本文旨在让无大模型开发背景的工程师或者技术爱好者无痛理解大语言模型应用开发的理论和主流工具,因此会先从与LLM应用开发相关的基础概念谈起,并不刻意追求极致的严谨和完备,而是从直觉和本质入手,结合笔者调研整理及消化理解,帮助大家能够更容易的理解LLM技术全貌,大家可以基于本文衍生展开,结合自己感兴趣的领域深入研究。若有不准确或者错误的地方也希望大家能够留言指正。
本文体系完整,内容丰富,由于内容比较多,分多次连载。
第一部分 基础概念
1.机器学习场景类别
2.机器学习类型(LLM相关)
3.深度学习的兴起
4.基础模型
第二部分 应用挑战
1.问题定义与基本思路
2.基本流程与相关技术
1)Tokenization与Embbeding
2)向量数据库
3)finetune(微调)
4)模型部署与推理
5)prompt
6)编排与集成
7)预训练
第三部分 场景案例
常用参考
第二部分 应用挑战
2.基本流程与相关技术
4)模型部署与推理
模型适配优化
大模型分析
经过上面的介绍,对一般的模型参数量,计算量等相关参数以及性能分析方法有了较为深入的了解。那么,针对于大模型,其相关参数和性能瓶颈又该怎么计算和分析呢?接下来,将围绕这一命题展开,由于当前已GPT3为主流的大模型,都是采用的transfomer模型的decoder-only结构(未遮盖部分),因此,以下分析都将以此展开。
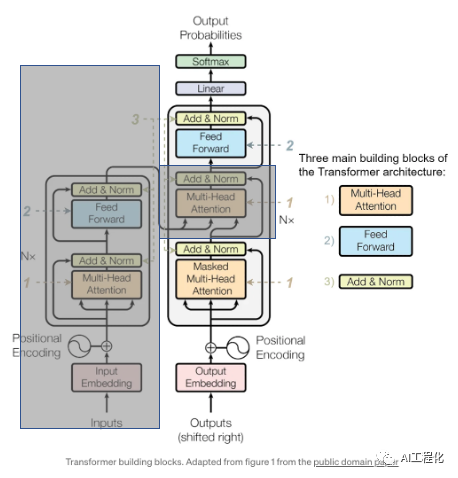
从图上可以看出,decoder结构由embedding层,主体transformer decoder块和输出层(linear及softmax)构成。而在decoder块又由多头注意力(Multi-head attention,MHA),前馈网络层(Feed-forward network,或FFN);LayerNorm层构成。假设记transformer模型各参数为:
| 参数名 | 标记符号 | 备注 |
|---|---|---|
| 模型参数量 | P | |
| transformer decoder block层数 | N | llama,gpt等大模型每层仅包含一个MHA和FFN 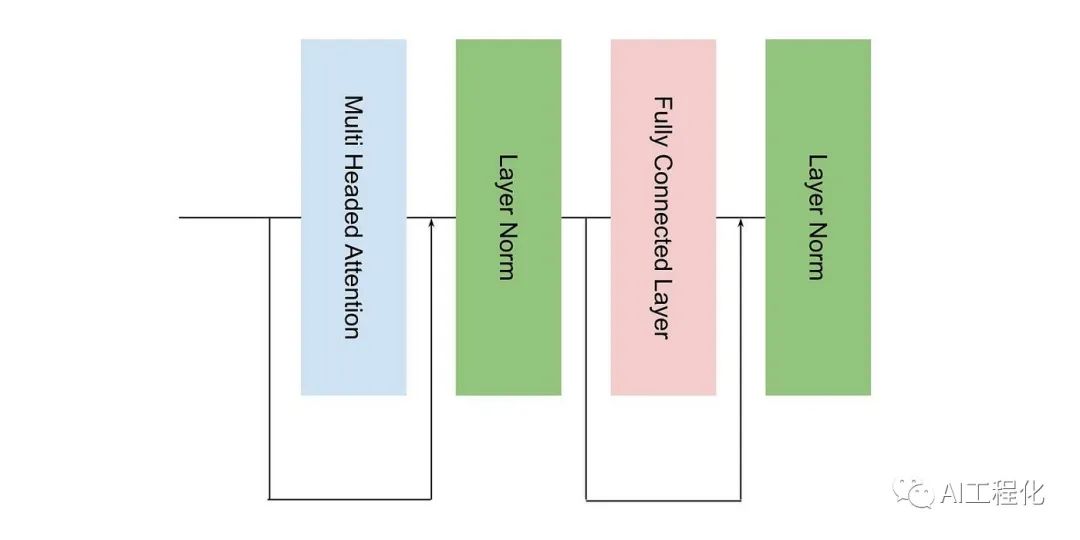 |
| 隐藏层维度 | d_model | 嵌入层维度,输出层维度与其一致 |
