概述
论文地址:https://arxiv.org/pdf/2403.10249
源码地址:https://github.com/BAAI-Agents/GPA-LM.git
本文指出,虽然以语言为中心或多模态的大规模模型(LMs)正在迅速发展,但对其能力和潜力缺乏系统的审查。本文尤其关注游戏场景,研究其现状,并找出悬而未决的问题。报告回顾了现有的基于 LM 的游戏代理(LMA)架构,并总结了其共性和面临的挑战。

介绍
大规模模型(LM)是语言模型和多模态模型的结合,它的发展推动了自然语言处理和计算机视觉领域的重大进步。这在文本生成、图像理解和机器人学等多个领域取得了显著成就。LM 在游戏场景中的应用尤其引人关注,目前正在研究其在复杂环境中的应用,如热门游戏 Minecraft。这是因为数字游戏提供了需要高级推理和认知能力的复杂挑战,在人工智能研究中具有重要意义:使用 LM 的游戏代理可能会比传统训练的代理表现出更有趣的泛化能力。然而,在这一领域仍有许多尚未解决的难题。为了应对这些挑战,我们研究了基于 LM 的游戏代理在感知、推理和行动阶段的表现,然后分析了共同面临的挑战和未来的研究方向。

审查
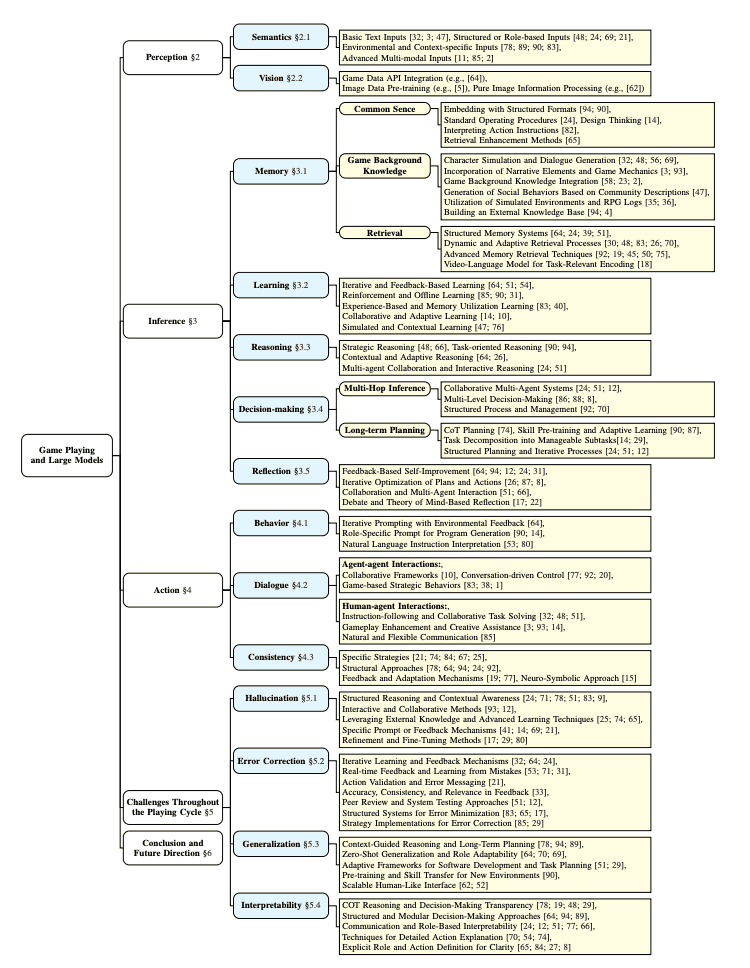
感知
多重输入--视觉、语义和音频--对于识别和思考游戏中出现的信息并选择行动非常重要。在游戏中,通过文字或音频来解决谜题或寻找隐藏信息是很常见的。数字游戏中的多模态信息整合可以带来更丰富的体验,但现有文献并不太关注如何将音频数据整合到模型中。这是未来的一个挑战。
此外,基于语义信息的识别主要依靠文本项目和自然语言指令,但这有其局限性。因此,我们需要处理更丰富语义信息的方法。在视觉方面,有多种不同的方法,例如将游戏相关信息纳入模型或使用图像和动作数据进行预训练。将这些方法结合起来,可以开发出更有效的游戏代理。
推理(推论)
语言模型(LM)可以作为智能代理认知框架的核心要素,包括自主性、反应性、自发性和社交性。然而,游戏的不同阶段都有特定的要求。在游戏的开始阶段,代理需要吸收有关游戏的重要常识和背景知识。然后,随着游戏的进行,代理的角色扩展到整合过去的游戏事件、管理知识和执行认知功能,如信息学习、推理、决策和反思。代理还不断更新或改进自己的知识,为未来的活动做好准备。
行动
本节将探讨语言模型(LM)表现出类似人类行为的方式。具体来说,本节重点讨论特定行为的执行、与人类或其他代理的交流,以及如何确保这些行为的一致性。
LM 在游戏中执行特定的操作。这包括基于文本的交互和决策,通过应用程序接口和预定义操作对游戏环境的操纵,以及通过直接控制进行操纵。LM 还能与人类和其他代理进行交流。这包括基于文本的对话和决策、通过游戏特定 API 进行的交互,以及通过输入设备(如鼠标和键盘)进行的直接操控。此外,LMs 还需要保持其行为和交流的一致性。这意味着要考虑到过去的行为和情况,并随着游戏的进行而改变行为。
这些元素允许 LM 在游戏中扮演不同的角色,并解决游戏的不同方面问题。
挑战
语言模型代理(LMA)游戏提出了几个重要的挑战。这些挑战包括消除错觉、纠错、泛化和增强可解释性。
首先,在消除错觉方面,LMA 可能会输出与原始信息不同的信息。这可能包括错误和不一致。为解决这一问题,可采用结构化推理、情景感知、互动方法以及特定的提示和反馈机制。其次,在纠错方面,必须找出识别和纠正 LMA 可能犯下的错误的方法。基于环境反馈的迭代反馈和迭代重新规划有助于纠正错误和提高准确性。此外,通用性是指 LMA 将在一种情况下学到的知识应用于其他情况和在新环境中执行任务的能力。这使 LMA 能够不断适应和解决新问题。
应对这些挑战的方法有很多,但有效的反馈机制和战略实施非常重要。这将提高 LMA 游戏的质量和效率,带来更流畅的游戏体验。
结论
本文以代理和语言模型(LMs)的结合为重点,对有关数字游戏的文献进行了调查,详细介绍了 LMAs 所面临的挑战及其解决方案,并为未来的研究提供了方向。本文特别强调在实时游戏环境中改进多模态感知和性能。这将有望带来更吸引人、更逼真的游戏体验。