在如今这个数据驱动的时代,中间件在性能测试中扮演着至关重要的角色。你是否曾听说过Kafka和MQ,却不清楚它们在实际应用中具体的作用是什么?让我们一起来揭开它们的神秘面纱。
Kafka和MQ究竟是什么?它们在性能测试中如何发挥作用,又为何成为现代分布式系统中的关键组成部分?

Kafka是一种分布式流处理平台,常用于构建实时数据管道和流式应用。它能够处理海量的数据流,并确保数据的高效传输和持久化。例如,在电商平台中,Kafka可以实时处理用户的行为数据,帮助企业做出及时的商业决策。
相比之下,MQ(Message Queue)是一种消息传递中间件,用于解耦和缓冲系统之间的数据传输。以银行系统为例,MQ可以在客户交易时,将交易信息缓冲处理,确保交易系统的稳定性和高效性。
在做项目的性能测试时,MQ和Kafka经常会是项目服务架构中非常重要的组成部分,负责处理大量的实时数据流,如日志收集、消息队列、事件流处理等,Kafka和MQ的性能会直接影响整个系统的表现。所以,我们做性能测试的时候经常也需要关注一下MQ中间件的性能。
消息队列【MQ】
消息队列,英文名:Message Queue,经常缩写为MQ。从字面上来理解,消息队列是一种用来存储消息的队列,我们可以简单理解消息队列就是将需要传输的数据存放在队列中。
而真正用来存储消息的软件(组件)叫做消息队列中间件。举个例子来理解,为了分析网站的用户行为,我们需要记录用户的访问日志。这些一条条的日志,可以看成是一条条的消息,我们可以将它们保存到消息队列中。将来有一些应用程序需要处理这些日志,就可以随时将这些消息取出来处理。
目前市面上的消息队列的中间件有很多,例如:Kafka、RabbitMQ、ActiveMQ、RocketMQ、ZeroMQ等。
MQ应用场景
1、异步处理
举例:电商网站中,新的用户注册时,需要将用户的信息保存到数据库中,同时还需要额外发送注册的邮件通知、以及短信注册码给用户。但因为发送邮件、发送注册短信需要连接外部的服务器,需要额外等待一段时间,这样就会造成用户的响应时间很长,体验很差:
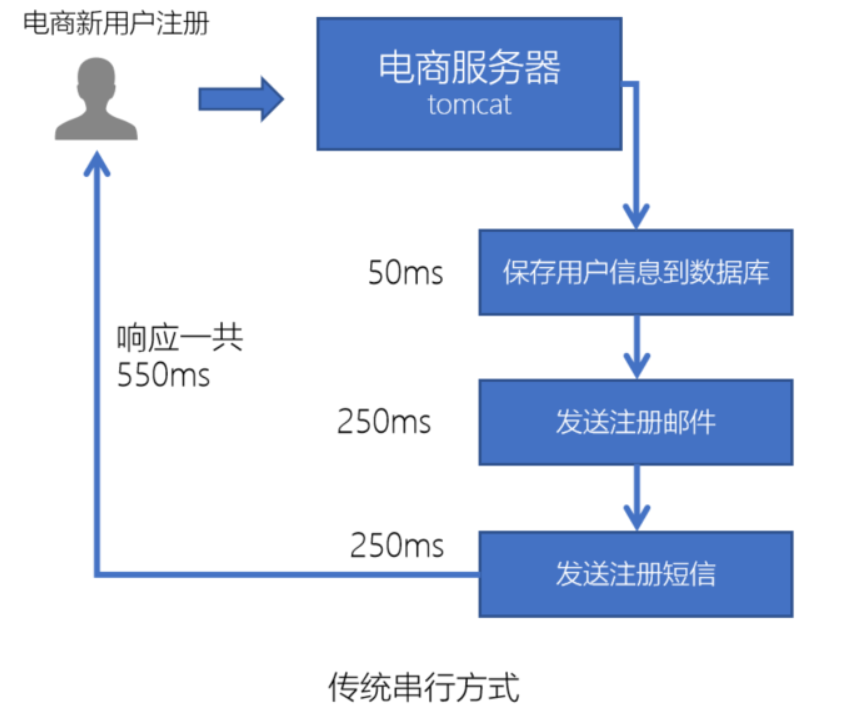
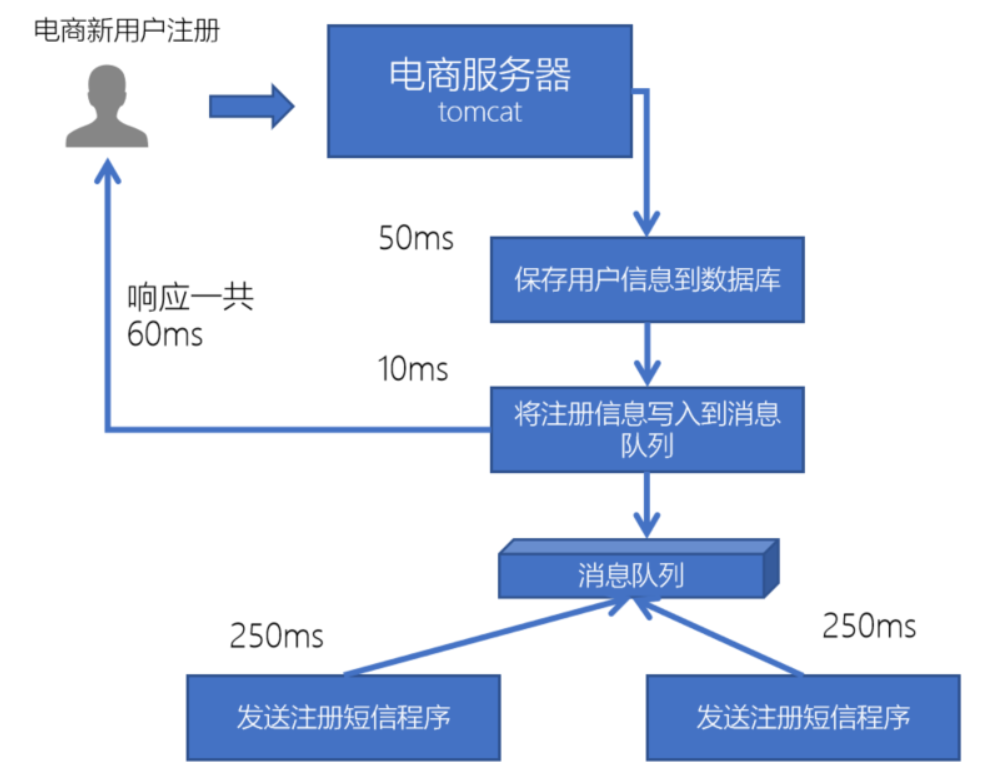
所以,此时我们就可以使用消息队列来进行异步处理,从而实现快速响应,提高用户的体验。
-
保存用户注册信息到数据库后,就直接返回给用户响应消息,这样用户就可以在非常短的时间里收到注册成功的使用体验;
-
而剩下的发送注册的邮件通知、以及短信注册码的消息写到消息队列里,跟用户收到回复信息的步骤异步执行,从而实现快速响应。
2、系统解耦
比如:用户秒杀需要下单,访问订单系统的时候订单系统需要保存用户的订单信息,并且调用接口访问库存系统,让库存系统同步减少库存;
在这个业务流程里,如果库存系统出现的问题,就会导致订单系统下单失败,而且如果库存系统接口修改了,会导致订单系统也无法工作了!这样的设计,会让两个系统之间的依赖性很强,系统出现问题的场景就会比较多。
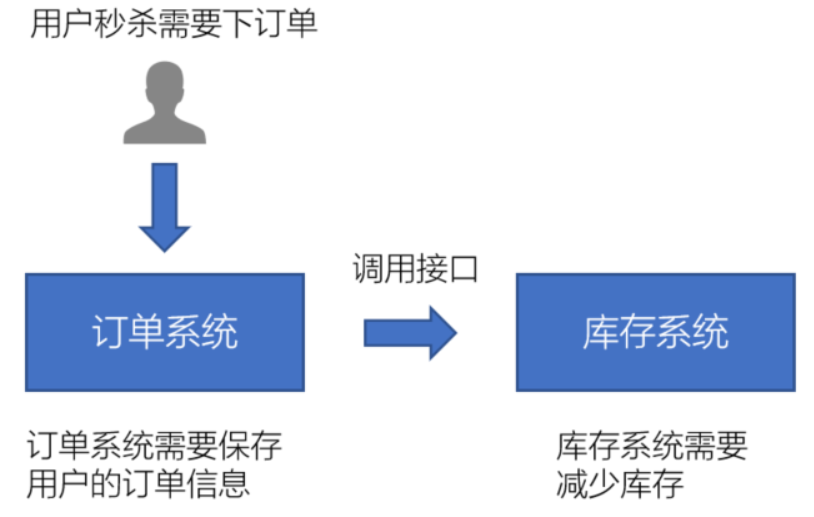
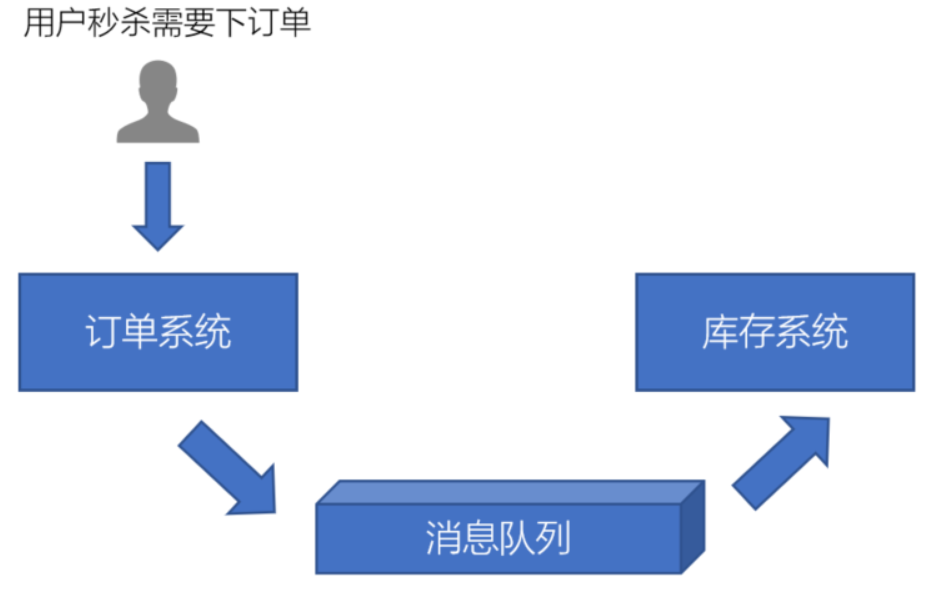
为了解决以上问题,我们可以使用消息队列来实现系统和系统之间的解耦。如下图所示:
-
订单系统不再调用库存系统的接口,而是把订单消息写到消息队列里;
-
库存系统从消息队列中拉取消息,然后再减库存,从而实现系统解耦,减少系统之间的依赖,降低问题出现的频率。
3、流量削峰
这个场景也比较常见,比如我们用12306抢火车票的时候:上亿的用户会同时对服务器发起请求,每一个请求都会去业务数据库里请求数据查询或者变更上的话,数据库压力就会很大;而且人越多反应越慢,用户可能越会疯狂刷新页面,这样会造成更大的并发,瞬间会压垮mysql。
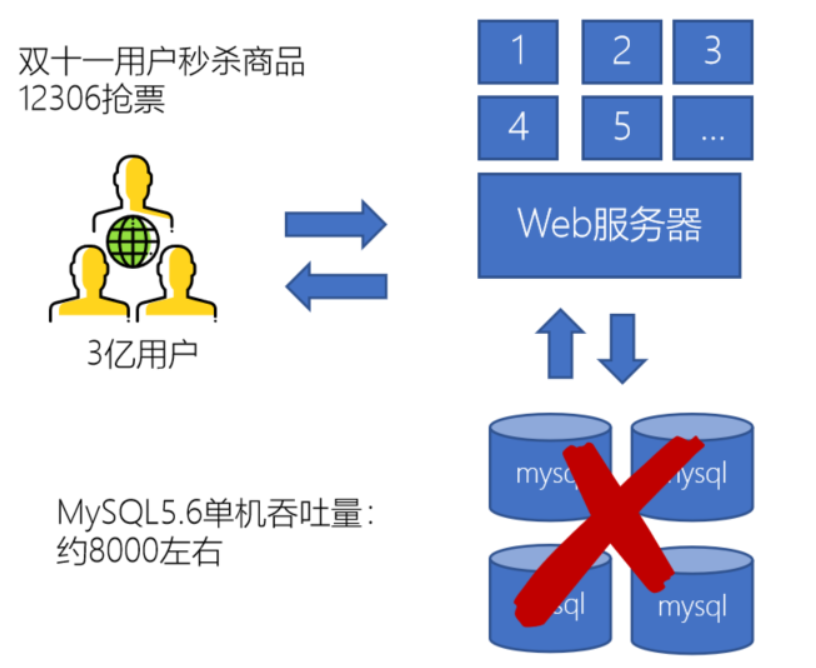
