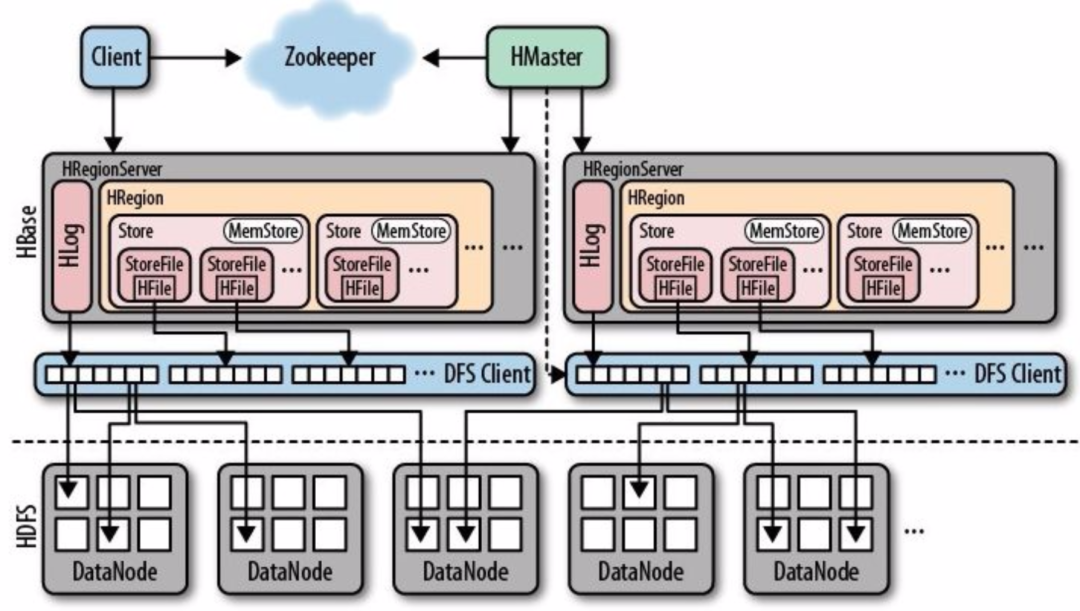
在大数据生态系统中,HBase 和 HDFS 是两个关键组件。HBase 是一个分布式列式数据库,常用于实时读写大规模数据;HDFS 是一个高可靠的分布式文件系统,用于存储海量数据。
1、背景
随着业务的发展和技术的进步,可能需要对现有的HBase/Hadoop集群进行迁移,或是因为各种原因(如成本控制、硬件升级、地理位置调整等)进行机房搬迁。这样的操作不仅涉及到大量的技术细节,还需要考虑业务连续性和数据一致性等关键因素。
2、重难点
在集群迁移过程中,为了避免HDFS NameNode的单点故障 风险,并增强系统的高可用性和容错能力,HDFS需要采用**多NameNode(MultiNN)**架构。在这一架构下,至少需要三个及以上的NameNode节点来确保在替换和迁移过程中,能够无缝地进行NameNode的切换和迁移,从而实现服务的不间断运行。
3、涉及迁移的角色
公共服务
- ZooKeeper:5台
HBASE
-
HMaster:1台
-
HRegion Server:n台
-
HBase thrift-Server:n台
HDFS
-
NameNode【重点】:2台HA
-
JN:5台
-
DFS-Router:2台
-
ZKFC:2台
4、迁移流程
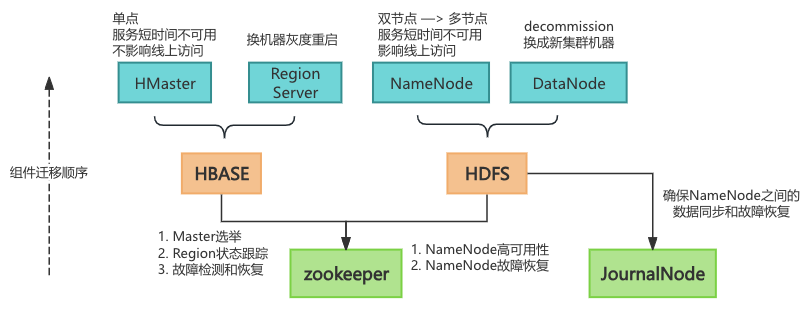
step1: 扩容ZK
预备知识:
-
zk节点dead过半后,如果leader down掉,将无法选主
-
zk集群如果无法选主,HBase集群服务将彻底挂掉
-
如果zk只剩下leader存活,其他follower全部宕机,hbase服务正常
扩容步骤:
- 扩容新集群的7台zk到原zk集群
说明:采取5台old+7台new方式进行扩容,因为如果5+5扩容,双数10台实际效果等于9台,扩容完毕后,再次缩容的时候就有风险了,因为dead过半了 一旦leader挂了就没法选主了。扩成成5+7后,这样就算第二轮关闭原来5台节点,新leader挂了也可以容错选主;主要操作成本在于让hbase识别扩容后的zk集群,需要重启生效。
step 2: JournalNode扩容
扩容步骤(扩入新集群的5台JN):
-
修改配置文件:在所有 NameNode(包括
nn1和nn2)以及所有 JournalNode 上编辑hdfs-site.xml配置文件,以新增的 JournalNode 配置信息。 -
依次重启 JournalNode:逐一重启每一个 JournalNode 实例,确保在重启下一个 JournalNode 之前,当前重启的 JournalNode 已经处于稳定状态。
-
重启 NameNode 并切换角色:首先重启处于 Standby 模式的 NameNode,随后通过操作命令进行主备切换,之后再重启另一个 NameNode,以此来确保新的 JournalNode 配置被主 NameNode 所识别并使用。
说明:为保证JounalNode的高可用,需要先扩容后再缩容,避免单点风险(3台old+5台new 类似于上述zk)。
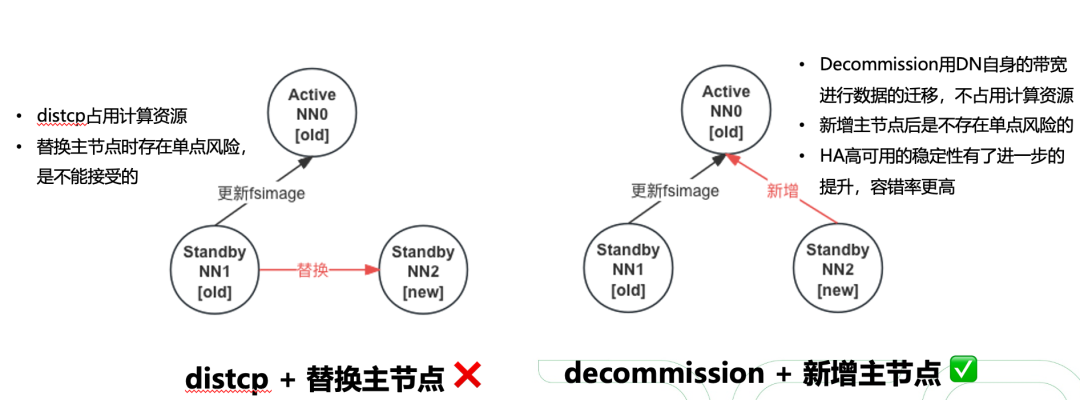
step 3: 迁移NN主节点
预备知识:机房搬迁/集群迁移,只要是涉及到换HDFS主节点,就不可避免的会带来单点风险,为了保证底层存储服务的稳定性,数据的一致性,必须随时保证有两个及以上的主节点可以正常提供服务,需要新增多NN(一主多备)的功能。
扩容步骤:
-
修改HA配置,添加在新集群上的Standby节点
-
拷贝老standby节点的fsimage editlog到新节点对应目录(整个namenode目录)
-
将三个节点的相关配置更新到所有的DataNode节点上,并refresh使配置生效
-
观察所有DataNode节点是否能成功汇报至新增Standby节点,fsimage是否能从两个Standby节点向Active节点成功更新
-
重复上述步骤,将所有NameNode都更新为新集群的节点,完成HDFS主节点的迁移
说明:通过上述步骤将可用NameNode个数随时保证在2个及以上,避免单点风险。
step 4: 迁移DN数据节点
迁移步骤:
-
扩容新集群的DN节点到该集群
-
采用decommission将老集群的DN节点逐步下掉(数据自动挪到新机器上)
说明:Decommission占用DN自身的带宽进行数据的迁移,不占用额外的计算资源。
step 5: RegionServer滚动重启
重启步骤:(换机器灰度重启)
-
新机器上新增hadoop客户端相关的HA配置(有router的话,可以配置router地址进行解析)
-
新机器上修改扩容后zk相关配置
-
逐步启动新机器的RS服务,观察服务是否能正常稳定运行
-
逐步停掉老机器的服务,并观察服务是否正常,若出现问题,立刻回滚
step 6: 替换HBase Master节点
预备知识:HBase Master负责一些周期性的清理工作,负载均衡,元数据操作;短时间无法提供服务是不会影响线上的请求的。
替换步骤:
-
新机器上新增hadoop客户端相关的HA配置(有router的话,可以配置router地址进行解析),并修改扩容后zk相关配置
-
停老机器上的Master服务
-
启动新机器的Master服务
-
观察服务是否正常,若出现问题,立刻回滚
step 7: zk缩容
缩容后只留下5台新集群的zk节点,并修改NameNode,DataNode,HMaster,RegionServer服务上的相关配置。
step 8: JournalNode缩容
缩容后只留下5台新集群的JN节点,并修改NameNode上相关的配置。
step 9: RegionServer滚动重启
滚动重启步骤:
-
依次将rs上的region无缝分配到其他机器,将rs挪到其他RSGroup中,业务几乎无感知
gomove_servers_rsgroup 'dest',['server1:port'] -
待rs上所有region都分配到其他机器上,可以重启机器,使新配置生效
-
最后将重启完的rs挪回原来的RSGroup,集群负载均衡后,即可正常提供服务
step 10: 重启所有NameNode节点并切换主备
升级遇到可优化问题
1. refresh node for DN
(1)执行refresh node,对于老的ns,是否应该区别对待,只向新建立ns进行汇报,减少汇报开销
(2)执行refresh node生效标志,目前是异步非阻塞执行,判断成功标志成本很高,是否应该做成同步阻塞执行
关键DN日志标志着命令生效:
-
refresh命令生效:Refresh request received for nameservices
-
开始为某台NN提供Block pool服务:starting to offer service
-
开始与NN挥手建联:beginning handshake with NN
标志着子流程阶段性成功:
- 成功注册到NN:successfully registered with NN
标志着refresh导致DN异常
-
根本性配置错误:Invalid host name: local host is: (unknown); destination host is
