LSTM与Transformer的结合,作为深度学习中的一项创新技术,近年来在学术界和工业界引起了广泛关注。这种混合模型巧妙地融合了LSTM在处理序列数据时的长短期记忆能力与Transformer在捕捉长距离依赖关系方面的优势,从而在文本生成、机器翻译和时间序列预测等多个领域取得了显著的性能提升。
为了促进对这一技术更深入的理解和应用,我们精心挑选了近两年内发表的20篇关于LSTM+Transformer的前沿论文。这些论文不仅涵盖了最新的研究成果,还提供了相关的数据集和代码实现,为研究人员和实践者提供了宝贵的资源和灵感。

三篇论文详解
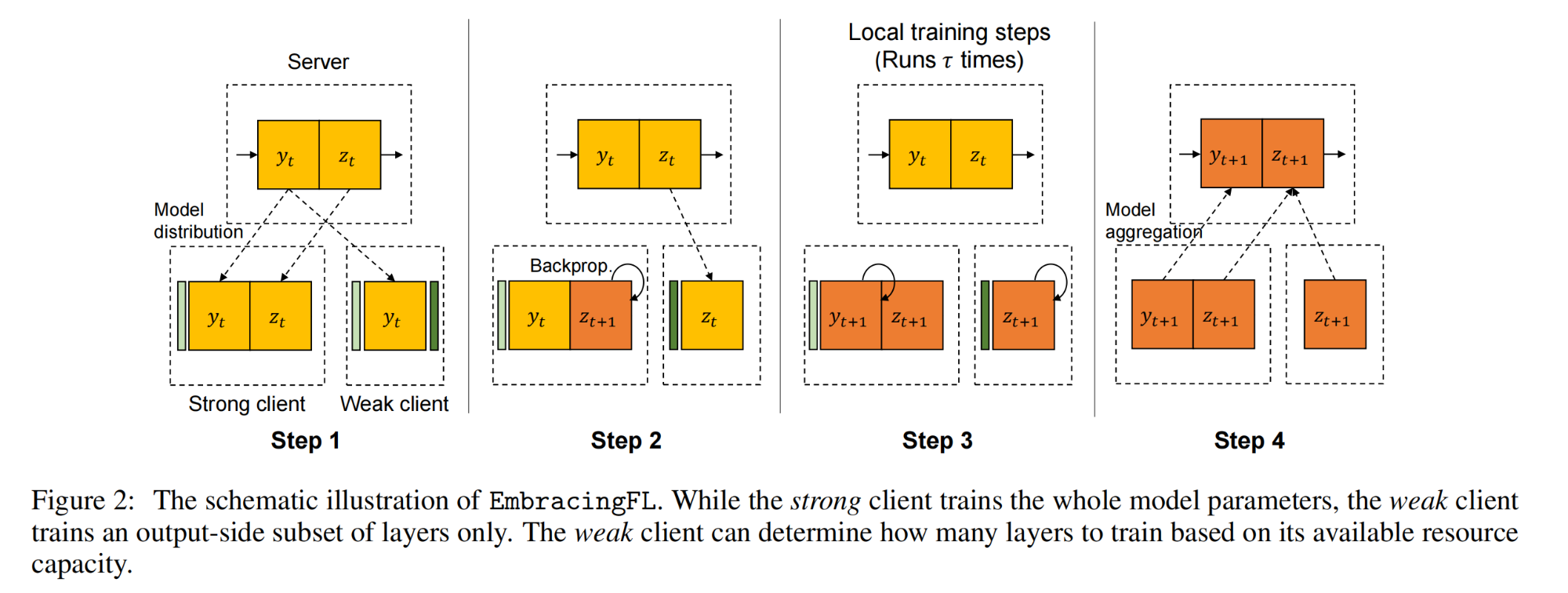
1. Embracing Federated Learning: Enabling Weak Client Participation via Partial Model Training
方法
-
本文提出了一种名为EmbracingFL的联邦学习(FL)框架,旨在通过部分模型训练方法,使所有可用客户端(无论其系统资源如何)都能参与分布式训练。
-
该框架建立在一种新颖的部分模型训练方法上,每个客户端根据自己的系统资源能力训练连续的输出层。
-
采用多步前向传播(multi-step forward pass)策略,弱客户端只接收其内存空间允许的输入层数量,执行前向传播,记录输出激活矩阵,并丢弃当前层以接收下一层。
-
在弱客户端上进行局部训练,只对分配的输出层子模型执行反向传播,从而减少内存占用和计算工作量。
-
通过理论分析,证明了EmbracingFL在非凸和光滑问题上保证收敛到静止点附近的区域,即使在弱客户端数量和分配给他们的层数不同的情况下。
创新点
-
创新性地提出了一种层级部分训练策略,允许弱客户端只训练模型的一部分,而不是整个模型,这在以往的研究中并不常见。
-
通过SVCCA(奇异向量典型相关分析)量化了不同客户端之间输出数据的相似性,发现输出层在客户端之间具有可区分的模式,这为部分模型训练方法提供了理论支持。
-
提出了一种多步前向传播算法,显著减少了弱客户端的内存占用和计算成本,同时保持了模型架构的一致性,简化了实现复杂性。
-
通过实验验证了EmbracingFL在多种设置下的有效性,包括不同的客户端数量、数据集和模型,展示了其在异构环境中的高准确性和鲁棒性。
-
引入了对比学习(contrastive learning)来增强模型对数据的表示能力,通过联合学习策略提高了模型对标签噪声和数据不平衡的鲁棒性。
-
证明了EmbracingFL在保持高准确度的同时,能够显著减少弱客户端的计算和通信负担,为实际大规模FL应用提供了一种可行的解决方案。
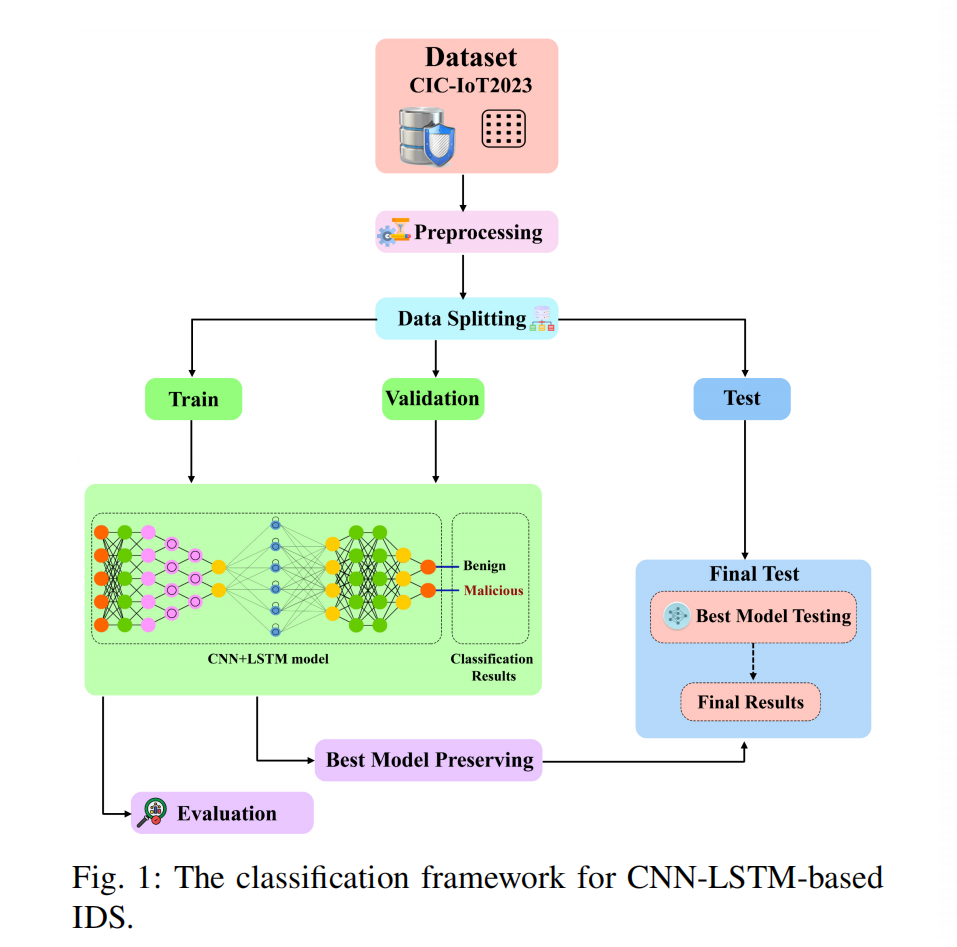
2.Enhancing IoT Security with CNN and LSTM-Based Intrusion Detection Systems
方法
-
该论文提出了一种基于卷积神经网络(CNN)和长短期记忆网络(LSTM)的混合模型,用于增强物联网(IoT)设备的安全性。
-
该模型结合了CNN的空间特征提取能力和LSTM的序列记忆保持能力,以识别和分类IoT流量为良性或恶意活动。
-
数据预处理:原始数据集包含45个不同特征,包括33种不同的攻击实例和正常流量。数据被组织成矩阵形式以便于模型训练,并转换为二维数据以符合模型输入要求,同时对标签进行了二进制转换。
-
数据分割:将预处理的数据集分为训练集和验证集,以及最终测试集。训练集占80%,验证集占20%,以评估模型性能。
-
模型架构:提出的模型采用多层结构,包括输入层、一维CNN层、平均池化层、展平层和密集层。模型首先接收45个特征的序列,然后应用一系列卷积层、批量归一化和平均池化层来提取特征和模式。接着,使用ReLU激活函数的密集层将特征转换为更高层次的表示。最后,通过softmax激活函数的密集层进行二分类预测。
创新点
-
混合模型的提出:将CNN和LSTM结合,利用CNN进行模式识别和LSTM进行复杂时间依赖性的识别,提高了检测和分类的准确性和效率。
-
新数据集的应用:使用了新的CICIoT2023数据集进行训练和最终测试,该数据集包含七类33种攻击,涵盖了物联网网络流量中的典型和新兴攻击类型。
-
性能评估:通过使用CICIDS2017数据集进行进一步的测试,验证了模型的泛化能力,确保了模型在不同数据集上的性能评估。
-
高准确率和低误报率:所提出的模型在CICIoT2023数据集上达到了98.42%的准确率和0.0275的最小损失,同时保持了9.17%的低误报率和98.57%的F1分数。
-
实时应用潜力:论文提出未来工作将考虑在实时场景中实施模型,例如在Raspberry Pi或FPGA上部署,以评估模型在实际环境中的表现。
-
模型改进方向:论文提出了未来工作的方向,包括使用所有CICIoT2023数据集进行更深入的分析,以及考虑集成Transformer模型,如注意力层,以进一步提高性能。
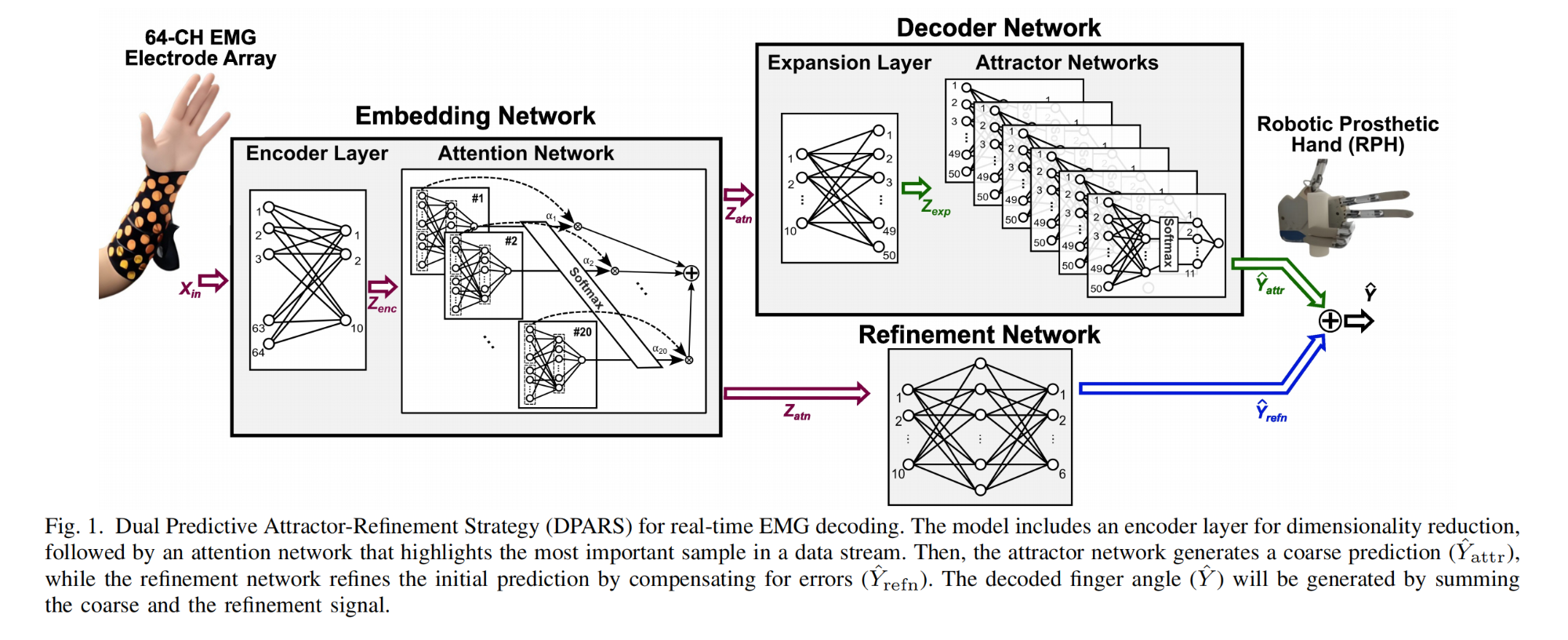
3. Hardware-Efficient EMG Decoding for Next-Generation Hand Prostheses
方法
-
本文提出了一种新颖的基于吸引子(attractor-based)的神经网络,用于实现下一代便携式机器人假手(RPHs)的芯片级运动解码。
-
所提出的架构包括一个编码器(encoder)、一个注意力层(attention layer)、一个吸引子网络(attractor network)和一个细化回归器(refinement regressor)。
-
该模型在四个健康受试者上进行了测试,达到了80.6±3.3%的解码准确率。
-
该模型与现有的LSTM和CNN模型相比,分别紧凑了120倍和50倍以上,同时保持了可比的(或更优越的)解码准确率。
-
该模型通过减少计算次数,在保持准确性的同时显著降低了复杂性,适合作为系统级芯片(System-on-Chip)有效集成。
创新点
-
吸引子网络:引入了一种新颖的基于吸引子的网络,用于提取最可能的状态(吸引子),并根据它们的概率分布进行预测,这模仿了手指自然倾向于保持特定位置的特性。
-
双重预测策略:提出了双重预测吸引器-细化策略(DPARS),该策略首先基于吸引子提供粗略估计,然后使用轻量级回归器进行细化,以提高RPHs运动的自然性。
-
硬件效率:通过显著降低模型大小和减少计算量,实现了硬件效率,使得模型非常适合轻量级、易于获取的AI驱动的假手,这对改善截肢者的生活质量具有重要意义。
-
编码器和注意力网络的结合:使用编码器网络进行降维,以及注意力网络关注数据流中最重要的样本,提高了预测的准确性并降低了计算负担。
-
熵正则化:在目标函数中使用熵项来提取吸引子,通过仅分配几个高度可能的状态到吸引子集,减少了计算次数,提高了解码的准确性。
-
模型紧凑性:所提出的DPARS模型在参数数量上大大减少,与现有模型相比,实现了更高的紧凑性,这对于硬件实现来说是一个显著的优势。
-
实时EMG解码:模型能够实时解码EMG信号,这对于实现假手的实时控制和提高用户满意度至关重要。