《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,全书共分10章,第1章主要让读者认识数据资产,了解数据资产相关的基础概念,以及数据资产的发展情况。第2~8章主要介绍大数据时代数据资产管理所涉及的核心技术,内容包括元数据的采集与存储、数据血缘、数据质量、数据监控与告警、数据服务、数据权限与安全、数据资产管理架构等。第9~10章主要从实战的角度介绍数据资产管理技术的应用实践,包括如何对元数据进行管理以发挥出数据资产的更大潜力,以及如何对数据进行建模以挖掘出数据中更大的价值。
图书介绍:数据资产管理核心技术与应用
今天主要是给大家分享一下第五章的内容:
第五章的标题为数据服务
内容思维导图如下:
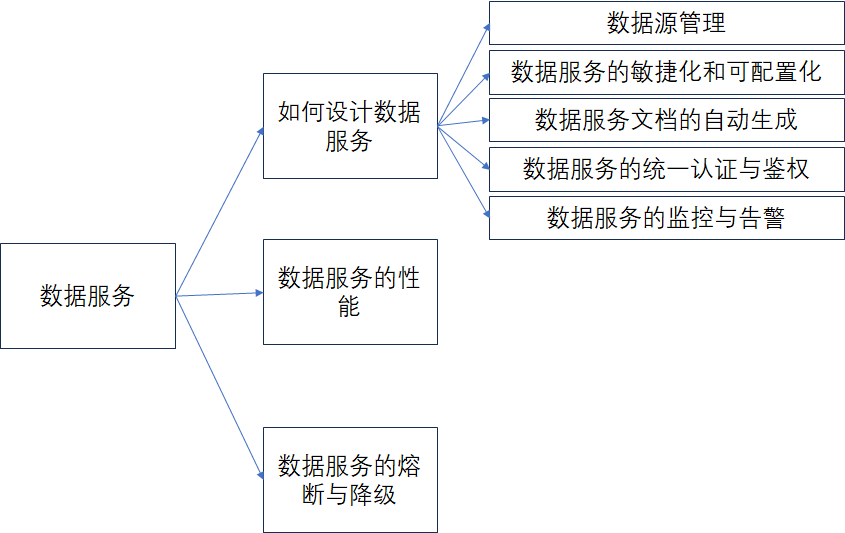
在数据资产中,数据服务是对外提供使用和访问的一种最重要的形式,数据只有提供对外的访问,才能体现其自身的价值。而且有了数据服务后也可以降低外部业务或者用户使用数据的门槛,对于用户来说提供了如下的便利。
- 不需要用户自己花时间从数据资产中去检索数据。
- 不要用户自己考虑怎么来获取自己已经检索到的数据。
- 不需要考虑获取数据时的网络安全等问题。
- 数据服务可以复用于多个用户和业务。
- 用户不需要关注技术细节,可以专注于数据服务的具体需求。
另外数据质量以及数据的监控与告警,会直接决定数据服务的质量,因为如果数据质量低下以及数据在存在问题时不能及时得到监控与告警,这样数据服务被用户访问时,就无法获取到准确的数据。
《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
1、如何设计数据服务
在传统的API接口服务中,通常会面临如下的一些问题:
- 一个普通的接口服务通常需要数据ETL开发工程师按照数据产品经理提供的业务逻辑进行数据处理加工得到最终的结果数据,然后再由后端开发工程师开发接口服务,并且输出接口服务的文档,之后再让业务通过接口来获取最终的结果数据。由于经过的环节很多,导致时间周期一般需要很长,如下图所示。
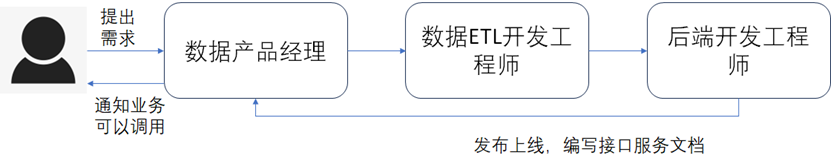
- 当业务众多时,对外输出的数据接口服务势必也会很多,随着人员的交替、数据需求逻辑的变更等,数据服务的管理会非常困难,需要维护的接口数量越来越多,运维成本非常大。
- 通常在时间久了后,由于业务方以及数据服务开发和运维人员的交替,会遇到每个数据服务有哪些业务在调用、每个业务的调用量有多少、数据服务在变更和升级时,需要通知到哪些业务等众多繁琐的问题。
