文章目录
-
- [1 初识MQ](#1 初识MQ)
-
- [1.1 同步调用](#1.1 同步调用)
-
- [1.1.1 同步调用的优势](#1.1.1 同步调用的优势)
- [1.1.2 同步调用的缺点](#1.1.2 同步调用的缺点)
- [1.2 异步调用](#1.2 异步调用)
-
- [1.2.1 异步调用的角色](#1.2.1 异步调用的角色)
- [1.2.2 异步调用的优势](#1.2.2 异步调用的优势)
- [1.2.3 异步调用的缺点](#1.2.3 异步调用的缺点)
- [1.2.4 异步调用的场景](#1.2.4 异步调用的场景)
- [1.3 MQ技术选型](#1.3 MQ技术选型)
- [2 RabbitMQ](#2 RabbitMQ)
-
- [2.1 安装](#2.1 安装)
-
- [2.1.1 资源准备](#2.1.1 资源准备)
- [2.1.2 安装步骤](#2.1.2 安装步骤)
- [2.2 RabbitMQ架构](#2.2 RabbitMQ架构)
- [2.3 RabbitMQ管理控制台收发消息](#2.3 RabbitMQ管理控制台收发消息)
-
- [2.3.1 创建队列](#2.3.1 创建队列)
- [2.3.2 交换机绑定队列★](#2.3.2 交换机绑定队列★)
- [2.3.3 交换机发送消息](#2.3.3 交换机发送消息)
- [2.3.4 查看消息接收](#2.3.4 查看消息接收)
- [2.4 数据隔离](#2.4 数据隔离)
-
- [2.4.1 用户管理](#2.4.1 用户管理)
- [2.4.2 virtual host 用户授权](#2.4.2 virtual host 用户授权)

