
🔥个人主页: 寻星探路
🎬作者简介:Java研发方向学习者
📖个人专栏: JAVA(SE)----如此简单从青铜到王者,就差这讲数据结构!!数据库那些事!!JavaEE 初阶启程记:跟我走不踩坑测试开发漫谈********
⭐️人生格言:没有人生来就会编程,但我生来倔强!!!

目录
[1、String 和StringBuilder、StringBuffer 的区别?](#1、String 和StringBuilder、StringBuffer 的区别?)
[2、String 是不可变类吗?](#2、String 是不可变类吗?)
[3、BIO、NIO、AIO 之间的区别?](#3、BIO、NIO、AIO 之间的区别?)
一、面向对象
1、深拷贝和其那拷贝的区别
在 Java 中,深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是两种拷贝对象的方式,它们在拷贝对象的方式上有很大不同。

浅拷贝会创建一个新对象,但这个新对象的属性(字段)和原对象的属性完全相同。如果属性是基本数据类型,拷贝的是基本数据类型的值;如果属性是引用类型,拷贝的是引用地址,因此新旧对象共享同一个引用对象。
浅拷贝的实现方式为:实现 Cloneable 接口并重写 clone() 方法。
java
class Person implements Cloneable {
String name;
int age;
Address address;
public Person(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
class Address {
String city;
public Address(String city) {
this.city = city;
}
}
public class Main {
public static void main(String[] args) throws CloneNotSupportedException {
Address address = new Address("张家口");
Person person1 = new Person("寻星探路", 18, address);
Person person2 = (Person) person1.clone();
System.out.println(person1.address == person2.address); // true
}
}深拷贝也会创建一个新对象,但会递归地复制所有的引用对象,确保新对象和原对象完全独立。新对象与原对象的任何更改都不会相互影响。
深拷贝的实现方式有:手动复制所有的引用对象,或者使用序列化与反序列化。
①、手动拷贝
java
class Person {
String name;
int age;
Address address;
public Person(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
public Person(Person person) {
this.name = person.name;
this.age = person.age;
this.address = new Address(person.address.city);
}
}
class Address {
String city;
public Address(String city) {
this.city = city;
}
}
public class Main {
public static void main(String[] args) {
Address address = new Address("张家口");
Person person1 = new Person("寻星探路", 18, address);
Person person2 = new Person(person1);
System.out.println(person1.address == person2.address); // false
}
}②、序列化与反序列化
java
import java.io.*;
class Person implements Serializable {
String name;
int age;
Address address;
public Person(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
public Person deepClone() throws IOException, ClassNotFoundException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Person) ois.readObject();
}
}
class Address implements Serializable {
String city;
public Address(String city) {
this.city = city;
}
}
public class Main {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Address address = new Address("张家口");
Person person1 = new Person("寻星探路", 18, address);
Person person2 = person1.deepClone();
System.out.println(person1.address == person2.address); // false
}
}2、Java创建对象有哪几种方式?

Java 有四种创建对象的方式:
①、new 关键字创建,这是最常见和直接的方式,通过调用类的构造方法来创建对象。
java
Person person = new Person();②、反射机制创建,反射机制允许在运行时创建对象,并且可以访问类的私有成员,在框架和工具类中比较常见。
java
Class clazz = Class.forName("Person");
Person person = (Person) clazz.newInstance();③、clone 拷贝创建,通过 clone 方法创建对象,需要实现 Cloneable 接口并重写 clone 方法。
java
Person person = new Person();
Person person2 = (Person) person.clone();④、序列化机制创建,通过序列化将对象转换为字节流,再通过反序列化从字节流中恢复对象。需要实现 Serializable 接口。
java
Person person = new Person();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.txt"));
oos.writeObject(person);
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.txt"));
Person person2 = (Person) ois.readObject();二、String
1、String 和StringBuilder、StringBuffer 的区别?
String 和StringBuilder、StringBuffer在 Java 中都是用于处理字符串的,它们之间的区别是,String 是不可变的,平常开发用得最多,当遇到大量字符串连接时,就用 StringBuilder,它不会生成很多新的对象,StringBuffer 和 StringBuilder 类似,但每个方法上都加了 synchronized 关键字,所以是线程安全的。
String的特点
String类的对象是不可变的。也就是说,一旦一个String对象被创建,它所包含的字符串内容是不可改变的。- 每次对
String对象进行修改操作(如拼接、替换等)实际上都会生成一个新的String对象,而不是修改原有对象。这可能会导致内存和性能开销,尤其是在大量字符串操作的情况下。
StringBuilder的特点
StringBuilder提供了一系列的方法来进行字符串的增删改查操作,这些操作都是直接在原有字符串对象的底层数组上进行的,而不是生成新的 String 对象。StringBuilder不是线程安全的。这意味着在没有外部同步的情况下,它不适用于多线程环境。- 相比于
String,在进行频繁的字符串修改操作时,StringBuilder能提供更好的性能。 Java 中的字符串连+操作其实就是通过StringBuilder实现的。
StringBuffer的特点
StringBuffer和StringBuilder类似,但StringBuffer是线程安全的,方法前面都加了synchronized关键字。
使用场景
- String:适用于字符串内容不会改变的场景,比如说作为 HashMap 的 key。
- StringBuilder:适用于单线程环境下需要频繁修改字符串内容的场景,比如在循环中拼接或修改字符串,是 String 的完美替代品。
- StringBuffer:现在已经不怎么用了,因为一般不会在多线程场景下去频繁的修改字符串内容
2、String 是不可变类吗?
