表最简单的部署方式。在未来的文章中,当我们对应用程序进行 instrument(仪器化)时,operator(操作员)会提供 auto-instrumentation(自动仪器化)功能和其他部署模式,例如作为 sidecar。但对于日志而言,基本的 chart 就足够了。有关安装和配置 chart 的完整详细信息可以在这里找到,包括部署网关和代理的步骤以及示例配置。
- https://github.com/open-telemetry/opentelemetry-helm-charts/tree/main/charts/opentelemetry-collector
- https://github.com/open-telemetry/opentelemetry-operator
- https://github.com/ClickHouse/examples/tree/main/observability/logs/kubernetes/otel_to_otel
请注意,导出器还支持 ClickHouse 的原生 TTL 特性来进行数据管理,并依赖于按日期进行分区(由 schema(模式)强制执行)。在我们的示例中,我们将 TTL 设置为 0,禁用了数据过期,但这代表了一个有用的功能,并且是日志中常见的需求,可以轻松地在其他代理的模式中使用。
- https://clickhouse.com/docs/en/faq/operations/delete-old-data/#ttl
- https://github.com/ClickHouse/examples/blob/d4d703633636c9282eb3589f52e64e34f1ab148f/observability/logs/kubernetes/otel_to_otel/gateway.yml#L81
Data & Schema
我们之前的示例已配置聚合器将数据发送到名为 otel.otel_logs 的表。我们可以通过简单的 SELECT 确认数据的成功收集。
sh
SELECT * FROM otel.otel_logs LIMIT 1 FORMAT Vertical
Row 1:
──────
Timestamp: 2023-01-04 17:27:29.880230118
TraceId:
SpanId:
TraceFlags: 0
SeverityText:
SeverityNumber: 0
ServiceName:
Body: {"level":"debug","ts":1672853249.8801103,"logger":"activity_tracker","caller":"logging/logger.go:161","msg":"Time tick; Starting fetch activity"}
ResourceAttributes: {'k8s.container.restart_count':'0','k8s.pod.uid':'82bc65e2-145b-4895-87fc-4a7db48e0fd9','k8s.container.name':'scraper-container','k8s.namespace.name':'ns-fuchsia-qe-86','k8s.pod.name':'c-fuchsia-qe-86-server-0'}
LogAttributes: {'log.file.path':'/var/log/pods/ns-fuchsia-qe-86_c-fuchsia-qe-86-server-0_82bc65e2-145b-4895-87fc-4a7db48e0fd9/scraper-container/0.log','time':'2023-01-04T17:27:29.880230118Z','log.iostream':'stderr'}
1 row in set. Elapsed: 0.302 sec. Processed 16.38 thousand rows, 10.59 MB (54.18 thousand rows/s., 35.02 MB/s.)请注意,Collector 对 schema 有特定的要求,包括强制执行特定的编解码器。虽然这些选择对于一般情况来说是合理的,但它阻止了用户根据自己的需求调整配置,例如修改表的排序键以适应特定的访问模式。
Schema 使用 PARTITION BY 来辅助 TTL。具体来说,这允许一天的数据被高效地删除。这可能会对查询产生正面和负面的影响。使用数据跳过的 Bloom 索引是一个高级主题,我们将其留待后续关于 schema 优化的文章中讨论。这里使用 Map 类型来存储 Kubernetes 和日志属性,这会影响我们的查询语法。
sh
SHOW CREATE TABLE otel.otel_logs
CREATE TABLE otel.otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_key mapKeys(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_value mapValues(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_body Body TYPE tokenbf_v1(32768, 3, 0) GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SeverityText, toUnixTimestamp(Timestamp), TraceId)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1Vector (beta)
Vector 是一个由 DataDog 维护的开源(采用 Mozilla 公共许可版本 2.0)可观测性数据管道工具,支持日志、指标和追踪数据的收集、转换和路由。它旨在成为供应商无关的工具,并支持多种 inputs 和 outputs,包括 OTLP 协议,这使得它可以作为 Open Telemetry 代理的聚合器。使用 Rust 编写,Vector在其三阶段管道中使用 sources(源)、transforms(转换)和 sinks(接收端)这样的术语。它代表了一个功能丰富的日志收集解决方案,在 ClickHouse 社区中越来越受欢迎。
ClickHouse 支持