| 注意力头数 | h | |
| 词表大小 | V | llama默认词表32000 |
| 批次大小 | b | |
| 序列长度 | s |
参数量与显存占用
参数量可以分三部分计算:
1)embedding层
该层包含了词嵌入矩阵(word_embedding)的参数量及位置编码(position_embedding)参数量,词向量维度通常等于隐藏层维度,词表大小为V,故词嵌入矩阵的参数为V*d_model。
而位置编码,如果采用可训练式的位置编码,可训练模型参数数量比较少。如果采用相对位置编码,例如RoPE和ALiBi,则不包含可训练的模型参数。
故embedding层参数量约为:V*d_model
2)输出层(Generator),
该层包含一个线性层和softmax,故参数量为:d_model*d_model+d_model
3)对于transformer核心结构decoder:
a.多头注意力MHA:
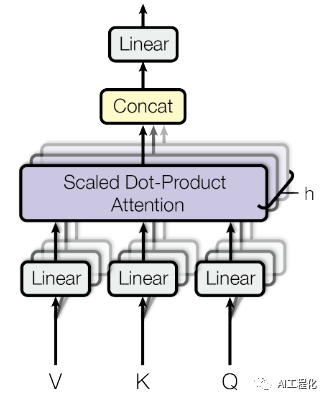
根据算法,Q、K、V向量要分别经过一层线性层,然后计算Scaled Dot-Product Attention,公式为:
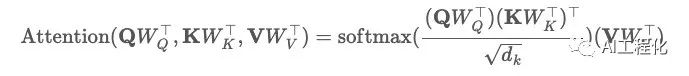
由于是多头注意力,故需要经过h个这样的计算,然后再将结果concat,再经过线性层输出。
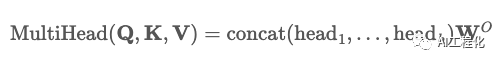
那么,看下这一系列计算里需要用到多少参数。因此,模块参数包含Q,K,V的权重矩阵W_q,W_k,W_v,其shape都为d_qkv,d_qkv,偏置向量的shape为d_model和输出W_o的shape为d_model,d_model,偏置向量的shape为d_qkv。
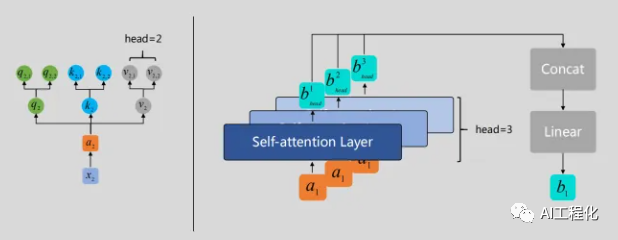
这里实现上要保证d_qkv=d_model/h(只有这样才能保证concat正确,在实际实现中,并没有真的拆分,只是逻辑上的"拆分",从这也能看出头数h并不会影响参数量)。
故MHA的参数量为:
3h (d_modeld_qkv+d_qkv)+ d_modeld_model+d_model,
即:4d_model^2+4d_model.
