目录规划
为了将这所有博客里的知识点逻辑顺畅地串联起来,特此设计了以下目录结构。这个顺序遵循了"概念引入 -> 基础回归 -> 分类进阶 -> 无监督学习"的学习路径:
- 第一章:启蒙篇------人工智能与机器学习的宏观版图
- 来源博客:人工智能和机器学习
- 核心内容:AI、ML、DL的关系,机器学习的分类(监督/无监督/强化),基本工作流程。
- 第二章:基石篇------预测连续值的线性回归
- 来源博客:线性回归
- 核心内容:一元/多元线性回归,损失函数,梯度下降,代码实战。
- 第三章:进阶篇------解决分类问题的逻辑回归
- 来源博客:逻辑回归
- 核心内容:从回归到分类的跨越,Sigmoid函数,决策边界,代码实战。
- 第四章:直觉篇------基于距离的K-近邻 (KNN)
- 来源博客:KNN算法
- 核心内容:KNN原理,K值选择,距离计算,优缺点分析,代码实战。
- 第五章:探索篇------发现数据内在结构的聚类算法
- 来源博客:聚类算法
- 核心内容:K-Means原理,簇的概念,与分类的区别,应用场景。
- 第六章:总结与展望
- 综合对比五大算法,如何选择适合的模型。
文章目录
- 目录规划
- [第四章:直觉篇------基于距离的 K-近邻 (KNN) 算法](#第四章:直觉篇——基于距离的 K-近邻 (KNN) 算法)
-
- [4.1 核心思想:物以类聚,人以群分](#4.1 核心思想:物以类聚,人以群分)
- [4.2 三大核心要素](#4.2 三大核心要素)
-
- [1. 距离度量 (Distance Metric)](#1. 距离度量 (Distance Metric))
- [2. K 值的选择 (The Value of K)](#2. K 值的选择 (The Value of K))
- [3. 分类决策规则](#3. 分类决策规则)
- [4.3 重要预处理:特征缩放 (Feature Scaling)](#4.3 重要预处理:特征缩放 (Feature Scaling))
- [4.4 代码实战:鸢尾花分类与 K 值的影响](#4.4 代码实战:鸢尾花分类与 K 值的影响)
- [4.5 KNN 的优缺点总结](#4.5 KNN 的优缺点总结)
-
- [✅ 优点](#✅ 优点)
- [❌ 缺点](#❌ 缺点)
- [4.6 KNN vs 逻辑回归 vs 线性回归](#4.6 KNN vs 逻辑回归 vs 线性回归)
- [4.7 本章小结](#4.7 本章小结)
第四章:直觉篇------基于距离的 K-近邻 (KNN) 算法
导读 :在前两章中,我们学习了线性回归和逻辑回归。这两种算法都有一个共同点:它们都需要通过训练"学习"出一组参数( w w w 和 b b b),形成一个明确的数学公式或模型。
但本章要介绍的 K-近邻算法 (K-Nearest Neighbors, KNN) 完全不同。它不学习任何公式 ,也没有训练过程。它的核心思想朴素而强大:"近朱者赤,近墨者黑"。如果你周围的邻居大多是好人,那你大概率也是好人。
本章基于文档《02_KNN算法.pdf》,带你领略这种"懒惰学习"的魅力。
4.1 核心思想:物以类聚,人以群分
KNN 是机器学习中最简单、最直观的算法之一。
工作原理
假设你有一个新来的数据点(比如一个未知的电影),想要知道它是"动作片"还是"爱情片"。
- 找邻居 :在已有的数据库里,找出离这个新电影最近 的 K K K 个电影。
- 看投票 :看看这
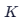 个邻居里,大多数是什么类型。
个邻居里,大多数是什么类型。 - 做决定 :如果
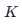 个邻居里有 4 个是动作片,1 个是爱情片,那么我们就判定新电影也是动作片。
个邻居里有 4 个是动作片,1 个是爱情片,那么我们就判定新电影也是动作片。
关键特点:懒惰学习 (Lazy Learning)
- 没有训练阶段:KNN 在"训练"时,只是把数据存起来而已。它不进行任何计算,不拟合任何曲线。
- 预测时才计算 :所有的计算工作都推迟到了预测(测试)阶段。当你给它一个新数据时,它才开始去计算距离、找邻居。
- 优点:模型适应性强,数据更新时无需重新训练。
- 缺点:预测速度慢,数据量大时计算量巨大。