ClickHouse 通过一个专用的 sink(当前处于 beta 阶段)在 Vector 中得到支持,通信通过 HTTP 协议使用 JSON 格式并在插入时批量请求。虽然不如其他协议性能高,但这将数据处理卸载给 ClickHouse,并简化了网络流量调试。虽然强制执行了一个数据模型,但用户必须创建目标表并选择它们的类型和编码。skip_unknown_fields 选项允许用户创建只包含可用列子集的表。这会导致任何不在目标表中的列被忽略。下面我们在 vector 数据库中创建一个目标表,覆盖所有 post 列,包括从Kubernetes 丰富化添加的那些。目前,我们利用一个针对容器名称过滤进行了优化的表排序键。未来的文章将讨论优化这个 schema。
sh
CREATE database vector
CREATE TABLE vector.vector_logs
(
`file` String,
`timestamp` DateTime64(3),
`kubernetes_container_id` LowCardinality(String),
`kubernetes_container_image` LowCardinality(String),
`kubernetes_container_name` LowCardinality(String),
`kubernetes_namespace_labels` Map(LowCardinality(String), String),
`kubernetes_pod_annotations` Map(LowCardinality(String), String),
`kubernetes_pod_ip` IPv4,
`kubernetes_pod_ips` Array(IPv4),
`kubernetes_pod_labels` Map(LowCardinality(String), String),
`kubernetes_pod_name` LowCardinality(String),
`kubernetes_pod_namespace` LowCardinality(String),
`kubernetes_pod_node_name` LowCardinality(String),
`kubernetes_pod_owner` LowCardinality(String),
`kubernetes_pod_uid` LowCardinality(String),
`message` String,
`source_type` LowCardinality(String),
`stream` Enum('stdout', 'stderr')
)
ENGINE = MergeTree
ORDER BY (`kubernetes_container_name`, timestamp)默认情况下,Vector 的 Kubernetes 日志输入会在列名中创建带有 . 的列,例如,kubernetes.pod_labels。我们不推荐在 Map 列名中使用点号,并可能废弃这种方法,因此建议使用下划线 _。转换在聚合器中实现了这一点(见下文)。注意我们如何同时获取 namespace(命名空间)和节点标签。
- https://vector.dev/docs/reference/configuration/sources/kubernetes_logs/
- https://github.com/ClickHouse/ClickHouse/issues/36146
Kubernetes 部署
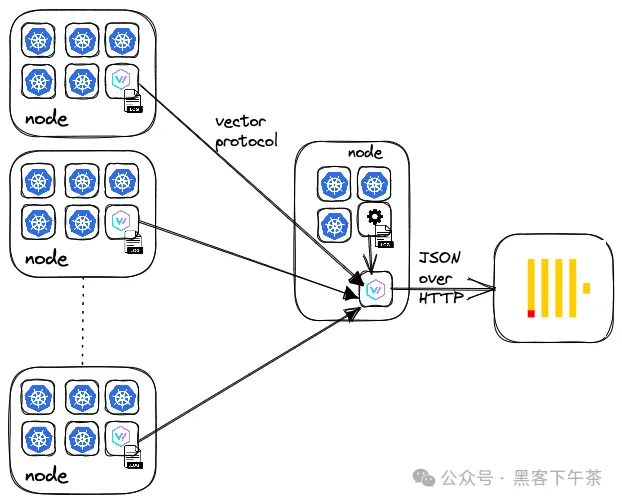
再次,我们使用 Helm 作为首选的安装方法,利用官方 chart。聚合器和代理的完整安装细节在这里,还包括示例配置。除了将输出源更改为 ClickHouse 之外,主要的变化是需要使用一个 remap 转换,它使用 Vector Remap Language (VRL)确保列使用 _ 作为分隔符而不是 .。
Data
我们可以使用一个简单的查询确认日志数据正在被插入:
sh
SELECT *
FROM vector.vector_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
file: /var/log/pods/argocd_argocd-application-controller-0_33574e53-966a-4d54-9229-205fc2a4ea03/application-controller/0.log
timestamp: 2023-01-05 12:12:50.766
kubernetes_container_id:
kubernetes_container_image: quay.io/argoproj/argocd:v2.3.3
kubernetes_namespace_labels: {'kubernetes.io/metadata.name':'argocd','name':'argocd'}
kubernetes_node_labels: {'beta.kubernetes.io/arch':'amd64','beta.kubernetes.io/instance-type':'r5.xlarge'...}
kubernetes_container_name: application-controller
kubernetes_pod_annotations: {'ad.agent.com/application-controller.check_names':'["openmetrics"]...'}
kubernetes_pod_ip: 10.1.3.30
kubernetes_pod_ips: ['10.1.3.30']
kubernetes_pod_labels: {'app.kubernetes.io/component':'application-controller'...}
kubernetes_pod_name: argocd-application-controller-0
kubernetes_pod_namespace: argocd
kubernetes_pod_node_name: ip-10-1-1-210.us-west-2.compute.internal
kubernetes_pod_owner: StatefulSet/argocd-application-controller