🙊 前言:本文章为瑞_系列专栏之《RabbitMQ》的初识MQ篇,主要介绍了市面上常见的 MQ,RabbitMQ 的安装、架构、管理控制台的基本使用以及数据隔离。由于博主是从B站黑马程序员的《RabbitMQ》学习其相关知识,所以本系列专栏主要是针对该课程进行笔记总结和拓展,文中的部分原理及图解等也是来源于黑马提供的资料,特此注明。本文仅供大家交流、学习及研究使用,禁止用于商业用途,违者必究!
1 初识MQ
微服务一旦拆分,必然涉及到服务之间的相互调用,目前我们服务之间调用采用的都是基于 OpenFeign 的调用。这种调用中,调用者发起请求后需要等待 服务提供者执行业务返回结果后,才能继续执行后面的业务。也就是说调用者在调用过程中处于阻塞状态,因此我们成这种调用方式为同步调用 ,也可以叫同步通讯 。但在很多场景下,我们可能需要采用异步通讯的方式,为什么呢?
我们先来看看什么是同步通讯和异步通讯。如图
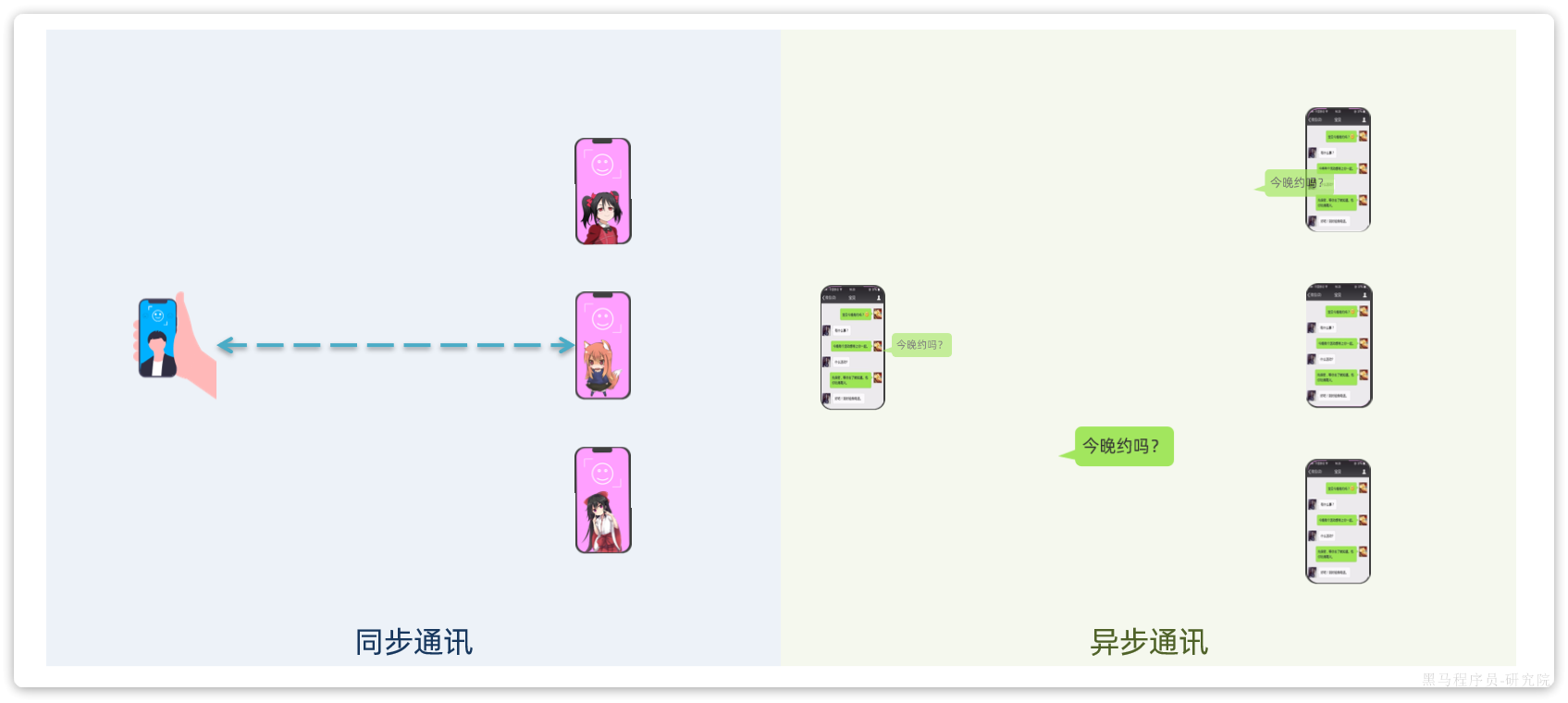
【解读】
- 同步通讯:就如同打视频电话,双方的交互都是实时的。因此同一时刻你只能跟一个人打视频电话。
- 异步通讯:就如同发微信聊天,双方的交互不是实时的,你不需要立刻给对方回应。因此你可以多线操作,同时跟多人聊天。
两种方式各有优劣,打电话可以立即得到响应,但是你却不能跟多个人同时通话。发微信可以同时与多个人收发微信,但是往往对方回复不及时导致响应延迟。
所以
- 如果我们的业务需要实时得到服务提供方的响应,则应该选择同步通讯(同步调用)
- 如果我们追求更高的效率,并且不需要实时响应,则应该选择异步通讯(异步调用)
同步调用的方式例如基于 OpenFeign 调用。异步调用的方式例如基于 MQ 消息通知的调用方式
1.1 同步调用
1.1.1 同步调用的优势
- 时效性强
等待到结果才返回