String 是不可变的,这意味着一旦一个 String 对象被创建,其存储的文本内容就不能被改变。这是因为:
①、不可变性使得 String 对象在使用中更加安全。因为字符串经常用作参数传递给其他 Java 方法,例如网络连接、打开文件等。
如果 String 是可变的,这些方法调用的参数值就可能在不知不觉中被改变,从而导致网络连接被篡改、文件被莫名其妙地修改等问题。
②、不可变的对象因为状态不会改变,所以更容易进行缓存和重用。字符串常量池的出现正是基于这个原因。
当代码中出现相同的字符串字面量时,JVM 会确保所有的引用都指向常量池中的同一个对象,从而节约内存。
③、因为 String 的内容不会改变,所以它的哈希值也就固定不变。这使得 String 对象特别适合作为 HashMap 或 HashSet 等集合的键,因为计算哈希值只需要进行一次,提高了哈希表操作的效率。
如何保证String不可变?
第一,String 类内部使用一个私有的字符数组来存储字符串数据。这个字符数组在创建字符串时被初始化,之后不允许被改变。
java
private final char value[];第二,String 类没有提供任何可以修改其内容的公共方法,像 concat 这些看似修改字符串的操作,实际上都是返回一个新创建的字符串对象,而原始字符串对象保持不变。
java
public String concat(String str) {
if (str.isEmpty()) {
return this;
}
int len = value.length;
int otherLen = str.length();
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}第三,String 类本身被声明为 final,这意味着它不能被继承。这防止了子类可能通过添加修改方法来改变字符串内容的可能性。
java
public final class String三、异常处理
1、Java中的异常体系?
Java 中的异常处理机制用于处理程序运行过程中可能发生的各种异常情况,通常通过 try-catch-finally 语句和 throw 关键字来实现。
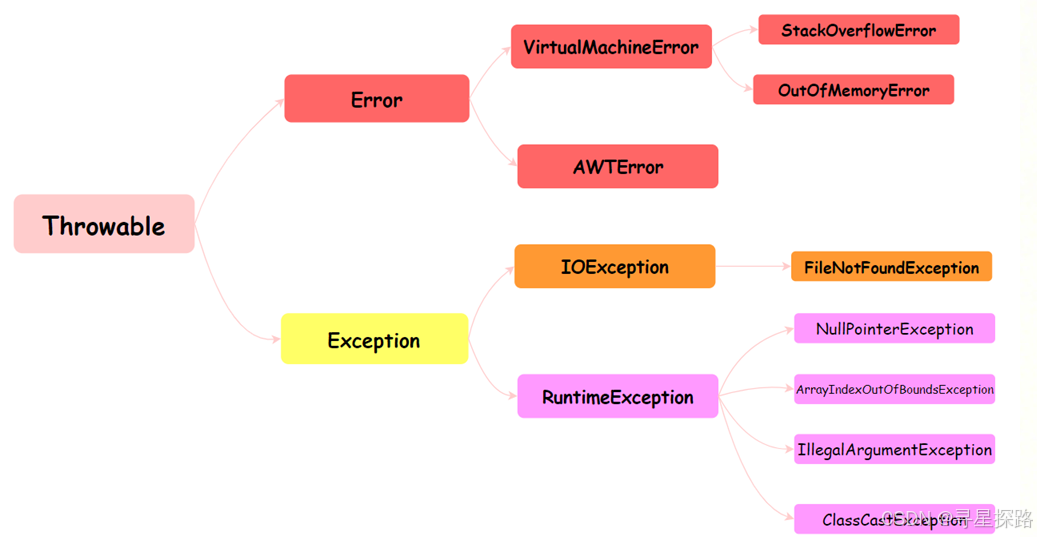
Throwable 是 Java 语言中所有错误和异常的基类。它有两个主要的子类:Error 和 Exception,这两个类分别代表了 Java 异常处理体系中的两个分支。
Error 类代表那些严重的错误,这类错误通常是程序无法处理的。比如,OutOfMemoryError 表示内存不足,StackOverflowError 表示栈溢出。这些错误通常与 JVM 的运行状态有关,一旦发生,应用程序通常无法恢复。
Exception 类代表程序可以处理的异常。它分为两大类:编译时异常(Checked Exception)和运行时异常(Runtime Exception)。
①、编译时异常(Checked Exception):这类异常在编译时必须被显式处理(捕获或声明抛出)。
如果方法可能抛出某种编译时异常,但没有捕获它(try-catch)或没有在方法声明中用 throws 子句声明它,那么编译将不会通过。例如:IOException、SQLException 等。
②、运行时异常(Runtime Exception):这类异常在运行时抛出,它们都是 RuntimeException 的子类。对于运行时异常,Java 编译器不要求必须处理它们(即不需要捕获也不需要声明抛出)。
运行时异常通常是由程序逻辑错误导致的,如 NullPointerException、IndexOutOfBoundsException 等。
2、异常的处理方式
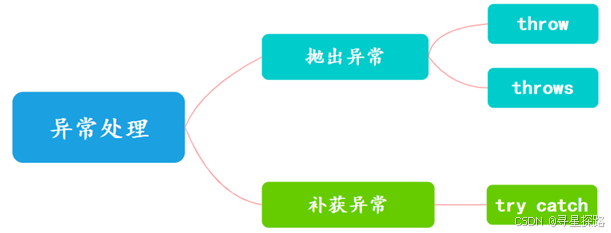
