引言
今天带来一篇百度提出的关于提升RAG准确率的论文笔记,Improving Retrieval Augmented Language Model with Self-Reasoning。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。
检索增强语言模型(Retrieval-Augmented Language Model,RALM)在知识密集型任务中表现出色,通过在推理过程中融入外部知识,有效缓解了大言模型固有的事实幻觉。尽管如此,RALM的实施仍面临挑战,尤其是在其可靠性和可追溯性(traceability)方面。
具体来说,不相关的文档检索可能导致无用的回应生成,甚至可能削弱LLM的性能,而生成输出中缺乏适当的引用则使得验证模型的可信度变得更加困难。为此,我们提出了一种新颖的自我推理框架,旨在提高RALM的可靠性和可追溯性,其核心思想是利用LLM自身生成的推理轨迹。该框架包括三个过程来构建自我推理轨迹:一个关注相关性的过程,一个证据选择性过程,以及一个轨迹分析过程。
1. 总体介绍
检索增强语言模型(RALM)已成为大语言模型的关键增强技术,通过在推理过程中整合外部知识来提升其能力。尽管LLM在语言理解和生成方面具有先进的能力,它们仍容易产生虚假的和不准确的内容,特别是在知识密集型任务中。通过从外部来源如维基百科和搜索引擎获取相关信息来增强LLM,已被证明能有效减少这些不准确性。这种方法也能有效缓解LLM固有的事实幻觉。
尽管如此,RALM仍存在一些局限性,特别是在可靠性和可追溯性方面。首先,检索信息的可靠性仍然是一个重大问题。噪声较大的检索会对LLM的性能产生不利影响,因为不相关的数据可能导致误导性的回应,并干扰模型有效利用其内在知识的能力。其次,RALM生成的输出的可解释性和可追溯性需要提高。虽然RALM在训练和推理阶段都结合了检索到的文档,但它们可能未能明确引用这些文档,从而使得追踪和验证LLM所做声明的过程变得复杂。为了提高检索的鲁棒性,近期研究探索了在推理过程中结合自然语言推理(NLI)模型和文档摘要模型。然而,这些外部NLI和摘要模型的有效性在很大程度上影响了RALM的整体性能。这些辅助模型的训练和优化需要额外的成本。因此,确定最合适的训练和选择方法用于这些NLI和摘要模型,也成为应用这些方法中的一个进一步挑战。
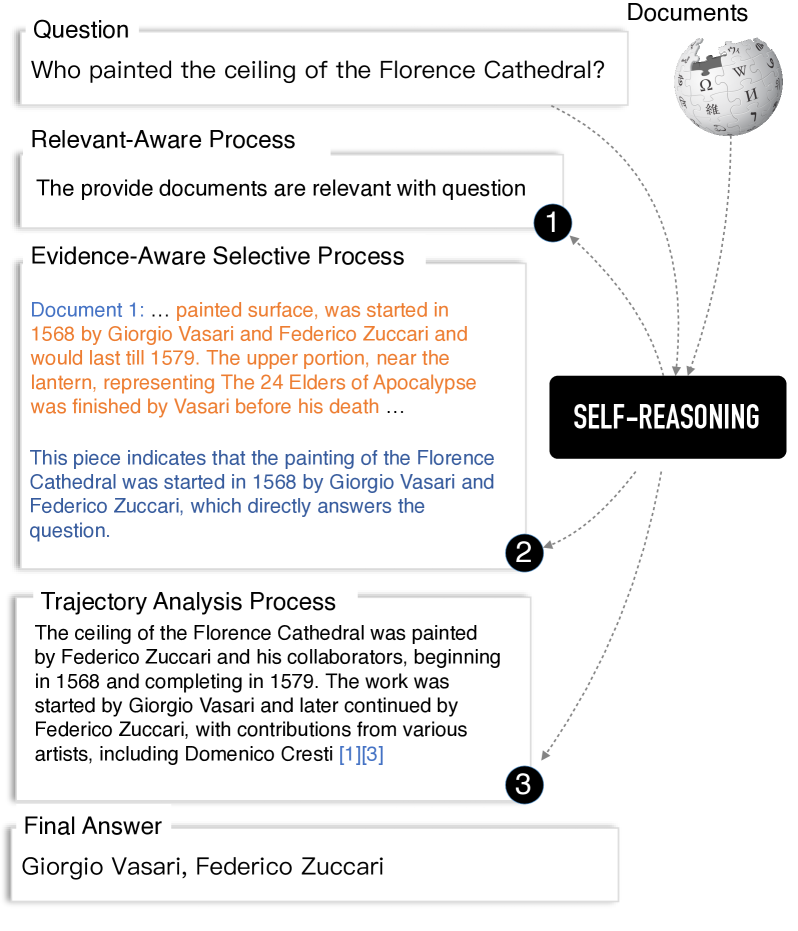
图1 一个示例展示了自我推理框架如何生成推理轨迹,包括相关性感知过程、证据感知选择过程和轨迹分析过程。
为了解决上述局限性,我们提出了一种新颖的端到端自我推理(SELF-REASONING)框架,以提升RALM的性能。我们的直觉是,通过LLM明确构建的自我推理轨迹可以改善检索的鲁棒性和问答的准确性 。在预训练阶段,LLM主要关注知识的获取,但它并未学习如何从检索到的文档中进行推理以生成答案。为了解决这个问题,一种可行的方法是将推理轨迹融入后训练阶段。这种方法可能会教会模型进行推理,并区分相关和不相关的文档,从而提高其对查询的回应准确性。我们的自我推理框架生成推理轨迹的示例如图1所示。相比之下,如图2中部所示,传统的RALM方法以非选择性的方式收集所有文档,导致LLM被无关内容分散注意力,从而生成错误的答案。
我们的框架包含三个自我推理过程:
- 相关性感知过程(Relevance-Aware Process,RAP):指导LLM判断检索到的文档与问题之间的相关性;
