《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,全书共分10章,第1章主要让读者认识数据资产,了解数据资产相关的基础概念,以及数据资产的发展情况。第2~8章主要介绍大数据时代数据资产管理所涉及的核心技术,内容包括元数据的采集与存储、数据血缘、数据质量、数据监控与告警、数据服务、数据权限与安全、数据资产管理架构等。第9~10章主要从实战的角度介绍数据资产管理技术的应用实践,包括如何对元数据进行管理以发挥出数据资产的更大潜力,以及如何对数据进行建模以挖掘出数据中更大的价值。
图书介绍:数据资产管理核心技术与应用
今天主要是给大家分享一下第四章的内容:
第四章的标题为数据质量的技术实现
内容思维导图如下:
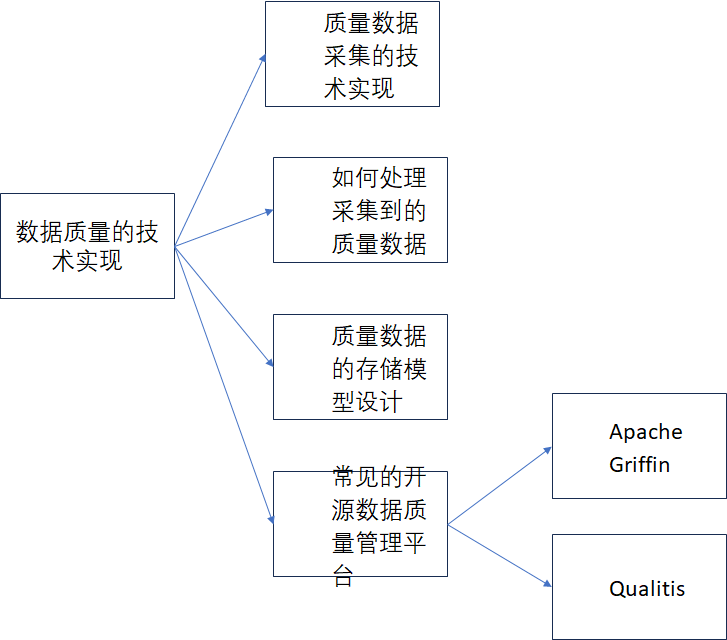
本文是接着
《数据资产管理核心技术与应用》读书笔记-第四章:数据质量的技术实现(一)
继续往下介绍
1、质量数据采集的技术实现
当然除了借助Apache DolphinSchedur外,我们也可以自己实现定时任务运行,相关的技术架构图如下图所示。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
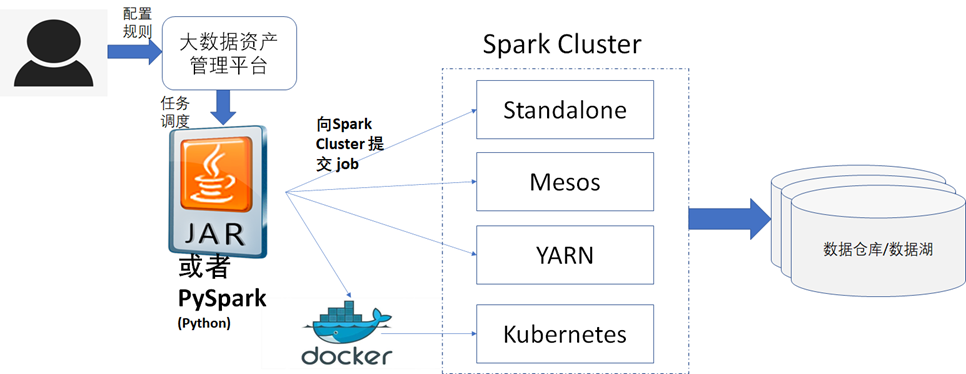
- 由于不管是数据湖还是数据仓库,都支持Spark 对其做数据读取和数据处理,所以对数据湖或者数据仓库的质量数据采集都可以通过在Spark集群中执行Spark任务的方式去获取数据。Spark 集群的部署支持Standalone、Mesos、YARN、Kubernetes 四种方式,可以参考Spark官方网址:https://spark.apache.org/docs/latest/cluster-overview.html#cluster-manager-types,如下图所示,可以根据实际使用的数据湖或者数据仓库的部署模式,来选择相应的Spark 集群的部署模式,比如您的数据仓库Hive 是通过Hadoop的方式部署的,那么Spark集群的部署方式就应该选择Hadoop YARN的部署模式更加合适。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著

- 设计一个Spark集群上可以执行的jar包或者PySpark脚本,该Jar包或者PySpark脚本用于提交任务到Spark集群中进行运行 ,运行时,读取配置好的质量规则,任务执行完毕后,将采集到的质量结果数据入库,关于如何向Spark集群提交Jar包或者PySpark脚本任务,可以参考官网网址:https://spark.apache.org/docs/latest/submitting-applications.html,如下图所示。
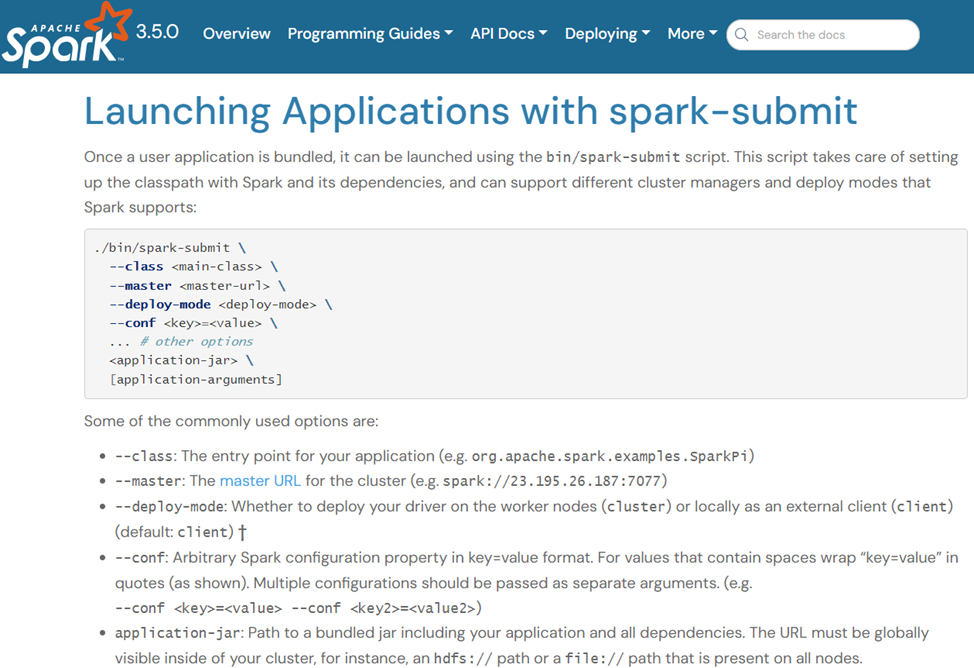
- Jar包或者PySpark脚本中可以执行Spark SQL语句,也可以执行Scala脚本或者Python脚本。
- 如果Spark 集群是通过Kubernetes部署的,那么需要先将Jar包或者PySpark脚本 做成Docker 镜像,然后通过镜像的方式将Jar包或者PySpark脚本运行至Spark 集群中,如下图所示,关于Kubernetes相关的知识可以参考:https://kubernetes.io/zh-cn/docs/home/ 。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著

- Jar包或者Python 脚本,需要做成通用的,而不是执行每一个质量规则时都需要去创建一个jar包或者Python 脚本,当然也可以支持用户自定义Jar包或者Python 脚本进行扩展,但是一定要定义Jar包或者Python 脚本的抽象接口,如下图所示。
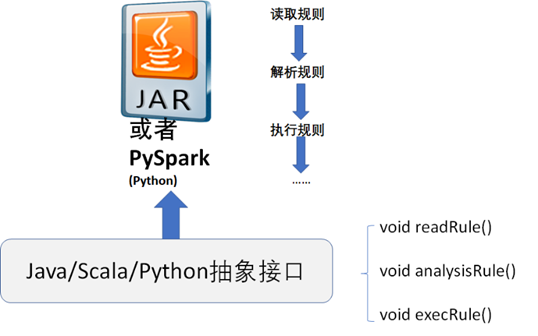
从图中可以看到,我们至少可以在抽象接口中先预定义好读取规则、解析规则以及执行规则等这几个方法,使用Java开发语言定义的抽象接口参考代码如下:《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
public interface Example { void readRule(String rule); void analysisRule(String rule); void execRule(String data);}根据上面描述的数据质量规则的配置到数据质量规则的定时采集执行,可以大致设计如下图的表结构模型供参考。

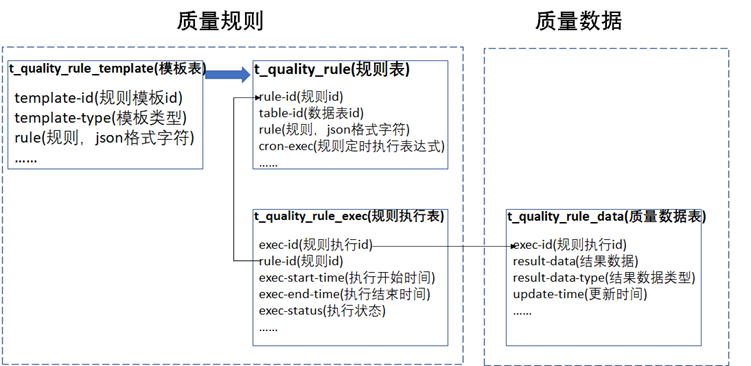
1)、t_quality_rule_template为数据质量规则模板表,可以将一些通用的规则做成模板,供规则的配置者直接使用或者基于选择的规则模板再做少量的二次修改。