①、遇到异常时可以不处理,直接通过throw 和 throws 抛出异常,交给上层调用者处理。
throws 关键字用于声明可能会抛出的异常,而 throw 关键字用于抛出异常。
java
public void test() throws Exception {
throw new Exception("抛出异常");
}②、使用 try-catch 捕获异常,处理异常。
java
try {
//包含可能会出现异常的代码以及声明异常的方法
}catch(Exception e) {
//捕获异常并进行处理
}finally {
//可选,必执行的代码
}catch和finally的异常可以同时抛出吗?
如果 catch 块抛出一个异常,而 finally 块中也抛出异常,那么最终抛出的将是 finally 块中的异常。catch 块中的异常会被丢弃,而 finally 块中的异常会覆盖并向上传递。
java
public class Example {
public static void main(String[] args) {
try {
throw new Exception("Exception in try");
} catch (Exception e) {
throw new RuntimeException("Exception in catch");
} finally {
throw new IllegalArgumentException("Exception in finally");
}
}
}- try 块首先抛出一个 Exception。
- 控制流进入 catch 块,catch 块中又抛出了一个 RuntimeException。
- 但是在 finally 块中,抛出了一个 IllegalArgumentException,最终程序抛出的异常是 finally 块中的 IllegalArgumentException。
虽然 catch 和 finally 中的异常不能同时抛出,但可以手动捕获 finally 块中的异常,并将 catch 块中的异常保留下来,避免被覆盖。常见的做法是使用一个变量临时存储 catch 中的异常,然后在 finally 中处理该异常:
java
public class Example {
public static void main(String[] args) {
Exception catchException = null;
try {
throw new Exception("Exception in try");
} catch (Exception e) {
catchException = e;
throw new RuntimeException("Exception in catch");
} finally {
try {
throw new IllegalArgumentException("Exception in finally");
} catch (IllegalArgumentException e) {
if (catchException != null) {
System.out.println("Catch exception: " + catchException.getMessage());
}
System.out.println("Finally exception: " + e.getMessage());
}
}
}
}
四、I/O
1、Java中IO流分为几种?
Jaa IO 流的划分可以根据多个维度进行,包括数据流的方向(输入或输出)、处理的数据单位(字节或字符)、流的功能以及流是否支持随机访问等。
按照数据流方向进行划分?
- 输入流(Input Stream):从源(如文件、网络等)读取数据到程序。
- 输出流(Output Stream):将数据从程序写出到目的地(如文件、网络、控制台等)。
按处理数据单位如何划分?