kubernetes_pod_uid: 33574e53-966a-4d54-9229-205fc2a4ea03
message: {"level":"info","msg":"Ignore '/spec/preserveUnknownFields' for CustomResourceDefinitions","time":"2023-01-05T12:12:50Z"}
source_type: kubernetes_logs
stream: stderrFluent Bit
Fluent Bit 是一个日志和指标 processor(处理器)及 forwarder(转发器)。它最初专注于日志处理,并用 C 语言编写以尽量减少任何开销,FluentBit 致力于轻量级和高速度。该代码最初由 TreasureData 开发,但早已作为开源项目在 Cloud Native Computing Foundation 下发布,遵循 Apache 2.0 许可证。多个云提供商将其作为第一类公民采用,它提供了与上述工具相当的输入、处理和输出功能。
- http://fluentbit.io/
- https://github.com/fluent/fluent-bit#fluent-bit-in-production
- https://github.com/fluent/fluent-bit#plugins-inputs-filters-and-outputs
FluentBit 使用 intputs(输入)、parsers(解析器)/filters(过滤器)和 outputs(输出)为其 pipeline(管道)(以及 buffer(缓冲区)和 router(路由器)概念,这些超出了本文范围)。聚合实例被称为 aggregator(聚合器)。
- https://docs.fluentbit.io/manual/concepts/data-pipeline/input
- https://docs.fluentbit.io/manual/concepts/data-pipeline/parser
- https://docs.fluentbit.io/manual/concepts/data-pipeline/filter
- https://docs.fluentbit.io/manual/concepts/data-pipeline/output
- https://docs.fluentbit.io/manual/concepts/data-pipeline/buffer
- https://docs.fluentbit.io/manual/concepts/data-pipeline/router
- https://fluentbit.io/blog/2020/12/03/common-architecture-patterns-with-fluentd-and-fluent-bit/
ClickHouse support
FluentBit 没有专门针对 ClickHouse 的输出插件,而是依赖通用的 HTTP 支持。这种方法工作良好,并依赖于将数据以 JSONEachRow 格式插入。然而,用户需要注意这种方法不执行批处理。因此,需要适当配置 FluentBit 来避免大量的小批量插入和 "too many part" 问题。用户应当知道 Fluent Bit 将所有内容存储为块。这些chunks(块)具有 tag 和最多 2MB 的有效负载大小的数据结构。当使用 Kubernetes 时,每个容器会输出到一个由动态 tag 标识的单独文件。Tag 也用于读取各个块。这些块按 tag 独立地由代理程序按照刷新间隔刷新到 aggregator(聚合器)。聚合器保留 tag 信息以满足下游路由需求。它会根据每个 tag 设置自己的刷新间隔来确定对 ClickHouse 的写入操作。因此,用户有两种选择:
https://docs.fluentbit.io/manual/pipeline/outputs/http
https://clickhouse.com/blog/common-getting-started-issues-with-clickhouse
https://docs.fluentbit.io/manual/administration/buffering-and-storage#chunkshttps://docs.fluentbit.io/manual/v/1.3/configuration/file#config_section
-
配置较大的刷新间隔,例如至少
10秒,在代理和聚合器上。这可能是有效的,但也可能导致 thundering-herd effect(惊群效应),导致向 ClickHouse 插入数据时出现峰值。但是,如果间隔足够大,内部合并应该能够跟上。 -
配置输出使用 ClickHouse 的异步插入 - 如果你不部署聚合器实例,特别推荐这种方法。这会导致 ClickHouse 缓冲插入操作,是处理这种写模式的推荐方法。异步插入的行为可以通过影响 Fluent Bit 的交付保证进行调整。具体来说,设置
wait_for_async_insert控制写入是否在写入 buffer 时得到确认(0)或在实际写入为数据部分并可用于查询时得到确认。值为 1 提供了更强的交付保证,但可能降低吞吐量。注意 Fluent Bit 的偏移管理及推进基于输出的确认。对于wait_for_async_insert设置为 0 的情况,意味着数据在完全处理之前就得到了确认,即后续可能出现失败导致数据丢失。在某些情况下,这可能是可以接受的。注意还有设置async_insert_max_data_size和async_insert_busy_timeout_ms,它们控制缓冲区的确切刷新行为。
没有明确理解 ClickHouse 的情况下,用户必须在部署前预创建表。与 Vector 类似,这将 schema 决策留给了用户。FluentBit 创建了一个嵌套深度大于 1 的 JSON Schema。这可能会包含数百个字段,因为每个唯一的 label 或 annotation 都会创建一个独特的列。我们之前的帖子建议使用 JSON type为此 kubernetes 列。这将列创建推迟给 ClickHouse,并允许根据数据动态创建子列。这提供了一个很好的入门体验,但并非最优,因为用户不能使用编解码器或在表的排序键中使用特定的子列(除非使用 JSONExtract),从而导致较差的压缩和较慢的查询。它也可能导致在没有控制 label 和 annotation 使用的环境中出现列爆炸。此外,此功能目前处于实验阶段。对此 schema 的一个更优化的方法是将 labels 和 annotations 移动到 Map type - 这方便地将 kubernetes 列减少到一层嵌套。这需要我们在处理管道中稍微修改数据结构,并产生以下 schema。
