编者按:LLMs 规模和性能的不断提升,让人们不禁产生疑问:这种趋势是否能一直持续下去?我们是否能通过不断扩大模型规模最终实现通用人工智能(AGI)?回答这些问题对于理解 AI 的未来发展轨迹至关重要。
在这篇深度分析文章中,作者提出了一个令人深思的观点:单单依靠扩大模型规模来实现 AGI 的可能性几乎为零。
这篇文章为我们提供了一个清醒的视角,提醒我们在预测 AI 未来发展时需要保持谨慎和理性。它挑战了业界普遍接受的观点,促使我们重新思考 AI 发展的方向和潜在瓶颈。随着 AI 技术的不断演进,我们需要更加全面和深入地理解这一领域,而不是简单地依赖于趋势线外推的预测方法。
作者 🕶 | Arvind Narayanan & Sayash Kapoor
编译 🐣 | 岳扬
目录📚
01 Scaling "laws" 经常被误解
02 这种趋势预测是毫无根据的猜测
03 合成数据并非万能钥匙
04 模型越来越小,但训练时间却越来越长
05 The ladder of generality
06 扩展阅读
到目前为止,LLMs 其规模不断增加,其性能表现也日益增强。然而,这是否意味着我们可以据此预测人工智能的未来发展趋势呢?
目前业界广泛接受的一种观点认为,AI 目前所保持的发展趋势仍将持续,并且可能会最终带领我们实现通用人工智能,也就是所谓的 AGI。
然而,这种观点建立在一连串的误解和错误观念之上。模型规模的线性增长看似可以预测,但这实际上似乎是对研究成果的误读。 另外,有迹象表明 LLMs 开发人员所能使用的高质量训练数据已经逼近极限。同时,整个行业正面临着缩小模型规模的巨大压力。虽然我们无法准确预知 AI 通过不断扩大模型规模将发展到何种程度,但我们认为单单依靠扩大模型规模实现 AGI 的可能性几乎为零。
01 Scaling "laws" 经常被误解
研究表明1,随着模型规模 、训练计算资源以及训练数据集的扩大,语言模型的性能表现似乎在"提升"。这种模型性能提升的规律性确实令人震惊🤯,并且在很大范围内都适用。这也是为什么很多人认为,不断增大模型规模的发展趋势在未来一段时间内仍将延续,顶尖的人工智能公司也将不断推出更大、更强的模型。
然而,这种理解完全曲解了 scaling laws 的本质。所谓"更好"的模型究竟指的是什么?scaling laws 仅仅量化了模型在预测文本时的不确定性的减少程度,也就是说,模型在预测序列中下一个词的能力的提高。 当然,不确定性的减少程度对于终端用户来说并不重要 ------ 关键在于模型的"涌现能力2",即模型随着规模的扩大,而获得新能力的趋势。
需要注意!涌现能力不会遵循某种固定法则。 虽然到目前为止,模型规模的增加确实带来了很多新能力,但我们没有任何经验性的规律可以确信这种趋势会无期限的持续下去。1
为什么模型的涌现能力不会无限期的持续增强?这涉及到 LLMs 能力的核心争论之一 ------ 它们能否超越训练数据进行外推(extrapolation),还是只能学习训练数据中的任务场景?目前的证据并不完整,对此有多种合理的解读方式。但我们更倾向于持怀疑态度。在那些评估模型解决未知任务能力的基准测试中,大语言模型通常表现不佳3。
如果 LLMs 无法在现有训练数据的基础上实现更多突破,那么到了某个阶段,单单增加数据量将不再起到任何作用,因为所有可能出现在训练数据中的任务场景都已经有所体现。传统的机器学习模型最终都会遇到性能瓶颈,也许 LLMs 也不例外。
02 这种趋势预测是毫无根据的猜测
持续扩大模型规模的另一个障碍在于获取训练数据。目前这些科技公司已经基本利用了所有易于获取的数据资源。那么,他们还能找到更多的优质数据吗?