- 字节流(Byte Streams):以字节为单位读写数据,主要用于处理二进制数据,如音频、图像文件等。
- 字符流(Character Streams):以字符为单位读写数据,主要用于处理文本数据。
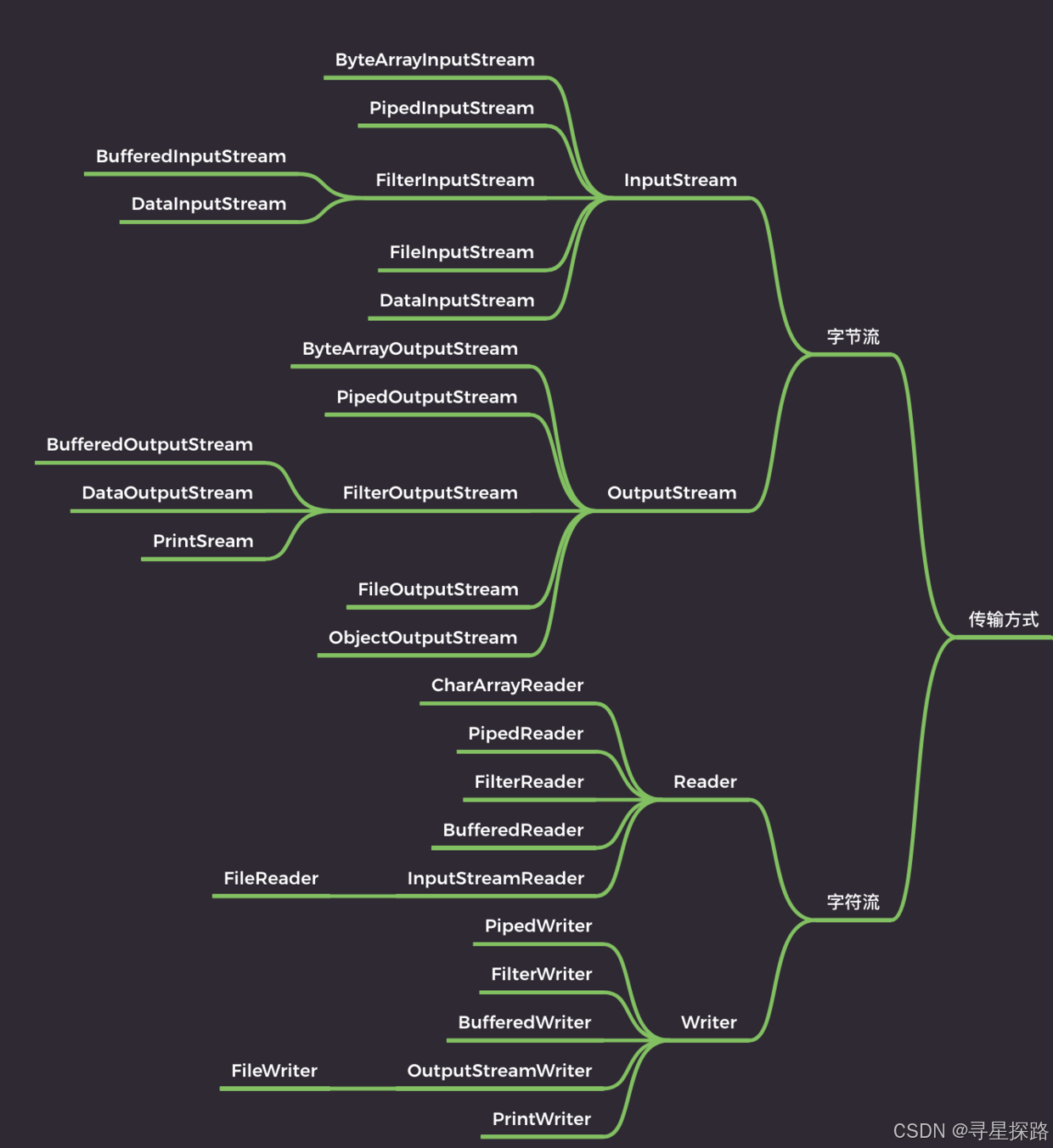
按功能如何划分?
- 节点流(Node Streams):直接与数据源或目的地相连,如 FileInputStream、FileOutputStream。
- 处理流(Processing Streams):对一个已存在的流进行包装,如缓冲流 BufferedInputStream、BufferedOutputStream。
- 管道流(Piped Streams):用于线程之间的数据传输,如 PipedInputStream、PipedOutputStream。
IO流用到了什么设计模式?
用到了------装饰器模式,装饰器模式的核心思想是在不改变原有对象结构的前提下,动态地给对象添加新的功能。
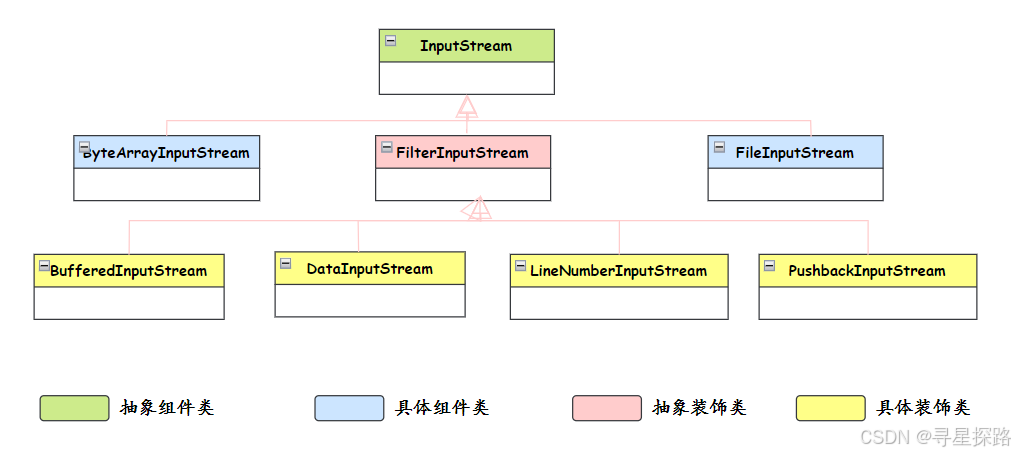
具体到 Java IO 中,InputStream 和 OutputStream 这些抽象类定义了基本的读写操作,然后通过各种装饰器类来增强功能。比如 BufferedInputStream 给基础的输入流增加了缓冲功能,DataInputStream 增加了读取基本数据类型的能力,它们都是对基础流的装饰和增强。
java
InputStream input = new BufferedInputStream(
new DataInputStream(
new FileInputStream("data.txt")
)
);这里 FileInputStream 提供基本的文件读取能力,DataInputStream 装饰它增加了数据类型转换功能,BufferedInputStream 再装饰它增加了缓冲功能。每一层装饰都在原有功能基础上增加新特性,而且可以灵活组合。
我对装饰器模式的理解是它很好地体现了"组合优于继承"的设计原则。优势在于运行时动态组合功能,而且遵循开闭原则,可以在不修改现有代码的情况下增加新功能。
Java 缓冲区溢出,如何预防?