所以数据服务的设计非常的重要,在设计时,通常需要考虑如下问题:《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
- 数据服务的敏捷化和可配置化:敏捷化是指数据服务可以随着业务需求的变化,能快速的进行修改和变更。可配置化是指数据服务不需要使用太多的代码开发,而是根据配置SQL查询逻辑、配置请求的入参和响应报文,就能快速生成一个对外使用的数据服务。
- 数据服务API文档可自动生成:能根据数据服务的请求入参和响应报文,自动生成API文档,不需要后端开发工程师每次手动进行编写,而且手动编写文档还极易出错,并且每次变更时都需要及时更新和维护。
- 数据服务的流程化管理:流程化管理是指可以在一个平台上完成数据服务调用的申请、审批、开发、上线、监控、告警等环节,方便数据服务的运维与管理。
- 数据服务的统一鉴权设计:所有的数据服务采用相同的统一鉴权方式,方便以后的运维和管理。
- 数据服务的性能以及熔断:性能是数据服务最重要的一项指标,因为如果性能不达标的话,那就无法满足业务的查询要求。熔断是指当数据服务的调用量过大或者发生了大量异常时,为了保护数据服务的整体稳定性,而触发的一种降级机制。
- 数据服务的监控与告警:数据服务在发生问题时,能通过监控与告警及时让运维或者开发人员进行处理,降低数据服务的问题给业务带来的影响。数据服务如果自身没有监控与告警,在发生问题时,可能就需要通过业务使用时主动来报出服务不可用的问题。
为了解决上述的问题,在大数据资产中,一般建议对数据服务进行平台化设计。开发一个数据服务API 通常的流程如下图所示。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著

上述的这些流程,在做数据服务的平台化设计时,都可以考虑进去,这样通过平台化的管理,就可以达到数据服务的敏捷化开发以及开发时可以基于平台快速配置来生成外部访问需要的数据服务节省人力的成本开销以及缩短开发的周期。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
在平台化的统一管理下,自然就可以在创建数据服务或者变更数据服务时,自动来生成API文档。也可以对数据服务进行统一的鉴权以及监控与告警。
1.1、数据源管理
数据源是数据服务的基础,没有数据源,自然也就无法提供数据服务。数据源的来源可以是多种多样的。数据仓库、数据湖、常见的各种类型的关系型数据库等都可以是数据服务的数据源。而且创建好的一个数据源也可以让多个数据服务共同使用,如下图所示。