瑞:在需要等待结果的业务场景下,就很需要同步调用。比如查询商品信息,需要同步调用商品查询服务,查到了商品信息后才能进行接下来的业务操作,诸如此类的查询业务基本上都采用同步调用
1.1.2 同步调用的缺点
瑞:同步调用虽然有问题,但仍具有大量的业务场景,在实际开发中也是经常使用的
-
拓展性差
一旦有功能变更,需要修改业务代码
-
性能下降
调用链路越长,那同步阻塞等待就会导致性能变差,微服务调用越多,性能越差
-
级联失败问题
一个服务挂了,这个链路上的服务全部会出现问题
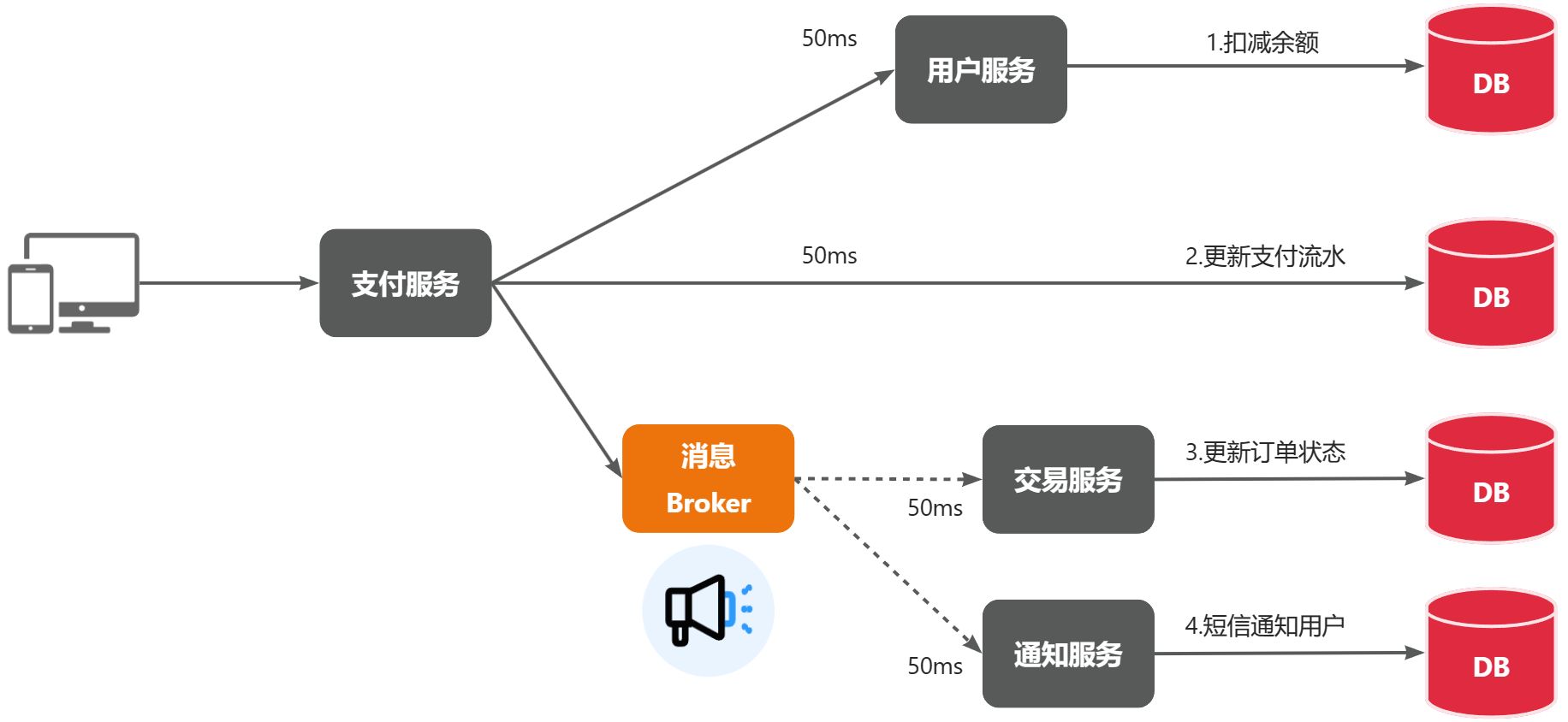
基于 OpenFeign 的调用属于是同步调用,这种方式存在的问题如【余额支付功能】
首先看下整个流程,如下图所示⬇️
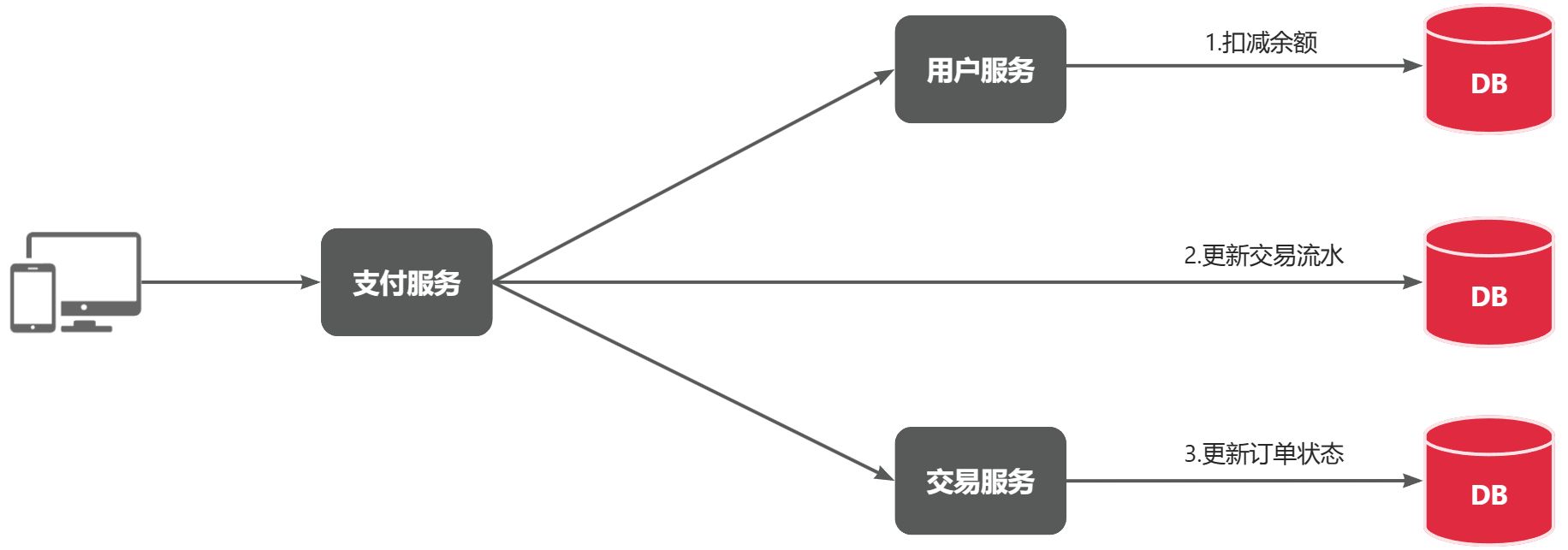
以上流程采用的是基于 OpenFeign 的同步调用,业务执行流程如下⬇️
1️⃣ 支付服务需要先调用用户服务完成余额扣减
2️⃣ 然后支付服务自己要更新支付流水单的状态
3️⃣ 然后支付服务调用交易服务,更新业务订单状态为已支付
三个步骤依次同步执行,这样就存在3个问题
第一 ,拓展性差
目前上述的业务相对简单,但是随着业务规模扩大,产品的功能也在不断完善。在大多数电商业务中,用户支付成功后都会以短信或者其它方式通知用户,告知支付成功。假如后期产品经理提出这样新的需求,你怎么办?是不是要在上述业务中再加入通知用户的业务?
某些电商项目中,还会有积分或金币的概念。假如产品经理提出需求,用户支付成功后,给用户以积分奖励或者返还金币,你怎么办?是不是要在上述业务中再加入积分业务、返还金币业务?
最终你的支付业务会越来越臃肿,如下⬇️
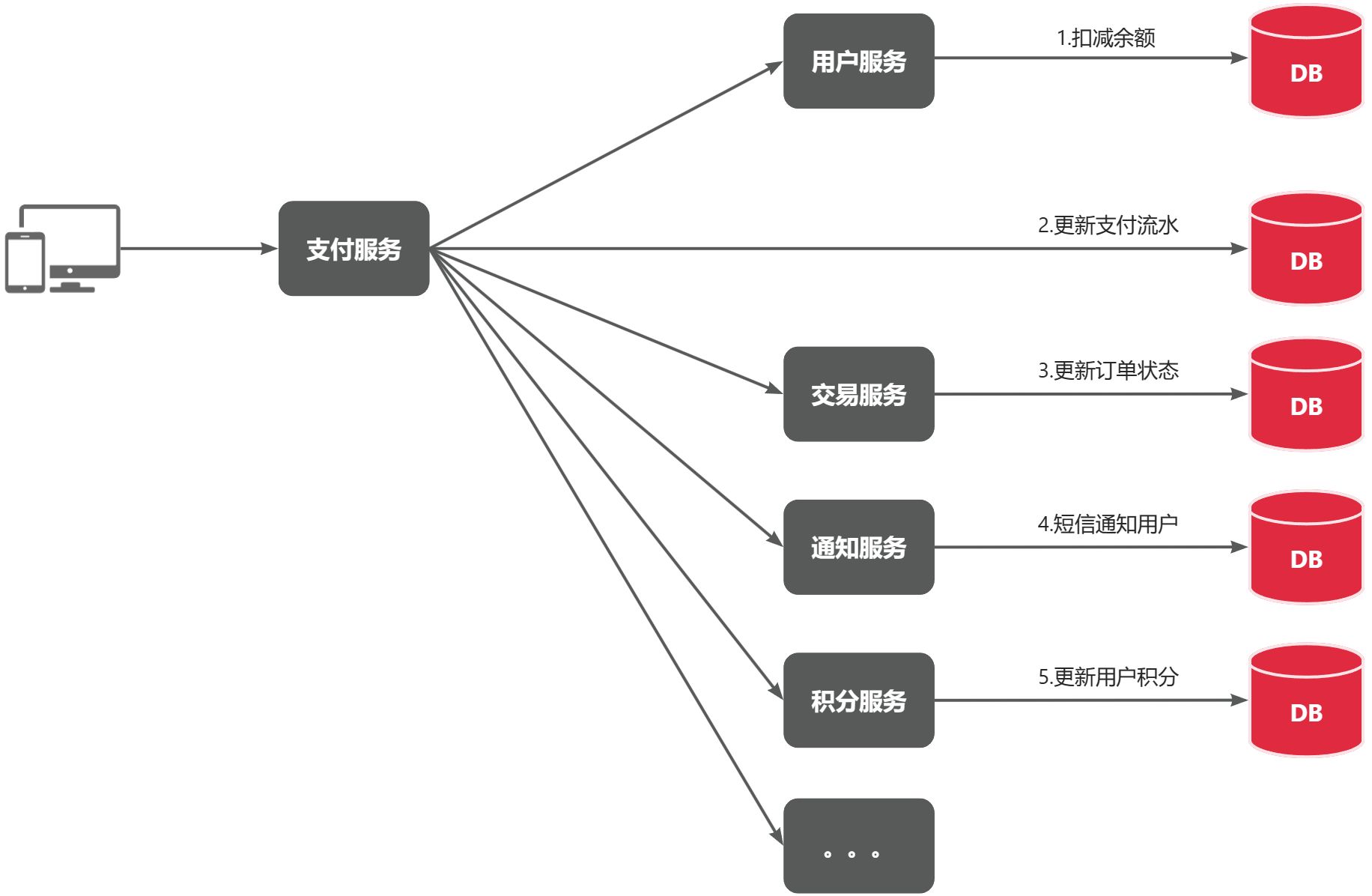
每当有新需求时,现有支付逻辑都要跟着变化,代码需要改动,不符合开闭原则(对扩展开放,对修改关闭),拓展性不好。
瑞:关于设计模式的 6 大法则,可以参考《瑞_23种设计模式_概述(含代码)》
第二 ,性能下降
由于我们采用了同步调用,调用者需要等待服务提供者执行完返回结果后,才能继续向下执行,也就是说每次远程调用,调用者都是阻塞等待状态。最终整个业务的响应时长就是每次远程调用的执行时长之和
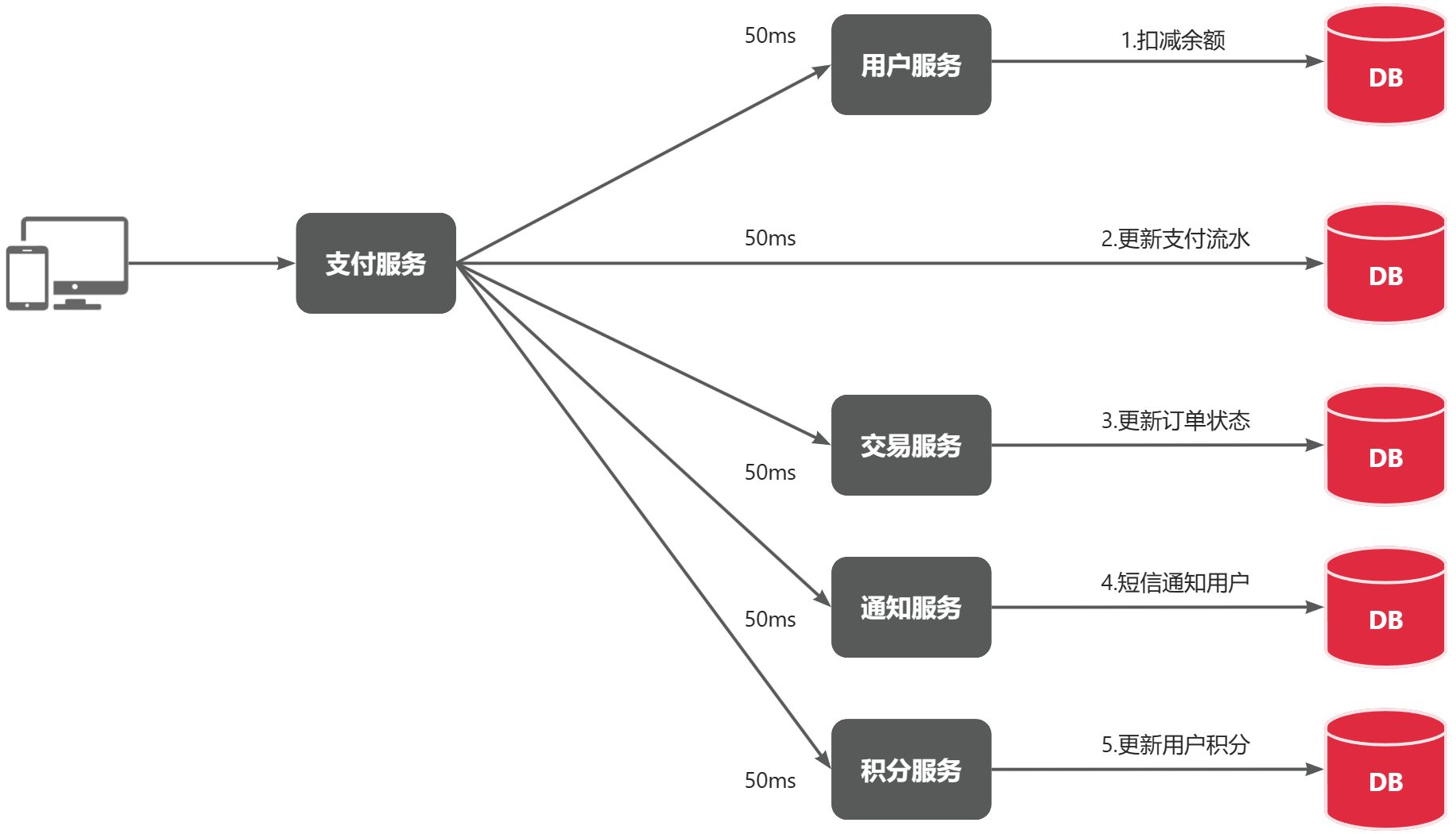
假如每个微服务的执行时长都是 50ms,则最终整个业务的耗时可能高达 300ms,性能太差了。
第三,级联失败
由于我们是基于 OpenFeign 调用交易服务、通知服务。当交易服务、通知服务出现故障时,整个事务都会回滚,交易失败。这其实就是同步调用的级联失败问题。
思考一下,我们假设用户余额充足,扣款已经成功,此时我们应该确保支付流水单更新为已支付,确保交易成功。毕竟收到手里的钱没道理再退回去吧
总不能因为短信通知、更新订单状态失败、积分增长失败等后续的业务逻辑执行失败而回滚整个事务
综上,同步调用的方式存在下列问题
- 拓展性差
- 性能下降
- 级联失败
而要解决这些问题,我们就必须用异步调用 的方式来代替同步调用
1.2 异步调用
1.2.1 异步调用的角色
异步调用方式其实就是基于消息通知的方式,一般包含以下三个角色
1️⃣ 消息发送者:投递消息的人,就是原来同步服务的调用方(生产者)
2️⃣ 消息 Broker:管理、暂存、转发消息,你可以把它理解成微信服务器(消息代理)
3️⃣ 消息接收者:接收和处理消息的人,就是原来的同步服务的提供方(消费者)
消息 Broker,目前常见的实现方案就是消息队列(MessageQueue),简称为MQ.
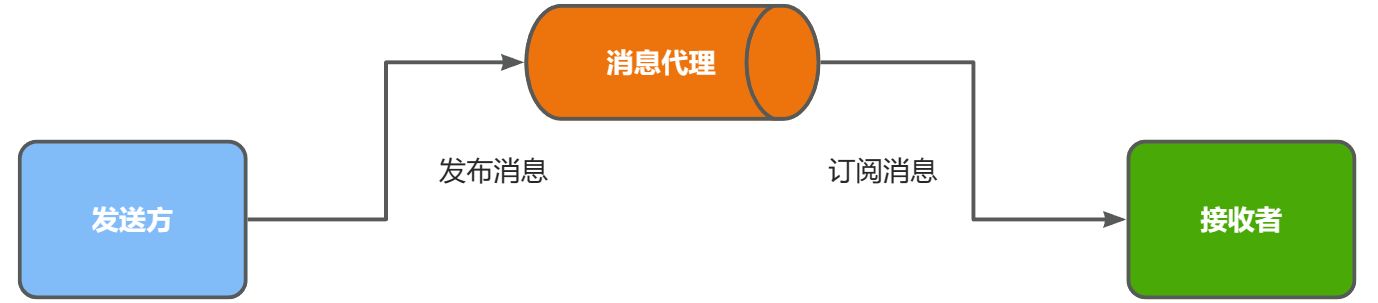