2)、t_quality_rule为数据质量规则配置表,表中存储了实际的数据质量采集规则以及该规则对应的数据表id以及定时采集的cron表达式,比如类似0 */30 * * * ?,就是每隔30分钟执行一次。
cron 表达式是一个字符串,该字符串通常是由 7 个域组成,每个域之间以空格格式,每个域代表一个特定的时间含义,如下表所示。
|-------|----------------|
| 域 | 取值范围 |
| 秒 | 0-59 |
| 分 | 0-59 |
| 时 | 0-23 |
| 日 | 1-31 |
| 月 | 1-12 或 JAN-DEC |
| 周 | 1-7 或 SUN-SAT |
| 年 | 1970-2099 |
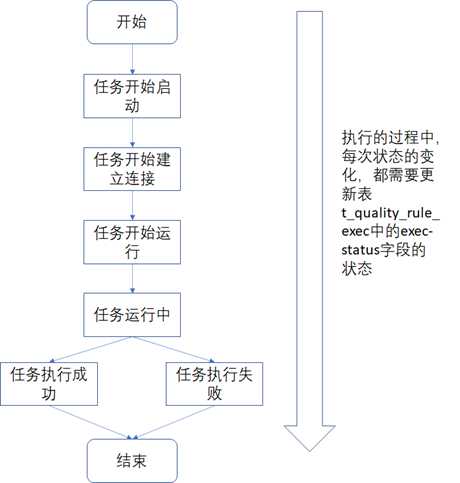
3)、t_quality_rule_exec为数据质量规则执行表,表中存储了每次定时采集任务的执行记录。定时采集任务执行时,其状态的变化过程大致如下图所示,为了方便问题的定位,任务执行过程中的状态变化都需要更新到表t_quality_rule_exec中。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
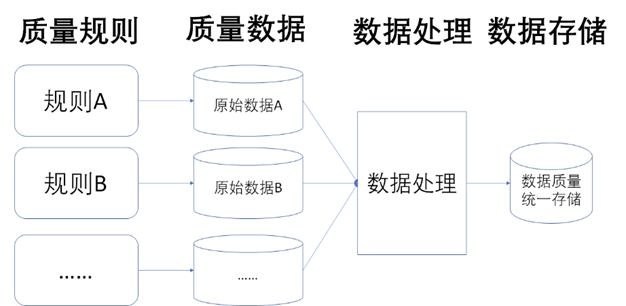
2、 如何处理采集到的质量数据
质量数据采集到的是原始的数据,由于数据质量规则众多,所以每一种规则采集到的原始数据可能都不一样,所以还需要对原始的数据做归一化处理,然后才能进行入库存储,如下图所示。
虽然每个质量规则采集到的原始数据可能都是不一样的,但是我们还是需要设计一个统一的原始数据消息格式以方便做数据的统一处理,参考如下:
[{ "execId": "", "ruleId": "", "returnType": "", "returnData": [], "startExecTime": "", "endExecTime": ""}]
3、质量数据的存储模型设计从架构设计的角度来看,数据质量的存储需要注意如下几点:
- 可扩展性: 支持对多种不同质量规则采集到的质量数据的存储,比如不能出现扩展了质量规则或者用户自定义的质量规则的结果数据无法存储,从而需要修改数据存储模型的情况。
- 可跟踪性:需要记录质量数据的变更记录,方便将来做质量数据变化的跟踪和审查。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
- 可维护性:支持手工运维,比如出现脏数据或者需要人工干预的情况时,可以让系统管理员进行相关的历史数据或者脏数据的清理等常规运维操作。
如下图所示基于上述的设计原则,设计了如下的数据质量存储模型供参考,下中在每张表中列出了数据质量存储模型的核心字段。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
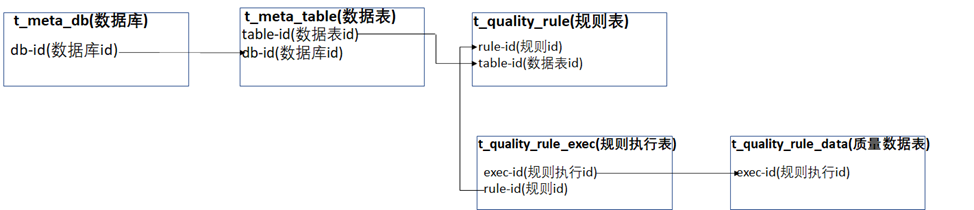
如果需要查询某张表的质量数据时,可以根据如下图所示的关联关系来获取数据。
质量数据其实和常用的监控数据很类似,也可以考虑用时序数据库来进行存储,因为质量数据都是按照时间来时序采集的,并且数据也是时序变化的,所以使用时序数据库来存储是非常适合的。常见的时序数据库对比介绍如下表所示,可以根据实际的场景来选择。《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著
|-----------|-----------------------------------------------|-----------------------------|------------------------------------------------|
| 数据库类型 | InfluxDB | Prometheus | OpenTSDB |
| 描述 | 用于存储时间序列、事件和度量的开源时序数据库 | 开源时序数据库,一般多用于监控系统 | 基于HBase的可扩展的时间序列开源数据库 |
| 官方网址 | https://www.influxdata.com/products/influxdb/ | 官方网址为https://prometheus.io/ | 官方网址为http://opentsdb.net/ |
| 文档介绍 | https://docs.influxdata.com/influxdb | https://prometheus.io/docs/ | http://opentsdb.net/docs/build/html/index.html |
| 底层实现的开发语言 | Go | Go | Java |
| 支持的数据类型 | 数字和字符串 | 只支持数字 | 指标支持数字 ,标签支持字符串 |
| 是否支持SQL语言 | 支持类SQL查询(和SQL语法类似) | 不支持 | 不支持 |
| API类型 | Http API | RESTful Http/JSON API | Http API |
未完待续......《数据资产管理核心技术与应用》是清华大学出版社出版的一本图书,作者为张永清等著