Java 缓冲区溢出主要是由于向缓冲区写入的数据超过其能够存储的数据量。可以采用这些措施来避免:
①、合理设置缓冲区大小:在创建缓冲区时,应根据实际需求合理设置缓冲区的大小,避免创建过大或过小的缓冲区。
②、控制写入数据量 :在向缓冲区写入数据时,应该控制写入的数据量,确保不会超过缓冲区的容量。Java 的 ByteBuffer 类提供了remaining()方法,可以获取缓冲区中剩余的可写入数据量。
java
import java.nio.ByteBuffer;
public class ByteBufferExample {
public static void main(String[] args) {
// 模拟接收到的数据
byte[] receivedData = {1, 2, 3, 4, 5};
int bufferSize = 1024; // 设置一个合理的缓冲区大小
// 创建ByteBuffer
ByteBuffer buffer = ByteBuffer.allocate(bufferSize);
// 写入数据之前检查容量是否足够
if (buffer.remaining() >= receivedData.length) {
buffer.put(receivedData);
} else {
System.out.println("Not enough space in buffer to write data.");
}
// 准备读取数据:将limit设置为当前位置,position设回0
buffer.flip();
// 读取数据
while (buffer.hasRemaining()) {
byte data = buffer.get();
System.out.println("Read data: " + data);
}
// 清空缓冲区以便再次使用
buffer.clear();
}
}2、有了字节流为什么还要有字符流?
其实字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还比较耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。
所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
文本存储是字节流还是字符流,视频文件呢?
在计算机中,文本和视频都是按照字节存储的,只是如果是文本文件的话,我们可以通过字符流的形式去读取,这样更方面的我们进行直接处理。
比如说我们需要在一个大文本文件中查找某个字符串,可以直接通过字符流来读取判断。
处理视频文件时,通常使用字节流(如 Java 中的FileInputStream、FileOutputStream)来读取或写入数据,并且会尽量使用缓冲流(如BufferedInputStream、BufferedOutputStream)来提高读写效率。
3、BIO、NIO、AIO 之间的区别?

BIO:采用阻塞式 I/O 模型,线程在执行 I/O 操作时被阻塞,无法处理其他任务,适用于连接数较少的场景。
NIO:采用非阻塞 I/O 模型,线程在等待 I/O 时可执行其他任务,通过 Selector 监控多个 Channel 上的事件,适用于连接数多但连接时间短的场景。
AIO:使用异步 I/O 模型,线程发起 I/O 请求后立即返回,当 I/O 操作完成时通过回调函数通知线程,适用于连接数多且连接时间长的场景。
五、序列化
1、什么是序列化?什么是反序列化?
序列化(Serialization)是指将对象转换为字节流的过程,以便能够将该对象保存到文件、数据库,或者进行网络传输。
反序列化(Deserialization)就是将字节流转换回对象的过程,以便构建原始对象。
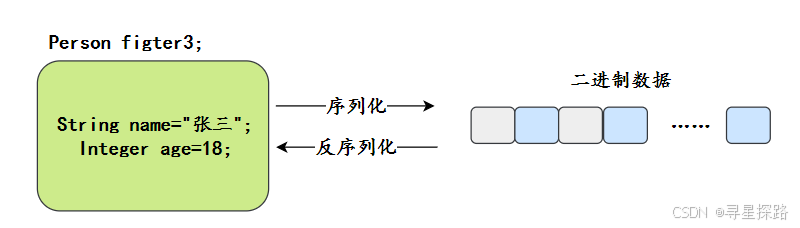
解释一下序列化的过程和作用
序列化过程通常涉及到以下几个步骤:
第一步,实现 Serializable 接口。
java
public class Person implements Serializable {
private String name;
private int age;
// 省略构造方法、getters和setters
}第二步,使用 ObjectOutputStream 来将对象写入到输出流中。
java
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.ser"));第三步,调用 ObjectOutputStream 的 writeObject 方法,将对象序列化并写入到输出流中。
java
Person person = new Person("寻星探路", 18);
out.writeObject(person);2、有几种序列化方式?