- 证据感知选择过程(Evidence-Aware Selective Process,EAP):指导LLM选择和引用相关文档,然后从引用的文档中自动选择关键句子片段作为证据;
- 轨迹分析过程(Trajectory Analysis Process,TAP):要求LLM基于前两个过程生成的所有自我推理轨迹生成简明分析,并随后提供最终推断的答案。
此外,我们提出了一种渐进训练方法,通过采用阶段性屏蔽策略来增强框架的性能。
主要贡献如下:
- 我们提出了一种新颖的端到端自我推理框架,通过利用LLM自身生成的推理轨迹来提高RALM的鲁棒性,而无需依赖外部模型或工具。
- 我们精心设计了三个过程,以提高RALM的可解释性和可追溯性,要求LLM明确生成文档片段和引用,并进一步解释引用文档为何能够帮助回答问题。
- 我们在四个公开数据集(两个短文本问答数据集、一个长文本问答数据集和一个事实验证数据集)上评估了我们的框架,结果表明我们的方法在性能上超越了现有的最先进模型,并且仅使用了2000个训练样本。
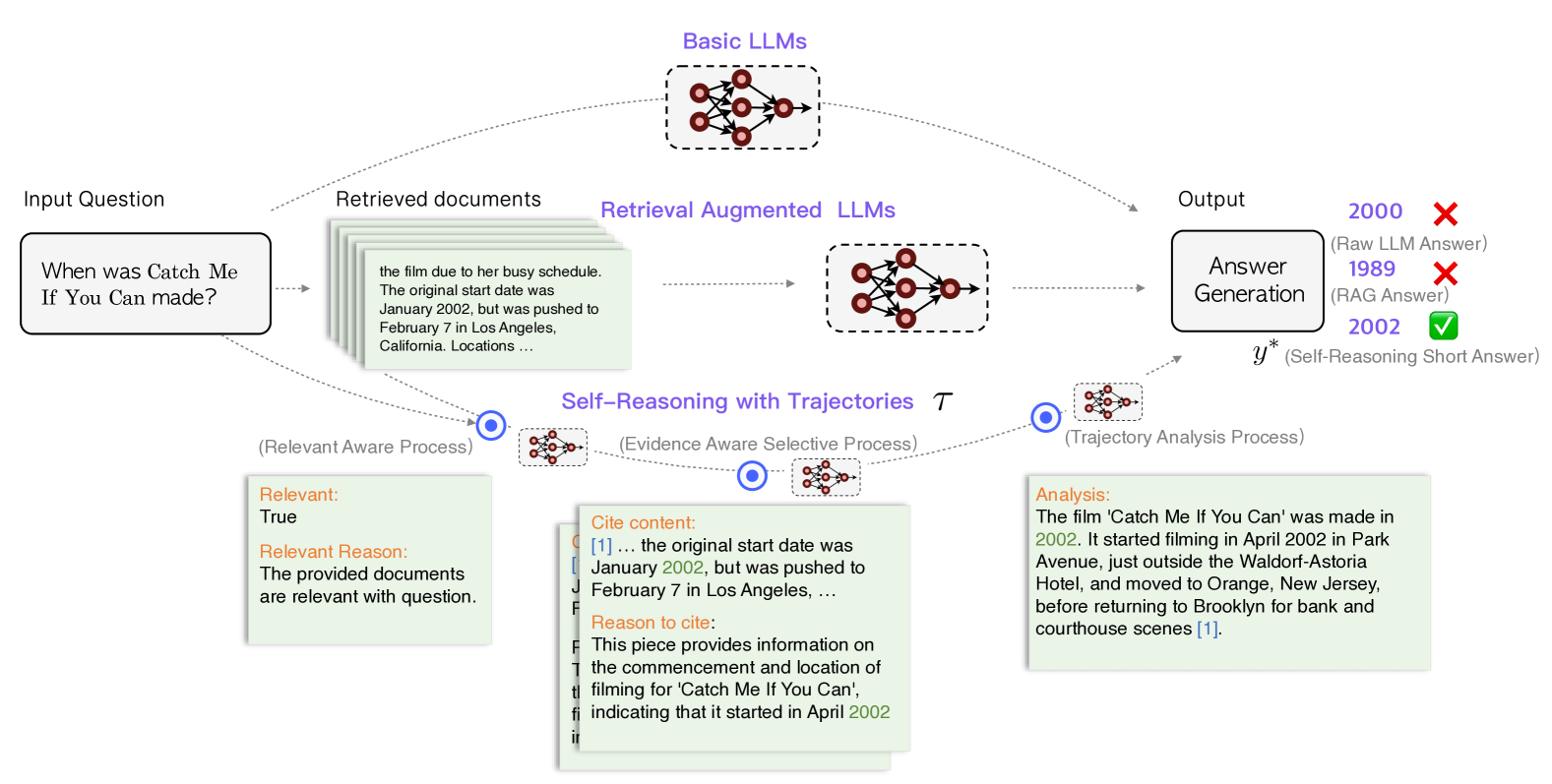
图2 自我推理框架用于改进RALM的示意图。(三条箭头)上部是基本的LLM,它通过固有知识回答问题。中部是标准的检索增强语言模型,它使用检索到的文档来帮助回答问题。底部是我们的自我推理框架,它利用自生成的推理轨迹来输出答案。
2. 相关工作
2.1 检索增强语言模型
许多研究探讨了通过外部检索信息增强LLM性能,其中一些研究在预训练阶段使用检索到的文段进行训练。针对带有引用的RALM的研究,指导或训练LLM在回答问题时使用检索到的文档并提供引用。Gao等提出了一种端到端系统来检索支持证据并生成带有引用的答案,但仅关注于提示,而不更新模型权重。其他研究则指导或微调LLM,以动态方式使用外部工具进行检索,提供了一种适应性的方法来决定何时以及检索什么内容。Gao等通过对LLM的输出进行后处理检索和编辑的方法,改善了语言模型的归因和真实性。
2.2 RALM的鲁棒性
为了提高RALM的鲁棒性,Yoran等在使用RALM之前,利用自然语言推理模型筛选掉不相关的文档,而Xu等则使用记忆模型来筛选或压缩检索到的文档,然后再用这些文档提示LLM。同期的工作在使用RALM之前生成文档的摘要作为笔记,而Baek等则使用一个独立的小型语言模型作为验证器,以检测和纠正LLM在检索过程中生成事实正确输出时的错误。与上述工作不同,我们通过一个端到端框架识别关键句子并引用相关文档,从而消除不相关的文档,且不依赖外部推理模型。
与我们的工作最相似的是Asai等提出的方法,他们开发了一种通过设计反射标记来教导模型检索信息的方法。然而,这种方法需要训练额外的评论模型和生成模型来预测反射标记,这需要数万个额外的训练样本。相比之下,我们的方法不依赖特殊标记。相反,我们构建推理轨迹,并利用这些轨迹直接提升LLM的性能,提供了一种更高效且可扩展的解决方案。
3. 初始定义
给定一个查询 q q q和一个文档语料库 D \mathcal D D,LLM生成的答案由 m m m个陈述和 n n n个词元(token)组成,可以定义为: y = ( s 1 , s 2 , ⋯ , s m ) = ( w 1 , w 2 , ⋯ , w n ) y = (s_1, s_2, \cdots, s_m) = (w_1, w_2, \cdots, w_n) y=(s1,s2,⋯,sm)=(w1,w2,⋯,wn),其中 s i s_i si是第 i i i个陈述, w j w_j wj是生成答案中的第 j j j个词元。此外,对于长文本问答设置,每个陈述 s i s_i si应引用一个文档列表 C i = { c i ( 1 ) , c i ( 2 ) , ... } C_i = \{ c_i^{(1)}, c_i^{(2)}, \ldots \} Ci={ci(1),ci(2),...},其中 c i ( k ) ∈ D c_i^{(k)} \in \mathcal D ci(k)∈D。
我们训练一个LLM(比如 LLaMA2)首先通过自我推理生成推理轨迹 τ \tau τ,然后在 τ \tau τ的条件下生成答案 y ∗ y^* y∗(包括长文本答案和短文本答案)。模型输出为: y = concat ( τ , y ∗ ) y = \text{concat}(\tau, y^*) y=concat(τ,y∗),即 τ \tau τ和 y ∗ y^* y∗的拼接。注意在自我推理 框架中, τ \tau τ和 y ∗ y^* y∗的生成是在一次(前向传播)推理中完成的。
4. 方法
在我们的工作中,我们提出了一个新颖的框架,包括三个过程:
- 相关性感知过程
- 证据感知选择过程
- 轨迹分析过程
我们在图2中展示了自我推理框架如何改善RALM的效果。
4.1 相关性感知过程
在本工作中,我们选择了DPR和Contriever作为默认的检索器 R R R来召回前 k k k个相关文档。当面对一个问题和一组文档时,人们可以判断问题是否与检索到的文档相关。因此,我们首先指导模型判断检索到的文档 D \mathcal D D和给定问题 q q q之间的相关性。
我们进一步要求模型明确生成解释为何给定文档被识别为相关的理由。输出应包括两个字段:相关性(relevant)和相关理由(relevant reason),如图2所示。需要注意的是,如果所有检索到的文档都不相关,模型应基于在预训练阶段获得的内部知识提供答案 。将RAP生成的自我推理轨迹定义为 τ r \tau_r τr。
4.2 证据感知选择过程
在回答问题时,人们通常会首先从提供的文档中识别关键句子,然后引用或突出这些句子作为重点。这种引用文档的过程有助于阅读理解,并且可以作为将多个简短答案组合起来以解决不同方面的技术。虽然人们可以瞬间进行这种选择性过程和引用,LLM则需要明确地制定自我推理轨迹。
在我们的工作中,我们要求LLM明确说明为何所选句子在回答问题时是支持性和可信的。我们将所选句子定义为证据。具体来说,在检索出前 k k k个文档后,证据感知选择过程的自我推理方法可以如下制定:首先,指导LLM选择相关文档,并自动选择这些文档的关键句子片段。然后,要求LLM输出所选片段为何能够回答问题的理由。中间输出是一个包含多个内容的列表,每个内容应包括两个字段:引用内容(cite content)和引用理由(reason for cite),如图2所示。将EAP生成的自我推理轨迹定义为 τ e \tau_e τe。
4.3 轨迹分析过程
最后,将前面过程中的所有自我推理轨迹( τ r \tau_r τr和 τ e \tau_e τe)整合在一起,形成一系列推理片段,从而提升检索增强生成的整体性能。具体而言,要求LLM分析其中的推理轨迹,并最终输出简明的分析和简短的答案。指导LLM输出包含两个字段的内容,即分析(analysis)和答案(answer),如图2所示。将TAP生成的自我推理轨迹定义为 τ a \tau_a τa。在本工作中,分析输出被定义为长文本答案,而答案输出被定义为短文本答案。
4.4 数据生成和质量控制
训练数据生成 对于相关性感知过程的数据生成,让GPT-4生成答案作为真实标签。具体而言,我们指导GPT-4生成关于不相关字段的标签,并进一步输出给定文档无法回答问题的理由。将给定问题和检索到的文档拼接在一起,作为正样本。对于负样本,我们从训练集中随机选择一个不同的问题,并检索与之相关的前 k k k个文档。然后将这些文档与初始问题拼接起来,形成负样本。为了避免训练数据中的顺序偏差,对文档的顺序进行随机打乱。
对于EAP和TAP的数据生成,手动注释文档的引用和为每个问题编写自我推理过程在实际操作中并不可行。因此,遵循与RAP类似的过程,首先指导GPT-4生成所选文档的片段,然后输出推理过程作为轨迹。构建EAP训练数据的方法与RAP相同,只是GPT-4的指令有所不同。
数据质量控制 对于训练数据生成,正确和全面的推理轨迹非常重要。在训练LLM时,训练样本的质量比数量更为关键。由于我们不能保证GPT-4生成的自我推理轨迹和引用的正确性,我们开发了两种有效的方法来控制数据生成的质量:
-
第一种方法 是使用Gao等人工作中现成工具,自动验证文档引用的数据生成性能。计算每个训练样本的引用精度和召回率,并筛选出低于预定义阈值 δ p \delta_p δp和 δ r \delta_r δr的样本,分别用于引用精度和召回率。
-
第二种方法是,尽管验证GPT-4生成的自我推理轨迹和引用的正确性具有挑战性,但验证最终答案的正确性相对简单。因此,筛选出导致错误答案的轨迹,只保留正确的轨迹。总共生成了10000个训练样本,通过质量控制的筛选策略,最终保留了2000个高质量的训练样本。
4.5 模型训练
4.5 模型训练
通过构建的语料库来训练自我推理生成模型 ϕ \phi ϕ,该语料库增强了自我推理轨迹 τ \tau τ,使用标准语言建模目标,即最大化似然函数:
max ϕ E ( q , τ , y ) ∼ D s r log p ϕ ( y ∣ τ , q ) p ϕ ( τ ∣ q ) (1) \max_{\phi} \mathbb{E}{(q, \tau, y) \sim \mathcal D{sr}} \log p_{\phi}(y \mid \tau, q) p_{\phi}(\tau \mid q)\tag 1 ϕmaxE(q,τ,y)∼Dsrlogpϕ(y∣τ,q)pϕ(τ∣q)(1)
其中, τ = τ r ⊕ τ e ⊕ τ a \tau = \tau_r \oplus \tau_e \oplus \tau_a τ=τr⊕τe⊕τa是自我推理轨迹; ⊕ \oplus ⊕是拼接操作符; τ r \tau_r τr、 τ e \tau_e τe和 τ a \tau_a τa分别是上述三个过程生成的轨迹; q q q是提供的问题; y y y是模型输出,包括中间推理轨迹和最终答案; D s r D_{sr} Dsr是增强了自我推理轨迹的训练语料库。
在训练过程中,当生成长推理轨迹时,确保具有13B参数的LLM的正确性比生成短推理轨迹更加具有挑战性。假设LLM的有效推理长度是有限的,超过这一限制可能会导致推理阶段的错误积累。因此,我们提出了一种渐进训练方法,通过阶段性掩码策略来逐步学习生成长轨迹。