-
根本性配置错误:Namenode for *** remains unresolved for ID null
-
【重点校验】偶发性错误,初始化注册block pool失败:Initialization failed for Block pool <registering>
2. 部分命令失效
前提:hdfs://xxxxx域名解析到router的lvs
(1)fsck失败,因为fsck访问hdfs://xxxxx:50070端口转向NN的web port,需要lvs上加上web端口解析
(2)升级后getReplicatedBlockStats方法不生效的原因是该方法走了hdfs://xxxxx域名,但是我们把他做成了router域名,在router实现上该方法没有支持, 所以暂时无法使用 ~/software/hadoop/bin/hdfs dfsadmin -report -live
解决办法:HDFS-14714. RBF: implement getReplicatedBlockStats interface. Contributed by Chen Zhang.
(3)同上,balance也无法工作:org.apache.hadoop.ipc.RemoteException(java.lang.UnsupportedOperationException): Operation "isUpgradeFinalized" is not supported
(4)balance执行中方法解析uri中"_"是非法的导致无法启动
properties
2024-05-30 02:00:46,832 ERROR org.apache.hadoop.hdfs.server.balancer.Balancer: Exiting balancer due an exception
java.lang.IllegalArgumentException: Illegal character in hostname at index 10: hdfs://xxxxx
at org.apache.hadoop.hdfs.DFSUtil.createUri(DFSUtil.java:1232)
at org.apache.hadoop.hdfs.DFSUtil.getNameServiceUris(DFSUtil.java:820)
at org.apache.hadoop.hdfs.DFSUtil.getInternalNsRpcUris(DFSUtil.java:791)
at org.apache.hadoop.hdfs.server.balancer.Balancer$Cli.run(Balancer.java:820)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.hadoop.hdfs.server.balancer.Balancer.main(Balancer.java:968)
备注:要留意hadoop-work-balancer-***.out中的日志更多产品和技术文章,敬请关注👆
360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。
目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案,助力客户降本增效,累计服务业务1000+。
智汇云致力于为各行各业的业务及应用提供强有力的产品、技术服务,帮助企业和业务实现更大的商业价值。
客服电话:4000052360