8.高速缓冲存储器Cache
文章目录
高速缓冲存储器简称 Cache ,位于主存和CPU之间,用来存放正在执行的程序段和数据,以便CPU能高速地使用它们。
Cache的存取速度可与CPU的速度相匹配,但存储容量小、成本高、集成度低。
目前的计算机通常将它们制作集成在CPU中,用SRAM实现。
8.1局部性原理
局部性原理:cache能够有效工作的理论依据。
高速缓冲技术就是利用程序访问的局部性原理,把程序中正在使用的部分存放在一个高速的、容量较小的Cache中,使CPU的访存操作大多数针对Cache进行,从而大大提高程序的执行速度。
8.1.1空间局部性
在最近的未来要用到的信息,很可能与现在正在使用的信息在存储空间上是邻近的(相邻信息),因为指令通常是顺序存放、顺序执行的,数据一般也是以向量、数组等形式簇聚地存储在一起的。
8.1.2时间局部性
在最近的未来要用到的信息,很可能是现在正在使用的信息(同一个信息),因为程序中存在循环。

例:假定数组元素按行优先方式存储,对于下面的两个函数:
cpp程序A: int sumarrayrows( int a[M][N] ) { int i,j,sum=0; for( i=0;i<M;i++ ) for( j=0;j<N;j++ ) sum+=a[i][j]; return sum; } 程序B: int sumarraycols( int a[M][N] ) { int i,j,sum=0; for( j=0;j<N;j++ ) for( i=0;i<M;i++ ) sum+=a[i][j]; return sum; }(1)对于数组a的访问,哪个空间局部性更好?哪个时间局部性更好?
(2)对于指令访问来说,for循环体的空间局部性和时间局部性如何?
答案:(1)程序A对数组a的访问顺序与存放顺序是一致的,因此空间局部性好。程序B对数组a的访问顺序与存放顺序不一致,因而没有空间局部性。两个程序的时间局部性都很差,因为每个数组元素都只被访问一次。
(2)对于for循环体,程序A和程序B中的访问局部性是一样的。因为循环体内指令按序连续存放,所以空间局部性好;内循环体被连续重复执行,因此时间局部性也好。
8.2性能指标
- 命中率 H:CPU想访问的信息已经在Cache比率。
H = N c N c + N m H=\frac {N_c}{N_c+N_m} H=Nc+NmNc
一个程序执行中:
N c N_c Nc:访问cache的总2次数。
N m N_m Nm:访问主存的总次数。
- 缺失(未命中)率 M :M = 1 - H
- 平均访问时间 Ta
有2种策略:
t c t_c tc:命中cache的访问时间
t m t_m tm:未命中的访问时间(这里的未命中而不是访问主存的时间)
- 同时访问Cache和主存:
T a = H ⋅ t c + ( 1 − H ) ⋅ t m T_a = H · t_c + (1-H) · t_m Ta=H⋅tc+(1−H)⋅tm
- 先访问Cache,再访问主存:
T a = H ⋅ t c + ( 1 − H ) ⋅ ( t c + t m ) T_a = H · t_c + (1-H) · (t_c+t_m) Ta=H⋅tc+(1−H)⋅(tc+tm)
- 系统的效率 e
e = t c T a e=\frac {t_c}{T_a} e=Tatc
【例】假设Cache的速度是主存的5倍,且Cache的命中率为95%,则采用Cache后,存储器性能提高多少(设Cache和主存同时被访问,若Cache命中则中断访问主存)?
解:设Cache的存取周期为t,则主存的存取周期为5tCache和主存同时访问,不命中时访问时间为5t故系统的平均访问时间为Ta=0.95×t+0.05×5t = 1.2t
设每个周期可存取的数据量为S,则存储系统带宽为S/1.2t ,不采用cache时的带宽为S/5t
S 1.2 t S 5 t = 5 t 1.2 t u ≈ 4.17 \cfrac {\cfrac {S}{1.2t}}{\cfrac {S}{5t}}=\cfrac {5t}{1.2t}u≈4.17 5tS1.2tS=1.2t5tu≈4.17因为是使用cache是不使用的4.17倍,所以要减去1,提高了3.17倍。
❗8.3主存映射(查策略)
详见《计算机组成原理》唐朔飞,高等教育出版社
| 存放方式 | 直接映射 | 全相联映射 |
|---|---|---|
| 命中率 | 最低 | 最高 |
| 判断开销 | 最小 | 最大 |
| 所需时间 | 最短 | 最长 |
| 标记所占的额外空间开销 | 最少 | 最大 |
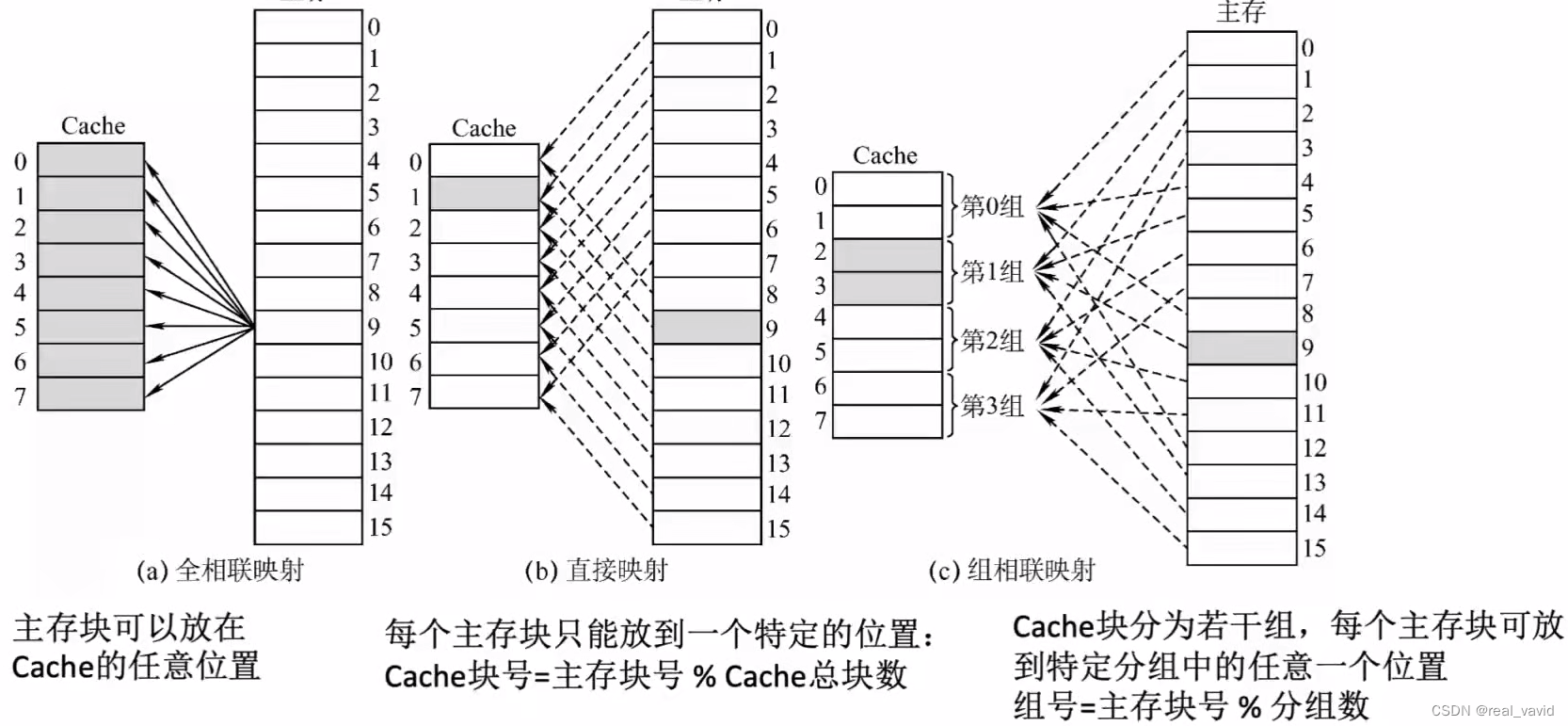
8.3.1全相联映射
空的位置随意放
- 优点:Cache块的冲突概率低,空间利用率高,命中率高。
- 缺点:标记的比较速度较慢,实现成本较高,需采用昂贵的按内容寻址的相联存储器进行地址映射。

地址结构:
| 标记 | 块内地址 |
|---|
8.3.2直接映射
对号入座:主存中的每一块只能装入Cache中的唯一位置。若这个位置已有内容,则产生块冲突,原来的块将无条件地被替换出去(无须使用替换算法)。
- 缺点:直接映射的块冲突概率最高,空间利用率最低。