在异步调用中,发送者不再直接同步调用接收者的业务接口,而是发送一条消息投递给消息 Broker。然后接收者根据自己的需求从消息 Broker 那里订阅消息。每当发送方发送消息后,接受者都能获取消息并处理。
这样,发送消息的人和接收消息的人就完全解耦了
还是以余额支付业务为例,除了扣减余额、更新支付流水单状态以外,其它同步调用逻辑全部取消。而是改为发送一条消息到 Broker。而相关的微服务都可以订阅消息通知,一旦消息到达 Broker,则会分发给每一个订阅了的微服务,处理各自的业务。
假如产品经理冒出了新的想法,给你提出了新的需求,比如要添加积分系统,即要在支付成功后更新用户积分。此时支付代码完全不用变更,而仅仅是让积分服务也订阅消息即可,如下⬇️
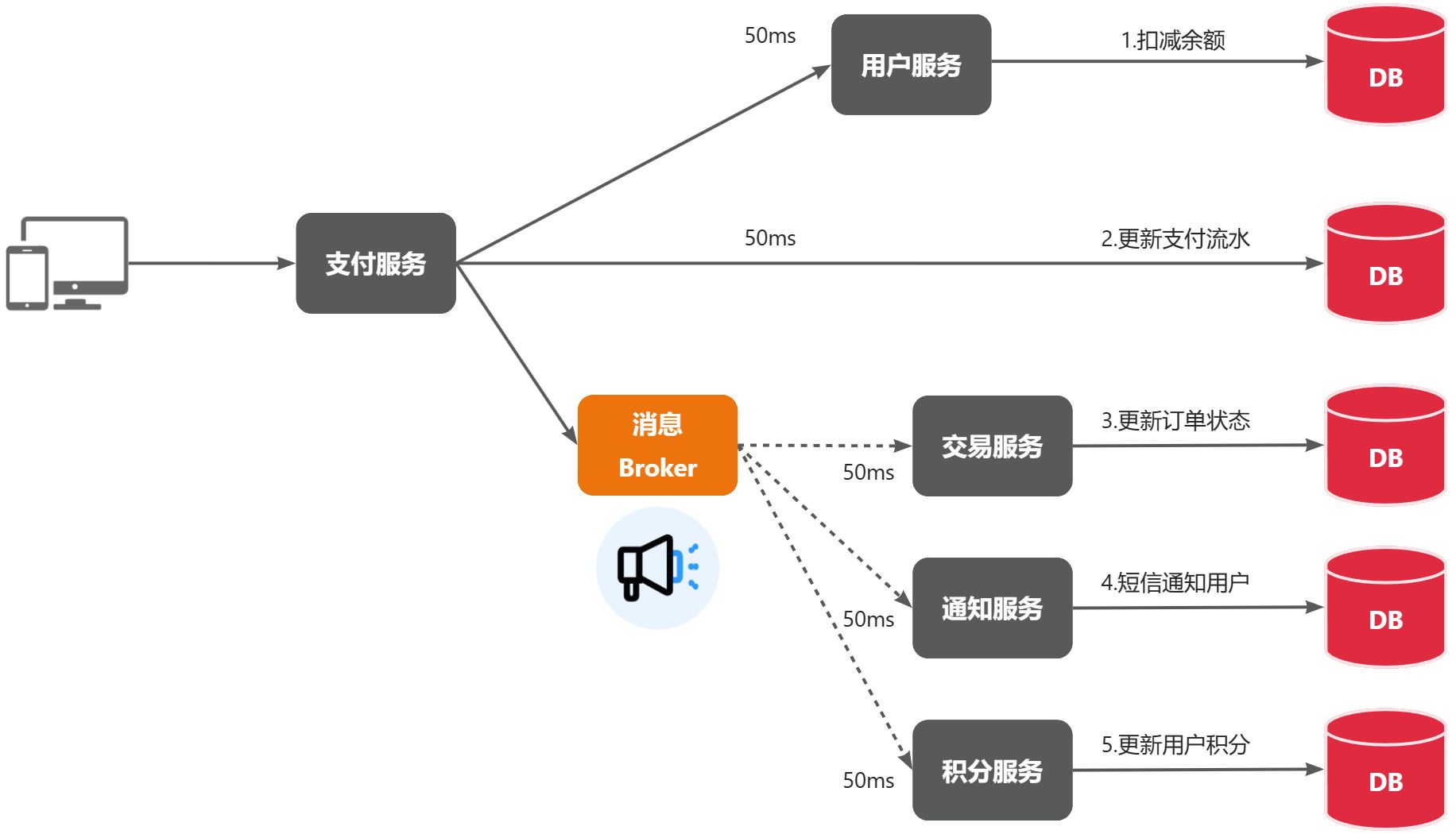
不管后期增加了多少消息订阅者,作为支付服务来讲,执行问扣减余额、更新支付流水状态后,发送消息即可。业务耗时仅仅是这三部分业务耗时,仅仅 100ms,大大提高了业务性能。
另外,不管是交易服务、通知服务,还是积分服务,他们的业务与支付关联度低。现在采用了异步调用,解除了耦合,他们即便执行过程中出现了故障,也不会影响到支付服务,只要保证最终一致性就行。
1.2.2 异步调用的优势
综上,异步调用的优势如下
-
解除耦合,拓展性强
只需要发消息到 Broker,后续如果要添加业务,其它业务只需要自行订阅相关消息即可
-
无需等待,性能好
发完消息,直接服务结束,无需等待异步调用服务的执行时间
-
故障隔离,避免级联失败
异步调用服务失败抛异常不影响消息发送者
-
缓存消息,流量削峰填谷
流量削峰填谷是在高并发场景下平滑系统负载,避免因瞬间高流量导致系统崩溃的技术策略。这种策略广泛应用于电商秒杀、大规模促销活动等场景,能够有效平衡上下游系统的负载差异,提高系统的稳定性和可靠性。