4.2 三大核心要素
要让 KNN 正常工作,必须确定三个关键要素:
1. 距离度量 (Distance Metric)
怎么定义"近"?最常用的方法是 欧氏距离 (Euclidean Distance),也就是两点之间的直线距离。
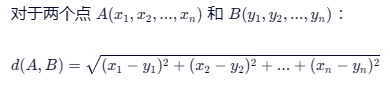
- 注:除了欧氏距离,还有曼哈顿距离(城市街区距离)、闵可夫斯基距离等,但欧氏距离最常用。
2. K 值的选择 (The Value of K)
K K K 代表我们要找几个邻居。 K K K 的选择对结果影响巨大:
- K 太小 (如 K=1) :
- 优点:模型非常灵活,能捕捉局部细节。
- 缺点 :容易受噪声 (异常点)干扰。如果那个唯一的邻居是个标错数据的异常点,你的预测就错了。这叫过拟合。
- K 太大 (如 K= 总样本数) :
- 优点:抗噪声能力强,结果稳定。
- 缺点 :忽略了局部特征,可能把少数类淹没在多数类中。如果数据集中 90% 是猫,无论来什么新数据,K 很大时都会预测为猫。这叫欠拟合。
- 如何选择 :通常通过交叉验证 ,尝试不同的 K K K 值(如 3, 5, 7, 9...),选择准确率最高的那个。一般取奇数,避免投票平局。
3. 分类决策规则
- 分类任务 :多数投票法 (Majority Voting)。哪个类别的邻居多,就选哪个。
- 回归任务 :平均值法。计算 K 个邻居目标值的平均数,作为预测结果。
4.3 重要预处理:特征缩放 (Feature Scaling)
这是 KNN 最容易踩的坑!
KNN 依赖距离计算。如果特征的**量纲(单位)**不一致,距离计算就会失真。
例子:
- 特征 A:年龄 (0 - 100 岁)
- 特征 B:年薪 (0 - 1,000,000 元)
计算距离时,年薪差 1000 元产生的平方差是 1,000,000,而年龄差 10 岁产生的平方差只有 100。
结果:年薪完全主导了距离计算,年龄特征几乎失效。
解决方案 :
在使用 KNN 之前,必须 进行标准化 (Standardization) 或 归一化 (Normalization),将所有特征缩放到相同的范围(如 0-1 之间,或均值为 0 方差为 1)。
4.4 代码实战:鸢尾花分类与 K 值的影响
我们将使用经典的鸢尾花数据集,并手动演示不同 K 值对决策边界的影响,以及特征缩放的重要性。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
# 1. 加载数据 (只取前两个特征以便可视化)
iris = load_iris()
X = iris.data[:, :2] # 花萼长度,花萼宽度
y = iris.target
# 2. 【关键步骤】特征缩放
# 如果不做这一步,KNN 的效果会大打折扣
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# 4. 探究 K 值的影响
k_range = range(1, 21)
scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
scores.append(accuracy_score(y_test, y_pred))
# 绘制 K 值 vs 准确率
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(k_range, scores, marker='o')
plt.title('K 值对准确率的影响')
plt.xlabel('K 值')
plt.ylabel('准确率')
plt.grid(True)
print(f"最佳 K 值: {k_range[np.argmax(scores)]}, 最高准确率: {max(scores):.4f}")
# 5. 可视化决策边界 (使用最佳 K 值)
best_k = k_range[np.argmax(scores)]
knn_best = KNeighborsClassifier(n_neighbors=best_k)
knn_best.fit(X_scaled, y)
# 生成网格点
h = 0.02
x_min, x_max = X_scaled[:, 0].min() - 1, X_scaled[:, 0].max() + 1
y_min, y_max = X_scaled[:, 1].min() - 1, X_scaled[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 预测网格点的类别
Z = knn_best.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.subplot(1, 2, 2)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Set1)
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=y, edgecolors='k', cmap=plt.cm.Set1)
plt.title(f'KNN 决策边界 (K={best_k})')
plt.xlabel('花萼长度 (标准化后)')
plt.ylabel('花萼宽度 (标准化后)')
plt.tight_layout()
plt.show()代码深度解析:
StandardScaler:我们首先对数据进行了标准化。如果你注释掉这一行,你会发现准确率可能会下降,且决策边界会变得奇怪(因为某个特征主导了距离)。- K 值搜索:我们遍历了 K=1 到 20,发现准确率是波动的。通常 K 在 3 到 10 之间表现较好。
- 决策边界图 :
- 背景色块代表模型预测的区域。
- 你会看到 KNN 的边界是不规则的、曲折的。这是因为它是基于局部邻居投票的,不像逻辑回归那样是一条平滑的直线。
- 这种不规则性让它能很好地适应复杂的数据分布,但也容易受到噪声点的干扰(边界出现细小的毛刺)。
4.5 KNN 的优缺点总结
✅ 优点
- 简单易懂:逻辑直观,无需复杂的数学推导,容易向非技术人员解释。
- 无需训练:新增数据直接加入数据集即可,无需重新训练模型。
- 适用于多分类:天然支持多类别分类,不需要像逻辑回归那样进行"一对多"改造。
- 非线性能力:能够处理复杂的非线性决策边界。
❌ 缺点
- 预测效率低 :每次预测都要计算与所有训练样本的距离。如果训练集有 100 万条数据,预测一次就要算 100 万次距离,速度极慢。
- 优化:可以使用 KD-Tree 或 Ball-Tree 等数据结构加速搜索。
- 对异常值敏感:尤其是当 K 值较小时,一个错误的标签就能改变预测结果。
- 对特征缩放敏感:必须进行归一化/标准化处理。
- 高维灾难:在特征维度非常高时,空间变得稀疏,"距离"的概念失效,所有点看起来都差不多远,导致算法失效。
- 样本不平衡问题:如果某一类样本数量特别多,大 K 值下小类别容易被淹没。
4.6 KNN vs 逻辑回归 vs 线性回归
| 特性 | 线性/逻辑回归 | KNN |
|---|---|---|
| 学习类型 | 急切学习 (Eager Learning):先训练出模型参数 | 懒惰学习 (Lazy Learning):不训练,预测时才算 |
| 决策边界 | 线性 (直线/平面),除非加多项式特征 | 非线性,形状复杂,局部适应性强 |
| 训练速度 | 慢 (需要迭代优化) | 快 (只是存数据) |
| 预测速度 | 快 (代入公式即可) | 慢 (需计算大量距离) |
| 可解释性 | 强 (权重代表影响程度) | 弱 (只能说是因为像邻居) |
| 适用场景 | 数据量大,需要快速预测,需要解释原因 | 数据量中小,决策边界复杂,对训练时间敏感 |
4.7 本章小结
- KNN 是基于距离 和投票的分类(或回归)算法。
- 它的核心在于K 值的选择 和距离的计算。
- 特征缩放是使用 KNN 前的必经之路。
- 它是一种"懒惰"但"灵活"的算法,适合小规模、复杂分布的数据,但在大数据量下预测性能较差。
至此,我们学习了三种监督学习算法:
- 线性回归:预测数值。
- 逻辑回归:二分类,基于概率。
- KNN:多分类,基于距离。
但是,如果数据没有标签 怎么办?比如我们有一堆用户数据,不知道他们属于哪一类,只想把他们分成几组以便进行差异化营销。这时候,监督学习就无能为力了,我们需要进入无监督学习的世界。
下一章预告:《第五章:探索篇------发现数据内在结构的聚类算法》,我们将学习如何在没有老师指导的情况下,让机器自动将数据分组(K-Means)。