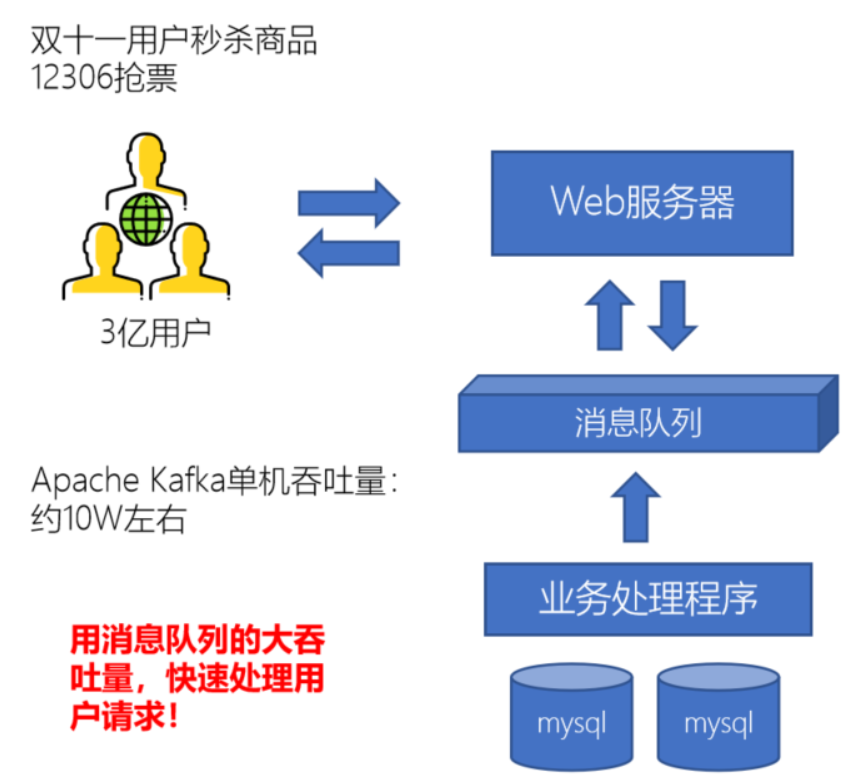
所以,为了解决以上的问题,我们同样可以使用消息队列,因为消息队列的吞吐量比起业务数据库的吞吐来你跟要大很多:mysql数据库的吞吐量大概8000左右,消息队列比如kafka中间件的吞吐量大概在10w左右。用户发给服务器的请求,服务器先发给消息队列,然后立马可以给用户返回,用户端能看到的信息就可能是在排队中。这样用户有收到响应就不会疯狂刷新页面,造成更大的压力了。
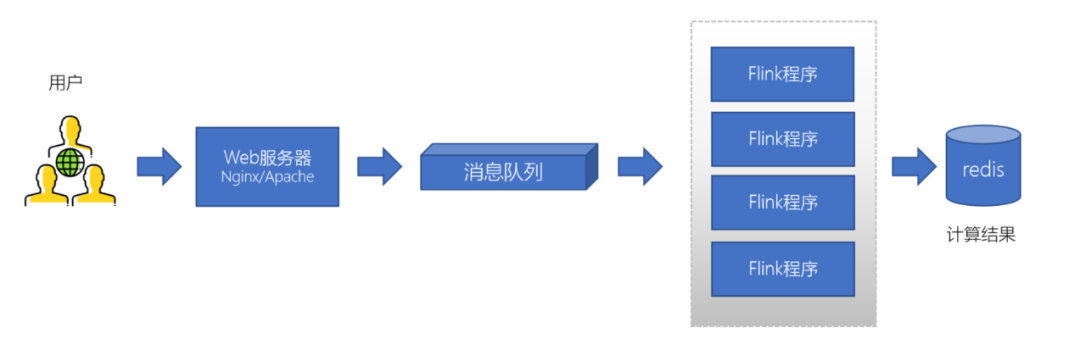
4、日志处理
大型电商网站(淘宝、京东、国美、苏宁...)、App(抖音、美团、滴滴等)等需要分析用户行为,要根据用户的访问行为来发现用户的喜好以及活跃情况,需要在页面上收集大量的用户访问信息。
Kafka
了解了消息队列之后,kafka作为MQ中非常主流的一个的中间件,我们来介绍一下kafka。
kafka是一个分布式、高吞吐量、高扩展性的消息队列系统。主要应用在日志收集系统和消息系统,也可以叫做KafkaMQ。总之,Kafka比其他消息队列要好一点,优点也比较多,稳定性和效率都比较高。
kafka的诞生背景
kafka的诞生,是为了解决linkedin的数据管道问题,起初linkedin采用了ActiveMQ来进行数据交换,大约是在2010年前后,那时的ActiveMQ还远远无法满足linkedin对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,linkedin决定研发自己的消息传递系统,当时linkedin的首席架构师jay kreps便开始组织团队进行消息传递系统的研发。
在大数据技术领域,一些重要的组件、框架都支持Apache Kafka,不论成成熟度、社区、性能、可靠性,Kafka都是非常有竞争力的一款产品。
kafka的重要概念
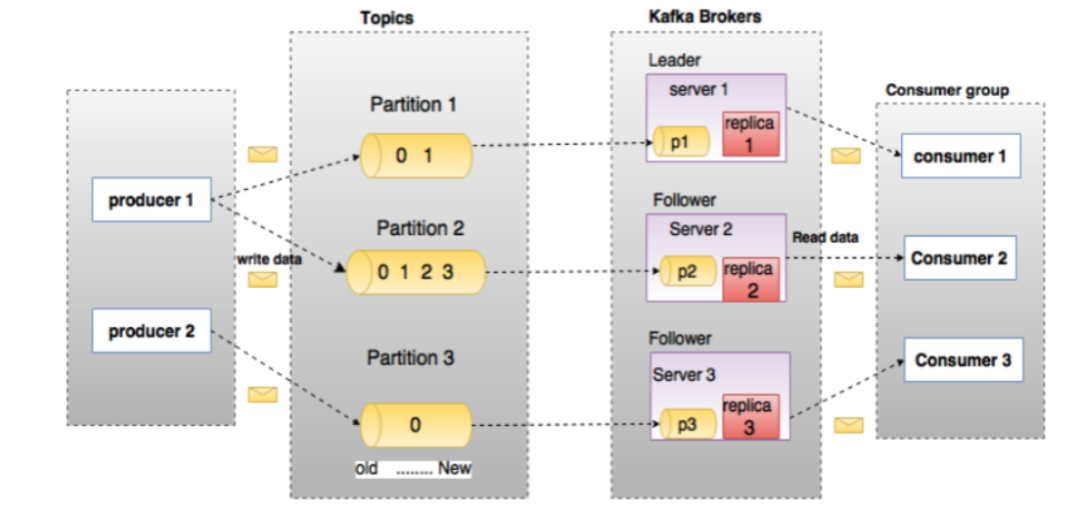
1)producer(生产者):生产者就是发送消息的,生产者每发送一个条消息必须有一个Topic(主题),也可以说是消息的类别,生产者源源不断的向kafka服务器发送消息。
2)Topic(主题):每一个发送到Kafka的消息都有一个主题,也可叫做一个类别,类似我们传统数据库中的表名一样,比如说发送一个主题为order的消息,那么这个order下边就会有多条关于订单的消息,只不过kafka称之为主题,都是一样的道理;
3)Partition(分区):生产者发送的消息数据Topic会被存储在分区中,这个分区是想把数据分成多个块,达到负载均衡,合理的把消息分布在不同的分区上,分区是被分在不同的B服务器上,这样我们大量的消息就实现了负载均衡。每个Topic可以指定多个分区,但是至少指定一个分区。每个分区存储的数据都是有序的,不同分区间的数据不保证有序性。因为如果有了多个分区,消费数据的时候肯定是各个分区独立开始的,有的消费得慢,有的消费得快肯定就不能保证顺序了。那么当需要保证消息的顺序消费时,我们可以设置为一个分区,只要一个分区的时候就只能消费这个一个分区,那自然就保证有序了。
4) Replica(副本):副本就是分区中数据的备份,是Kafka为了防止数据丢失或者服务器宕机采取的保护数据完整性的措施,一般的数据存储软件都应该会有这个功能。如果有某些服务器宕机,我们可以通过副本恢复数据,也可以暂时用副本中的数据来使用。
5)Broker(实例或节点):就是Kafka的实例,启动一个Kafka就是一个Broker,多个Brokder构成一个Kafka集群,这就是分布式的体现,服务器多了自然吞吐率效率啥的都上来了。
6)Consumer Group(消费者组)和 Consumer(消费者):Consume消费者来读取Kafka中的消息,可以消费任何Topic的数据,多个Consume组成一个消费者组,一般的一个消费者必须有一个组(Group)名,如果没有的话会被分一个默认的组名。
如下图就包括了2个Producer(生产者),一个Topic(主题),3个Partition(分区),3个Replica(副本),3个Broker(Kafka实例或节点),一个Consumer Group(消费者组),其中包含3个Consumer(消费者)
kafka 在性能测试中的应用场景
1、在什么样的项目里需要关注kafka的性能?
如果 Kafka 是项目中数据流处理的核心部分,负责处理大量的实时数据流,如日志收集、消息队列、事件流处理等,或者项目需要处理高吞吐量数据的场景中,Kafka 的性能会直接影响整个系统的表现。如果系统依赖 Kafka 处理和传递大量消息,测试 Kafka 的吞吐量、延迟等指标是至关重要的。
2、在性能测试或实际生产环境中,以下一些关键指标的异常可能表明 Kafka 出现了问题,我们需要去分析和调优:
1) 吞吐量下降:系统整体的消息处理速度明显下降,即每秒处理的消息数量减少。Kafka 的生产者或消费者无法以预期的速度发送或接收消息。
可能原因:
-
Kafka 集群的带宽或 I/O 达到瓶颈,导致无法处理更多的消息。
-
分区数不足或副本同步速度过慢,导致生产者和消费者的处理速度受到限制。
-
内部队列(如 Broker 的缓冲区或网络层队列)积压,导致吞吐量下降。
2)消息延迟增加:从生产者发送消息到消费者接收到消息的时间(端到端延迟)显著增加。
可能原因:
-
Kafka 的内部缓冲区或日志队列积压,导致消息在 Broker 内部的处理变慢。
-
网络延迟或带宽不足,导致生产者或消费者与 Broker 之间的通信变慢。
-
由于 Kafka 的副本同步问题(例如 ISR 列表中有节点失效),导致消息在写入时需要等待其他副本的同步,增加延迟。
3)消费者滞后(Lag)增加:Kafka 消费者滞后明显增加,即消费者无法及时处理已提交到 Kafka 的消息,造成未消费的消息积压。