具体而言,我们提出了一种阶段性训练过程,逐步训练LLM。在第一阶段,掩码下一两个阶段(EAP和TAP)生成的轨迹,并以学习率 r a r_a ra训练模型。然后,在第二阶段,仅掩码TAP生成的轨迹,并以学习率 r b r_b rb训练模型。最后,将所有阶段的推理轨迹拼接起来,并将其输入到自我推理LLM中进行端到端训练,使用学习率 r c r_c rc。
5. 实验
使用NaturalQuestion、PopQA两个短文本问答数据集,一个长文本问答数据集ASQA和一个事实验证数据集FEVER。
探索了现成的检索器,使用了DPR和Contriever-MS MARCO从维基百科中检索前5个文档。
为短文本问答、长文本问答和事实验证任务使用不同的评估指标。
短文本问答指标 报告短文本问答任务的准确率。
长文本问答指标 对于长文本问答任务,报告 EM 召回率作为正确性指标,以及引用召回率和引用精度作为引用质量指标。
事实验证指标。对于事实验证任务,报告准确率作为指标。
基线模型
无检索的基线模型 评估了强大的开源预训练 LLM 作为基线模型。对于基本 LLM,测试了 LLaMA2-7B、LLaMA2-13B及其指令调整版聊天模型 LLaMA2-Chat-7B 和 LLaMA2-Chat-13B。
有检索的基线模型 为了评估检索增强 LMs 的性能。首先,使用 LLaMA2 和 Vicuna系列模型进行基线测试。其中 LLaMA2 在除自我推理轨迹外的所有由 GPT-4 生成的训练样本上进行了微调。为了建立强有力的基线。
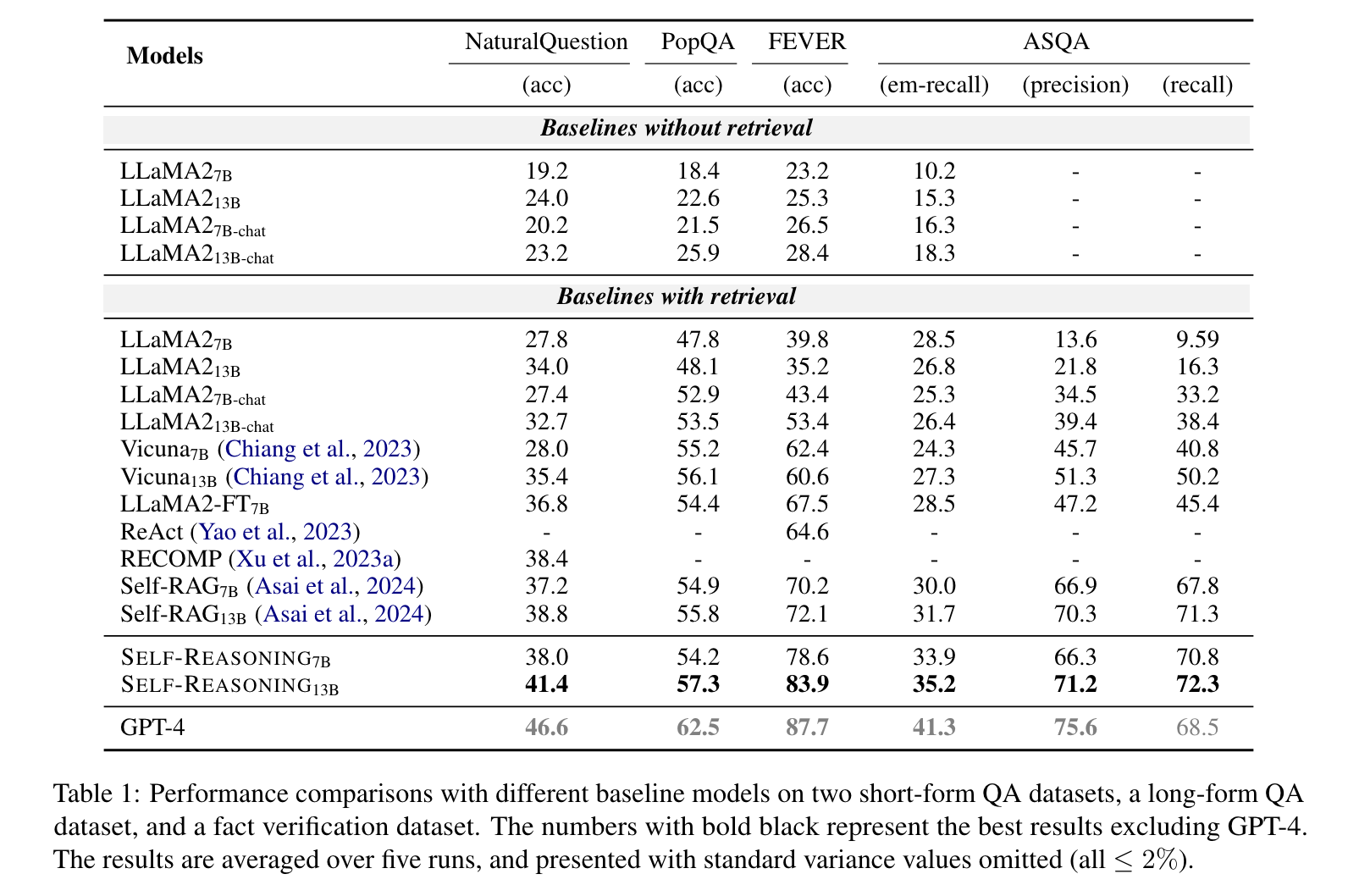
表 1 显示了在四个公共数据集上不同方法的性能比较。对于短文本问答评估,增强检索的 LLM 的性能始终优于基础模型,确认了增强方法的有效性。值得注意的是,在相同数量级的参数下, SELF-REASONING 框架超越了大多数强基线 LLM。
在长文本问答评估的背景下,EM 召回率指标需要理解多个文档并合并答案。EAP 和 TAP 专门设计用于多文档阅读理解,使我们的性能超越其他基线模型。在引用评估指标方面,我们的 SELF-REASONING 框架在 ASQA 的引用召回指标中可以获得比 GPT-4 更好的结果。这主要得益于 EAP 中生成的推理轨迹,它们能够提高引用评估的召回率和精度,从而生成更具可解释性的结果。
在事实验证评估中,观察到 SELF-REASONING 明显优于所有基线模型。框架中的 RAP 旨在判断检索文档与问题之间的相关性,这显著提升了该事实验证任务的准确性。
6. 分析
6.1 消融研究
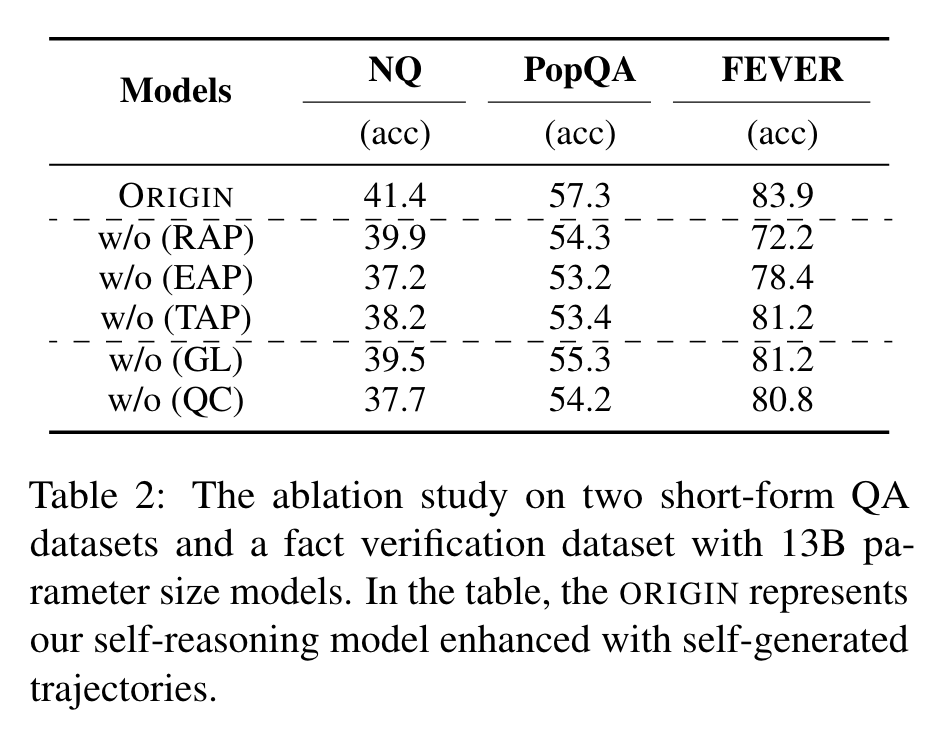
主要的消融研究结果见表 2。
相关性感知过程的有效性
首先,评估了相关性感知过程(RAP)的效果。移除 RAP 会导致两个短文本问答数据集和一个事实验证数据集的整体性能下降,这表明初步考虑问题和检索文档之间的相关性有助于提高性能。
证据感知选择过程的有效性
评估了证据感知选择过程(EAP)的效果。移除 EAP 会导致三个短文本问答数据集的平均准确率从 60.9 下降到 56.3。这一降幅表明,通过自我推理生成的关键句子片段和文档引用对于提高准确性具有重要作用。
轨迹分析过程的有效性
评估了轨迹分析过程(TAP)的效果。排除 TAP 时,可以观察到三个数据集上的性能下降,这表明基于前两个过程生成的轨迹的自我分析也能提高 LLM 的性能。需要注意的是,TAP 生成的分析内容对于长文本问答评估是不可或缺的。
6.2 检索鲁棒性分析
由于检索器并不完美,且过去的研究表明,噪声检索会对 LLM 的性能产生负面影响,因此在本节中设计了两种设置来验证 RALMs 的鲁棒性。在第一个设置中,测试检索文档的顺序是否会影响 RALMs 的性能。具体来说,在使用检索器(如 DPR)按照递减相关性评分检索前 k 个文档后,我们随机打乱这些文档的顺序,然后将其输入到 LLM 中。在第二个设置中,测试噪声文档如何影响 LLM 的性能。当从给定问题中检索前 k 个文档时,随机将 50% 的检索文档替换为从数据集中不同问题中抽取的其他文档。
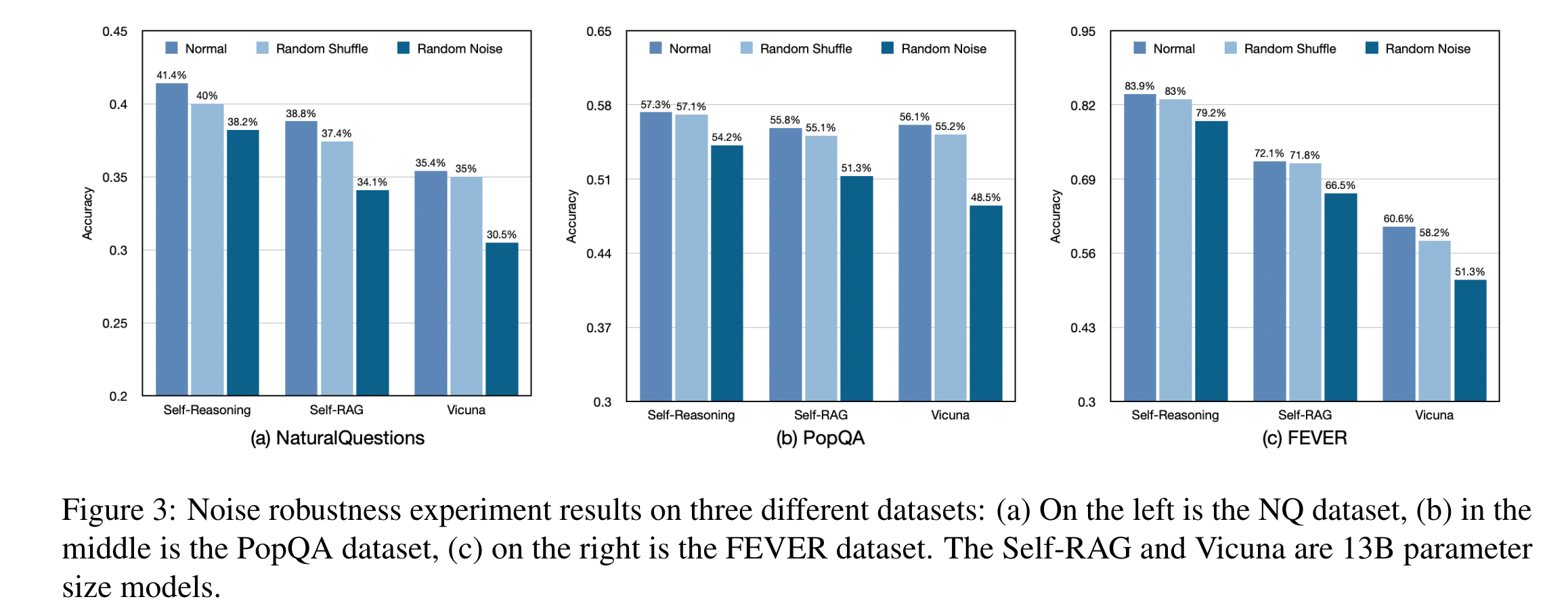
图 3 显示了三个数据集上的噪声鲁棒性实验结果。SELF-REASONING 框架在性能上始终优于 Self-RAG 和 Vicuna 模型。随机打乱检索文档对 RALMs 的性能影响较小。如果提供的文档是支持性的,RALM 判断正确答案是简单的。然而,当遇到噪声文档时,所有模型的性能都有所下降。自我推理框架的性能下降相对较小,这表明即使在处理噪声文档时,我们提出的方法也具有鲁棒性。
6.3 引用分析
由于 NLI 模型的自动评估无法检测部分支持的引用,在本节中讨论了通过人工评估进行的引用分析。与 Liu 等的做法类似,在两个维度上进行人工评估:1)引用召回率 :评估员会被提供一个陈述和所有引用该陈述的文档,并被要求判断这些文档是否完全支持该陈述;2)引用精确度:给定一个陈述及其某一引用,评估员需要验证该引用是否完全支持、部分支持或不支持该陈述。如果输出句子中的引用召回率为 1,并且该引用至少部分支持该陈述,则该引用的精确度评分为 1。
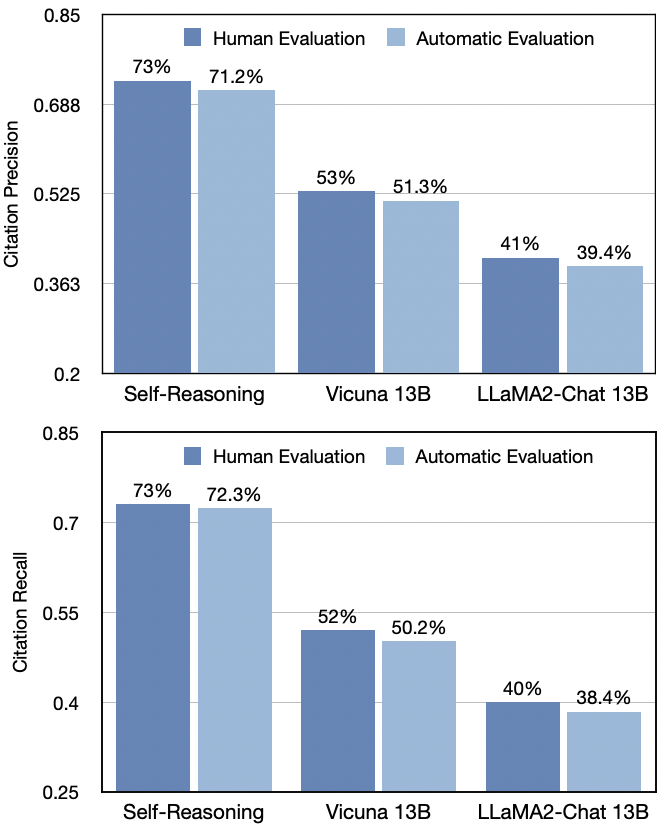
如图 4 所示,人工评估的相对排名与自动评估的结果非常一致,并且人工评估的得分通常比自动评估高。
7. 结论
作者提出了一种新颖的 SELF-REASONING 框架,通过利用 LLM 自身生成的推理轨迹来提升 RALMs 的性能。该框架包含了以下三个过程:相关性感知过程、证据感知选择过程和轨迹分析过程。
A 附录
A.1 更多与推理相关的语言模型研究
其中一种最著名的使用 LLMs 进行推理的方法是 Chain-of-Thought (CoT) ,它展示了 LLMs 创建其思维过程以解决问题的能力。Zhou等人提出了一个从简单到复杂的提示方法,用于解决复杂任务。Wang等人介绍了一种通过自我一致性进行推理的方法。Press等人提出了一个通过显式推理而不是隐式推理进一步改进思维链的方法。
最近的研究超越了 LLMs 的内部推理能力,纳入了与外部工具(例如搜索引擎或检索器)的互动来解决复杂任务。ReAct 提出了一个迭代范式,将推理与行动相结合,用于处理语言推理和决策任务。Xu等人介绍了一个框架,使信息检索和 LLMs 能够通过链式查询分解有效互动。Pan等人提出了一个名为 Chain-of-Action (CoA) 的新框架,它整合了推理检索方法,将复杂问题分解为一系列可配置的行动链。
与上述大多基于相对较大 LLMs (例如 ChatGPT ) 的工作不同,我们提出的方法专注于通过仅使用有限数量的样本来增强较小的 LLMs (例如 LLaMA2),以通过单步交互实现高鲁棒性和可解释性。
A.2 指令

图5
生成自我推理轨迹的 GPT-4 指令见图 5(短问答和长问答任务)和图 6(事实验证任务)。橙色字体中的词汇是需要生成的关键字段。