- https://clickhouse.com/docs/en/guides/developer/working-with-json/json-semi-structured
- https://clickhouse.com/docs/en/sql-reference/functions/json-functions/
- https://clickhouse.com/docs/en/integrations/data-formats/json#other-approaches
sh
CREATE TABLE fluent.fluent_logs
(
`timestamp` DateTime64(9),
`log` String,
`kubernetes` Map(LowCardinality(String), String),
`host` LowCardinality(String),
`pod_name` LowCardinality(String),
`stream` LowCardinality(String),
`labels` Map(LowCardinality(String), String),
`annotations` Map(LowCardinality(String), String)
)
ENGINE = MergeTree
ORDER BY (host, pod_name, timestamp)Kubernetes 部署

一篇之前的博客文章详细讨论了将 Fluent Bit 部署到收集 Kubernetes 日志到 ClickHouse。这篇文章关注于仅部署代理架构而不部署聚合器。一般配置仍然适用,只是有一些不同之处以改进模式并引入聚合器。
聚合器和代理的完整安装细节以及示例配置可以在这里找到。关于配置的一些重要细节:
-
我们使用不同的 Lua 脚本来将特定字段从
kubernetes键移动到根目录,以便这些字段可以在排序键中使用。我们还将annotations 和 labels 移动到根目录。这允许它们被声明为 Map 类型,并且由于它们非常稀疏而被排除在压缩统计之外。此外,这意味着我们的kubernetes列只有一层嵌套,并且也可以声明为 Map 类型。 -
聚合器输出在 URI 中指定了使用异步插入。我们结合使用了 5 秒的刷新间隔。在我们的示例中,我们没有指定
wait_for_async_insert=1,但可以根据需要作为参数附加。
Data
我们可以使用简单的查询来确认日志数据正在插入:
sh
SELECT *
FROM fluent.fluent_logs
LIMIT 1
FORMAT Vertical
Row 1:
──────
timestamp: 2023-01-05 13:11:36.452730318
log: 2023.01.05 13:11:36.452588 [ 41 ] {} RaftInstance: Receive a append_entries_request message from 1 with LastLogIndex=298734, LastLogTerm=17, EntriesLength=0, CommitIndex=298734 and Term=17
kubernetes: {'namespace_name':'ns-chartreuse-at-71','container_hash':'609927696493.dkr.ecr.us-west-2.amazonaws.com/clickhouse-keeper@sha256:e9efecbef9498dea6ddc029a8913dc391c49c7d0b776cb9b1c767cdb1bf15489',...}
host: ip-10-1-3-9.us-west-2.compute.internal
pod_name: c-chartreuse-at-71-keeper-2
stream: stderr
labels: {'controller-revision-hash':..}互操作性和选择栈
我们之前的示例假设代理和聚合器都使用相同的技术。通常这并非最优选择,甚至有时不可能实现,原因可能是组织标准或代理不支持特定的数据类型。例如,如果您使用 Open Telemetry 语言代理进行追踪,则可能会部署一个 OTEL Collector 作为聚合器。在这种情况下,您可以选择 Fluent Bit 作为首选的日志收集代理(因为它在这方面更加成熟),但仍继续使用 OTEL Collector 作为聚合器以保持数据模型的一致性。
幸运的是,作为更广泛的 Open Telemetry 项目一部分推广的 OTLP 协议以及对 forward 协议的支持(这是 Fluent Bit 偏好的通信标准)在某些情况下允许实现互操作性。
Vector 支持这些协议作为数据源,并可以作为 Fluent Bit 和 Open Telemetry Collector 的日志聚合器。但是,它不支持这些协议作为接收端,这使得在已经部署了 OTEL Collector 或 Fluent Bit 的环境中将其作为代理来部署变得具有挑战性。请注意,Vector 对于您应该用 Vector 替换的栈中的哪些组件有着明确的观点。
Fluent Bit 最近增加了 OTLP 支持作为输入和输出,这可能允许与 OTEL Collector(也支持 forward 协议作为接收器)实现高度的互操作性。作为日志收集代理的 Fluent Bit,通过 forward 或 OTLP 协议向 OTEL Collector 发送数据,正变得越来越流行,尤其是在 Open Telemetry 已经成为标准的环境中。
- https://github.com/fluent/fluent-bit/pull/5928
- https://github.com/fluent/fluent-bit/pull/5747
