在OceanBase 4.3版本发布后(OceanBase社区版 V4.3 免费下载),其新增的列存引擎,及行列混存一体化的能力,可以支持秒级实时分析,引发了用户、开发者及业界人士的广泛讨论。本文选取了这些讨论中较为典型的一些问题,以解答大家的疑惑。
Q1:OceanBase 列存是什么?
OceanBase的列存技术是一种数据存储形态,它将磁盘上的静态数据以列存的方式保存,而将内存中的修改数据以行存的方式保存,这种设计既保证了高效的扫描性能,又兼顾了出色的事务处理能力。
对于分析类查询,列存可以极大地提升查询性能,也是OceanBase做好 HTAP 的一项不可缺少的功能。经典 AP 数据库,列存数据通常是静态的,很难被原地更新,而 OceanBase 的 LSM Tree 架构中 SSTable 是静态的,天然适合列存的实现;MemTable 是动态的,仍然是行存,对于事务处理不会造成额外影响,这样我们可以一定程度上兼顾 TP 类和 AP 类查询的性能。
Q2:列存版推荐配置是什么?
# 设置 collation 为 utf8mb4_bin,性能瞬间提升 15%
set global collation_connection = utf8mb4_bin;
set global collation_server = utf8mb4_bin;
set global ob_query_timeout= 10000000000;
set global ob_trx_timeout= 100000000000;
set global ob_sql_work_area_percentage=30;
set global max_allowed_packet=67108864;
# 建议是cpu的10倍
set global parallel_servers_target=1000;
set global parallel_degree_policy = auto;
set global parallel_min_scan_time_threshold = 10;
# 限制 parallel_degree_policy = auto 时的最大 dop
# 出现较大 dop 可能导致性能问题。下面的值建议设为 cpu_count * 2
set global parallel_degree_limit = 0;
alter system set compaction_low_thread_score = cpu_count;
alter system set compaction_mid_thread_score = cpu_count;
alter system set default_table_store_format = "column";注:上述代码中 cpu_count 表示创建租户时指定的 min_cpu。
Q3:如何让租户创建出来的表,默认就是列存表?
这很简单,设置一个租户级配置项即可:
alter system set default_table_store_format = "column";相应地,也可以把默认建表做成行存,或者行存列存双份:
alter system set default_table_store_format = "row"; //行存
alter system set default_table_store_format = "compound"; //行存列存双份数据Q4:列存表的空间占用和行存表比怎么样?
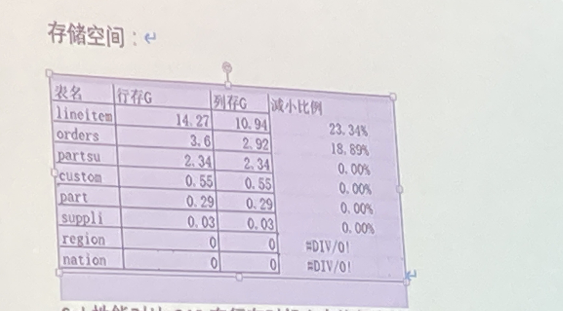
列存表的空间比行存表省 20% 左右。为什么不是更多?因为OceanBase的行存表,压缩能力已经非常强了!
下面是一个客户自己测试 TPC-H 100G 的结果,供参考:
Q5:如何创建一个列存表?
首先,创建行列混合表(冗余行存列存表)。
非分区表
create table t1(
c1 TINYINT,
c2 SMALLINT,
c3 MEDIUMINT
) with column group (all columns, each column);分区表:
create table t2(
pk int,
c1 int,
c2 int,
primary key (pk)
)
partition by hash(pk) partitions 4
with column group (all columns, each column);创建行列混合的列存表的时候,总是会用到 with column group (all columns, each column)语法,它表示的意思如下:
- all columns。把所有列聚合在一起成组,看成一个宽列,一行一行存储。这其实就和原来的行存是一致的。
- each column。表中的每一列分别使用列格式来存储。
all columns、each column 一起出现,意味着默认创建列存表后同时冗余行存, **每个副本存储两份基线数据。**不过值得注意的是,每张表无论多少份基线数据,在 memtable 和转储里的增量数据,依然是共享同一份。
其次,创建纯列存表。
非分区表
create table t3(
c1 TINYINT,
c2 SMALLINT,
c3 MEDIUMINT
) with column group (each column);分区表:
create table t4(
pk1 int,
pk2 int,
c1 int,
c2 int,
primary key (pk1, pk2)
)
partition by hash(pk1) partitions 4
with column group (each column);对于 t4 表,会针对 pk1、pk2、c1、c2 分别建一个列存,同时还会针对 (pk1, pk2)组合建一个行存。
Q6:如何判断是否走到了列存?
