问题描述
在 spark 上跑 python 任务最常见的异常就是下面的版本不一致问题了:
`RuntimeError: Python in worker has different version 3.7 than that in driver 3.6, PySpark cannot run with different minor versions. Please check environment variables PYSPARK PYTHON...`这个异常的原因是 worker 或叫 executor 中使用 python 版本与 driver 上的 python 版本不一致造成的。
这里面要明确一个概念,worker 上的版本也就是官网 pyspark 使用的 python 版本,这个是固定的,可以在 spark 中的官网查询到,比如在 spark 3.3.4 版本中:
Installation --- PySpark 3.3.4 documentation
可以看到官网描述的支持的 Python 版本是不能低于 Python 3.7 的:
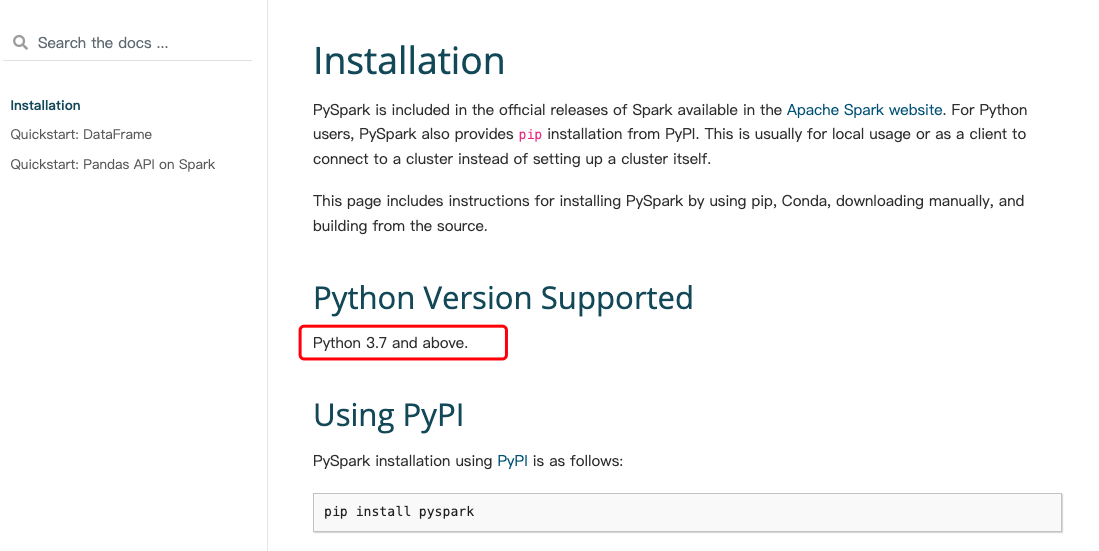
这也就是说,如果你要跑 python 任务,你的 driver 和 worker 侧的 python 版本不能低于 3.7 版本,最小是 3.7,否则就会出现上面描述的异常。
解决方案
那就很简单了,只需要保证 driver 和 worker 上的 python 版本符合 pyspark 的要求即可,如果本地有多个 python 版本,我们只需要通过环境变量指定正确的 python 版本即可:
1,如果是 python 代码,可以直接在代码中指定:
# 系统环境变量配置 PYSPARK_PYTHON 和 PYSPARK_DRIVER_PYTHON
import os
os.environ['PYSPARK_PYTHON'] = "/Users/spark/conda/miniconda3/envs/py37/bin/python"
os.environ['PYSPARK_DRIVER_PYTHON'] = "/Users/spark/conda/miniconda3/envs/py37/bin/python"2,如果不是 python 代码,则可以在环境变量中指定:
export PYSPARK_PYTHON=/Users/spark/conda/miniconda3/envs/py37/bin/python
export PYSPARK_DRIVER_PYTHON=/Users/spark/conda/miniconda3/envs/py37/bin/python其他注意事项
如果是使用 mlflow 包管理的任务,除了 driver 和 executor 上 python 版本保持一致,训练模型用的 python 版本也尽量匹配 pyspark 的版本要求,否则可能出现兼容性问题