这种情况可能比想象中更为棘手。有人可能会认为,新的数据源(比如转录 YouTube 上的全部视频为文本文档)能够使数据量增加一到两个数量级。诚然,YouTube 上的视频总时长达到了 1500 亿分钟4。但考虑到其中大部分视频并没有实用的音频内容(可能是音乐、静态图片或游戏视频等),实际可用的数据量可能远低于 Llama 3 目前使用的150万亿个词元(tokens) ------ 这还不包括对转录的 YouTube 音频进行去重和根据质量进行筛选的过程,这一步骤很可能会再减少至少一个数量级的数据量。2
大家经常会讨论这些科技公司何时会"耗尽"训练数据。但这并不是一个有意义的问题,训练数据总会有的,但获取训练数据的成本会越来越高。 而且,版权所有者已经意识到这一点5,并希望得到报酬,获取数据的成本可能会急剧上升。除了经济成本,还可能涉及声誉和合规风险,因为整个社会可能会对某些数据收集行为产生抵触情绪。
我们可以肯定,没有任何指数型增长的趋势能够无限期地持续。但是,很难预测技术趋势何时会趋于平稳。特别是当这种增长趋势是突然停止而非逐渐放缓时,趋势线并不会提前给出即将趋于平稳的信号。
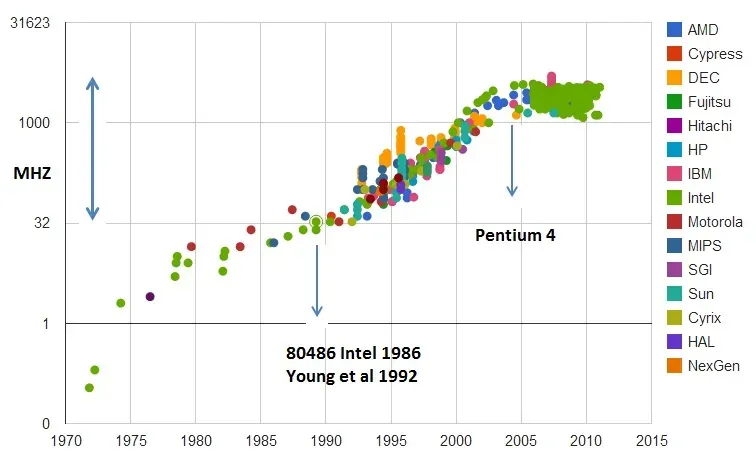
中央处理器(CPU)的时钟速度历史变化图。y轴采用对数尺度。
source: https://en.wikipedia.org/wiki/File:Clock_CPU_Scaling.jpg
有两个著名的案例可以证明这一观点,一个是 00 年代 CPU 的时钟速度,另一个则是上世纪 70 年代的飞机速度。CPU 制造商们认为,进一步提升时钟速度的成本过高且意义不大(因为 CPU 已不再是影响整体性能的关键瓶颈),因此干脆决定停止在这一领域的竞争,从而突然间消解了不断提高时钟速度的压力。至于飞机飞行速度的情况则更为复杂,但本质上是因为市场开始更加重视燃油效率67而不再是飞行速度。3
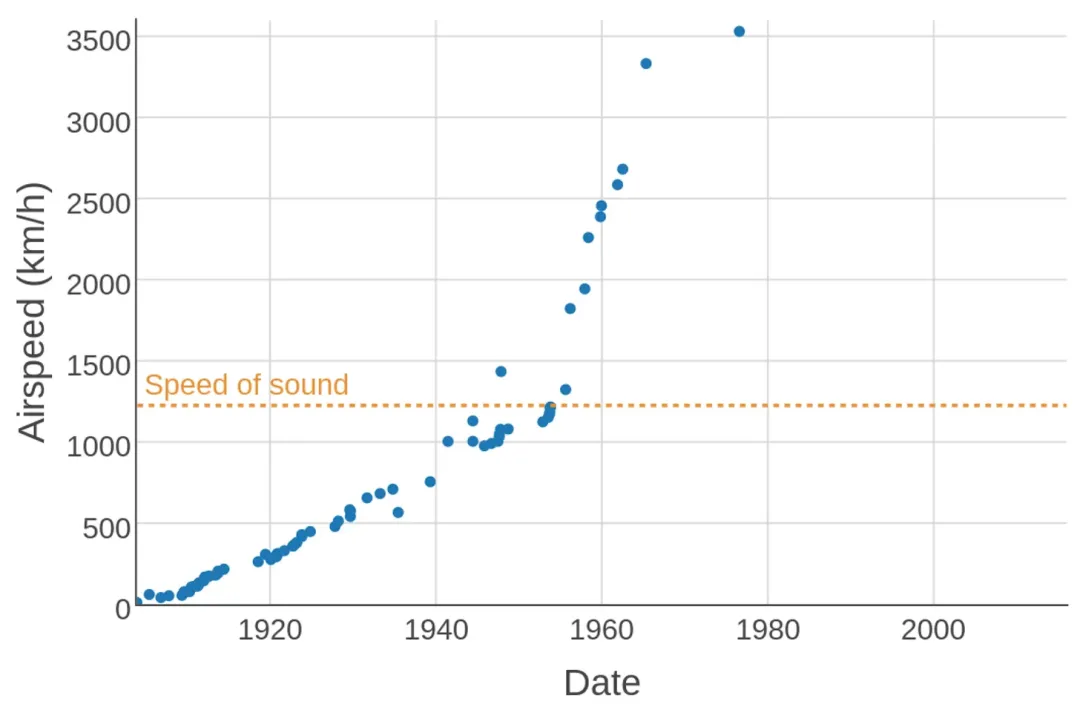
不同时期的飞行空速记录。1976年 SR-71 Blackbird 创造的纪录至今仍未被打破。Source: https://en.wikipedia.org/wiki/Flight_airspeed_record
对于 LLMs ,可能还有几个数量级的扩展空间,或者可能现在就已经达到了极限。与 CPU 和飞机的情况类似,是否继续扩展本质是一个商业决策,而且很难提前做出准确预测。
在研究领域,目前的焦点已经从不断扩充数据集转向提升训练数据的质量 8。通过精细的数据清洗和筛选过滤,我们可以使用更小的数据集910构建出同样强大的模型。4
03 合成数据并非万能钥匙
合成数据(Synthetic data)通常被看作是继续扩展模型规模的关键途径。换句1话说,目前的模型或许能够用来为下一代模型生成训练数据。
但我们认为这种看法基于一种错误的认识 ------ 我们不相信开发者正在使用(或者能够使用)合成数据来增加训练数据量。有一篇论文11详细列出了合成数据在模型训练中的各种使用场景,并且都是为了弥补具体差距,并针对特定领域(比如数学语言、编程语言或其他 low-resource languages(译者注:在数字世界中可用资源较少的语言。))进行改进的使用场景。同样, Nvidia 最近推出的 Nemotron 340B 模型12,专注于生成合成数据,该模型的主要应用场景就是数据对齐(译者注:alignment,确保合成数据与真实数据在分布上尽可能接近,以便合成数据可以有效地用于训练和提升模型性能。)。虽然还有一些次要用途,但用合成数据取代当前的用于预训练机器学习模型的数据源(sources of pre-training data)并不是其目标。简而言之,盲目生成合成训练数据不太可能达到人类生产的高质量数据相同效果。
在某些案例中,合成数据的效果十分好,例如 AlphaGo13 在 2016 年击败了围棋世界冠军,以及它的后续版本 AlphaGo Zero 和 AlphaZero**14 。这些系统通过自我对弈来学习下棋♟,后两者甚至没有使用任何人类棋谱作为训练数据。它们通过大量计算生成了相对高质量的棋谱数据,然后用这些棋谱数据集来训练神经网络,神经网络再结合计算生成更高质量的棋谱数据集,从而形成了一个迭代改进的正向循环。
自我下棋对弈♟是 "System 2 --> System 1 distillation" 过程的典型案例,在这个例子中,缓慢且昂贵的 "System 2" 模型生成训练数据,用以训练一个快速且经济的 "System 1" 模型。这种方法对于像围棋这样完全封闭的游戏非常有效。将自我对弈(self-play)应用于游戏之外的领域是一个有价值的研究方向。在诸如代码生成(code generation)等重要领域,这种策略可能很有价值。但我们不能指望在更开放的任务(open-ended tasks)中(比如语言翻译),能无限期地自我完善、提升。我们应该期待,能够通过自我对弈实现重大改进的领域是特殊情况,而不是普遍规律。
04 模型越来越小,但训练时间却越来越长
从历史角度来看,数据集大小、模型大小和投入的训练算力 ------ 这三个要素通常是同步增长的15,这一点也已经被证明是最佳的。但如果其中某个要素(高质量数据)成为瓶颈,其他两个要素,模型大小和投入的训练算力,是否还会继续增长?