扫描走行存时,explain 中显示的是 TABLE FULL SCAN,走到列存时,显示的是 COLUMN TABLE FULL SCAN。以访问下面的 t5 表为例:
create table t5(
c1 TINYINT,
c2 SMALLINT,
c3 MEDIUMINT,
c4 INT,
c5 INT,
PRIMARY KEY(c1, c2)
) with column group(all columns, each column);
OceanBase(admin@test)>explain select c1,c2 from t5;
+------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t5 |1 |3 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t5.c1], [t5.c2]), filter(nil), rowset=16 |
| access([t5.c1], [t5.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t5.c1], [t5.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------+
11 rows in set (0.011 sec)
OceanBase(admin@test)>explain select c1 from t5;
+------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------+
| ====================================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------ |
| |0 |COLUMN TABLE FULL SCAN|t5 |1 |3 | |
| ====================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t5.c1]), filter(nil), rowset=16 |
| access([t5.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t5.c1], [t5.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------+
11 rows in set (0.003 sec)Q7:列存支持更新吗?如何更新?memtable里的结构是怎样的?
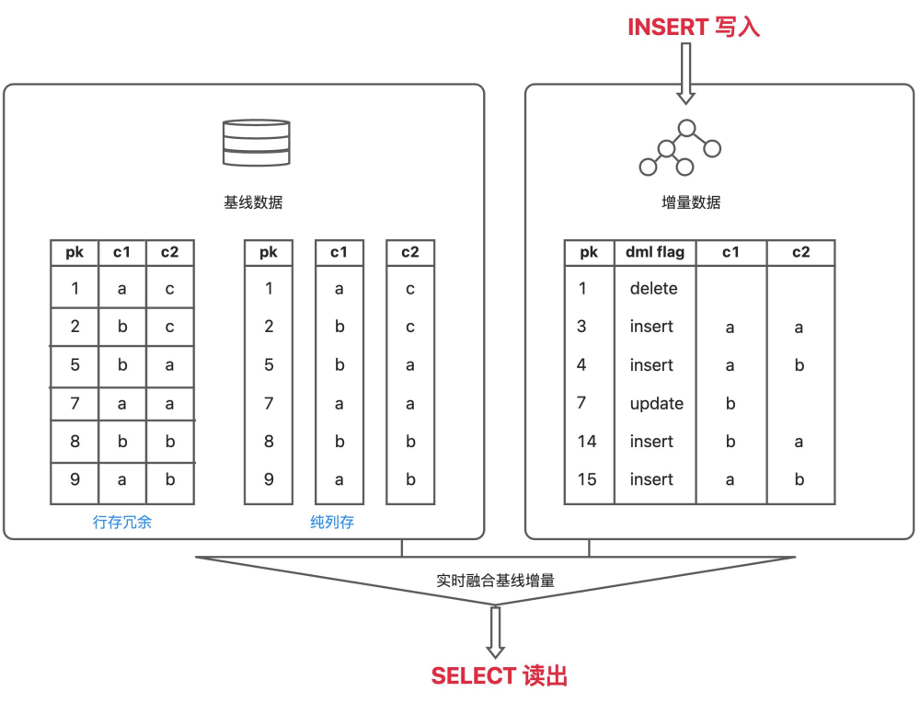
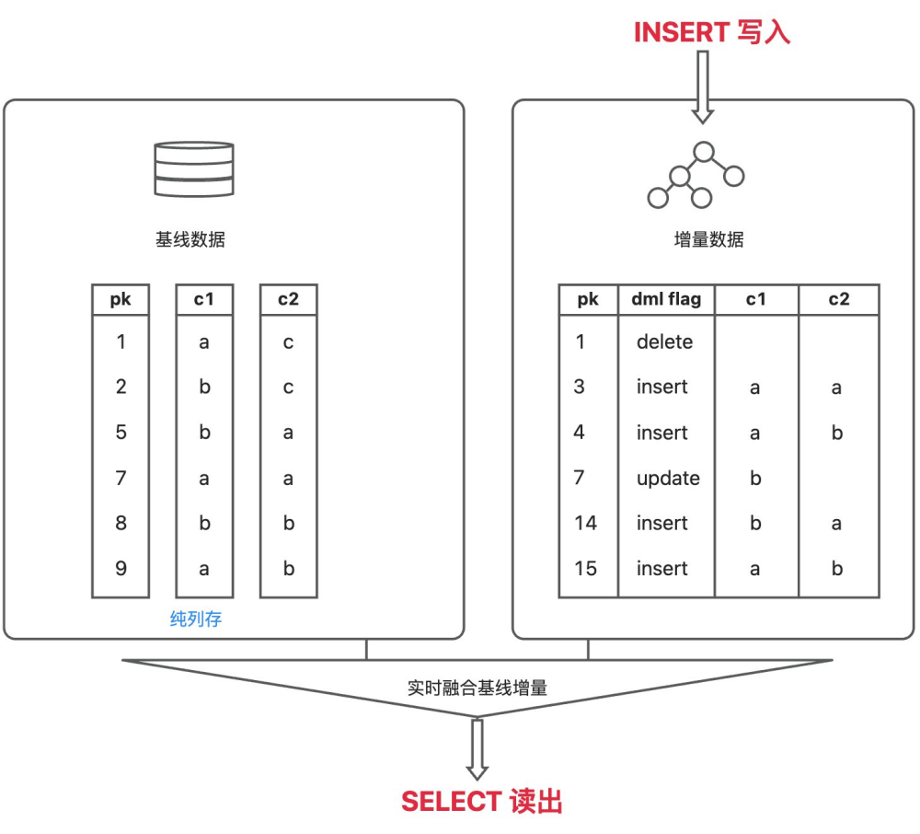
OceanBase 中,增删改操作都在内存里完成,数据以行存的形式保存在 Memtable 里;而基线数据是只读的,以列存的形式保存在磁盘上。当读取一列数据时,会实时地融合Memtable 中的行存数据和磁盘里的列存数据,输出给用户。这意味着,OceanBase 支持强一致读列存,不会有数据延迟。
写入memtable 的数据支持转储,转储数据依然以行存的形式保存。合并后,行存数据和基线列存数据融合,形成新的基线列存数据。
需要注意的是,对于列存表来说,如果存在大量更新操作,并且没有及时合并,查询性能是不优的。推荐批量导入数据后发起一次合并,可以获得最优的查询性能。少量更新,则对性能影响不大。
Q8:列存里支持部分列集合在一起存储吗?