1.2.3 异步调用的缺点
当然,异步通信也并非完美无缺,存在下列缺点⬇️
- 不能立即得到调用结果,时效性差
- 不确定下游业务执行是否成功
- 业务完全依赖于 Broker 的可靠性、安全性和性能
- 架构复杂,后期维护和调试麻烦
1.2.4 异步调用的场景
- 对异步调用的结果不关心,如发送通知、记录日志、执行后台任务等操作。
- 调用链非常长的业务中,一般会改造成异步调用的方式
瑞:对结果不关心指的是:无论异步调用的结果成功或者失败,对当前业务都没有特别大的影响。比如余额支付业务中,订单的状态更新即使失败了,但根据业务逻辑,一般会继续尝试更新,不管是最后人工解决还是怎么慢慢处理,最后总会更新成功,关键点是在于之前的同步调用中用户的钱已经支付成功。但是像查询类型的业务,必须要立马得到结果,这种场景就不能使用异步调用。
1.3 MQ技术选型
MQ(MessageQueue),中文是消息队列,如同字面上的意思就是存放消息的队列。也就是异步调用中的 Broker 角色,目比较常见的 MQ 实现如下
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
以上 MQ 的对比
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高(主从架构) | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构) |
| 单机吞吐量 | 一般(万级) | 差 (万级) | 高 (十万级) | 非常高(百万级) |
| 消息延迟 | 微秒级(us级) | 毫秒级(ms级) | 毫秒级(ms级) | 毫秒以内(ms级以内) |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
| 功能特性 | 基于Erlang开发,所以并发能力很强,性能极其好,延时很低;管理界面较丰富 | 成熟的产品,在很多公司得到应用,有较多的文档;各种协议支持较好 | MQ功能比较完备,扩展性佳 | 只支持主要的MQ功能,像一些消息查询、消息回溯等功能没有提供,是为大数据准备的,在大数据领域应用广 |
- 追求可用性:Kafka、 RocketMQ 、RabbitMQ
- 追求可靠性:RabbitMQ、RocketMQ
- 追求吞吐能力:RocketMQ、Kafka
- 追求消息低延迟:RabbitMQ、Kafka
RabbitMQ 是基于 Erlang 语言开发的开源消息通信中间件,性能好,Erlang 语言是面向并发的语言;协议支持丰富,符合微服务理念,Spring 官方默认支持 RabbitMQ ;支持集群,可用性高;单机吞吐量(并发能力)十万二十万左右的样子,但已经满足大多数企业级应用需求;消息延迟在毫秒级;需要消息确认,消息可靠性高。
Kafka 适用于吞吐量需求很高的场景中,如日志搜集,但由于其消息不可靠,可能存在数据丢失的情况。
据统计,大厂基本上是使用自研,而中小型企业消息队列使用最多的是 RabbitMQ,因为其各方面都比较均衡,稳定性也好。至于 RocketMQ 由于是阿里的产品,而阿里每年向外输出大量的人才,这些人才流入到中小型企业中,会优先选择去使用 RocketMQ ,但具数据统计 RabbitMQ 在国内还是更受欢迎。
瑞:除了 RabbitMQ 以外,其它的 MQ 都是大厂开发的。大厂有大厂的问题,小厂有小厂的好处。Rabbit 公司主营核心业务之一就是 RabbitMQ ,有团队专门维护,社区也活跃。而其它大厂开发的业务多,如阿里,在阿里待过的同学就知道,阿里中的开源往往是奔 KPI 去的,想要升职加薪得有业绩,得有开源贡献,完成业绩指标之后,后续的升级、维护工作可能就没有那么到位,就会导致 bug 比较多,常见的如 FastJson
2 RabbitMQ
RabbitMQ的官网地址:Messaging that just works --- RabbitMQ
2.1 安装
本文是基于 Docker 来安装 RabbitMQ
瑞:Docker 的安装和使用可以参考《瑞_Docker(笔记超详细,有这一篇就够了)》
瑞:博主使用的SSH客户端远程连接工具是 MobaXterm,有需要的小伙伴可以参考《瑞_Java所有相关环境及软件的安装和卸载》
2.1.1 资源准备
如果是内网中开发或拉取镜像困难,请准备好以下资源,如果您的设备可以连接互联网,则可以直接开始安装
瑞:下面是博主提供
rabbitmq:3.8-management的 Docker 镜像文件压缩包mq.tar的某度网盘链接,有需要的伙伴请自提
bash
链接:https://pan.baidu.com/s/1tBRud60ExkPXcOBsr7R_rA?pwd=sm4u
提取码:sm4u 将mq.tar上传至root目录下,执行以下命令加载镜像
bash
cd /root
docker load -i mq.tar
2.1.2 安装步骤
执行以下命令进行安装
shell
docker run \
-e RABBITMQ_DEFAULT_USER=ray \
-e RABBITMQ_DEFAULT_PASS=123456 \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
-d \
rabbitmq:3.8-management【命令解读】
-
-e RABBITMQ_DEFAULT_USER=ray设置 RabbitMQ 用户名为:ray
-
-e RABBITMQ_DEFAULT_PASS=123456设置 RabbitMQ 密码为:123456
-
-v mq-plugins:/plugins挂载数据卷 mq-plugins 对应容器内目录 plugins
-
--name mq容器名为:mq
-
--hostname mq主机名为:mq
-
-p 15672:15672端口映射,表示将本机的 15672 端口映射到 RabbitMQ 镜像的 15672 端口
-
-p 5672:5672端口映射,表示将本机的 5672 端口映射到 RabbitMQ 镜像的 5672 端口
-
docker run -d创建并运行一个容器,
-d则是让容器以后台进程运行
在安装命令中有两个映射的端口
- 15672:RabbitMQ 提供的管理控制台的端口
- 5672:RabbitMQ 的消息发送处理接口