b.前馈网络层(FFN)是由两个全连接层(fully connected layers)组成,其中间有一个 ReLU 激活函数。
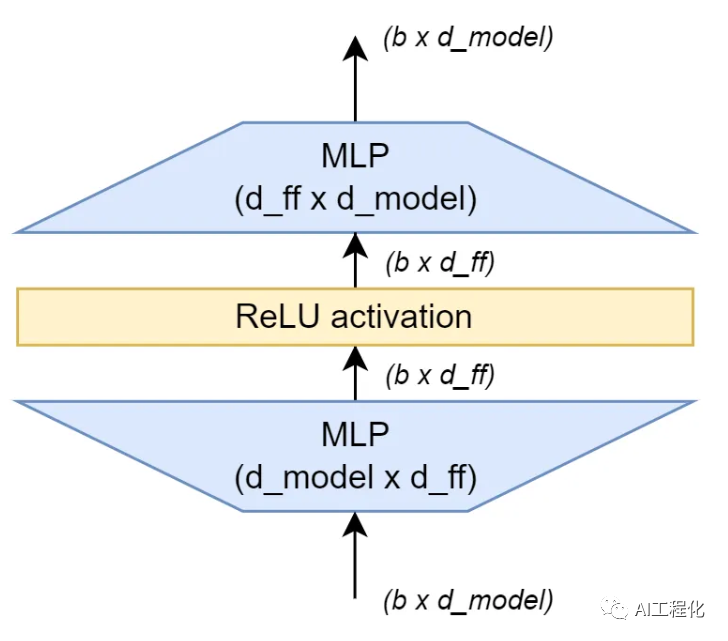
故前馈网络层(FFN,也叫MLP)的参数量为:
(d_modeld_ff+d_ff)+(d_ffd_model+d_model)
即:2*d_model*d_ff+d_model+d_ff

由于d_model,d_ff都是模型里超参数,原论文中为d_model设置为512时,d_ff为2048,即一般会将d_ff设置为d_model的4倍。故参数量可以简化为:8*d_model^2+5d_model
c.最后是LayerNorm层,包含2个可训练参数:缩放参数和平移参数,形状都是d_model,故每个Layer Norm的参数量就是2*d_model。而在decoder中包含2个LayerNorm,故总参数量为:4*d_model
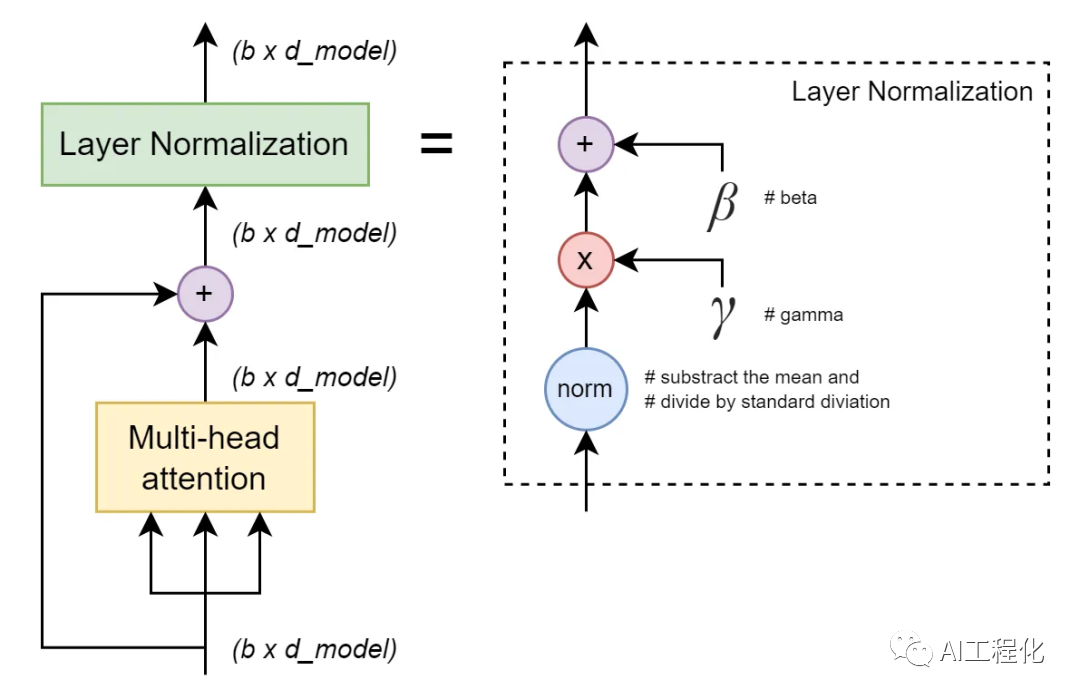
另外,GPT,llama等大模型对与transformer的Decoder结构做了改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,只保留了 Mask Multi-Head Attention。
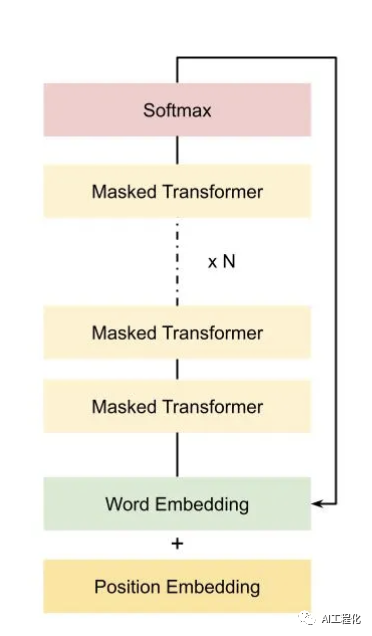
即堆叠结构为Multi-Head Attention和前馈层构成,故包含N层的transformer decoder模型的总参数量为:
N*((4d_model2+4d_model)+8*d_model2+5d_model+4d_model)
即:N*(12d_model^2+13d_model)
那么一个完整的基于transformer decoder-only结构的大模型参数量为:
输入层参数量+输出层参数量+N*transformer-decoder-block
代入前面计算的结果:
V*d_model+d_modeld_model+d_model+N*(12d_model2+13d_model)
=12N*d_model^2+ 13*N*d_model + d_model^2 + V*d_model
当d_model足够大,故可以省略掉低次项,约等于(12N+1)d_model2+V*d_model,考虑到输出层,输入层和具体任务有关,为了简化计算也可以直接计算decoder本身的参数量即可,即:**12*N*d_model2*
以llama为例,基于以上公式(12Nd_model2+d_model2 + Vd_model)可得:
| 实际参数量P | 隐藏层维度d_model | 层数N | 注意力头数h | 参数计算公式 | 估算参数量 | 不含输出层和输入层,参数量 | 显存/硬盘大小(2倍参数量f16) |
|---|---|---|---|---|---|---|---|
| 6.7B | 4096 | 32 | 32 | (124096 4096)32+40964096 + 32000*4096 | 6590300160 | 6442450944 | ~13GB |
| 13.0B | 5120 | 40 | 40 | (125120 5120)40+40964096 + 32000*4096 | 12730761216 | 12585574400 | ~24GB |
| 32.5B | 6656 | 60 | 52 | (126656 6656)60+40964096 + 32000*4096 | 32045531136 | 31902873600 | ~60GB |
| 65.2B | 8192 | 80 | 64 | (128192 8192)80+40964096 + 32000*4096 | 64572358656 | 64433029120 | ~120GB |
实际上这样的计算只是为了理解其中的参数逻辑,实际计算参数量可以利用上面提到的工具计算。
需要说明的是,上面显存占用仅仅是模型参数内存,下面进一步具体分析训练和推理阶段显存占用。
1)训练显存
训练显存是由模型参数 、模型梯度信息(gradients) 、*优化器状态(OptimSates)和*模型中间结果(Activations)****共同构成。假设模型参数为X。
模型梯度,在反向传播时,需要将模型梯度信息存放到显存中,每个参数都会对应1个梯度,故和参数显存大小相当,其数量为P。
优化器状态,以Adam优化器为例,一个参数对应2个优化器状态(Adam优化器梯度的一阶动量和二阶动量),故数量为2P。
中间结果,即前向传递过程中计算得到的中间激活值,需要保存中间激活以便在后向传递计算梯度时使用。激活(activations)指的是:前向传递过程中计算得到的,并在后向传递过程中需要用到的所有张量,简单理解就是临时变量。这里的激活不包含模型参数和优化器状态,但包含了dropout操作需要用到的mask矩阵。该结果与批次大小b,序列长度s有关。分别计算MHA,前馈网络,layerNorm等中间存储的大小,可获得N层transformer模型中间激活层最终显存占用为:
34*b*s*d_model + 5*b*s^2*h
总的显存占用(假设f16存储)即为:
(P+2P+P)2+N (34b sd_model + 5 bs^2h)
= 8*12*N*d_model^2 + N * (34*b*s*d_model + 5*b*s^2*h)
可以从公式看出,模型和梯度占用的大小是与参数量相关与输入数据无关,而中间激活值与输入数据的大小(批次大小b和序列长度s)是成正相关的,随着批次大小和序列长度的增大,中间激活占用的显存会同步增大。当训练神经网络遇到显存不足OOM(Out Of Memory)问题时,通常会尝试减小批次大小来避免显存不足的问题,这种方式减少的其实是中间激活占用的显存,而不是模型参数、梯度和优化器的显存。
以lllama 13B为例,参数显存占用为2*12B,约为24GB,梯度,优化器等占用36GB,中间激活层占用,如图:
| batchsize | 参数显存占用 | 固定显存占用 | 激活层占用 | 与参数显存比 |
|---|---|---|---|---|
| 1 | 24GB | 96GB | 31GB | 1.3 |
| 64 | 24GB | 96GB | 1.9T | 82 |
| 128 | 24GB | 96GB | 3.8T | 165 |
可以看到随着批次大小的增大,中间激活占用的显存远远超过了模型参数显存,呈线性比例增长。如何减少显存占用,提高利用率,是优化的重点。采用激活重计算技术来减少中间激活就是一种办法,代价是增加了一次额外前向计算的时间,本质上是"时间换空间"。
2)推理显存
推理显存不需要存放梯度信息和优化信息,根据经验值大概是模型参数显存占用的1.2倍。由于推理过程是面向延迟优化的,为了加快推理速度,在推理过程中,避免每次采样token时重新计算键值(KV)向量,可以利用预先计算好的k值和v值,将其存储在cache中,这叫做KV cache,它们会存储在GPU的显存中,从而节省计算时间,但同样它会带来显存的消耗。包含两个阶段:
- 预填充阶段:输入一个prompt序列,为每个transformer层生成 key cache和value cache,即KV cache。
- 解码阶段:使用并更新KV cache, 一个接一个地生成词,当前生成的词依赖于之前已经生成的词。
采样时,Transformer模型会以给定的prompt/context作为初始输入进行推理(可以并行处理),随后逐一生成额外的token来继续完善生成的序列(体现了模型的自回归性质)。在采样过程中,Transformer会执行自注意力操作,为此需要给当前序列中的每个项目(无论是prompt/context还是生成的token)提取键值(kv)向量。这些向量存储在一个矩阵中,通常被称为kv缓存或者past缓存(开源GPT-2的实现称其为past缓存)。
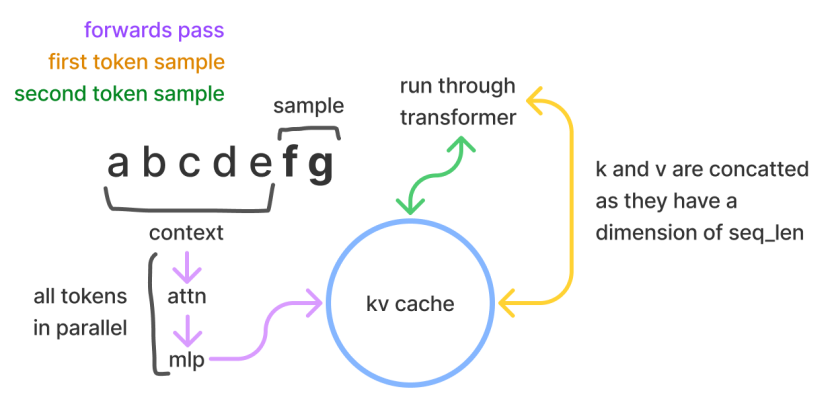
而这部分的显存占用,大概遵照这样的计算规则:
假设输入序列长度为s,输出序列长度为n,以float16来保存KV cache,那么KV cache的峰值显存占用大小为,其中第一个2表示KV cache,第二个2表示float16占2个bytes。其KV cache峰值显存占用为:
b*(s+n)*d_model*L*2*2 = 4bLd_model(s+n)
仍以llama 13B为例,其kv cache占用显存为:
| 批次大小b | 输入序列长度s | 输出序列长度n | 公式 | KV Cache大小 |
|---|---|---|---|---|
| 64 | 512 | 32 | 464 405120(512+32) | ~26GB |
计算量
对于transformer结构的模型来讲,权重矩阵乘法计算相较于其他(Layer Norm,残差,激活函数,softmax,甚至 Attention)都可以忽略不计。当输入变量为X: (input_size, d_model),权重矩阵为W: (d_model, out)时:
该矩阵计算的FlOPs:2*input_size * d_model。(对于该结果矩阵的每个元素,都是做 h 次乘法(按位相乘),然后再做h次加法,故为2倍)
对于每个step,模型的前向传播 FLOPs = 2 * b * s * P,后向传递的计算量近似是前向传递的2倍(后向传播除了计算梯度之外,还需要存储梯度并进行参数更新),见https://epochai.org/blog/backward-forward-FLOP-ratio。rd-forward-FLOP-ratiord-forward-FLOP-ratio。若一次训练总共需要steps次迭代,那么完整的计算量 :