OceanBase v4.3.3 及之前版本里,仅支持要么每个列独立存储,要么所有列组成行在一起存储。暂不支持任选若干列集合在一起存储。
Q9:最多支持多少列?
目前一个列存表最多支持 4096 列。
Q10:允许增删列吗?
允许增加列,允许删列。支持 varchar 列字符数改大、改小。
列存支持多种 DDL,和行存表无异。
Q11:支持对列存的某一列建索引吗?
支持对列存的某一列建索引。OceanBase 不区分是对列存建索引,还是对行存建索引,默认建出来的索引结构是一样的(行存格式)。
对列存某一列或几列建索引的意义在于可以构造一个覆盖索引,提升点查询性能,或者对特定列做排序以提升排序性能。
Q12:"列存索引"是什么意思?
OceanBase 还支持列存索引的概念,意思是:索引表的结构是列存格式。这里容易和"对列存建索引"混淆。
例如,我们已经有行存表 t6 ,希望对 c3 求和且性能最好,这时可以对 c3 建一个列存索引,例如:
create table t6(
c1 TINYINT,
c2 SMALLINT,
c3 MEDIUMINT
);
create /*+ parallel(2) */ index idx1 on t6(c3) with column group (each column);除此之外,OceanBase还支持更多索引创建方式,如下:
//支持索引中冗余行存
create index idx1 on t1(c2) storing(c1) with column group(all columns, each column);
alter table t1 add index idx1 (c2) storing(c1) with column group(all columns, each column);
//纯列存
create index idx1 on t1(c2) storing(c1) with column group(each column);
alter table t1 add index idx1 (c2) storing(c1) with column group(each column);在数据库索引中使用 STORING 子句的目的是存储额外的非索引列数据到索引中。这可以为特定的查询提供性能优化,既可以避免回表,也可以降低索引排序的代价。当查询仅需要访问存储在索引中的列,而不需要回表查询原始行时,可以大幅提升查询效率。
Q13:列存表的查询有何特点?
冗余行存表中,列存表查询逻辑默认 range scan 走列存模式, point get 仍回退到行存模式。
纯列存表中,任何查询都走列存模式。
Q14:有和 ClickHouse 的性能对比吗?
OceanBase v4.3.1 没有发布测试性能数据。
我们内部对比过OceanBase v4.3.2 开发版和 ClickHouse 的性能,但目前没有第三方的测试和对比结果,因此下文的测试结果仅供参考。
(1)ClickBench(aws) RT 对比。
云上标准测试(c6a.4xlarge 500gb gp2) 配置:16C、32G内存、500G磁盘、1500 iops。
|-----------|-------|--------|----------|--------|---------|
| | OB | CK |
| | OB | CK | cold run | 114.35 | 139.572 |
| hot run 1 | 36.88 | 44.051 |
| hot run 2 | 36.83 | 36.831 |
该对比无Q30改写优化,若Q30改写优化后,OceanBase的测试结果预计可再提升2s。
Q15:使用列存有什么注意事项?