如上图所示,安装完成后,访问 http://192.168.133.131:15672即可看到管理控制台(记得 IP 要替换为你虚拟机的 IP)
瑞:如果页面无法访问,有可能是因为你的服务器或者虚拟机的对应端口没有开放,请参考《瑞_Linux防火墙相关命令_Windows远程连接虚拟机的服务失败_Linux防火墙端口开放》将 15672 以及 5672 端口开放
首次访问需要登录,默认的用户名和密码在 docker run 中指定了,博主的用户名为:ray,密码为:123456
登录成功后即可看到管理控制台总览页面

RabbitMQ 安装完成
2.2 RabbitMQ架构
RabbitMQ 对应的架构如下图所示
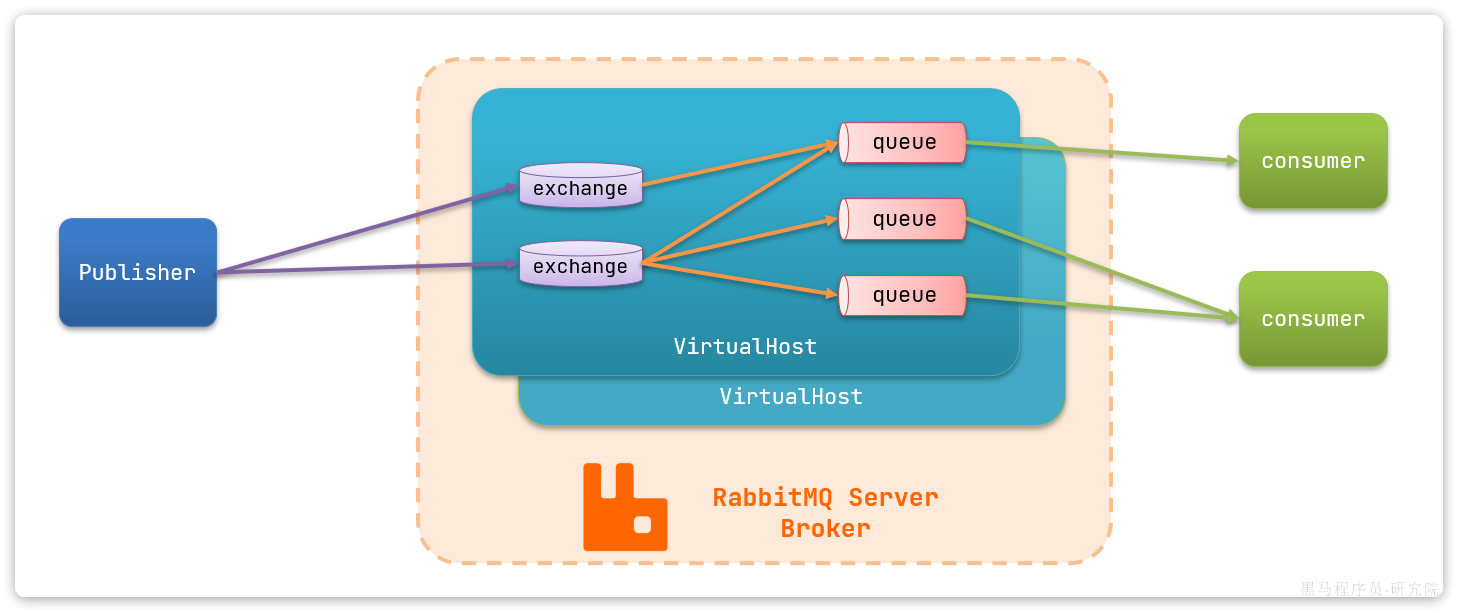
其中包含几个概念:
publisher:生产者,也就是发送消息的一方consumer:消费者,也就是消费消息的一方queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
上述这些东西都可以在 RabbitMQ 的管理控制台来管理。
瑞:交换机不能存储消息,只能路由和转发消息
2.3 RabbitMQ管理控制台收发消息
访问
http://192.168.133.131:15672到 RabbitMQ 管理控制台(记得替换 IP)
RabbitMQ 的管理控制台入门小案例------收发消息
【需求】在 RabbitMQ 的控制台完成下列操作
2.3.1 创建队列
- 新建队列 hello.queue1 和 hello.queue2
1️⃣ 点击导航栏中的Queues,选择Add a new queue,在Name中输入 hello.queue1,点击Add queue即可添加队列,hello.queue2 同理添加