根据当前的市场趋势,即使构建更大的模型能够解锁新的能力,但这似乎并不是一个明智的商业选择。这是因为模型的能力不再是大家选用某款模型所考虑的主要因素。换句话说,有许多应用程序都可以利用当前 LLMs 的能力来构建,但由于使用成本等原因,这些 Apps 没有被构建或使用。对那些可能需要多次调用16 LLMs 来完成某项任务的 "agentic" 工作流程(例如代码生成(code generation)17)来说尤其如此。
在过去的一年中,大部分开发工作都集中于在保持一定能力的前提下,开发更小的模型 5。前沿模型开发者不再公开模型的具体规模,所以我们无法确切知道这一点,但我们可以通过观察 API 定价来大致推测模型的规模。例如,GPT-4o 的成本是 GPT-4 的 25%,而能力相似或甚至更强。在 Anthropic 和 Google 系列模型也看到了同样的模式。Claude 3 Opus 是 Claude 模型家族中最昂贵(也可能是规模最大的)模型,但最近推出的 Claude** 3.5 Sonnet 不仅使用成本是前者的五倍,而且能力也更强。同样,Gemini 1.5 Pro 不仅使用成本更低,而且模型能力也更强大。因此,规模最大的模型并不一定是最强大的!
然而,另一方面,用于模型训练的算力规模可能还会继续增长。尽管看起来有些矛盾,但实际上较小的模型需要更多训练迭代次数才能达到与较大模型相同的性能水平。 因此,减小模型规模后,为了保持相同的性能水平,开发者需要消耗更多的训练计算资源。开发者必须在训练成本和推理成本之间做出权衡。早期的模型(如 GPT-3.5 和 GPT-4)在一定程度上被认为是训练不足的,因为在它们的整个生命周期中,推理成本被认为是训练成本的主要部分。理想情况下,这两者应该大致相等,因为总是有可能用训练成本的增加换取推理成本的减少,反之亦然。有这么一个典型案例:80 亿参数规模的 Llama 3 模型在训练过程中使用了 20 倍于原始 Llama 模型(大约70亿参数)的浮点运算次数(FLOPs)** 。
05 The ladder of generality
一个支持我们不太可能通过 "scaling" 看到模型拥有更多能力提升观点的迹象是,AI 巨头的 CEO 们已经大幅降低18了他们对通用人工智能(AGI)的预期。遗憾的是,他们并没有承认他们对"三年内实现AGI"的预测是错误的,而是为了挽回面子,决定淡化 AGI 的含义,以至于现在 AGI 的含义变得毫无意义。从一开始,AGI 就没有被明确定义19,这对它的发展很有帮助。
我们不必将泛化能力视为一个非黑即白的问题(binary),我们可以将其视为一个连续的过程(spectrum)。 在过去,为了让计算机执行一个全新的任务,需要大量的编程工作,可能需要编写和测试大量的代码。然而,随着技术的发展,出现了更高级的编程语言、更高效的编程工具和更智能的编程辅助系统,使得编程变得更加自动化和易于操作。我们可以将其视为泛化能力的提升。这一趋势始于从专用计算机(special-purpose computers)向图灵机**(Turing machines)的转变。从这个角度看,大语言模型的泛化能力并不是一个全新的概念。
这就是我们在《AI Snake Oil》20一书中所持的观点,其中有一章专门讨论 AGI。我们将人工智能的发展视为一种 punctuated equilibrium (译者注:是一个生物学术语,由古生物学家尼尔斯·埃德雷(Niles Eldredge)和史蒂芬·杰·古尔德(Stephen Jay Gould)在1972年提出,用来描述生物进化的一种模式。在这种模式中,物种的形态在长时间的稳定期(equilibrium)之后,会经历短暂的、快速的形态变化(punctuation),这些变化可能伴随着物种的灭绝和新物种的产生。这个概念在此强调了技术进步的不连续性和突发性,而不是持续和稳定的线性发展。)的过程,我们称之为 "The ladder of generality"(并不意味着泛化能力的进步是线性的)。指令调优(Instruction-tuned)的 LLMs 是这个阶梯(ladder)上最新的一步。在我们能让 AI 像人类一样有效地完成任何有经济价值的工作(这是 AGI 的一种定义)的泛化水平之前,我们还有许多台阶要走。
回顾历史,当人类站在阶梯的每一级台阶时,AI 研究领域都很难预测当前范式还能走多远、下一级台阶会是什么、它将何时到来、会开启哪些新应用以及对安全性的影响。我们认为这一趋势还将继续下去。
06 扩展阅读
Leopold Aschenbrenner 最近发表了一篇文章21,声称 "到 2027 年实现 AGI 是非常有可能的",这引起了轩然大波。我们没有试图在此逐点反驳 ------ 这篇文章的大部分内容都是在 Aschenbrenner 的那篇文章发布之前草拟的。Leopold Aschenbrenner 对于 AGI 将在2027年实现的观点,虽然有趣且引人深思,但本质上是一种趋势线外推预测方法的使用。此外,像许多 AI 推动者一样,他将基准性能与现实世界中的实用性混为一谈22了。
许多 AI 研究人员都对他的观点持怀疑态度,包括 Melanie Mitchell**、Yann LeCun、Gary Marcus、François Chollet 和 Subbarao Kambhampati 等人。
Dwarkesh Patel 为这场辩论的双方观点进行了很好地概述23。
致谢:感谢 Matt Salganik、Ollie Stephenson 和 Benedikt Ströbl 对本文初稿的反馈意见。
脚注:
-
如果能够找到一个平滑而非不连续变化的泛化能力度量标准,那么新出现的能力将是可预测的。然而,找到这样一个度量标准并不容易,尤其是对于那些需要综合技能的任务而言。在实践中,下一个数量级上是否会出现新能力以及哪些新能力将出现,这个问题谁也说不准。
-
人工智能公司确实使用转录的 YouTube 文本数据进行训练,但这些数据之所以有价值,是因为它可以帮助 LLMs 学习口语对话,而不是因为其数据数量庞大。
-