可能原因:
-
消费者的处理能力不足,无法跟上生产者的消息发送速度。
-
Kafka Broker 处理负载过高,导致消息无法及时发送到消费者。
-
分区分配不均或消费者群组配置不当,导致部分分区处理速度远慢于其他分区。
4)磁盘 I/O 使用率过高:Kafka Broker 的磁盘 I/O 使用率接近或达到100%,导致系统性能下降。
可能原因:
-
Kafka 日志文件的写入和清理操作频繁,导致磁盘 I/O 成为瓶颈。
-
Kafka 配置不当,如日志分段(log segment)过小,导致频繁的日志文件创建和删除操作。
-
大量的持久化消息写入操作占用了磁盘带宽,影响到 Kafka 的正常运行。
5)CPU 使用率过高:Kafka Broker 的 CPU 使用率持续高企,导致其他任务无法顺利执行。
可能原因:
-
Kafka Broker 在处理大量请求(如高频的生产和消费操作)时占用大量 CPU 资源。
-
数据压缩或解压缩、加密或解密操作过多,导致 CPU 资源紧张。
-
不合理的批量设置或频繁的上下文切换,导致 CPU 负载过高。
6)网络带宽占用率过高:Kafka Broker 的网络带宽使用接近或达到上限,导致消息传输延迟或丢包。
可能原因:
-
高频的数据传输或大量副本同步操作导致网络带宽不足。
-
生产者和消费者之间的数据传输过于频繁,超过了网络的处理能力。
-
Kafka 集群中节点之间的副本同步流量过大,影响了生产和消费的正常流量。
7)高频率的垃圾回收(GC)活动:Kafka Broker 出现频繁的垃圾回收活动,导致系统停顿和性能下降。
可能原因:
-
Kafka 配置的内存(heap size)过小,导致 JVM 频繁进行 GC 操作。
-
Kafka 的内存管理不当,导致内存碎片或大量对象驻留在堆内存中。
-
由于高负载或错误的配置,Kafka Broker 产生了大量短生命周期的对象,增加了 GC 负担。
8)高频率的 ISR 列表变动:Kafka 的 ISR(In-Sync Replica)列表频繁变动,导致分区副本状态不稳定。
可能原因:
-
Kafka 集群中的某些 Broker 出现网络问题或资源不足,导致副本掉线和恢复频繁发生。
-
磁盘 I/O 性能问题或网络延迟导致副本无法及时同步数据,进而被移出 ISR 列表。
-
配置了过短的超时设置(如 **
replica.lag.time.max.ms),导致副本被频繁踢出 ISR 列表。
9)消息丢失或重复:系统中出现了消息丢失或重复消费的现象,影响了数据的一致性。
可能原因:
-
Kafka 的副本机制或事务性配置未正确设置,导致在 Broker 故障或重启时发生消息丢失。
-
消费者配置错误,导致在重新平衡时重复消费消息。
-
生产者在发送消息时未正确处理
acks设置,导致消息未被可靠接收。
10)集群的稳定性下降:Kafka 集群中频繁出现节点失效、分区不可用、重新平衡等现象。
可能原因:
-
Kafka Broker 配置不当或硬件资源不足,导致在高负载下节点失效。
-
网络问题导致 Kafka 集群中的节点无法正常通信,引发集群不稳定。
-
副本数量配置不足,导致在节点失效时,分区不可用。
随着企业对数据实时性和系统可扩展性要求的提升,Kafka和MQ的应用场景越来越广泛。在大数据和云计算的推动下,企业纷纷采用这类中间件来提高系统性能和数据处理能力。同时,这也反映了现代企业在应对复杂业务需求时,越来越注重系统架构的稳定性和灵活性。
如果你正在考虑如何优化企业的性能测试和数据处理,不妨了解一下Kafka和MQ。这些中间件不仅能够提升系统的可靠性,还能帮助你更好地应对大规模数据处理的挑战。
Kafka和MQ作为现代分布式系统中的重要中间件,正在帮助越来越多的企业实现数据的高效传输和系统的性能优化。理解它们的工作原理和应用场景,不仅能提升你在性能测试中的技能,还能为你在大数据时代的职业发展铺平道路。