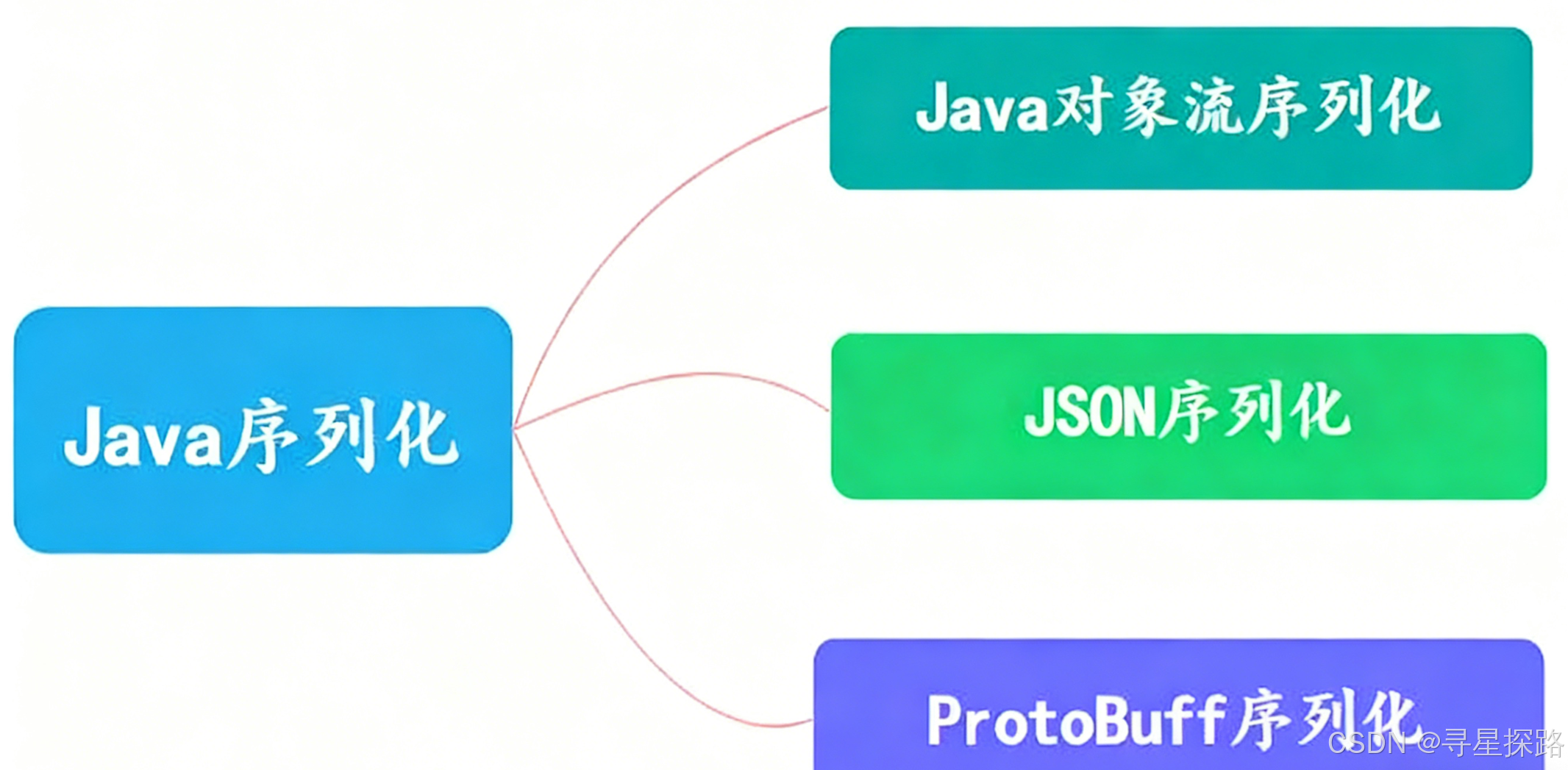
- Java 对象序列化 :Java 原生序列化方法即通过 Java 原生流(InputStream 和 OutputStream 之间的转化)的方式进行转化,一般是对象输出流
ObjectOutputStream和对象输入流ObjectInputStream。 - Json 序列化:这个可能是我们最常用的序列化方式,Json 序列化的选择很多,一般会使用 jackson 包,通过 ObjectMapper 类来进行一些操作,比如将对象转化为 byte 数组或者将 json 串转化为对象。
- ProtoBuff 序列化:ProtocolBuffer 是一种轻便高效的结构化数据存储格式,ProtoBuff 序列化对象可以很大程度上将其压缩,可以大大减少数据传输大小,提高系统性能。
六、网络编程
1、了解过Socket网络套接字吗?
Socket 是网络通信的基础,表示两台设备之间通信的一个端点。Socket 通常用于建立 TCP 或 UDP 连接,实现进程间的网络通信。

一个简单的 TCP 客户端:
java
class TcpClient {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 8080); // 连接服务器
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
out.println("Hello, Server!"); // 发送消息
System.out.println("Server response: " + in.readLine()); // 接收服务器响应
socket.close();
}
}TCP 服务端:
java
class TcpServer {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8080); // 创建服务器端Socket
System.out.println("Server started, waiting for connection...");
Socket socket = serverSocket.accept(); // 等待客户端连接
System.out.println("Client connected: " + socket.getInetAddress());
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
String message;
while ((message = in.readLine()) != null) {
System.out.println("Received: " + message);
out.println("Echo: " + message); // 回送消息
}
socket.close();
serverSocket.close();
}
}RPC框架了解吗?
RPC是一种协议,允许程序调用位于远程服务器上的方法,就像调用本地方法一样。RPC 通常基于 Socket 通信实现。
RPC,Remote Procedure Call,远程过程调用
RPC 框架支持高效的序列化(如 Protocol Buffers)和通信协议(如 HTTP/2),屏蔽了底层网络通信的细节,开发者只需关注业务逻辑即可。
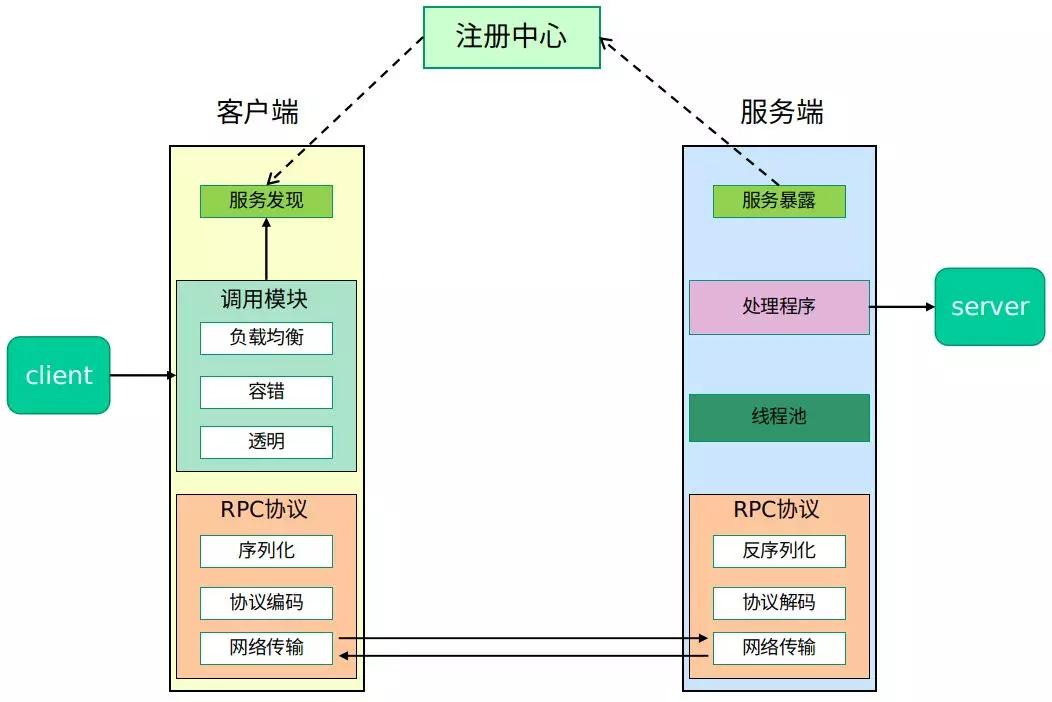
常见的 RPC 框架包括:
- gRPC:基于 HTTP/2 和 Protocol Buffers。
- Dubbo:阿里开源的分布式 RPC 框架,适合微服务场景。
- Spring Cloud OpenFeign:基于 REST 的轻量级 RPC 框架。
- Thrift:Apache 的跨语言 RPC 框架,支持多语言代码生成。
七、泛型
1、Java泛型了吗?
泛型主要用于提高代码的类型安全,它允许在定义类、接口和方法时使用类型参数,这样可以在编译时检查类型一致性,避免不必要的类型转换和类型错误。
没有泛型的时候,像 List 这样的集合类存储的是 Object 类型,导致从集合中读取数据时,必须进行强制类型转换,否则会引发 ClassCastException。
java
List list = new ArrayList();
list.add("hello");
String str = (String) list.get(0); // 必须强制类型转换泛型一般有三种使用方式:泛型类 、泛型接口 、泛型方法。

1.泛型类:
java
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}如何实例化泛型类:
java
Generic<Integer> genericInteger = new Generic<Integer>(123456);2.泛型接口 :
java
public interface Generator<T> {
public T method();
}实现泛型接口,指定类型:
java
class GeneratorImpl<T> implements Generator<String>{
@Override
public String method() {
return "hello";
}
}3.泛型方法 :
java
public static < E > void printArray( E[] inputArray )
{
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}使用:
java
// 创建不同类型数组: Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { "Hello", "World" };
printArray( intArray );
printArray( stringArray );泛型常用的通配符有哪些?
常用的通配符为: T,E,K,V,?
- ? 表示不确定的 java 类型
- T (type) 表示具体的一个 java 类型
- K V (key value) 分别代表 java 键值中的 Key Value
- E (element) 代表 Element
什么是泛型擦除?