2️⃣ 添加成功后如下图

2.3.2 交换机绑定队列★
- 将刚刚创建的 hello.queue1 和 hello.queue2 队列绑定到默认的 amp.fanout 交换机
1️⃣ 点击Exchanges,鼠标单击选中amp.fanout交换机

2️⃣ 点击Bindings,在To queue中输入或选择 hello.queue1 ,点击Bind进行绑定,hello.queue2 同理绑定

3️⃣ 绑定完成后如下图所示

4️⃣ 到Queues中查看Bindings中是否绑定了交换机amp.fanout

2.3.3 交换机发送消息
- 向默认的 amp.fanout 交换机发送一条消息
1️⃣ 点击Exchanges,鼠标单击选中amp.fanout交换机进入交换机详情页面,然后点击Publish message,在Payload中输入要发送的消息,如"hello every queue!",然后点击Publish message,会有提示框提示"Message published",点击Close即可

2️⃣ 在Overview中查看消息发送情况,如下图所示

2.3.4 查看消息接收
- 查看消息是否到达 hello.queue1 和 hello.queue2
1️⃣ 点击导航栏中的Queues,查看队列消息接收情况,如下图所示

2️⃣ 选中 hellp.queue1 ,进入队列管理界面,展开Get messages,点击Get Message(s)按钮,查看交换机发送的消息内容

此时如果有消费者监听了 MQ 的
hello.queue1或hello.queue2队列,就能接收到消息了
2.4 数据隔离
在 RabbitMQ 中存在 virtual host 即虚拟主机的概念,交换机和队列都有自己所属的虚拟主机,以此实现数据隔离的效果。
2.4.1 用户管理
点击Admin选项卡,会看到 RabbitMQ 控制台的用户管理界面 Users

这些用户都是 RabbitMQ 的管理或运维人员。目前只有安装 RabbitMQ 时添加的ray这个用户。用户表格中的字段,如下:
Name:ray,也就是用户名Tags:administrator,说明ray用户是超级管理员,拥有所有权限Can access virtual host:/,可以访问的virtual host,这里的/是默认的virtual host
对于小型企业而言,出于成本考虑,通常只会搭建一套 MQ 集群,公司内的多个不同项目同时使用。这个时候为了避免互相干扰, 会利用virtual host的隔离特性,将不同项目隔离。一般会做两件事情:
- 给每个项目创建独立的运维账号,将管理权限分离。
- 给每个项目创建不同的
virtual host,将每个项目的数据隔离。
比如给黑马商城项目创建一个新的用户,名为hmall,密码为123456,标签选择admin即administrator超级管理员权限

此时会发现 hmall 用户没有任何virtual host的访问权限

别急,接下来我们就来为 hmall 进行授权操作
2.4.2 virtual host 用户授权
1️⃣ 先点击页面右上角的Log out退出登录

2️⃣ 切换到刚刚创建的 hmall 用户登录,在Admin标签页中点击Virtual Hosts菜单,进入virtual host管理页

可以看到目前只有一个默认的virtual host,名字为 /
3️⃣ 给黑马商城项目创建一个单独的virtual host,而不是使用默认的/,展开Add a new virtual host

4️⃣ 创建完成后如下图所示

由于我们是登录hmall账户后创建的virtual host,因此回到users菜单,你会发现当前用户已经具备了对/hmall这个virtual host的访问权限了

5️⃣ 点击页面右上角的virtual host下拉菜单,切换virtual host为 /hmall


6️⃣ 切换virtual host为 /hmall后,查看Queues选项卡,会发现之前的队列已经看不到了

这就是基于virtual host 的隔离效果
瑞:可以理解为 MySQL 中的 database 数据库就是虚拟机,默认有
/数据库,它的数据表和新建的hmall数据库中的数据表即使命名相同,但会处于互相隔离互不影响的状态,我们能看到其它数据库(虚拟机)是因为无论是 hmall 用户还是 ray 用户,都具有超级管理员权限,但并不能操作对方的虚拟机,只能操作本用户下的虚拟机中的交换机和队列,以此做到数据隔离的效果。所以一般每一个项目会创建一个用户,创建一个专属的虚拟机。
本文是博主的粗浅理解,可能存在一些错误或不完善之处,如有遗漏或错误欢迎各位补充,谢谢
如果觉得这篇文章对您有所帮助的话,请动动小手点波关注💗,你的点赞👍收藏⭐️转发🔗评论📝都是对博主最好的支持~