6 * steps * b * s * P,
其中 steps * b * s 就是训练语料的 Token 数量 T,则训练的总计算量为6 * T * P ,单次token的推理计算量为2P。

另一个较详细的推算解释:
对于一个层的transformer模型,输入数据形状为的情况下,一次训练迭代计算量为N*(24b sd_model^2 + 4 bh s^2)+4bsd_model*V。
当d_model较大,且远大于序列长度s时,忽略一次项,计算量近似为24N bs d_model2,而模型参数量约为12Nd_model2,输入的tokens数为bs,存在等式24N bsd_model^2 / 12* N * d_model^2 = 2, 可近似认为在一次前向传递中,对于每个token,每个模型参数,需要进行2次浮点数运算,即一次乘法运算和一次加法运算。
训练时间估计
训练时间就可以估算:6TP/(nXu),其中X是计算显卡的峰值FLOPS,n为卡的数量,u为利用率。
以LLaMA-65B为例,在2048张80GB显存的A100上,在1.4TB tokens的数据上训练了65B参数量的模型。80GB显存A100的峰值性能为624TFLOPS,设GPU利用率为0.3,则所需要的训练时间为:
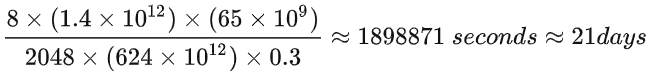

从这里可以看出,提高GPU利用率对于模型性能来讲,是非常重要的。
推理性能分析
如上一节介绍,根据RoofLine模型,计算性能表现与模型是计算密集和访存密集有关。运算量会随批处理大小和参数量增加而增加,而内存只随参数量增加而增加。如果每个参数需要进行的乘法运算很少,那么可能就更会受到内存带宽的影响。
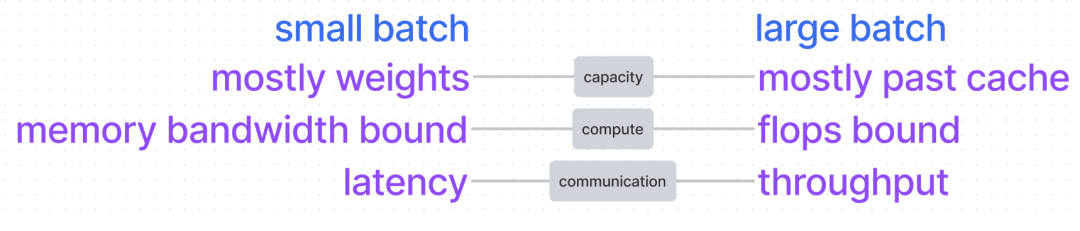
如图,这里有一个基本结论是,batchsize越大,GPU处理相同请求所需的时间就越短,就能更有效地利用GPU资源,大吞吐。然而,batch size小,低延迟,内存又会受到限制。在这种情况下,应该放弃使用kv cache,节省内存,选择支付计算成本。在足够负载下,倾向于程序是计算密集的,因为基于计算密度公式,这样的计算效率高,但如果是计算密集,那么增大batchsize并不能提高计算速度。下图,为计算密度的公式总结。

以A100芯片为例,每字节通信的浮点运算次数为(312e12/300e9)=1040次。我们希望计算密度(flops/byte)大于硬件计算能力(每秒浮点运算次数FLOPS),以保持计算密集(假设我们在这里没有内存限制)。对于维度超过1024的模型就能满足条件。
在接口负载较低时,batchsize会比较小,这时可以考虑放弃kv缓存等决策,充分利用计算能力。如果接口需要处理大量批次输入,那么即使还有剩余容量,也可能会希望保持最小的batchsize,以保证较小的请求延迟。
小结
前文介绍了模型的推理性能受到多个因素的影响,结合roofline模型对模型进行分析,降低参数量和计算量,提升计算效率是未来推理内存占用和延迟优化的重要优化方向。未来章节将围绕这一方向,给出相关优化理论和方法。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。