第一,批量导入数据后,建议做一次合并,读性能可以更优。导完数据后租户内触发一次合并,保证数据全部进入基线,租户内执行 alter system major freeze; 然后在系统租户执行 select STATUS from CDB_OB_MAJOR_COMPACTION where TENANT_ID = 租户ID; 判断合并是否完成,当 STATUS 变为 IDLE 即表示合并完成。
第二,合并后,推荐做一次统计信息收集。收集统计信息方法如下:
- 在业务租户一键对所有表收集统计信息,启动16个线程并发收集
CALL DBMS_STATS.GATHER_SCHEMA_STATS ('db', granularity=>'auto', degree=>16);
- 观测统计信息进度可以通过视图
GV$OB_OPT_STAT_GATHER_MONITOR
第三,可以使用全量旁路导入逻辑批量导入数据,使用这种方式导入数据的表无需做合并,就能达到最优列存扫描性能。支持全量旁路导入的工具包括 obloader、原生 load data 命令。
第四,对于非大宽表场景,不使用列存也可能达到和列存相当的性能。这得益于 OceanBase 行存版本中微块级别的行列混合存储架构(遇到这种情况,不用惊讶)。
第五,大数据量表,cold run 和 hot run 性能有区别。
第六,优化器会根据代价估算,自动选择对列数据的访问使用行存还是列存。
第七,列存表合并速度会变慢。
Q16:什么是旁路导入?如何做旁路导入?
旁路导入是一种加快数据导入,并且能够加速数据查询的数据导入方式。大表数据导入,推荐使用旁路导入方式。目前,load data 命令、insert into select 语句支持旁路导入。旁路导入的详细使用方式参考 OceanBase 官网文档。
Q17:支持事务吗?对事务大小有限制吗?
和行存表一样,支持事务,并且事务大小无限制,具备高一致性。
和 Doris 相比,OceanBase 事务能实时性更好。OceanBase 支持大量小事务,而 Doris 必须攒批多行形成大事务后再提交。
Q18:支持使用 FlinkCDC 从其它数据库同步数据到 OceanBase 吗?
支持。例如,使用 FlinkCDC 从 MySQL 同步数据到 OceanBase:OceanBase分布式数据库-海量数据 笔笔算数
Q19:是否支持 Flink Connector 访问 OceanBase?
支持。详见 https://github.com/oceanbase/flink-connector-oceanbase
Q20:列存表的日志同步、备份恢复等有什么特别之处吗?
没有任何特别之处,和行存表一致。同步的日志都是行存模式。
Q21:是否支持将行存表用 DDL 变成列存表?
支持。通过加列存、删行存实现。相关语法示例如下。
create table t1( pk1 int, c2 int, primary key (pk1));
alter table t1 add column group(all columns, each column);
alter table t1 drop column group(all columns, each column);
alter table t1 add column group(each column);
alter table t1 drop column group(each column);- note:
alter table t1 drop column group(all columns, each column);执行后,不用担心没有任何 group 来承载数据,所有列会被放到一个叫做DEFAUTL COLUMN GROUP的默认 group 中。DEFAUTL COLUMN GROUP中的存储格式,由租户级配置项default_table_store_format的取值决定。 - 该操作为 offline DDL,会锁表。线上谨慎使用。
Q22:还有哪些可以进一步提升 AP Query 性能的方法?
根据一些实践经验得知,首先如果不是有特殊排序要求,建表时候字符集不要使用 utf8mb4,而是使用 binary,可以提升性能。例如:
create table t5(c1 TINYINT, c2 VARVHAR(50)) CHARSET=binary with column group (each column);其次,如用户或者业务可以接受, mysql 租户建表时指定 utf8mb4_bin 字符集,建表时带上:CHARSET = utf8mb4 collate=utf8mb4_bin
此外,增加 UNIT 的 IOPS,可以加速旁路导入。
Q23:面向列存的优化器,有什么特点?
面相列存的优化器,相对于面相行存优化器,增加了:
- 优化器自主选择行、列存的能力。
- hint 控制行、列存选择的能力(表级别)。
- 适配了列存的计划代价计算。
- 增加了列存的晚期物化优化。
以上就是目前关于列存的解答,如果大家有其他疑问,欢迎在评论区留言讨论。