图6
A.3 数据集描述
NaturalQuestion (NQ) 包含真实用户向 Google 搜索发出的提问以及由标注员从维基百科找到的答案。NQ 的创建旨在训练和评估自动问答系统。
PopQA 是一个大规模开放领域问答数据集,包含以实体为中心的问答对。每个问题通过将从 Wikidata 检索到的知识三元组转换为模板生成。在这项工作中,我们使用 PopQA 来评估在长尾设置中的表现。
ASQA 是一个长形式的事实型数据集,大部分问题可以通过维基百科回答。每个问题来自 AmbigQA (Min et al., 2020),代表一个需要多个简短答案来覆盖不同方面的模糊查询。数据集提供了包含所有简短答案的长形式答案。
FEVER 是一个事实验证数据集,包含通过重写从维基百科提取的句子生成的声明,并在不知情的情况下进行验证。声明被分类为支持、反驳或信息不足。
A.4 实验设置
训练设置: 在逐步学习过程中,使用自我推理框架对 LLaMA-2 模型进行微调,训练 3 个epoch,批次大小设置为 32,利用 DeepSpeed 和 ZeRO 优化器,使用参数分区的 ZeRO 第三阶段,精度为 float16。第一阶段的学习率 r a r_a ra 设置为 5e-5,第二阶段的学习率 r b r_b rb 设置为 3e-5,最后阶段的学习率 r c r_c rc 设置为 1e-5。 SELF-REASONING 13B 模型在 NVIDIA Tesla 8 × V100 32GB GPU 上训练了 4 小时,而 7B 模型训练了 2 小时。
推理设置: 使用 vLLM 框架 来加速推理过程。在所有实验中使用贪婪解码以确保生成结果的确定性。我们测试了范围为 { 0.2 , 0.4 , 0.6 , 0.8 , 1.0 } \{0.2, 0.4, 0.6, 0.8, 1.0\} {0.2,0.4,0.6,0.8,1.0} 的温度,最终将温度设置为 0.2,因为我们观察到较低的温度在开放领域问答任务中能获得更好的性能。将最大生成长度设置为 2048。所有基线模型在短问答数据集上使用0-shot 设置,在长问答和事实验证数据集上使用1-shot 设置进行测试。
其他设置: 对于文档检索,我们检索前 k 个相关文档,其中 k 设置为 5。我们在短问答设置中使用 DPR 和 Contriever。在长问答中,我们使用 GTR 作为检索工具,并使用1-shot 设置来指导模型生成引用。对于数据生成质量控制设置,引用召回的阈值设置为 0.8,引用精度的阈值也设置为 0.8。
A.5 类别比较
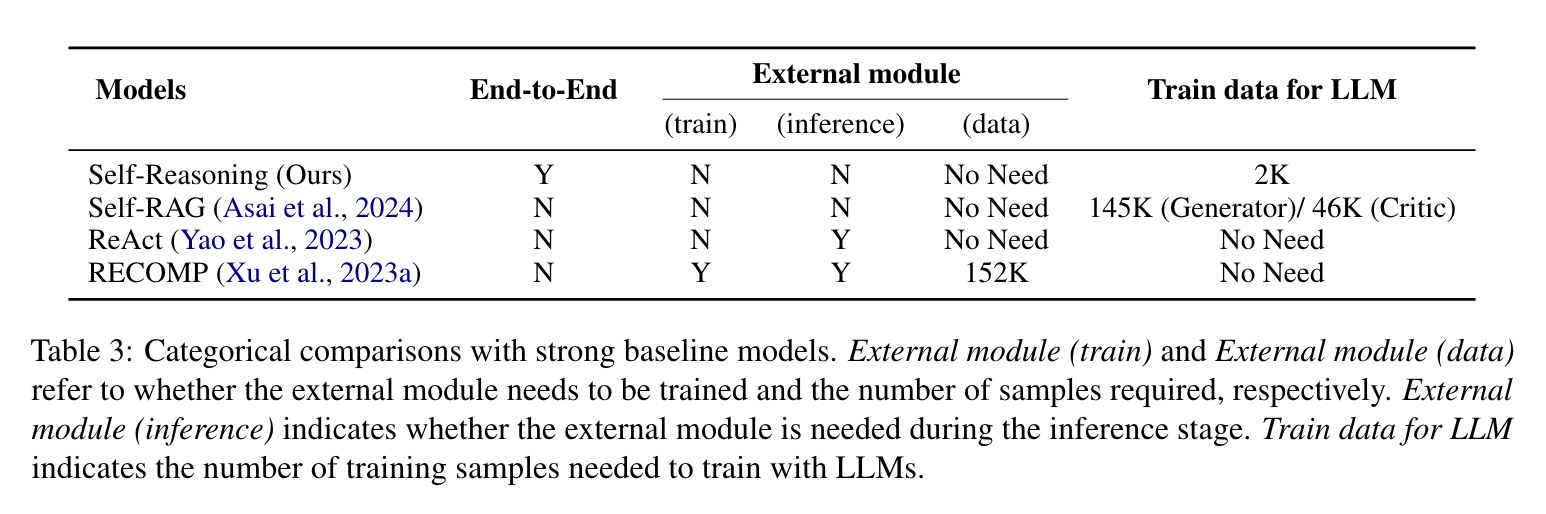
我们通过在六个维度上对比,区分我们的方法与现有强基线模型的不同,如表 3 所示。表中显示,我们的方法在几个关键方面表现突出。
首先,我们的 SELF-REASONING 方法是现有方法中唯一一个可以在不依赖外部模型或工具的情况下提升性能的端到端框架。其次,我们的方法在训练和推理阶段都无需外部模块。在实际应用中,我们的框架无需调用多个工具或模块。第三,我们的框架相比其他方法需要的训练数据集要小得多,仅需 2000 个包含自我推理轨迹的样本。
A.6 案例研究

在案例研究中,如图 7 所示,我们比较了原始 LLM、标准的 RALM(例如带有检索功能的 LLaMA2)和我们的 SELF-REASONING 方法生成的响应。挑战在于将来自多个检索文档的信息进行调和,以提供正确的答案,因为检索到的文档包含了噪声数据。
