Topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Prodcuer生产的数据,Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment,每个segment包括:".index文件"、".log"文件和.timeindex等文件,这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号,例如first-0,(server.properties文件里面log.dirs的路径下可以找到该文件夹)
一个topic分为多个partition
一个partition分为多个segment
一个segment由如下部分组成:
.log 日志文件(存储实际数据)
.index 偏移量索引文件
.timeindex 时间戳索引文件
其他文件
说明:index和log文件以当前segment的第一条消息的offset命名
这里的配置如下:
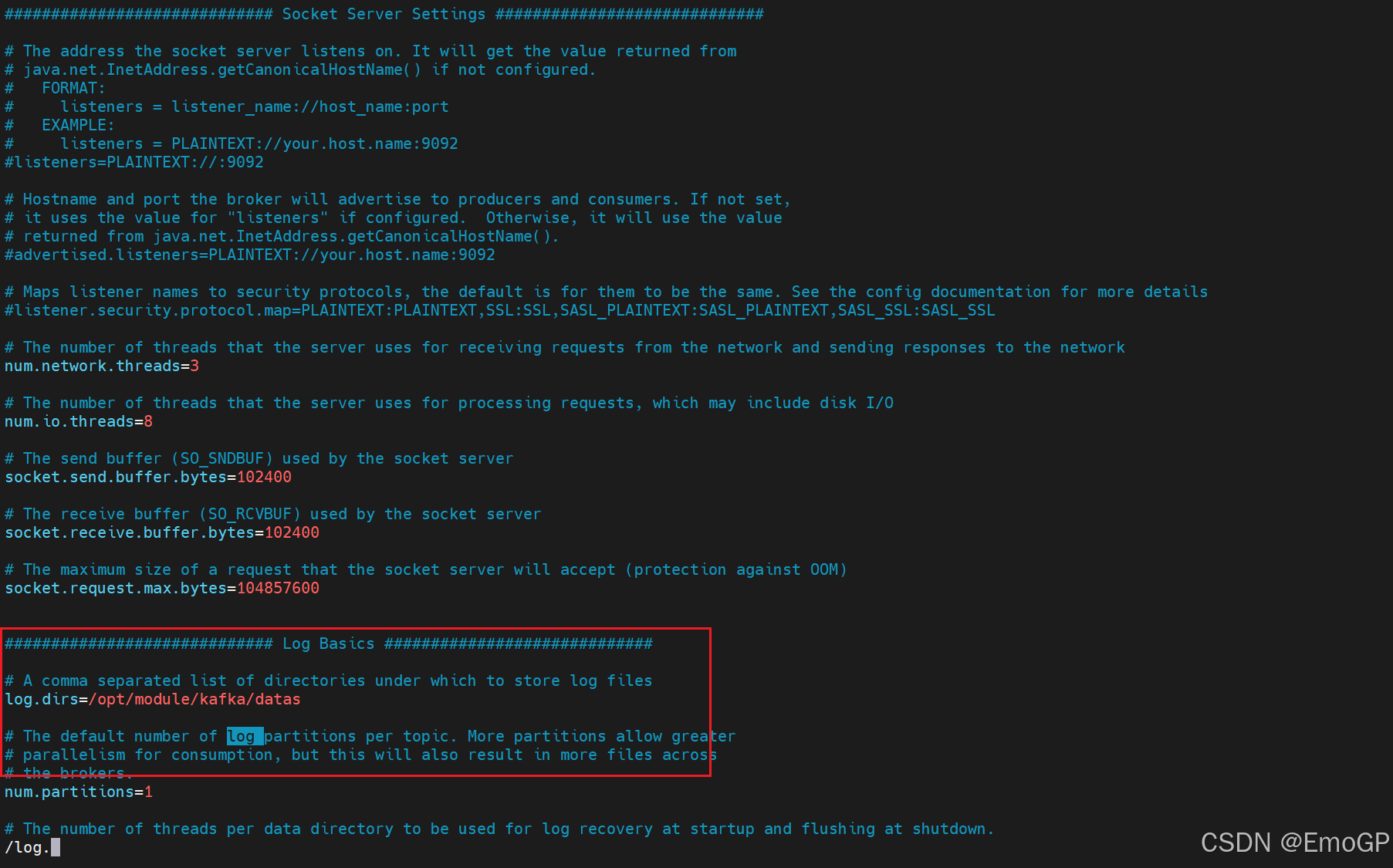
查看文件:
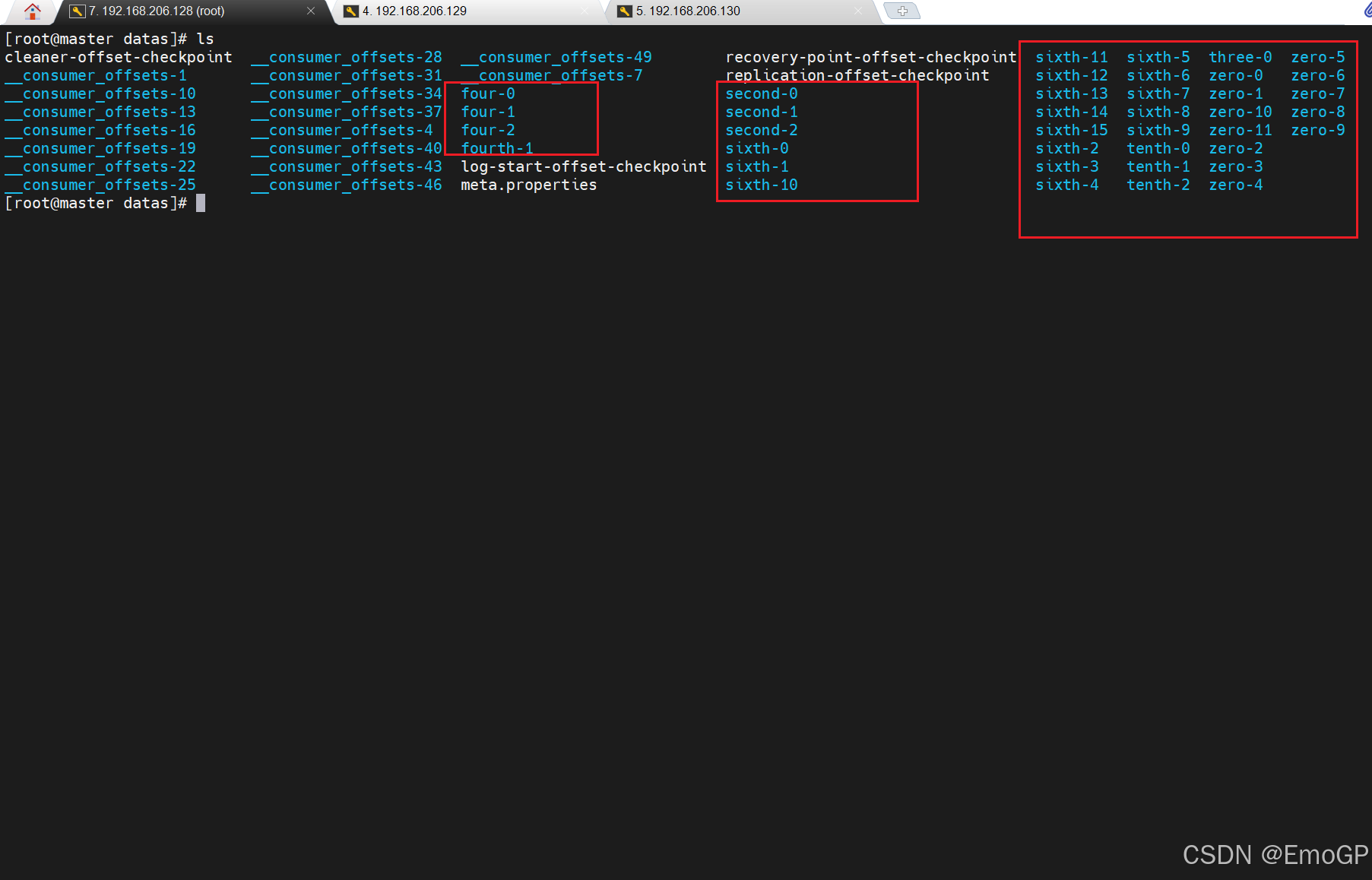
查看topic为four,0号分区的数据
直接查看log日志和index文件是乱码
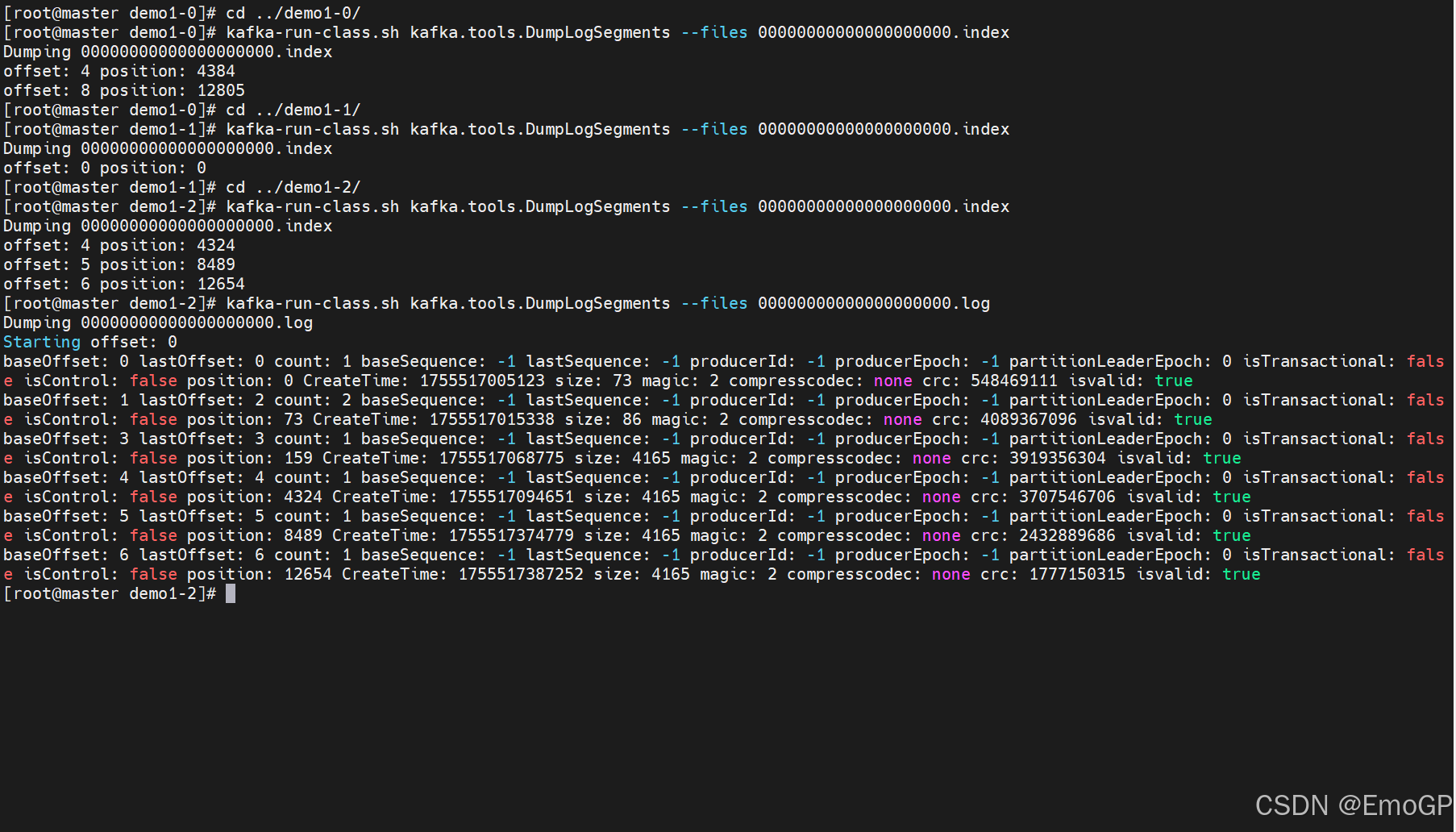
可以通过工具查看index和log信息
c
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.index
注意:
index为稀疏索引,大约每往log文件写入4kb数据,会往index文件写入一条索引,参数log.index.interval.bytes默认为4kb
index文件中保存的offset为相对offset,这样能确保offset的值所占空间不会过大,因此能将offset的值控制在固定大小
- 根据目标offset定位segment文件
- 找到小于等于目标offset的最大offset对应的索引项
- 定位到log文件
- 向下遍历找到目标Record
创建topic

创建生产者:
创建生产者:

生产并消费数据
查看数据: