文章目录
-
- [1. 引言:为什么你的代码助手总是"差点意思"?------一场凌晨 2 点的生产力惨案](#1. 引言:为什么你的代码助手总是“差点意思”?——一场凌晨 2 点的生产力惨案)
- [2. 核心洞察:代码是图,不是文本 ------ 为什么传统切分必"翻车"?](#2. 核心洞察:代码是图,不是文本 —— 为什么传统切分必“翻车”?)
-
- [2.1 "文本刀法"的三大原罪](#2.1 “文本刀法”的三大原罪)
-
- [1. 语义连贯性被物理斩断(Semantic Decapitation)](#1. 语义连贯性被物理斩断(Semantic Decapitation))
- [2. 噪声泛滥与上下文窗口的极度浪费(Context Pollution)](#2. 噪声泛滥与上下文窗口的极度浪费(Context Pollution))
- [3. 依赖缺失:硬伤中的硬伤(Missing Dependencies)](#3. 依赖缺失:硬伤中的硬伤(Missing Dependencies))
- [3. 技术范式转移:引入 Tree-sitter 与 AST 结构化索引](#3. 技术范式转移:引入 Tree-sitter 与 AST 结构化索引)
-
- [3.1 降维打击的武器:Tree-sitter](#3.1 降维打击的武器:Tree-sitter)
- [3.2 节点元数据(Metadata)建模:构建代码知识图谱](#3.2 节点元数据(Metadata)建模:构建代码知识图谱)
- [3.3 Python 实战:如何用 Tree-sitter 提取精准结构](#3.3 Python 实战:如何用 Tree-sitter 提取精准结构)
- [4. 实战架构:两阶段图检索(Multi-hop Retrieval)的工作流](#4. 实战架构:两阶段图检索(Multi-hop Retrieval)的工作流)
-
- [Stage A:广度寻址(定位种子节点 Seed Nodes)](#Stage A:广度寻址(定位种子节点 Seed Nodes))
- [Stage B:深度补链(多跳遍历依赖图)](#Stage B:深度补链(多跳遍历依赖图))
- [5. 工程化细节与数学建模:如何科学分配 Context 预算?](#5. 工程化细节与数学建模:如何科学分配 Context 预算?)
-
- [5.1 启发式图注意力衰减模型](#5.1 启发式图注意力衰减模型)
- [5.2 Context Packer 的"两条硬规则"](#5.2 Context Packer 的“两条硬规则”)
- [6. 验收标准:代码助手的最终评测不在 Prompt,而在 CI/CD 流水线](#6. 验收标准:代码助手的最终评测不在 Prompt,而在 CI/CD 流水线)
- [7. 结语:从"复读机"到真正的"数字队友"](#7. 结语:从“复读机”到真正的“数字队友”)
摘要:在构建企业级代码库 Copilot 的道路上,无数团队在 Code RAG(Retrieval-Augmented Generation for Code)的"第一跪",往往不是因为大模型智商不够,而是因为底层的"切分与检索方式"从一开始就走错了方向。本文由浅入深,从底层抽象、数学建模、算法设计到工程架构,带你完成从"字符串暴力切分"到"AST 语法树结构化图检索"的认知飞跃与技术重构。
1. 引言:为什么你的代码助手总是"差点意思"?------一场凌晨 2 点的生产力惨案
想象这样一个典型的研发场景:凌晨 2 点,线上支付链路突然出现偶现的超时告警。你的开发团队满怀希望地打开了公司内部刚刚上线的"代码库 Copilot"。这个系统是你们 AI 团队花了两个月时间,用目前最流行的"向量数据库 + LangChain + 顶级大模型"搭建的 Code RAG POC(概念验证)系统。
开发人员焦急地在对话框输入:"如何处理 PayService 中的支付异常?"
几秒钟后,系统因为检索到了包含 pay 和 exception 关键词的注释,吐出了一大段看似非常相关的代码片段,并自信地给出了一段修复补丁。开发人员眼前一亮,立刻复制、粘贴------然后,IDE 的满屏红线给了他沉重一击。
生成的代码虽然"看起来很美",但根本编译不过!
- 缺少了关键的
PaymentRequestDTO定义; - 漏掉了
application.yml中的超时重试配置项; - 甚至连抛出的
InsufficientBalanceException异常类都没有 Import。
这种深深的挫败感,我相信做过 AI 辅助研发工具的同行都经历过。它的根源到底在哪里?
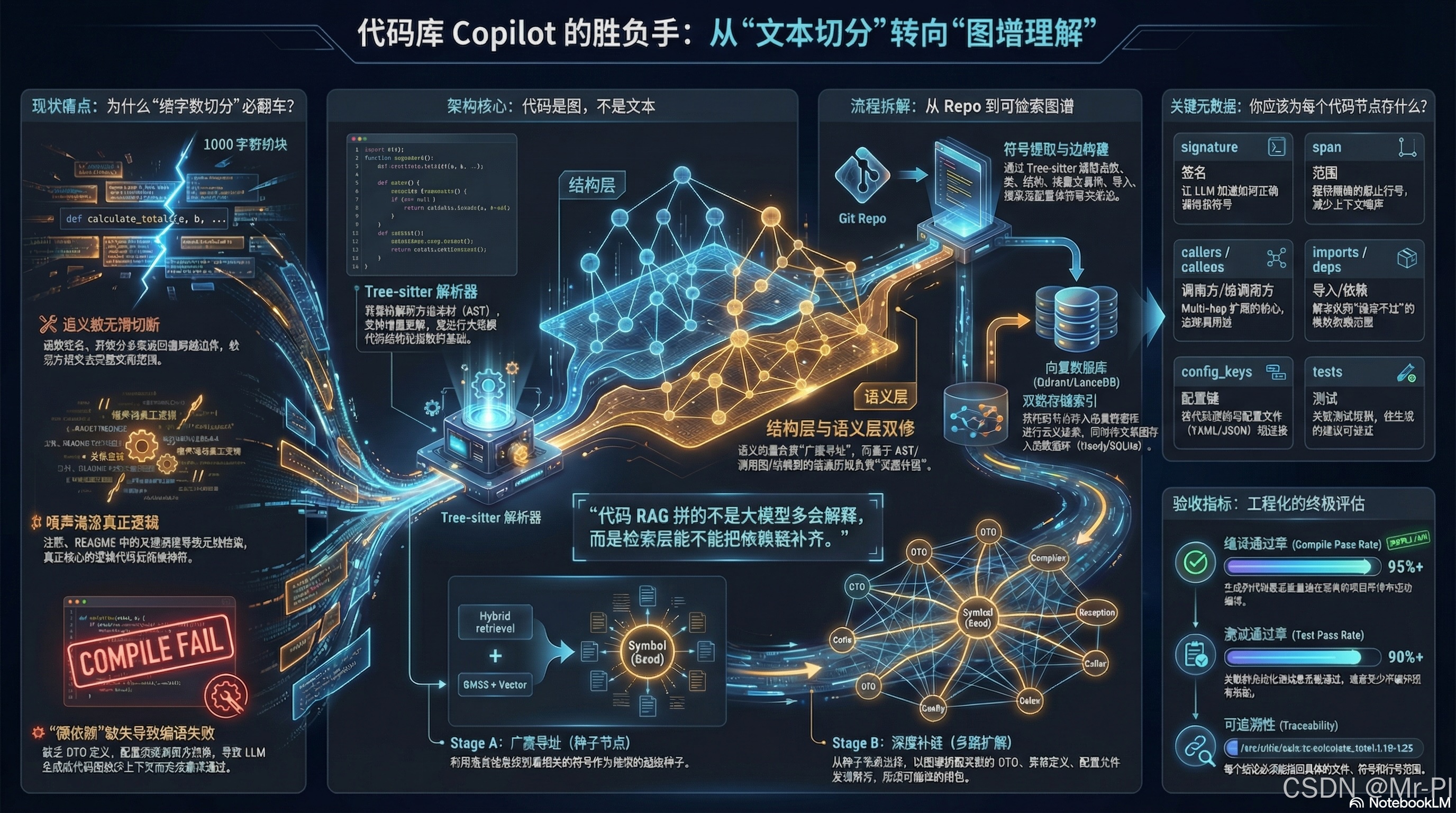
核心痛点在于:代码不是散文,而是高度结构化的有向无环图(DAG/Graph)。
很多团队在做 Code RAG 时,直接复用了处理维基百科、新闻小说的"切文章"逻辑(例如 LangChain 中的 RecursiveCharacterTextSplitter,按 1000 个字符生硬切分)。这就好比用一把剁骨头的菜刀,去给病人做精密的大脑神经显微外科手术------你虽然切下了一块肉(代码片段),但也无情地切断了最关键的逻辑神经(上下文依赖、类型定义、函数调用栈)。
2. 核心洞察:代码是图,不是文本 ------ 为什么传统切分必"翻车"?
让我们从系统架构师的视角,重新审视将整个 Repo(代码仓库)当成纯文本进行线性切分,在生产环境中为什么几乎等同于"生产事故"。
2.1 "文本刀法"的三大原罪
1. 语义连贯性被物理斩断(Semantic Decapitation)
假设我们有一个 1500 字符长的复杂方法。如果按 1000 字符切分,一个完整的函数签名可能留在了 Chunk A,而其核心的 switch-case 业务逻辑或 return 语句却被甩到了 Chunk B。
检索层即便通过向量相似度命中了 Chunk A,大模型拿到的也是一个"没有下半身"的残缺函数,它只能靠幻觉(Hallucination)去瞎猜后半段。
2. 噪声泛滥与上下文窗口的极度浪费(Context Pollution)
代码库中充满了无意义的注释(比如 // TODO: fix this later)、README.md 中的冗余关键词、甚至是自动生成的 Getters/Setters。传统的向量检索极其容易被这些高频词汇干扰。由于大模型的 Context Window 极其宝贵(即使是 128K 窗口,在处理大量代码时也会面临"Lost in the Middle"中间注意力丢失问题),把毫无逻辑价值的纯文本垃圾塞给模型,是对算力的极大浪费。
3. 依赖缺失:硬伤中的硬伤(Missing Dependencies)
这是最致命的问题。LLM 要生成一段**"能跑"**的代码,不仅仅需要知道当前的函数逻辑,还需要:
- 输入输出:相关的 DTO(Data Transfer Object)定义是什么?
- 外部约束:全局的配置项(JSON/YAML)限制是什么?
- 异常处理:上游系统会捕获哪些定制化异常?
"代码 RAG 拼的根本不是'大模型有多会解释',而是'底层检索系统能不能把完整的依赖链条找齐并喂给模型'。"
函数签名、异常分支和配置文件之间的关联,是文本切分完全无法捕捉的。代码的本质是符号(Symbols)间的引用与依赖,这种"隐性结构"才是 RAG 检索层的真正战场。
3. 技术范式转移:引入 Tree-sitter 与 AST 结构化索引
要解决上述问题,我们必须进行一次底层的技术范式转移:从"基于字符串模式匹配的处理"走向"基于编译原理的语法树解析"。
3.1 降维打击的武器:Tree-sitter
我们引入 Tree-sitter,这是一个为各种编程语言生成具体语法树(CST)并支持极速增量更新的解析工具。相比于直接使用 Python 的 ast 模块或 Java 的 JDT,Tree-sitter 具备跨语言统一接口、容错性强(代码有语法错误也能解析)等企业级特性。
通过 Tree-sitter,我们可以实现**"结构化切分"(AST Chunking)**。
**原则是:**永远以函数(Function/Method)、类(Class/Struct)、接口(Interface)或配置块(Config block)作为最小检索单元(Chunk),绝不在逻辑中间下刀。
根据 cAST (2025) 等前沿研究论文证明,基于 AST 的代码切分与检索方式,能将代码生成任务的准确率(Pass@1)提升 40% 以上。
3.2 节点元数据(Metadata)建模:构建代码知识图谱
为了确保生成的代码不仅"能看"而且"能跑",我们在构建向量数据库和图数据库索引时,每个代码节点(AST Node)必须存储极其精细的元数据。这是一个架构师必须烂熟于心的 Schema:
| 字段名称 | 类型 | 说明 | 对编译/生成的实际意义 |
|---|---|---|---|
symbol_id |
String | 稳定 ID(如 com.app.PayService.handle) |
实现前端 UI 的点击溯源与审计回放,是全局唯一标识 |
file_path |
String | 文件绝对/相对路径 | 关键! 用于生成 Git Patch 补丁与 IDE 精准跳转 |
signature |
String | 函数签名或类声明头 | 让 LLM 明确调用方式,无需加载全量方法体代码 |
span |
Tuple | 起止行号与字符范围 (start_row, end_row) |
精确引用原始代码,减少 Context 拼接时的重叠噪声 |
callers |
List | 调用图中的上游节点 ID 列表 | 构建图数据库的边(Edge),用于寻找是谁调用了我 |
callees |
List | 调用图中的下游节点 ID 列表 | 多跳扩展的核心! 寻找我依赖了哪些底层方法 |
imports |
List | 模块依赖关系(包级引入) | 解决"为什么编译不过"的根本问题,补齐依赖环境 |
config_keys |
List | 关联的配置项路径(如 YAML 中的 pay.timeout) |
将逻辑代码与 DevOps 环境配置彻底打通 |
tests |
List | 关联的测试用例方法 ID | 驱动 TDD(测试驱动生成),提供可验证的输出闭包 |
commit_hash |