所谓的泛型擦除,官方名叫"类型擦除"。
Java 的泛型是伪泛型,这是因为 Java 在编译期间,所有的类型信息都会被擦掉。
也就是说,在运行的时候是没有泛型的。
例如这段代码,往一群猫里放条狗:
java
LinkedList<Cat> cats = new LinkedList<Cat>();
LinkedList list = cats; // 注意我在这里把范型去掉了,但是list和cats是同一个链表!
list.add(new Dog()); // 完全没问题!因为 Java 的范型只存在于源码里,编译的时候给你静态地检查一下范型类型是否正确,而到了运行时就不检查了。上面这段代码在 JRE(Java运行环境)看来和下面这段没区别:
java
LinkedList cats = new LinkedList(); // 注意:没有范型!
LinkedList list = cats;
list.add(new Dog());为什么要类型擦除呢?
主要是为了向下兼容,因为 JDK5 之前是没有泛型的,为了让 JVM 保持向下兼容,就出了类型擦除这个策略。
八、反射
1、什么是反射?原理?应用?
反射允许 Java 在运行时检查和操作类的方法和字段。通过反射,可以动态地获取类的字段、方法、构造方法等信息,并在运行时调用方法或访问字段。
比如创建一个对象是通过 new 关键字来实现的:
java
Person person = new Person();Person 类的信息在编译时就确定了,那假如在编译期无法确定类的信息,但又想在运行时获取类的信息、创建类的实例、调用类的方法,这时候就要用到反射。
反射功能主要通过 java.lang.Class 类及 java.lang.reflect 包中的类如 Method, Field, Constructor 等来实现。

比如说我们可以动态加载类并创建对象:
java
String className = "java.util.Date";
Class<?> cls = Class.forName(className);
Object obj = cls.newInstance();
System.out.println(obj.getClass().getName());比如说我们可以这样来访问字段和方法:
java
// 加载并实例化类
Class<?> cls = Class.forName("java.util.Date");
Object obj = cls.newInstance();
// 获取并调用方法
Method method = cls.getMethod("getTime");
Object result = method.invoke(obj);
System.out.println("Time: " + result);
// 访问字段
Field field = cls.getDeclaredField("fastTime");
field.setAccessible(true); // 对于私有字段需要这样做
System.out.println("fastTime: " + field.getLong(obj));反射有哪些应用场景?
①、Spring 框架就大量使用了反射来动态加载和管理 Bean。
java
Class<?> clazz = Class.forName("com.example.MyClass");
Object instance = clazz.newInstance();②、Java 的动态代理机制就使用了反射来创建代理类。代理类可以在运行时动态处理方法调用,这在实现 AOP 和拦截器时非常有用。
java
InvocationHandler handler = new MyInvocationHandler();
MyInterface proxyInstance = (MyInterface) Proxy.newProxyInstance(
MyInterface.class.getClassLoader(),
new Class<?>[] { MyInterface.class },
handler
);③、JUnit 和 TestNG 等测试框架使用反射机制来发现和执行测试方法。反射允许框架扫描类,查找带有特定注解(如 @Test)的方法,并在运行时调用它们。
java
Method testMethod = testClass.getMethod("testSomething");
testMethod.invoke(testInstance);④、最常见的是写通用的工具类,比如对象拷贝工具。比如说 BeanUtils、MapStruct 等等,能够自动拷贝两个对象之间的同名属性,就是通过反射来实现的。
反射的原理是什么?
每个类在加载到 JVM 后,都会在方法区生成一个对应的 Class 对象,这个对象包含了类的所有元信息,比如字段、方法、构造器、注解等。
通过这个 Class 对象,我们就能在运行时动态地创建对象、调用方法、访问字段。
反射的优缺点是什么?
反射的优点还是很明显的。首先是能够在运行时动态操作类和对象。其次是能够编写通用的代码,一套代码可以处理不同类型的对象。还有就是能够突破访问限制,访问 private 字段和方法,这在反编译场景下很有用。
但反射的缺点也不少。最明显的是性能问题,反射操作比直接调用要慢很多,因为需要在运行时解析类信息、进行类型检查、权限验证等。
其次是反射能够绕过访问控制,访问和修改 private 成员,这会破坏类的封装。
九、Lambda表达式
1、Lambda表达式了解多少?
Lambda 表达式主要用于提供一种简洁的方式来表示匿名方法,使 Java 具备了函数式编程的特性。
比如说我们可以使用 Lambda 表达式来简化线程的创建:
java
new Thread(() -> System.out.println("Hello World")).start();这比以前的匿名内部类要简洁很多。
所谓的函数式编程,就是把函数作为参数传递给方法,或者作为方法的结果返回。比如说我们可以配合 Stream 流进行数据过滤:
java
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> evenNumbers = numbers.stream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());其中 n -> n % 2 == 0 就是一个 Lambda 表达式。表示传入一个参数 n,返回 n % 2 == 0 的结果。