地址结构:
| 标记 | Cache行号 | 块内地址 |
|---|
8.3.3组相联映射
按号分组,在自己组内随便放:将Cache空间分为大小相同的组,主存的一个数据块可以装入一组内的任何一个位置。

地址结构:
| 标记 | 组号 | 块内地址 |
|---|
CPU访存过程
首先根据访存地址中间的组号找到对应的Cache组;将对应Cache组中每个行的标记与主存地址的高位标记进行比较;若有一个相等且有效位为1,则访问Cache命中, 此时根据主存地址中的块内地址,在对应Cache行中存取信息;
若都不相等或相等但有效位为0,则不命中,此时CPU从主存中读出该地址所在的一块信息送到对应Cache组的任意一个空闲行中,将有效位置。
8.4替换算法
Cache很小,主存很大。如果Cache满了,那么就需要使用替换算法来替换数据。

8.4.1随机算法(RAND)
随机算法(RAND, Random):若cache已满,则随机选择一块替换。
实现简单,但完全没考虑局部性原理,命中率低,实际效果很不稳定。
8.4.2先进先出算法(FIFO)
先进先出算法 (FIFO, First In First Out):若Cache已满,则替换最先被调入Cache的块。

FIFO算法实现简单,最开始按#0#1#2#3放入cache,之后轮流替换#0#1#2#3。
FIFO依然没考虑局部性原理,最先被调入Cache的块也有可能是被频繁访问的。
抖动现象:频繁的换入换出现象(刚被替换的块很快又被调入)。
❗8.4.3近期最少使用(LRU)
近期最少使用算法 (LRU , Least Recently Used):为每一个Cache块设置一个"计数器",用于记录每个Cache块已经有多久没被访问了。当cache满后替换"计数器"最大的。

这里命中了,然后比其低的计数器 +1,因为计数器的目的是用于寻找计数器最大的cache块。而这3已经是最大了,3+1=4也就没有意义,因为3足以判断找出计数器最大的cache块,所以3加1是没有意义的,所以这里不用加1。
【总结】Cache块的总数=2n,则计数器只需 n 位。且Cache装满后所有计数器的值一定不重复。
LRU算波基于"局部性原理"。近期被访问过的主存块,在不久的将来也很有可能被再次访间,因此淘汰最久没被访问过的块是合理的。LRU算法的实际运行效果优秀,Cache命中率高。
但是若被频繁访问的主存块数量 > Cache行的数量,则还是有可能发生"抖动 "。
如:{1,2,3,4,5,1,2,3,4,5,1,2...}
【技巧】做题小妙招,可以看主存块前面的有哪些主存块,那么最后没有出现的那一个就是要替换的cache块。

8.4.4最近不经常使用(LFU)
最不经常使用算法 (LFU, LeastErequentlyUsed):为每一个Cache块设置一个"计数器",用于记录每个cache块被访问过几次。当Cache满后替换"计数器"最小的。

若有多个计数器最小的行,可按行号递增、或者FIFO策略进行选择。
LFU算法:曾经被经常访问的主存块在未来不一定会用到(如:微信视频聊天相关的块),并没有很好地遵循局部性原理,因此实际运行效果不如LRU。
8.5Cache写策略
读操作不会导致cache和主存的数据不一致,但是写操作会导致。
- 写命中
- 写回法
- 全写法
- 写不命中
-
写分配法
-
非写分配法
-
8.5.1写命中
1)写回法
写回法(write-back):当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。
未修改的块不用写回。
减少了访存次数,但存在数据不一致的隐患。

2)全写法
全写法 (写直通法,write-through):当CPU对Cache写命中时,必须把数据同时写入Cache和主存,一般使用写缓冲(write buffer)。
访存次数增加,速度变慢,但更能保证数据一致性。
但如果使用写缓冲,CPU写的速度很快,若写操作不频繁,则效果很好。若写操作很频繁,可能会因为写缓冲饱和而发生阻塞。

暂时放到写缓冲中,当CPU去做其他任务,这时候会有一个专门的电路把修改同步到主存。
8.5.2写不命中
1)写分配法
写分配法(write-allocate):有CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改。
通常搭配写回法使用。
2)非写分配法
非写分配法(not-write-allocate):当CPU对Cache写不命中时,直接写入主存,不调入Cache。
通常搭配全写法使用。
8.6多级Cache
现代计算机常采用多级Cache。
L1, L2, L3...
离CPU越近的速度越快,容量越小;
离CPU越远的速度越慢,容量越大。