- https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver/fluentforwardreceiver
注意:截至本文撰写之时,我们在 Fluent Bit 的 OTLP 输入和输出方面遇到了一些问题,但我们预计这些问题很快会得到解决。
下面总结了当前日志收集的兼容状态,并链接到示例 Helm 配置,其中详细说明了已知的问题,这些可以参照上面的例子。请注意,这里仅讨论日志收集。

https://github.com/ClickHouse/examples/tree/main/observability/logs/kubernetes
当代理配置为聚合器以从不同的技术接收事件时,最终的数据模式会与等效的同构架构不同。上述链接展示了结果数据模式的例子。如果需要一致的数据模式,用户可能需要利用每个代理的转换功能。
压缩
将日志数据存储在 ClickHouse 中的主要好处之一就是其出色的压缩性能:这是由于它的列式设计和可配置的编解码器。以下查询显示,在之前收集的数据上,根据不同的聚合器,我们的压缩率范围从 14 倍到 30 倍不等。这些结果代表的是未经优化的模式(尽管默认的 OTEL 模式是合理的),因此通过调整可以实现进一步的压缩。细心的读者会注意到,我们排除了 Kubernetes 的 labels 和 annotations,这些默认添加到了 Fluent Bit 和 Vector 的部署中,但在 OTEL Collector 中并未添加(虽然 OTEL Collector 支持这一点,但需要额外的配置)。这些数据非常稀疏,并且因为大多数 annotations 只存在于一小部分 Pod 上而被压缩得非常好。这扭曲了压缩比率(提高了它们),因为大多数值为空,所以我们选择排除它们 --- 好消息是这些数据在被压缩后占用的空间很小。
sh
SELECT
database,
table,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE (database IN ('fluent', 'vector', 'otel')) AND (name NOT LIKE '%labels%') AND (name NOT LIKE '%annotations%')
GROUP BY
database,
table
ORDER BY
database ASC,
table ASC
┌─database─┬─table───────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ fluent │ fluent_logs │ 2.43 GiB │ 80.23 GiB │ 33.04 │
│ otel │ otel_logs │ 5.57 GiB │ 78.51 GiB │ 14.1 │
│ vector │ vector_logs │ 3.69 GiB │ 77.92 GiB │ 21.13 │
└──────────┴─────────────┴─────────────────┴───────────────────┴───────┘我们将在后续的文章中探讨这些变化的压缩率的原因,但即使是初次尝试,上述的压缩率也显示出相对于其他解决方案的巨大潜力。这些 schemas(模式)可以被规范化,并且可以独立于代理实现类似的压缩率,因此这些结果不应该用来比较代理。
关于注释高压缩率的一个例子:
sh
SELECT
name,
table,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE (database IN ('fluent', 'vector', 'otel')) AND ((name LIKE '%labels%') OR (name LIKE '%annotations%'))
GROUP BY
database,
table,
name
ORDER BY
database ASC,
table ASC
┌─name────────────────────────┬─table───────┬─compressed_size─┬─uncompressed_size─┬──ratio─┐
│ labels │ fluent_logs │ 2.95 MiB │ 581.31 MiB │ 196.93 │
│ annotations │ fluent_logs │ 14.97 MiB │ 7.17 GiB │ 490.57 │
│ kubernetes_pod_annotations │ vector_logs │ 36.67 MiB │ 23.97 GiB │ 669.29 │
│ kubernetes_node_labels │ vector_logs │ 18.67 MiB │ 4.18 GiB │ 229.55 │
│ kubernetes_pod_labels │ vector_logs │ 6.89 MiB │ 1.88 GiB │ 279.92 │
│ kubernetes_namespace_labels │ vector_logs │ 3.91 MiB │ 468.14 MiB │ 119.62 │
└─────────────────────────────┴─────────────┴─────────────────┴───────────────────┴────────┘我们将在未来的文章中深入探讨这一点,但在此期间推荐阅读使用 Schemas and Codecs 优化 ClickHouse。
查询 & 可视化日志
常见查询
日志数据本质上是 time-series(时间序列) 数据,ClickHouse 提供了许多函数来辅助查询。我们在最近的一篇博客文章中对此进行了详尽的介绍,其中大多数查询概念都是相关的。大多数仪表板和调查都需要按时间进行聚合以绘制时间序列图表,随后再根据 server/pod 名称或错误代码进行过滤。下面的示例使用了 Vector 收集的日志,但这些示例可以适应其他收集类似字段的代理数据。
按 pod 名称随时间变化的日志
在这里,我们按照自定义的时间间隔进行分组,并使用填充来填充缺失的分组。根据需要进行调整。请参阅我们最近的博客获取更多详情。
sh
SELECT
toStartOfInterval(timestamp, toIntervalDay(1)) AS time,
kubernetes_pod_name AS pod_name,
count() AS c
FROM vector.vector_logs
GROUP BY
time,
pod_name
ORDER BY
pod_name ASC,
time ASC WITH FILL STEP toIntervalDay(1)
LIMIT 5
┌────────────────time─┬─pod_name──────────────────────────────────────────┬─────c─┐
│ 2023-01-05 00:00:00 │ argocd-application-controller-0 │ 8736 │
│ 2023-01-05 00:00:00 │ argocd-applicationset-controller-745c6c86fd-vfhzp │ 9 │
│ 2023-01-05 00:00:00 │ argocd-notifications-controller-54495dd444-b824r │ 15137 │
│ 2023-01-05 00:00:00 │ argocd-repo-server-d4787b66b-ksjps │ 2056 │
│ 2023-01-05 00:00:00 │ argocd-server-58dd79dbbf-wbthh │ 9 │
└─────────────────────┴───────────────────────────────────────────────────┴───────┘
5 rows in set. Elapsed: 0.270 sec. Processed 15.62 million rows, 141.97 MB (57.76 million rows/s., 524.86 MB/s.)在特定时间窗口内针对容器的日志
sh
SELECT
timestamp,
kubernetes_pod_namespace AS namespace,
kubernetes_pod_name AS pod,
kubernetes_container_name AS container,
message
FROM vector.vector_logs
WHERE (kubernetes_pod_name = 'argocd-application-controller-0') AND ((timestamp >= '2023-01-05 13:40:00.000') AND (timestamp <= '2023-01-05 13:45:00.000'))
ORDER BY timestamp DESC
LIMIT 2
FORMAT Vertical
Row 1:
──────
timestamp: 2023-01-05 13:44:41.516
namespace: argocd
pod: argocd-application-controller-0
container: application-controller
message: W0105 13:44:41.516636 1 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
Row 2:
──────
timestamp: 2023-01-05 13:44:09.515
namespace: argocd
pod: argocd-application-controller-0
container: application-controller
message: W0105 13:44:09.515884 1 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
2 rows in set. Elapsed: 0.219 sec. Processed 1.94 million rows, 21.59 MB (8.83 million rows/s., 98.38 MB/s.)查询 Map 类型
上述许多代理产生相似的模式,并使用 Map 数据类型来处理 Kubernetes 的 annotations 和 labels。用户可以通过 map notation 法访问嵌套键,此外还可以使用专门的 ClickHouse map functions 来进行过滤或选择这些列。
- https://clickhouse.com/docs/en/guides/developer/working-with-json/json-other-approaches#using-maps
- https://clickhouse.com/docs/en/sql-reference/functions/tuple-map-functions/
sh
SELECT
kubernetes_pod_labels['statefulset.kubernetes.io/pod-name'] AS statefulset_pod_name,
count() AS c
FROM vector.vector_logs
WHERE statefulset_pod_name != ''
GROUP BY statefulset_pod_name
ORDER BY c DESC
LIMIT 10
┌─statefulset_pod_name────────┬──────c─┐
│ c-snow-db-40-keeper-2 │ 587961 │
│ c-coral-cy-94-keeper-0 │ 587873 │
│ c-ivory-es-35-keeper-2 │ 587331 │
│ c-feldspar-hh-33-keeper-2 │ 587169 │
│ c-steel-np-64-keeper-2 │ 586828 │
│ c-fuchsia-qe-86-keeper-2 │ 583358 │
│ c-canary-os-78-keeper-2 │ 546849 │
│ c-salmon-sq-90-keeper-1 │ 544693 │
│ c-claret-tk-79-keeper-2 │ 539923 │
│ c-chartreuse-at-71-keeper-1 │ 538370 │
└─────────────────────────────┴────────┘
10 rows in set. Elapsed: 0.343 sec. Processed 16.98 million rows, 3.15 GB (49.59 million rows/s., 9.18 GB/s.)
// use groupArrayDistinctArray to list all pod label keys
SELECT groupArrayDistinctArray(mapKeys(kubernetes_pod_annotations))
FROM vector.vector_logs
LIMIT 10
['clickhouse.com/chi','clickhouse.com/namespace','release','app.kubernetes.io/part-of','control-plane-id','controller-revision-hash','app.kubernetes.io/managed-by','clickhouse.com/replica','kind','chart','heritage','cpu-request','memory-request','app.kubernetes.io/version','app','clickhouse.com/ready','clickhouse.com/shard','clickhouse.com/settings-version','control-plane','name','app.kubernetes.io/component','updateTime','clickhouse.com/app','role','pod-template-hash','app.kubernetes.io/instance','eks.amazonaws.com/component','clickhouse.com/zookeeper-version','app.kubernetes.io/name','helm.sh/chart','k8s-app','statefulset.kubernetes.io/pod-name','clickhouse.com/cluster','component','pod-template-generation']查找包含特定字符串的日志的容器
可以通过 ClickHouse 的字符串和正则表达式函数对日志行进行模式匹配,如下所示:
sh
SELECT
kubernetes_pod_name,
count() AS c
FROM vector.vector_logs
WHERE message ILIKE '% error %'
GROUP BY kubernetes_pod_name
ORDER BY c DESC
LIMIT 5
┌─kubernetes_pod_name──────────────────────────────────────────┬───c─┐
│ falcosidekick-ui-redis-0 │ 808 │
│ clickhouse-operator-clickhouse-operator-helm-dc8f5789b-lb88m │ 48 │
│ argocd-repo-server-d4787b66b-ksjps │ 37 │
│ kube-metric-forwarder-7df6d8b686-29bd5 │ 22 │
│ c-violet-sg-87-keeper-1 │ 22 │
└──────────────────────────────────────────────────────────────┴─────┘
5 rows in set. Elapsed: 0.578 sec. Processed 18.02 million rows, 2.79 GB (31.17 million rows/s., 4.82 GB/s.)使用正则表达式查找有问题的容器
sh
SELECT
kubernetes_pod_name,
arrayCompact(extractAll(message, 'Cannot resolve host \\((.*)\\)')) AS cannot_resolve_host
FROM vector.vector_logs
WHERE match(message, 'Cannot resolve host')
LIMIT 5
FORMAT PrettyCompactMonoBlock
┌─kubernetes_pod_name─────┬─cannot_resolve_host──────────────────────────────────────────────────────────────────────────┐
│ c-violet-sg-87-keeper-0 │ ['c-violet-sg-87-keeper-1.c-violet-sg-87-keeper-headless.ns-violet-sg-87.svc.cluster.local'] │
│ c-violet-sg-87-keeper-0 │ ['c-violet-sg-87-keeper-2.c-violet-sg-87-keeper-headless.ns-violet-sg-87.svc.cluster.local'] │
│ c-violet-sg-87-keeper-0 │ ['c-violet-sg-87-keeper-1.c-violet-sg-87-keeper-headless.ns-violet-sg-87.svc.cluster.local'] │
│ c-violet-sg-87-keeper-0 │ ['c-violet-sg-87-keeper-2.c-violet-sg-87-keeper-headless.ns-violet-sg-87.svc.cluster.local'] │
│ c-violet-sg-87-keeper-0 │ ['c-violet-sg-87-keeper-1.c-violet-sg-87-keeper-headless.ns-violet-sg-87.svc.cluster.local'] │
└─────────────────────────┴──────────────────────────────────────────────────────────────────────────────────────────────┘
5 rows in set. Elapsed: 0.690 sec. Processed 18.04 million rows, 2.76 GB (26.13 million rows/s., 3.99 GB/s.)查询性能优化
对于上述代理生成的数据的查询性能主要取决于在创建表时定义的排序键。这些键应与您的典型工作流程和访问模式相匹配。确保您在工作流程中经常用于过滤的列出现在 ORDER BY 表声明中。这些列的排序还应考虑它们各自的基数,以确保 ClickHouse 可以使用最佳的过滤算法。在大多数情况下,按照基数递增的顺序排列您的列。对于日志来说,这意味着通常先放置服务器或容器名称,然后是时间戳:但这取决于您计划如何进行过滤。超过 3-4 列的键内的列通常不建议使用,并且提供的价值不大。相反,可以考虑加速查询的替代方案,如在文章超级加速您的 ClickHouse 查询和在 ClickHouse 中处理时间序列数据中讨论的那样。
- https://clickhouse.com/docs/en/guides/improving-query-performance/sparse-primary-indexes/sparse-primary-indexes-multiple/#generic-exclusion-search-algorithm
- https://clickhouse.com/blog/clickhouse-faster-queries-with-projections-and-primary-indexes
- https://clickhouse.com/blog/working-with-time-series-data-and-functions-ClickHouse
Map 类型在这篇文章中的许多模式中都很常见。这种类型要求值和键具有相同的类型------这对于 Kubernetes 标签来说是足够的。需要注意的是,在查询 Map 类型的子键时,整个父列会被加载。如果映射中有许多键,这可能会导致显著的查询开销。如果您需要频繁查询特定的键,请考虑将其移动到根级别的专用列中。
需要注意的是,我们目前发现 OTEL Collector 默认的表模式和排序键在数据集变大时会使某些查询变得昂贵,特别是如果您的访问模式与键不匹配的话。用户应根据自己的工作流程评估模式,并提前创建表以避免这种情况。
OTEL 模式为使用 TTL 来管理数据提供了灵感。这对于日志数据尤其相关,因为日志数据通常只需要保留几天就可以删除。需要注意的是,分区可能会对查询性能产生正面或负面的影响:如果大多数查询只命中单个分区,查询性能会有所提高。相反,如果查询通常会命中多个分区,则可能导致性能下降。
最后,即使您的访问模式与排序键不完全匹配,ClickHouse 中的线性扫描也非常快,使得大多数查询仍然可行。未来的一篇文章将更详细地探讨针对日志优化模式和排序键的方法。
可视化工具
我们目前推荐使用官方 ClickHouse 插件的 Grafana 来可视化和探索日志数据。之前的帖子和视频已经深入探讨了这个插件。
- https://grafana.com/grafana/plugins/grafana-clickhouse-datasource/
- https://clickhouse.com/blog/visualizing-data-with-grafana
- https://www.youtube.com/watch?v=Ve-VPDxHgZU
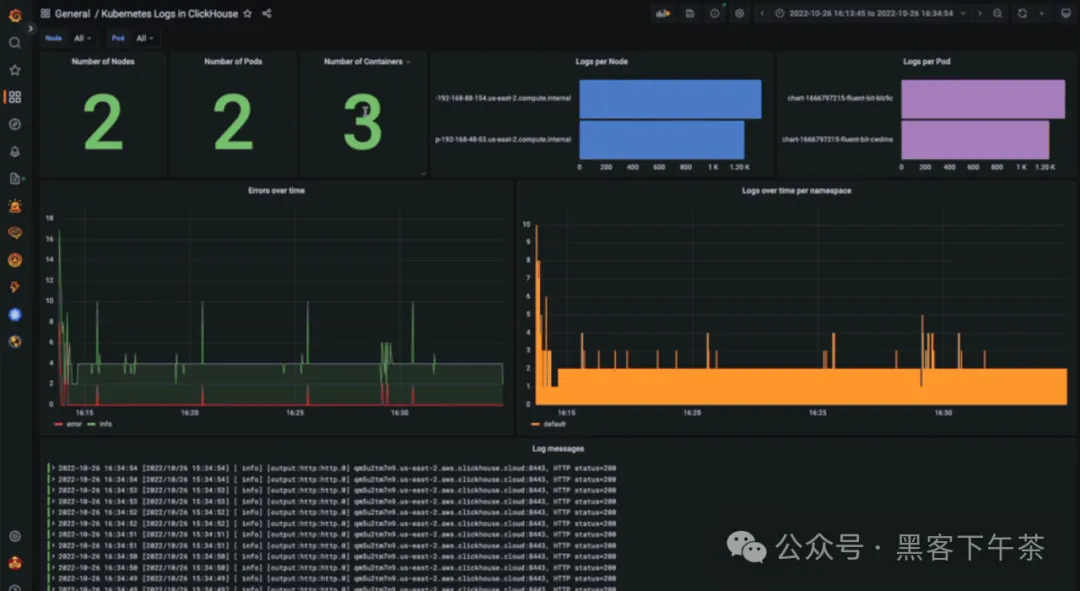
我们之前使用 Fluent Bit 的博客文章演示了如何在 Grafana 中可视化来自 Kubernetes 的日志数据。可以从这里下载此仪表板,并像下面所示导入到 Grafana 中------请注意仪表板 id 为 17284。将此适配到特定代理的选择留给读者自行完成。
- https://clickhouse.com/blog/kubernetes-logs-to-clickhouse-fluent-bit#visualizingthekubernetesdata
- https://grafana.com/grafana/dashboards/17284
- https://grafana.com/docs/grafana/v9.0/dashboards/export-import/
此仪表板的只读版本可从这里获得。
结论
本篇博客展示了如何利用多种代理和技术轻松地收集并存储日志数据到 ClickHouse。虽然我们使用了现代的 Kubernetes 架构来说明这一点,但这些工具同样适用于更传统的自管理服务器或容器编排系统。我们也提到了查询以及可能的互操作方法和挑战。为了进一步阅读,我们鼓励用户探索超出本文的主题,例如代理如何处理队列、背压以及它们承诺的交付保证。我们将在后续的文章中探讨这些主题,并向我们的 ClickHouse 实例中添加指标和追踪数据,然后再探讨如何优化 schemas 以及如何利用生命周期功能管理数据。