原始 LLM(如 LLaMA2)的响应显示,根据其固有的知识,该电影是在 2000 年制作的。然而,这个答案是不正确的,是 LLM 生成的幻觉。标准 RALM 方法则给出了 1989 年作为制作日期。这个答案基于从检索文档中获得的无关细节,显示了缺乏上下文特定理解和对噪声数据的鲁棒性。
我们的 SELF-REASONING 框架提供了一种全面的方法,通过评估检索文档的相关性和上下文来改进答案。首先,在相关性感知过程中,文档被识别为相关,因为它们涉及电影的制作日期和相关事件。其次,在证据感知选择过程中,模型检索了第一批文档,这些文档突出了电影的原始开始日期为 2002 年 1 月,拍摄开始于 2002 年 2 月(图中绿色突出显示)。这些信息对建立电影制作的时间线至关重要。模型还能够理解第三个检索文档中制作日期与发布日期之间的差异(图中红色突出显示)。在轨迹分析过程中,通过拼接自生成的轨迹,推断出电影Catch Me If You Can的确是在 2002 年制作的。正如上述案例所示,通过利用相关文档并关注上下文证据,我们的 SELF-REASONING 框架能够实现精准且有力支持的答案,突显了其在复杂信息检索任务中的实用性和鲁棒性。
A.7 消融研究的进一步分析
渐进学习的有效性
进一步验证了渐进学习的效果。与逐阶段训练的方法不同,最初将所有阶段的推理轨迹连接起来,然后将其输入到 LLM 中进行端到端的训练。如表 2 所示,在三个数据集中观察到了性能下降,这表明渐进学习可以帮助提高性能。
质量控制的有效性
还评估了数据生成中的质量控制效果。我们随机抽取了 2000 个未经过滤的训练样本,这些样本由 GPT-4 生成,而不是使用过滤后的高质量训练样本。如表 2 所示,用未经过滤的训练数据替代会导致模型结果的下降。
A.8 人工评估
从 ASQA 数据集中随机抽取了 100 个示例,并对选定模型的输出进行了标注。每个样本被分配给两个人进行标注。每位标注者需要根据提供的方案验证引用的召回率和引用的准确率。标注方案参考了Gao等人,具体如下:
引用召回率
标注者查看问题 q q q、陈述 s i s_i si 和所有相关的引用 C i C_i Ci,并评估这些引用集合是否完全支持陈述(召回率=1),或者是否没有支持所有主张(召回率=0)。通过平均所有陈述的召回率来计算模型的整体召回率得分。
引用准确率
标注者查看问题 q q q 和陈述 s i s_i si 以及其引用中的一个 c i ( k ) ∈ C i c^{(k)}_i ∈ C_i ci(k)∈Ci。我们要求标注者判断该引用是否完全支持、部分支持或不支持生成的陈述 s i s_i si。 如果 s i s_i si 的召回率为 1 且 c i ( k ) c^{(k)}_i ci(k) 完全或部分支持 s i s_i si,则引用 c i ( k ) c^{(k)}_i ci(k)的准确率为 1。最后,通过平均所有陈述的准确率得分来计算模型的整体准确率得分。
总结
⭐ 作者提出了一种新颖的自我推理框架,其核心思想是利用LLM自身生成的推理轨迹。该框架包括三个过程来构建自我推理轨迹:关注相关性的过程、证据选择性过程、一个轨迹分析过程。基于GPT4生成了2000个高质量的训练样本,提出了一种阶段性训练过程基于这些样本训练自我推理生成模型,声称效果很好,但是训练样本和训练好的模型都没有公开出来。