String | 索引时的 Git 版本哈希 | 关键! 防止"版本漂移"导致旧索引覆盖新代码的误引用 |
3.3 Python 实战:如何用 Tree-sitter 提取精准结构
下面是一段简化版的 Python 代码,展示如何从"字符串切分"走向"结构化提取":
python
from tree_sitter import Language, Parser
# 1. 初始化 Tree-sitter 语言模型 (以 Python 为例)
Language.build_library('build/my-languages.so', ['tree-sitter-python'])
PY_LANGUAGE = Language('build/my-languages.so', 'python')
parser = Parser()
parser.set_language(PY_LANGUAGE)
source_code = b"""
def process_payment(order_id: str, amount: float) -> bool:
'''处理核心支付逻辑'''
if amount <= 0:
raise ValueError("Invalid amount")
user = db.get_user(order_id)
return payment_gateway.charge(user.account, amount)
"""
# 2. 解析生成语法树
tree = parser.parse(source_code)
# 3. 使用 Query 语法精准提取函数和依赖 (类似 XPath)
query = PY_LANGUAGE.query("""
(function_definition
name: (identifier) @func.name
parameters: (parameters) @func.params
return_type: (type) @func.return
body: (block) @func.body
) @function
(call
function: (attribute attribute: (identifier) @call.method)
) @method_call
""")
captures = query.captures(tree.root_node)
# 4. 组装结构化 Chunk
chunk_metadata = {}
callees =[]
for node, tag in captures:
if tag == 'func.name':
chunk_metadata['symbol_id'] = node.text.decode('utf8')
elif tag == 'function':
chunk_metadata['code_content'] = node.text.decode('utf8')
chunk_metadata['span'] = (node.start_point, node.end_point)
elif tag == 'call.method':
callees.append(node.text.decode('utf8'))
chunk_metadata['callees'] = list(set(callees)) # 提取到依赖:['get_user', 'charge']
print(chunk_metadata)通过这种方式入库的代码 Chunk,才是有生命力、带有网络拓扑结构的"活数据"。
4. 实战架构:两阶段图检索(Multi-hop Retrieval)的工作流
当底层数据结构从"文本"升级为"带属性的有向图"后,我们的检索架构也必须随之升级。一个成熟的企业级代码 RAG 架构应分为语义层(Semantic Layer) 和 结构层(Structural Layer)。
我们用 Mermaid 绘制出这个两阶段检索的宏观架构:
Context Assembly
Stage B: 深度补链 (多跳遍历依赖图)
Stage A: 广度寻址 (定位种子节点)
Vector/Embedding
BM25/Keyword
Hop 1: callees
Hop 1: exceptions
Hop 2: configs
Hop 1: callers
格式化 Prompt
User Query: '如何处理支付异常?'
Hybrid Search
Vector DB
ElasticSearch
Reranker 模型
Seed Nodes 种子节点集合
e.g. PayService.handle
Graph Engine 遍历图数据库
获取 PayRequest DTO
获取 PaymentException
获取 application.yml 配置
获取单元测试
Context Packer
上下文预算分配器
LLM 代码生成
Stage A:广度寻址(定位种子节点 Seed Nodes)
在这个阶段,目标是在浩如烟海的代码库中找到"入口"。
这里有一个必须避开的坑:在代码库场景中,绝对不要只靠向量(Vector)检索!
代码中包含了大量的专有名词、业务缩写和错误码。大模型的 Embedding 模型往往对长尾的内部方法名(如 doWxPayBizV2)缺乏理解。因此,Hybrid 检索(向量相似度 + 关键词 BM25)是必不可少的现实主义手段。
找到相关性最高的几个代码片段后,我们将它们定义为"种子节点(Seed Nodes)"。
Stage B:深度补链(多跳遍历依赖图)
一旦锁定种子节点(如 PayService.handle),系统立刻从"纯粹的自然语言检索"切换到"图式计算机科学检索"模式。沿着 AST 提取出的依赖边进行多跳遍历:
- 抓取依赖(Downstream) :从种子节点出发,获取其内部调用的
AliPayClient.query接口签名,以及作为入参出参的PayRequest/PayResponseDTO 类。 - 获取约束(Constraints) :提取该逻辑中抛出的
PaymentException类的定义,以及方法内部引用的application.yml中的超时配置。 - 获取参考(Upstream):反向查询调用图,拉取上游调用方的约束条件,并关联同目录下的单元测试用例。单元测试是极佳的 Few-shot Prompt!
通过多跳检索,最终交给 Context Packer 打包给大模型的,不再是一堆支离破碎的文本碎片,而是一个逻辑严密、自包含、甚至理论上可以直接拉起本地编译器的依赖闭包(Dependency Closure)。
5. 工程化细节与数学建模:如何科学分配 Context 预算?
理论很美好,但一到工程落地,新问题又来了:上下文爆炸(Context Explosion)。
企业级项目里,一个核心方法可能间接调用了几百个底层类,如果把所有依赖的源码都塞进去,哪怕是 200K 窗口的模型也会因为冗余信息过多而智商降级,且推理成本(Token 费用)和延迟(Latency)将是灾难性的。
作为一个算法架构师,你必须设计一个精确的 Token 预算分配策略(Budget Allocation Strategy)。
5.1 启发式图注意力衰减模型
设大模型的输入窗口总预算为 B B B (tokens)。对于检索出来的图节点集合 V = { v 1 , v 2 , . . . , v n } V = \{v_1, v_2, ..., v_n\} V={v1,v2,...,vn},我们需要决定每个节点分配多少 token(即展示源码、还是只展示函数签名,或者直接丢弃)。
我们可以定义第 i i i 个节点 v i v_i vi 的综合评分 S ( v i ) S(v_i) S(vi) 为:
S ( v i ) = α ⋅ Rerank ( Q , v i ) + β ⋅ exp ( − λ ⋅ Dist ( v s e e d , v i ) ) S(v_i) = \alpha \cdot \text{Rerank}(Q, v_i) + \beta \cdot \exp(-\lambda \cdot \text{Dist}(v_{seed}, v_i)) S(vi)=α⋅Rerank(Q,vi)+β⋅exp(−λ⋅Dist(vseed,vi))
其中:
- Rerank ( Q , v i ) \text{Rerank}(Q, v_i) Rerank(Q,vi):语义层计算出的 Query 与节点的文本相关性打分。
- Dist ( v s e e d , v i ) \text{Dist}(v_{seed}, v_i) Dist(vseed,vi):该节点在调用图上距离种子节点的最短路径跳数(Hops)。
- λ \lambda λ:距离衰减系数(比如每多一跳,重要性指数级下降)。
- α , β \alpha, \beta α,β:调节语义与结构权重的超参数。
接着,计算节点的归一化权重 w i w_i wi:
w i = S ( v i ) ∑ j = 1 n S ( v j ) w_i = \frac{S(v_i)}{\sum_{j=1}^{n} S(v_j)} wi=∑j=1nS(vj)S(vi)
那么,分配给该节点 v i v_i vi 的预算 b i b_i bi 为:
b i = min ( b max , ⌊ B ⋅ w i ⌋ ) b_i = \min(b_{\max}, \lfloor B \cdot w_i \rfloor) bi=min(bmax,⌊B⋅wi⌋)
(注: b max b_{\max} bmax 是单个节点的大小上限,防止某个巨型类耗尽所有预算。)
5.2 Context Packer 的"两条硬规则"
在工程实现这个数学模型时,必须在代码层面加上兜底的"硬规则":
- 近邻优先(Nearest Neighbor First):距离种子节点为 1 的依赖(直接调用的方法签名、直接引用的 DTO 结构)拥有绝对的最高分配权重。如果预算紧张,远跳的节点只保留签名(Signature),不展示具体实现(Body)。
- 去重优先(Deduplication) :代码图常常存在菱形依赖(多个路径指向同一个文件或基础类库)。在装填 Prompt 时,必须通过
symbol_id进行全局去重。只保留最高评分的那一次引用,坚决避免 Context 空间浪费。
6. 验收标准:代码助手的最终评测不在 Prompt,而在 CI/CD 流水线
当我们搭建好这一套"重装武器"后,如何向老板或技术委员会证明它的 ROI?