自由主义评论家(Libertarian commentators)将飞机速度的停滞增长完全归因于监管,但这是错误的,或者充其量是过于简单化了。诚然,FAA 在 1973 年基本上禁止了民用飞机在美国陆地上空进行超音速飞行。但最快的飞机都是军用飞机,所以禁令对它们没有影响。而且,民用飞机的巡航速度远低于 1 马赫,这是出于燃油效率和其他考虑。
-
关于 LLMs 的训练是否可以通过使用更少的训练数据(样本)来达到同样的甚至更好的性能,仍然存在争议。毕竟,人类儿童在接触到比 LLMs 少得多的词汇后就能学会语言。另一方面,人类儿童是"摇篮里的科学家",在很早就开发出了世界模型(world models)和推理能力(reasoning abilities),也许这就是他们能够高效学习语言的原因。这场争论与本文的观点无关。如果模型在处理特定任务或进行外推(extrapolation)时存在困难,那么这些困难将成为限制 LLMs 能力的主要因素,而不是样本数据的使用效率(译者注:sample efficiency,指的是模型在训练过程中使用最少的数据量就能达到良好性能的能力。)。
-
即便模型开发者发布了规模更大的模型(以参数数量计算),也越来越关注推理效率(例如在 MoE 模型 Mixtral 8x22B 中),推理过程中的有效活跃参数数量远远低于总参数数量。
Thanks for reading!
Hope you have enjoyed and learned new things from this blog!
About the authors
Arvind Narayanan is a professor of computer science at Princeton and the director of the Center for Information Technology Policy. He led the Princeton Web Transparency and Accountability Project to uncover how companies collect and use our personal information. His work was among the first to show how machine learning reflects cultural stereotypes. Narayanan is a recipient of the Presidential Early Career Award for Scientists and Engineers (PECASE).
Sayash Kapoor is a computer science Ph.D. candidate at Princeton University's Center for Information Technology Policy. His research focuses on the societal impact of AI. He previously worked on AI in the industry and academia at Facebook, Columbia University, and EPFL Switzerland. He is a recipient of a best paper award at ACM FAccT and an impact recognition award at ACM CSCW.
END
文中链接
1https://arxiv.org/abs/2001.08361
2https://arxiv.org/abs/2206.07682
4https://journalqd.org/article/view/4066
5https://reutersinstitute.politics.ox.ac.uk/how-many-news-websites-block-ai-crawlers
6https://theicct.org/sites/default/files/publications/Aircraft-fuel-burn-trends-sept2020.pdf
7https://www.etw.de/uploads/pdfs/ATAG_Beginners_Guide_to_Aviation_Efficiency_web.pdf
8https://x.com/karpathy/status/1797313173449764933
9https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
10https://arxiv.org/abs/2406.11794
11https://arxiv.org/html/2404.07503v1
13https://www.nature.com/articles/nature24270
14https://www.science.org/doi/10.1126/science.aar6404
15https://www.cnas.org/publications/reports/future-proofing-frontier-ai-regulation
16https://www.aisnakeoil.com/p/ai-leaderboards-are-no-longer-useful
17https://www.youtube.com/watch?v=tNmgmwEtoWE
19https://www.scientificamerican.com/article/what-does-artificial-general-intelligence-actually-mean/
20https://www.amazon.com/Snake-Oil-Artificial-Intelligence-Difference/dp/069124913X
21https://situational-awareness.ai/
22https://www.aisnakeoil.com/p/gpt-4-and-professional-benchmarks
23https://www.dwarkeshpatel.com/p/will-scaling-work
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: