目录
[第11章 报表数据导出](#第11章 报表数据导出)
[11.1 Clickhouse安装](#11.1 Clickhouse安装)
[11.2 Clickhouse建表](#11.2 Clickhouse建表)
[11.2.1 创建database](#11.2.1 创建database)
[11.2.2 创建table](#11.2.2 创建table)
[11.3 Hive数据导出至Clickhouse](#11.3 Hive数据导出至Clickhouse)
第11章 报表数据导出
由于本项目最终要出的报表,要求具备交互功能,以及进行自助分析的能力,所以为保证数据分析的最大灵活度,我们需要提供明细数据。
上述描述对计算引擎提出来了两点要求:
第一点:延迟低,交互式的自助分析,一般都要求低延时。
第二点:支持的数据量大:由于需要计算明细数据,所说数据量相对较大。
综合考虑:我们选择使用clickhouse作为分析引擎。
11.1 Clickhouse 安装
Clickhouse的安装和使用可参考以下博客。
大数据技术------ Clickhouse安装-CSDN博客
11.2 Clickhouse 建表
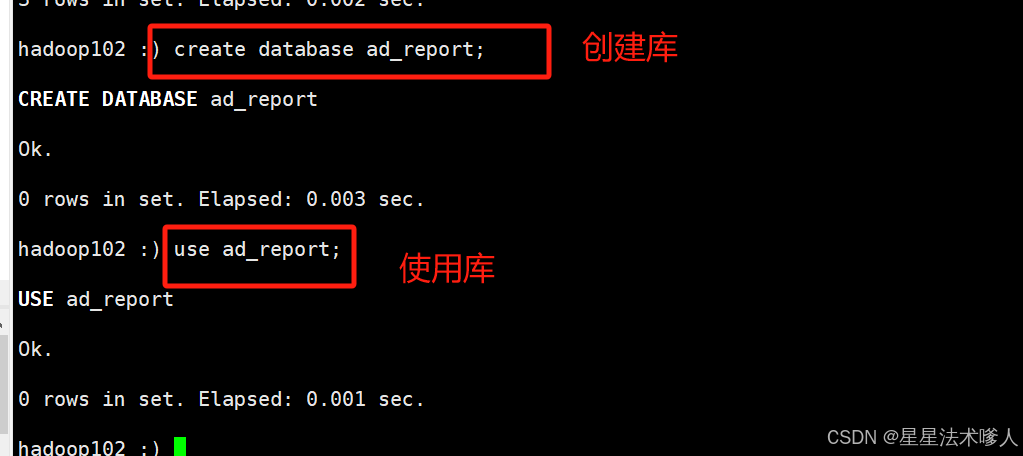
11.2.1 创建 database
需要先启动hiveserver2,并执行clickhouse-client -m连接server
hadoop102 :)
create database ad_report;
use ad_report;
11.2.2 创建 table
sql
drop table if exists dwd_ad_event_inc;
create table if not exists dwd_ad_event_inc
(
event_time Int64 comment '事件时间',
event_type String comment '事件类型',
ad_id String comment '广告id',
ad_name String comment '广告名称',
ad_product_id String comment '广告产品id',
ad_product_name String comment '广告产品名称',
ad_product_price Decimal(16, 2) comment '广告产品价格',
ad_material_id String comment '广告素材id',
ad_material_url String comment '广告素材url',
ad_group_id String comment '广告组id',
platform_id String comment '推广平台id',
platform_name_en String comment '推广平台名称(英文)',
platform_name_zh String comment '推广平台名称(中文)',
client_country String comment '客户端所处国家',
client_area String comment '客户端所处地区',
client_province String comment '客户端所处省份',
client_city String comment '客户端所处城市',
client_ip String comment '客户端ip地址',
client_device_id String comment '客户端设备id',
client_os_type String comment '客户端操作系统类型',
client_os_version String comment '客户端操作系统版本',
client_browser_type String comment '客户端浏览器类型',
client_browser_version String comment '客户端浏览器版本',
client_user_agent String comment '客户端UA',
is_invalid_traffic UInt8 comment '是否是异常流量'
) ENGINE = MergeTree()
ORDER BY (event_time, ad_name, event_type, client_province, client_city, client_os_type,
client_browser_type, is_invalid_traffic);11.3 Hive 数据导出至 Clickhouse
本项目使用spark-sql查询数据,然后通过jdbc写入Clickhouse,具体操作如下:
1 )创建 Maven 项目, pom.xml 文件如下
XML
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>ad_hive_to_clickhouse</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- 引入mysql驱动,目的是访问hive的metastore元数据-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.31</version>
</dependency>
<!-- 引入spark-hive模块-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<!--引入clickhouse-jdbc驱动,为解决依赖冲突,需排除jackson的两个依赖-->
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
<exclusions>
<exclusion>
<artifactId>jackson-databind</artifactId>
<groupId>com.fasterxml.jackson.core</groupId>
</exclusion>
<exclusion>
<artifactId>jackson-core</artifactId>
<groupId>com.fasterxml.jackson.core</groupId>
</exclusion>
</exclusions>
</dependency>
<!-- 引入commons-cli,目的是方便处理程序的输入参数 -->
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<!--将依赖编译到jar包中-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<!--配置执行器-->
<execution>
<id>make-assembly</id>
<!--绑定到package执行周期上-->
<phase>package</phase>
<goals>
<!--只运行一次-->
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>2 )创建 com.atguigu.ad.spark.HiveToClickhouse 类,并编辑如下内容
java
package com.atguigu.ad.spark;
import org.apache.commons.cli.*;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
public class HiveToClickhouse {
public static void main(String[] args) {
// 使用common-cli处理传入参数
// 1 定义能够传入哪些参数
Options options = new Options();
options.addOption(OptionBuilder.withLongOpt("hive_db").withDescription("hive数据库名称(required)").hasArg(true).isRequired(true).create());
options.addOption(OptionBuilder.withLongOpt("hive_table").withDescription("hive表名称(required)").hasArg(true).isRequired(true).create());
options.addOption(OptionBuilder.withLongOpt("hive_partition").withDescription("hive分区(required)").hasArg(true).isRequired(true).create());
options.addOption(OptionBuilder.withLongOpt("ck_url").withDescription("clickhouse的jdbc url(required)").hasArg(true).isRequired(true).create());
options.addOption(OptionBuilder.withLongOpt("ck_table").withDescription("clickhouse表名称(required)").hasArg(true).isRequired(true).create());
options.addOption(OptionBuilder.withLongOpt("batch_size").withDescription("数据写入clickhouse时的批次大小(required)").hasArg(true).isRequired(true).create());