过去,很多团队评估 AI 助手,就像评估聊天机器人一样:找几个工程师问几个问题,看看 AI 回答得"流利不流利"、"态度好不好"。这在研发领域简直是闹剧。
"评估一个代码助手,不要看它对话是否幽默,而要看它在工程链路上的硬核表现。"
我们需要将视角从"对话框(Chat UI)"转向"持续集成(CI Pipeline)",引入以下三大核心工程指标进行严格的自动化评测(类似业界知名的 SWE-bench 评测体系):
- Compile Pass Rate (编译通过率)
- 定义 :LLM 生成的修复补丁或新增代码,应用到沙盒环境中,能否直接通过
mvn clean compile或npm run build? - 本质:检验你的结构化图检索是否完美补齐了所有 DTO、Imports 和配置项等环境依赖。
- 定义 :LLM 生成的修复补丁或新增代码,应用到沙盒环境中,能否直接通过
- Test Pass Rate (测试通过率)
- 定义:生成的代码编译通过后,运行现有的单元测试(Unit Tests)或集成测试,成功率是多少?有没有引入破坏现有逻辑的回退(Regression)?
- 本质:检验模型是否真正理解了代码边界条件,你的 RAG 检索层是否正确提供了相关的上下文约束。
- Traceability (可溯源性)
- 定义:在 Copilot 生成的每一段代码解释中,涉及到的类名、方法名,是否能在 UI 上变成一个高亮的可点击链接,并精准跳转回代码库的对应行数?
- 本质 :检验 AST Metadata(如
file_path,span,commit_hash)是否在全链路中完整透传。这是建立开发者对 AI 信任感的最关键产品特性!
python
# 一个极简的自动化验证伪代码思路:
def evaluate_copilot_generation(query: str, repo_path: str):
# 1. 触发架构获取生成代码
patch_code = my_copilot.generate_patch(query)
# 2. 自动应用 Patch 到沙盒
apply_patch_to_sandbox(repo_path, patch_code)
# 3. 拦截 CI 结果
compile_result = run_command("cd sandbox && mvn clean compile")
if not compile_result.success:
return "Failed at Compile: Dependencies Missing"
test_result = run_command("cd sandbox && mvn test")
if not test_result.success:
return "Failed at Test: Logic Regression"
return "Pass!"7. 结语:从"复读机"到真正的"数字队友"
从 LangChain 中几行简单的 TextSplitter,进化到动用 Tree-sitter、图数据库、多跳检索与预算分配算法构建的仓库级结构化知识图谱(RepoGraph),这不是把简单问题复杂化,而是代码辅助开发迈向真正"生产力工具"必经的涅槃与质变。
传统的文本 RAG,仅仅打造了一个会"背诵散文的复读机";
而基于 AST 结构化图检索的 RAG,则孕育了一个能够洞悉整个系统架构、理解全量依赖闭包的**"数字高级架构师队友"**。
当 AI 具备了这种如同上帝视角般的上下文掌控力时,AI 原生研发的(AI-Native Engineering)大门才算真正开启。
最后,留给各位技术同行一个思考题:
当你的 AI 能够毫无遗漏地理解你整个庞大代码仓库的依赖闭包,完全掌握那些盘根错节的祖传代码时,你最想让它帮你重构哪一个满是技术债的陈旧模块?欢迎在评论区交流你的痛点!
继续分别阅读RAG 五大应用场景 :
(零)总论
(一)
(二)
(四)法务合同合规系统
(五)