在数据服务的平台化建设中,数据源管理的关键就在于需要去适配多种不同的数据源,而每一种数据源通常都有自己专有的数据驱动。所以数据服务平台在底层技术实现时需要能支持动态的去根据不同的数据源加载不同的数据驱动来达到创建数据源连接的目的,如下图所示。

1.2、 数据服务的敏捷化和可配置化
数据服务的敏捷化和可配置化主要体现在能随着业务需求的变化而快速的开发、修改对应的数据服务。而要达到快速响应需求的提出或者变更,将数据服务设计成能配置SQL查询逻辑或者低代码的逻辑脚本、能配置请求的入参和响应报文便是一种最好的解决方式,如下图所示为建议的数据服务可配置的技术实现方案设计。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
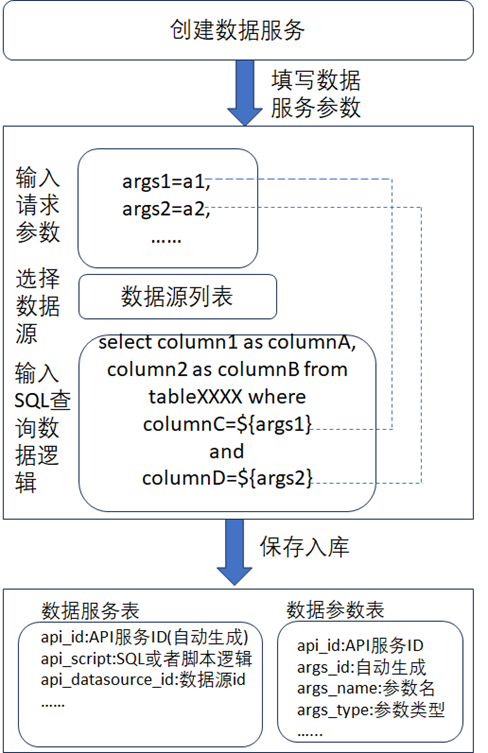
从图中可以看到
- 在创建数据服务时,填入的请求参数,需要和SQL查询脚本中的查询条件对应上。
- 创建的数据服务在保存时,需要将参数和SQL查询脚本都保存到数据库表中,在设计时,会设计两张表,一张表用于存储数据服务的相关信息,一张表用于存储数据服务对应的数据参数信息。创建数据服务时,数据服务平台会自动生成一个唯一的API服务ID,两张表之间通过API服务ID进行关联。
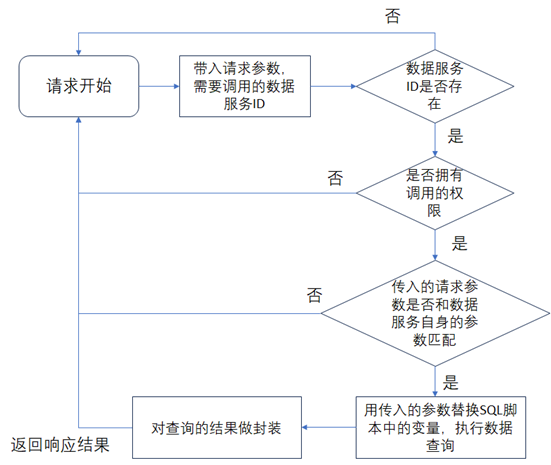
数据服务在创建好了后,外部用户在调用数据服务时,数据服务平台处理请求的逻辑如下图所示。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
1.3、 数据服务文档的自动生成
数据服务在支持了可配置化之后,还需要能自动生成数据服务的API文档,这样外部用户在调用数据服务的API时,就知道如何去调用了。由于数据服务的请求参数、服务ID等信息都已经保存在数据服务平台中了,所以通过从数据服务平台中把这些数据信息查询出来,按照API文档的格式展示出来就可以了,如下图所示。
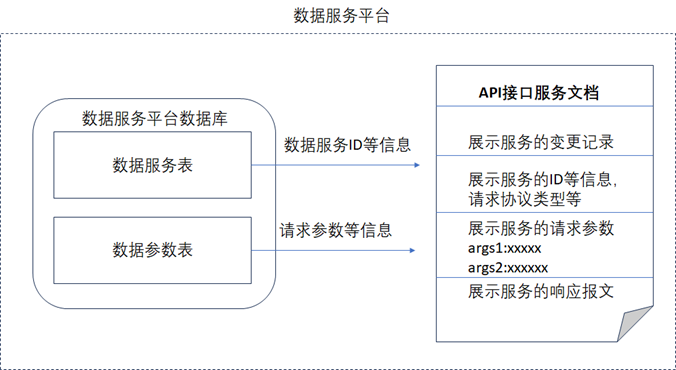
从图中可以看到,由于数据服务平台中保存了数据服务每次修改变更的信息,所以在自动生成出的数据服务文档中,还可以将该数据服务的历史变更记录也展示出来,可以看到自动生成出来的数据服务文档和通常手动编写的那种接口服务文档的内容几乎是一致的。
1.4、数据服务的统一认证与鉴权
数据服务在创建好了后,在调用时必定需要认证,不然就无法保证服务的安全性,也无法防止网络机器人或者黑客等发起的频繁恶意的请求或者攻击等。传统的认证通常是通过密码来完成的,给每个请求方分配一个唯一的密码,然后请求时,每次都带上这个密码,如果密码正确,那么就可以完成请求的调用,如下图所示。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著

但是这种简单的认证方式会面临如下问题:
- 安全性太低,密码容易丢失或者被别人使用。
- 通常情况下,很多数据服务都是支持Http协议,但是Http请求非常容易被劫持,一旦被劫持后,就可以从拦截到的请求中获取到密码,这样别人就可以用这个密码来发送请求或者直接篡改劫持到的请求,造成恶意的攻击。
为了解决上述的问题,通常推荐使用数字签名的方式来完成数据服务的统一认证,如下图所示,数字签名通常采用非对称的密码的方式(也称为公私钥机制),请求方通过私钥对请求的报文进行加密。数据服务平台通过使用该私钥对应的公钥进行解密。
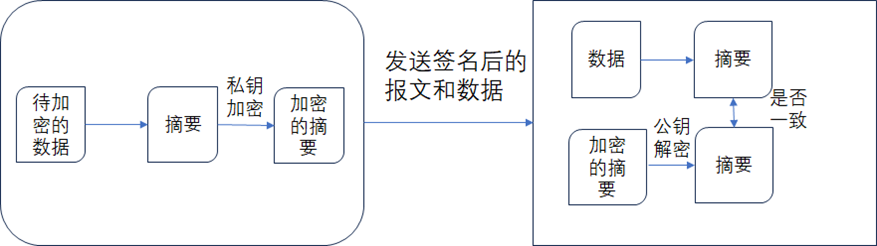
从图中可以看到请求方需要先对数据生成摘要,然后再用私钥加密后,生成加密的摘要,然后将数据和加密的摘要一起发送给数据服务平台,数据服务平台在收到数据和加密后的摘要后,先对加密后的摘要使用对应的公钥进行解密得到解密后的摘要,并且对发送过来的数据也重新生成摘要,如果生成出来的摘要和解密后的摘要一致,说明数据在传输过程中没用被更改。数据签名的认证方式可以有效的防止请求被劫持从而发生篡改。
在服务认证时,还可以加入网络认证,这样可以有效的拦截非正常调用的请求,最常见的网络认证的方式就是在网络中设置白名单,如下图所示。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
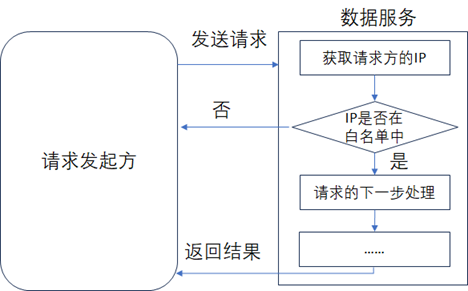
从图中可以看到,数据服务首先就会判断请求方的IP地址是否在白名单内,如果不在就可以直接返回。
在服务认证通过后,就可以进行下一步的鉴权操作了,数据服务平台在设计时,通常会给每个请求方分配唯一的身份ID(通常也称作appId),数据服务平台在收到该唯一身份ID后,会判断其是否有调用该数据服务的权限,如下图所示,如果没用权限,那么就直接返回并且给出对应的提示信息。
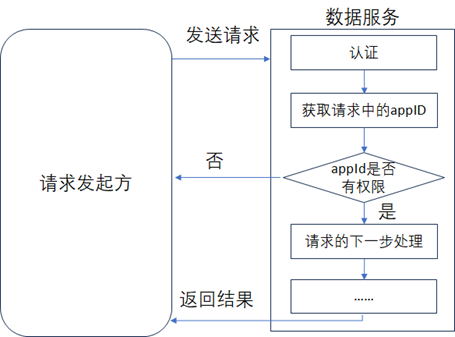
未完待续......《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著