// 2 解析参数
GnuParser gnuParser = new GnuParser();
CommandLine cmd = null;
try {
cmd = gnuParser.parse(options, args);
} catch (ParseException e) {
e.printStackTrace();
return;
}
// 创建spark-sql环境
SparkConf conf = new SparkConf().setAppName("HiveToClickhouse");
SparkSession sparkSession = SparkSession.builder()
.enableHiveSupport()
.config(conf)
.getOrCreate();
// 读取hive中的数据
//5.设置如下参数,支持使用正则表达式匹配查询字段
sparkSession.sql("set spark.sql.parser.quotedRegexColumnNames=true");
Dataset<Row> dataset = sparkSession.sql("" +
"select `(dt)?+.+` from " + cmd.getOptionValue("hive_db") + "." + cmd.getOptionValue("hive_table") + " where dt='" + cmd.getOptionValue("hive_partition") + "'");
// 写入到clickhouse中
dataset.write().format("jdbc")
.mode(SaveMode.Append)
.option("url",cmd.getOptionValue("ck_url"))
.option("driver","ru.yandex.clickhouse.ClickHouseDriver")
.option("dbtable",cmd.getOptionValue("ck_table"))
.option("batch_size",cmd.getOptionValue("batch_size"))
.save();
sparkSession.close();
}
}3 )上传 hive-site.xml 、 文件到项目的 resource 目录下
4 )打包,并上传 xxx-jar-with-dependencies.jar 到 hadoop102 节点/opt/module/spark
5 )执行如下命令测试
java
spark-submit \
--class com.atguigu.ad.spark.HiveToClickhouse \
--master yarn \
ad_hive_to_clickhouse-1.0-SNAPSHOT-jar-with-dependencies.jar \
--hive_db ad \
--hive_table dwd_ad_event_inc \
--hive_partition 2023-01-07 \
--ck_url jdbc:clickhouse://hadoop102:8123/ad_report \
--ck_table dwd_ad_event_inc \
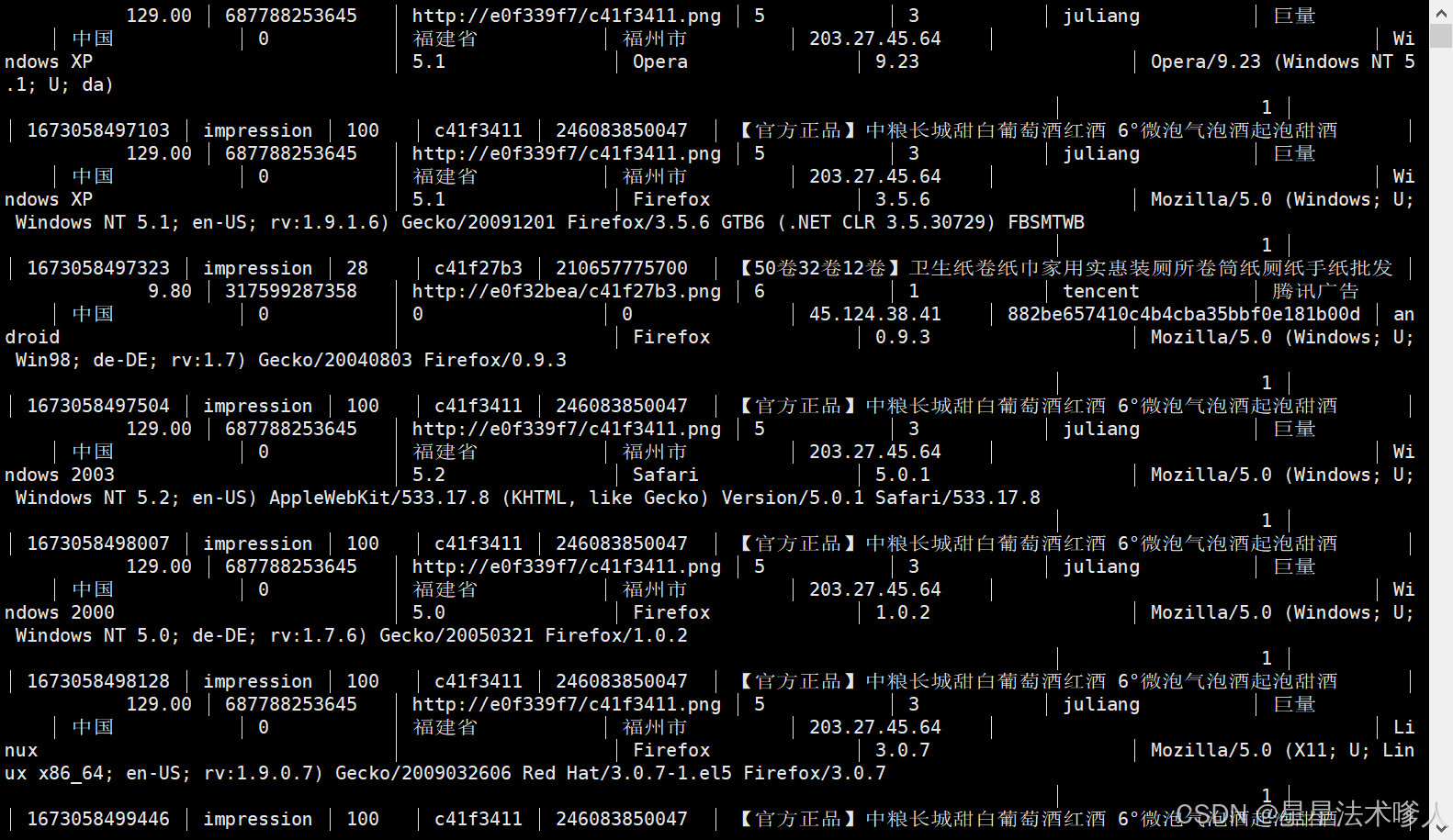
--batch_size 10006) 在clickhouse中运行select * from dwd_ad_event_inc; ,可看到数据已经导入clickhouse
注意事项:
( 1 )本地安装的 Spark ,需由原来数仓安装的纯净版,替换为:
https://archive.apache.org/dist/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz
( 2 )为保证之前数仓的 hive on spark 环境可继续使用,需要在 $HIVE_HOME/conf/spark-defaults.conf 中增加如下参数:
spark.yarn.populateHadoopClasspath true
增加原因如下:
Running Spark on YARN - Spark 3.5.2 Documentation
( 3 )为保证任务可提交到 yarn 运行,需在 $SPARK_HOME/conf/spark-env.sh 文件中增加如下参数:
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop/
我们此项目安装的不是纯净版,所以不需要执行此操作。
前面章节:
大数据项目------实战项目:广告数仓(第一部分)-CSDN博客
大数据项目------实战项目:广告数仓(第二部分)-CSDN博客
大数据技术------实战项目:广告数仓(第三部分)-CSDN博客