端到端 - UniAD: Planning-oriented Autonomous Driving - 以规划为导向的自动驾驶(CVPR 2023)
- 摘要
- [1. 引言](#1. 引言)
- [2. 方法](#2. 方法)
-
- [2.1. 感知:跟踪和建图](#2.1. 感知:跟踪和建图)
- [2.2. 预测:运动预测](#2.2. 预测:运动预测)
- [2.3. 预测:占用预测](#2.3. 预测:占用预测)
- [2.4. 规划](#2.4. 规划)
- [2.5. 学习](#2.5. 学习)
- [3. 实验](#3. 实验)
-
- [3.1. 联合结果](#3.1. 联合结果)
- [3.2. 模块化结果](#3.2. 模块化结果)
- [3.3. 定性结果](#3.3. 定性结果)
- [3.4. 消融研究](#3.4. 消融研究)
- [4. 结论和今后的工作](#4. 结论和今后的工作)
- References
- 附录
- [A. 任务定义](#A. 任务定义)
- [B. 每项任务的必要性](#B. 每项任务的必要性)
- [C. 相关工作](#C. 相关工作)
-
- [C.1. 联合感知和预测](#C.1. 联合感知和预测)
- [C.2. 联合预测与规划](#C.2. 联合预测与规划)
- [C.3. 端到端运动规划](#C.3. 端到端运动规划)
- [D. 符号](#D. 符号)
- [E. 实施细节](#E. 实施细节)
-
- [E.1. 检测与跟踪](#E.1. 检测与跟踪)
- [E.2. 在线建图](#E.2. 在线建图)
- [E.3. 运动预测](#E.3. 运动预测)
- [E.4. 占用预测](#E.4. 占用预测)
- [E.5. 规划](#E.5. 规划)
- [E.6. 训练详情](#E.6. 训练详情)
- [F. 实验](#F. 实验)
-
- [F.1. 协议](#F.1. 协议)
- [F.2. 指标](#F.2. 指标)
- [F.3. 模型复杂性和计算成本](#F.3. 模型复杂性和计算成本)
- [F.4. 模型尺寸](#F.4. 模型尺寸)
- [F.5. 定性结果](#F.5. 定性结果)
声明:此翻译仅为个人学习记录
文章信息
- 标题:UniAD: Planning-oriented Autonomous Driving (CVPR 2023)
- 作者:Yihan Hu1,2*, Jiazhi Yang1*, Li Chen1*†, Keyu Li1*, Chonghao Sima1, Xizhou Zhu3,1, Siqi Chai2, Senyao Du2, Tianwei Lin2, Wenhai Wang1, Lewei Lu3, Xiaosong Jia1, Qiang Liu2, Jifeng Dai1, Yu Qiao1, Hongyang Li1† (* Equal contribution, † Project lead)
- 文章链接:https://arxiv.org/pdf/2212.10156
- 文章代码:https://github.com/OpenDriveLab/UniAD
摘要
现代自动驾驶系统的特点是按顺序执行模块化任务,即感知、预测和规划。为了执行各种各样的任务并实现高级智能,当代方法要么为单个任务部署独立模型,要么设计一个具有独立头部的多任务范式。然而,他们可能会出现累积错误或任务协调不足。相反,我们认为应该设计并优化一个有利的框架,以实现最终目标,即自动驾驶汽车的规划。为此,我们重新审视了感知和预测中的关键组成部分,并对任务进行了优先级排序,以便所有这些任务都有助于规划。我们介绍了Unified Autonomous Driving(UniAD),这是一个最新的综合框架,将全栈驾驶任务整合到一个网络中。它经过精心设计,可以利用每个模块的优势,并从全局角度为代理交互提供互补的特征抽象。任务通过统一的查询界面进行沟通,以便于彼此进行规划。我们在具有挑战性的nuScenes基准上实例化了UniAD。通过广泛的消融,使用这种思想体系的有效性得到了证明,在所有方面都远远优于以前的最新技术。代码和模型是公开的。
1. 引言
随着深度学习的成功发展,自动驾驶算法由一系列任务(1在以下上下文中,我们可互换地使用任务、模块、组件、单元和节点来表示某个任务(例如检测)。)组成,包括感知中的检测、跟踪、建图;以及预测中的运动和占用预测。如图1(a)所示,只要板载芯片的资源带宽允许,大多数行业解决方案都会为每个任务独立部署独立模型68,71。尽管这种设计简化了跨团队的研发难度,但由于优化目标的隔离,它存在跨模块信息丢失、错误累积和特征错位的风险57,66,82。
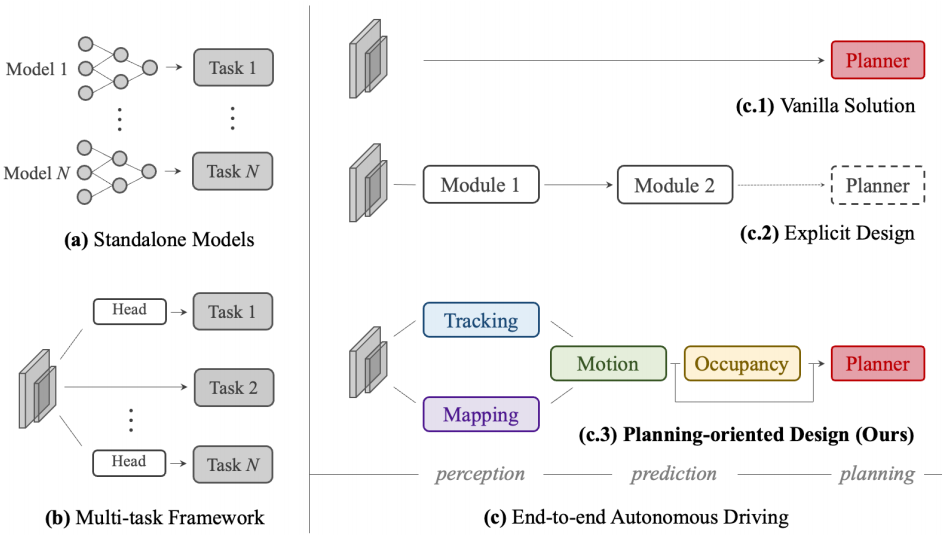
图1. 自动驾驶框架各种设计的比较。(a)大多数工业解决方案为不同的任务部署单独的模型。(b) 多任务学习方案共享一个由多个任务头组成的主干。(c) 端到端范式将感知和预测模块结合在一起。之前的尝试要么在(c.1)中对规划进行直接优化,要么在(c.2)中设计具有部分组件的系统。相反,我们在(c.3)中认为,一个理想的系统应该以规划为导向,并适当组织前面的任务以促进规划。
一种更优雅的设计是通过将多个特定任务的头部插入共享特征提取器中,将广泛的任务纳入多任务学习(MTL)范式,如图1(b)所示。这在许多领域都是一种流行的做法,包括通用视觉79,92,108、自动驾驶(2在本文中,我们将自动驾驶中的MTL称为超越感知的任务。关于感知中的MTL有很多工作,例如检测、深度、流动等。这种文献超出了范围。)15,60,101,105,如Transfuser20、BEV-erse105,以及工业化产品,如Mobileye68、Tesla87、Nvidia71等。在MTL中,跨任务的联合训练策略可以利用特征抽象;它可以毫不费力地扩展到其他任务,并节省板载芯片的计算成本。然而,这种方案可能会导致不希望的"负转移"23,64。
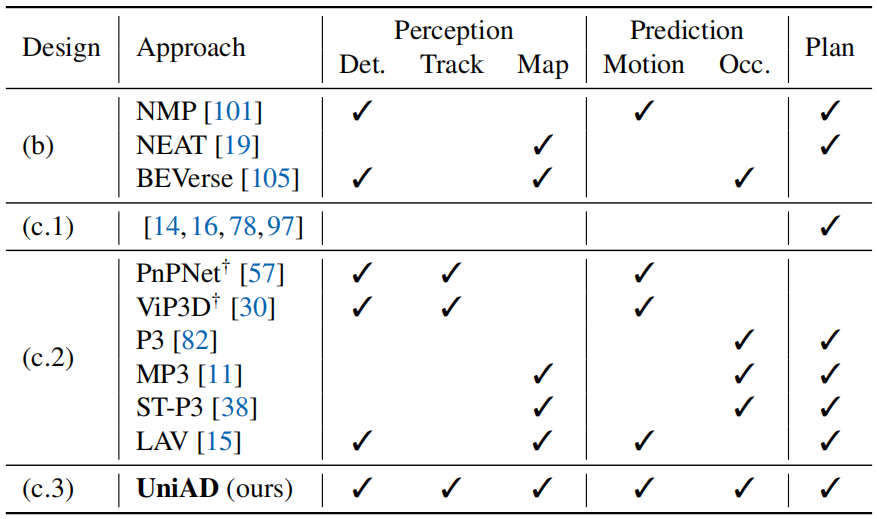
表1. 任务比较和分类。"设计"栏的分类如图1所示。"Det."表示3D目标检测,"Map"表示在线建图,"Occ."表示占用地图预测。†:这些作品不是直接为规划而提出的,但它们仍然具有共同感知和预测的本质。UniAD执行五项基本驾驶任务以便于规划。
相比之下,端到端自动驾驶的出现11,15,19,38,97将感知、预测和规划的所有节点作为一个整体。应确定优先任务的选择和优先级,以利于规划。该系统应以规划为导向,精心设计,涉及某些组件,这样就不会像独立选项那样出现累积误差,也不会像MTL方案那样出现负转移。表1描述了不同框架设计的任务分类。
遵循端到端范式,一种"白板"实践是直接预测规划的轨迹,而不需要对感知和预测进行任何明确的监督,如图1(c.1)所示。开创性工作14,16,21,2,78,95,97106在闭环仿真中验证了这种香草设计26。虽然这一方向值得进一步探索,但在安全保障和可解释性方面存在不足,特别是对于高度动态的城市场景。在这篇论文中,我们倾向于另一种观点,并提出以下问题:对于一个可靠且面向规划的自动驾驶系统,如何设计有利于规划的管道?哪些前面的任务是必需的?
一个直观的解决方案是感知周围的物体,预测未来的行为,并明确地规划一个安全的方法,如图1(c.2)所示。当代方法11,30,38,57,82提供了很好的见解,并取得了令人印象深刻的成绩。然而,我们认为魔鬼在于细节;以前的工作或多或少没有考虑到某些组成部分(见表1中的块(c.2)),让人想起以规划为导向的本质。我们在补充中详细阐述了这些模块的详细定义和术语以及必要性。
为此,我们引入了UniAD,这是一个统一的自动驾驶算法框架,可以利用五个基本任务来构建一个安全稳健的系统,如图1(c.3)和表1(c.3)所示。UniAD是以规划为导向本质的设计。我们认为,这不是一堆简单的任务,而不仅仅是工程工作。一个关键组件是连接所有节点的基于查询的设计。与经典的边界框表示法相比,查询受益于更大的接受域,以减轻上游预测的复合误差。此外,查询可以灵活地对各种交互进行建模和编码,例如多个代理之间的关系。据我们所知,UniAD是第一个全面研究自动驾驶领域感知、预测和规划等多种任务联合合作的工作。
贡献摘要如下。(a) 我们秉持以规划为导向的理念,对自动驾驶框架进行了新的展望,并证明了有效任务协调的必要性,而不是独立设计或简单的多任务学习。(b) 我们介绍UniAD,这是一个全面的端到端系统,利用了广泛的任务。启动的关键组件是作为连接所有节点的接口的查询设计。因此,UniAD具有灵活的中间表示和交换多任务知识以进行规划。(c) 我们在现实场景的具有挑战性的基准上实例化了UniAD。通过广泛的消融,我们验证了我们的方法在各个方面都优于先前的技术水平。
我们希望这项工作能够为自动驾驶系统的目标驱动设计提供一些启示,为协调各种驾驶任务提供一个起点。
2. 方法
概述 。如图2所示,UniAD包括四个基于变换器解码器的感知和预测模块,最后还有一个规划器。查询Q的作用是连接管道,以模拟驾驶场景中实体的不同交互。具体来说,将一系列多相机图像输入特征提取器,并通过BEVFormer中的现成BEV编码器将得到的透视图特征转换为统一的鸟瞰图(BEV)特征B55。请注意,UniAD不限于特定的BEV编码器,可以利用其他替代方案通过长期时间融合31,74或多模态融合58,64提取更丰富的BEV表示。在TrackFormer 中,我们称之为跟踪查询的可学习嵌入从B查询代理的信息,以检测和跟踪代理。MapFormer 将地图查询视为道路元素(如车道和分隔带)的语义抽象,并对地图进行全景分割。通过上述表示代理和地图的查询,MotionFormer 捕获代理和地图之间的交互,并预测每个代理的未来轨迹。由于每个代理的动作都会对场景中的其他代理产生重大影响,因此该模块会对所有考虑的代理进行联合预测。同时,我们设计了一个自车查询来显式地建模自车,并使其能够在这种以场景为中心的范式中与其他代理进行交互。OccFormer 采用BEV特征B作为查询,配备智能代理知识作为关键字和值,并在保留代理身份的情况下预测多步未来占用。最后,Planner利用MotionFormer中富有表现力的自车查询来预测规划结果,并远离OccFormer预测的占用区域,以避免碰撞。
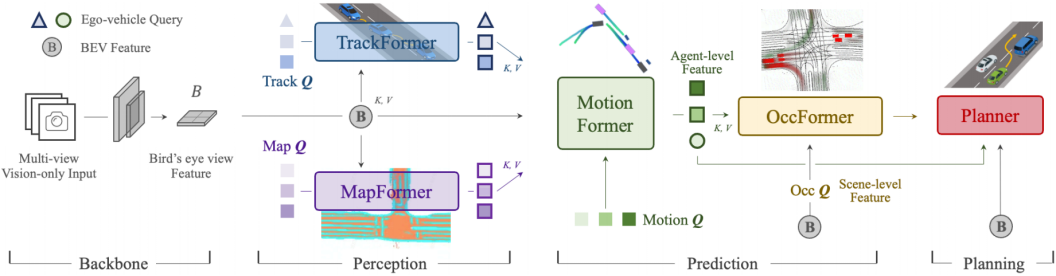
图2: 统一自动驾驶(UniAD)管道。它是按照以规划为导向的理念精心设计的。我们不是简单的任务堆栈,而是研究每个模块在感知和预测中的作用,利用从前面的节点到驾驶场景中的最终规划的联合优化的好处。所有感知和预测模块都采用变压器解码器结构设计,任务查询作为连接每个节点的接口。最后,一个简单的基于注意力的规划器考虑从前面的节点中提取的知识来预测自车的未来航路点。占用地图仅用于视觉目的。
2.1. 感知:跟踪和建图
TrackFormer 。它联合执行检测和多目标跟踪(MOT),而无需进行不可微分的后处理。受100, 104的启发,我们采用了类似的查询设计。除了在目标检测8, 109中使用的传统检测查询外,还引入了额外的跟踪查询来跨帧跟踪代理。具体来说,在每个时间步,初始化的检测查询负责检测第一次被感知的新代理,而跟踪查询则继续对在先前帧中检测到的代理进行建模。检测查询和跟踪查询都通过关注BEV特征B来捕获代理抽象。随着场景的不断发展,当前帧的跟踪查询与自注意力模块中先前记录的查询进行交互,以聚合时间信息,直到相应的代理完全消失(在某个时间段内未被跟踪)。与8类似,Track Former包含N层,最终输出状态QA为下游预测任务提供了Na有效代理的知识。除了对自车周围的其他代理进行编码的查询外,我们还在查询集中引入了一个特定的自车查询,以显式地对自动驾驶车辆本身进行建模,这进一步用于规划。
MapFormer 。我们基于二维全景分割方法 Panoptic SegFormer设计了它56。我们稀疏地将道路元素表示为地图查询,以帮助下游运动预测,并对位置和结构知识进行编码。对于驾驶场景,我们将车道、分隔带和十字路口设置为things,将可驾驶区域设置为stuff50。MapFormer还有N个堆叠层,每层的输出结果都受到监督,而只有最后一层中更新的查询QM被转发给MotionFormer进行代理地图交互。
2.2. 预测:运动预测
最近的研究已经证明了transformer结构在运动任务上的有效性43,44,63,69,70,84,99,受此启发,我们在端到端的设置中提出了MotionFormer。通过分别从 TrackFormer 和 MapFormer 中提取动态代理 QA 和静态地图 QM 的高度抽象查询,MotionFormer以场景为中心的方式预测所有代理的多模态未来运动,即 top-k 个可能的轨迹。这种范式在具有单个正向通道的框架中产生了多代理轨迹,这大大节省了将整个场景与每个代理的坐标对齐的计算成本49。同时,我们将来自 TrackFormer 的自车查询通过 MotionFormer 进行传递,以使自车与其他代理进行交互,并考虑未来的动态。从形式上讲,输出运动被公式化为 { x ^ i , k ∈ R T × 2 ∣ i = 1 , . . . , N a ; k = 1 , . . . , K } \{\hat{x}_{i,k}∈\mathbb{R}^{T×2}|i=1,...,N_a;k=1,...,K\} {x^i,k∈RT×2∣i=1,...,Na;k=1,...,K},其中 i 表示代理,k 表示轨迹模态,T 是预测时域的长度。
MotionFormer 。它由 N 层组成,每层捕获三种类型的交互:代理-代理、代理-地图和代理-目标点。对于每个运动查询 Q i , k Q_{i,k} Qi,k(稍后定义,为简单起见,在下文中省略下标 i, k),它与其他代理 QA 或地图元素 QM 之间的交互可以表示为:
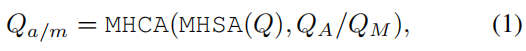
其中 MHCA、MHSA 分别表示多头交叉注意力和多头自注意力91。由于关注预期位置(即目标点)以细化预测轨迹也很重要,我们通过可变形注意力109设计了一种代理-目标点注意力机制,如下所示:
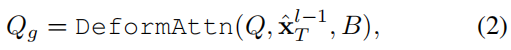
其中 x ^ T l − 1 \hat{x}T^{l-1} x^Tl−1是前一层预测轨迹的终点。DeformAttn(q,r,x) 是一个可变形的注意力模块,它接收查询 q、参考点 r 和空间特征 x。它对参考点周围的空间特征执行稀疏注意力。通过这种方式,预测的轨迹在意识到端点环境的情况下得到了进一步的细化。所有三种交互都是并行建模的,其中生成的 Qa、Qm 和 Qg 被连接并传递给多层感知器(MLP),从而得到查询上下文 Q c t x Q{ctx} Qctx。然后, Q c t x Q_{ctx} Qctx被发送到后续层进行细化,或在最后一层作为预测结果进行解码。
运动查询 。MotionFormer每一层的输入查询称为运动查询,包括两个组件:如前所述,前一层生成的查询上下文 Q c t x Q_{ctx} Qctx和查询位置 Q p o s Q_{pos} Qpos。具体来说, Q p o s Q_{pos} Qpos将位置知识整合为四个方面,如方程式(3)所示:(1)场景级锚点 I s I^s Is的位置;(2) 代理级锚点 I a I^a Ia的位置;(3)代理 i 的当前位置和(4)预测的目标点。
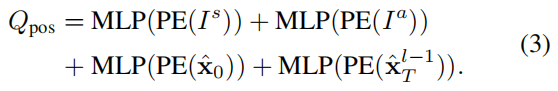
这里使用正弦位置编码 PE(·) 和 MLP 对位置点进行编码,并在第一层将 x ^ T 0 \hat{x}^0_T x^T0设置为 I s I^s Is(下标 i、k 也省略了)。场景级锚点表示全局视图中的先前运动统计数据,而代理级锚点捕获局部坐标中的可能意图。它们都通过k-means算法在真值轨迹的端点上进行聚类,以缩小预测的不确定性。与先前的知识相反,起点为每个代理提供定制的位置嵌入,预测的终点作为一个动态锚点,以从粗到细的方式逐层优化。
非线性优化。与直接访问真值感知结果(即代理的位置和相应的轨迹)的传统运动预测工作不同,我们在端到端范式中考虑了先前模块的预测不确定性。从不完美的检测位置或航向角粗略地回归真值航路点可能会导致曲率和加速度较大的不切实际的轨迹预测。为了解决这个问题,我们采用了一种非线性平滑器7来调整目标轨迹,并在上游模块预测的不精确起点下使其在物理上可行。该过程是:
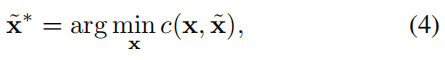
其中, x ~ \widetilde{x} x 和 x ~ ∗ \widetilde{x}^∗ x ∗ 表示真值和平滑轨迹,x 由 multiple-shooting 产生3,成本函数如下:
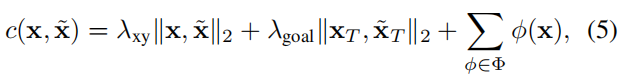
其中 λ x y λ_{xy} λxy 和 λ g o a l λ_{goal} λgoal是超参数,运动学函数集Φ有五个项,包括急动度、曲率、曲率率、加速度和横向加速度。成本函数使目标轨迹正则化以遵守运动学约束。这种目标轨迹优化仅在训练中进行,不影响推理。
2.3. 预测:占用预测
占用网格图是一种离散的BEV表示,其中每个单元格都有一个信念,指示它是否被占用,占用预测任务是发现网格图在未来如何变化。以前的方法利用RNN结构从观测到的BEV特征中对未来的预测进行时间扩展35,38,105。然而,它们依赖于高度手工制作的聚类后处理来生成每个代理的占用图,因为它们通过将BEV特征作为一个整体压缩为RNN隐藏状态,基本上与代理无关。由于代理知识的使用不足,他们很难在全球范围内预测所有代理的行为,这对于理解场景的演变至关重要。为了解决这个问题,我们提出OccFormer在两个方面结合场景级和代理级语义:(1)密集场景特征在展开到未来视野时通过精心设计的注意力模块获取代理级特征;(2) 我们通过在代理级特征和密集场景特征之间进行矩阵乘法,无需进行大量后处理,即可轻松生成实例占用。
OccFormer 由 To 连续块组成,其中 To 表示预测范围。请注意,由于密集表示占用的高计算成本,在运动任务中 To 通常小于 T。每个块都将前一层的富代理特征 Gt 和状态(密集特征)Ft-1 作为输入,并考虑实例和场景级信息为时间步长 t 生成 Ft。为了获得具有动力学和空间先验的代理特征 Gt,我们在表示为 Q X ∈ R N a × D Q_X∈\mathbb{R}^{N_a×D} QX∈RNa×D的模态维度上最大化 MotionFormer 的池运动查询,其中 D 为特征维度。然后,我们通过时间特定的 MLP 将其与上游跟踪查询 QA 和当前位置嵌入 PA 融合:
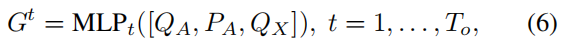
其中 · 表示连接。对于场景级知识,为了提高训练效率,BEV 特征 B 被缩小到 1/4 分辨率,作为输入 F0 的第一个块。为了进一步节省训练存储,每个块都遵循降采样-升采样方式,中间有一个注意力模块,以 1/8 的降尺度特征(表示为 F d s t F^t_{ds} Fdst)进行像素代理交互。
像素代理交互 旨在在预测未来占用时统一场景和代理级别的理解。我们将密集特征 F d s t F^t_{ds} Fdst 作为查询,将实例级特征作为键和值,以随时间更新密集特征。具体来说, F d s t F^t_{ds} Fdst通过一个自关注层来模拟远距离网格之间的响应,然后通过一个跨关注层来建模代理特征 Gt 和每个网格特征之间的交互。此外,为了对齐像素-代理对应关系,我们通过一个注意力掩码来约束交叉注意力,该掩码限制每个像素只查看在时间步长 t 占据它的代理,灵感来自17。密集特征的更新过程公式如下:
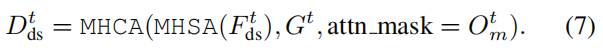
注意力掩码 O m t O^t_m Omt 在语义上类似于占用,是通过将额外的代理级特征和密集特征 F d s t F^t_{ds} Fdst 相乘而生成的,其中我们将代理级特征命名为掩码特征 M t = M L P ( G t ) M^t=MLP(G^t) Mt=MLP(Gt) 。在等式(7)中的交互过程之后, D d s t D^t_{ds} Ddst 被上采样到 B 的 1/4 大小。我们进一步将 D d s t D^t_{ds} Ddst 与块输入 F t − 1 F^{t-1} Ft−1 相加作为残差连接,并将得到的特征 F t F^t Ft 传递给下一个块。
实例级占用 . 它代表了保留每个代理身份的占用情况。它可以简单地通过矩阵乘法来绘制,就像最近基于查询的分割工作一样18,52。形式上,为了得到 BEV 特征 B 的原始大小 H×W 的占用预测,场景级特征 F t F^t Ft 通过卷积解码器上采样到 F d e c t ∈ R C × H × W F^t_{dec}∈\mathbb{R}^{C×H×W} Fdect∈RC×H×W,其中 C 是信道维数。对于代理级特征,我们进一步通过另一个 MLP 将粗掩模特征 M t M^t Mt 更新为占用特征 U t ∈ R N a × C U^t∈\mathbb{R}^{N_a×C} Ut∈RNa×C。我们实证发现,从掩模特征 M t M^t Mt 而不是原始代理特征 G t G^t Gt 生成 U t U^t Ut 可以获得更优的性能。时间步长 t 的最终实例级占用为:

2.4. 规划
没有高清(HD)地图或预定义路线的规划通常需要一个高级命令来指示前进的方向11,38。在此之后,我们将原始导航信号(即左转、右转和向前行驶)转换为三个可学习的嵌入,称为命令嵌入。由于MotionFormer的自车查询已经表达了其多模态意图,我们为其配备了命令嵌入,形成了一个"规划查询"。我们对BEV特征B进行规划查询,使其了解周围环境,然后将其解码为未来的航路点 τ ^ \hat{τ} τ^。
为了进一步避免碰撞,我们仅通过以下方式基于牛顿推理方法优化 τ ^ \hat{τ} τ^:
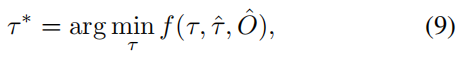
其中 τ ^ \hat{τ} τ^是原始规划预测, τ ∗ τ^∗ τ∗表示优化规划,从 multiple-shooting3 轨迹 τ τ τ 中选择,以最小化成本函数 f(·)。 O ^ \hat{O} O^是一个经典的二进制占用图,由OccFormer的实例占用预测合并而成。成本函数 f(·) 的计算公式为:
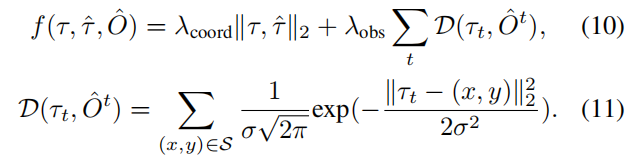
这里 λ c o o r d λ_{coord} λcoord、 λ o b s λ_{obs} λobs 和 σ 是超参数,t 表示未来视界的时间步长。 l 2 l_2 l2成本将轨迹拉向原始预测的轨迹,而碰撞项D将其推离被占用的网格,考虑到周围位置被限制在 S = { ( x , y ) ∣ ∣ ∣ ( x , y ) − τ t ∣ ∣ 2 < d , O ^ x , y t = 1 } S=\{(x,y)|||(x,y)-τ_t||2<d,\hat{O}^t{x,y}=1\} S={(x,y)∣∣∣(x,y)−τt∣∣2<d,O^x,yt=1}。
2.5. 学习
UniAD的训练分为两个阶段。我们首先联合训练感知部分,即跟踪和建图模块,持续几个时期(在我们的实验中为6个),然后使用所有感知、预测和规划模块对模型进行端到端的20个时期的训练。实验发现,两阶段训练更稳定。我们建议观众查阅补充文件,了解每项损失的详细情况。
共享匹配。由于UniAD涉及实例建模,因此在感知和预测任务中需要将预测与真值集配对。与DETR8,56类似,在跟踪和在线建图阶段采用了二分匹配算法。至于跟踪,来自检测查询的候选对象与新的真值对象配对,来自跟踪查询的预测继承了先前帧的分配。跟踪模块中的匹配结果在运动和占用节点中被重用,以在端到端框架中从历史轨迹到未来运动对代理进行一致的建模。
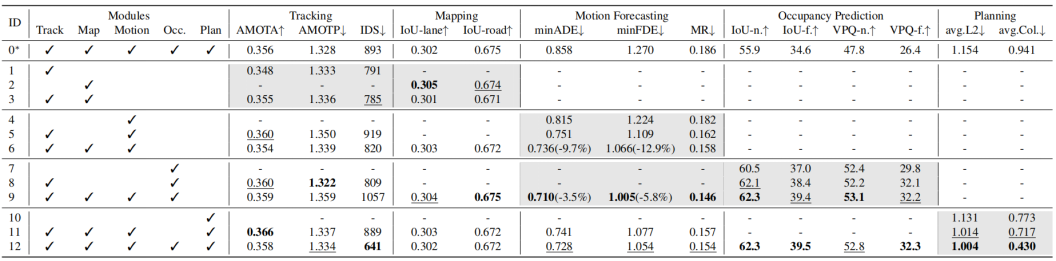
表2. 详细说明每项任务的有效性。我们可以得出结论,两个感知子任务极大地帮助了运动预测,统一两个预测模块也有助于提高预测性能。通过所有先前的陈述,我们的目标规划大大提高了安全性。UniAD在预测和规划任务方面远远优于朴素的MTL解决方案,并且它还具有不会发生实质性感知性能下降的优势。为简洁起见,仅显示主要指标。"avg.L2"和"avg.Col"是整个规划期的平均值。*:ID-0是MTL方案,每个任务都有单独的头。
3. 实验
我们在具有挑战性的nuScenes数据集上进行了实验6。在本节中,我们从三个方面验证了我们设计的有效性:联合结果揭示了任务协调的优势及其对规划的影响,与以前的方法相比,每个任务的模块化结果,以及特定模块的设计空间上的消融。由于空间限制,补充资料中提供了全套协议、一些消融和可视化。
3.1. 联合结果
如表2所示,我们进行了广泛的消融,以证明端到端管道中先前任务的有效性和必要性。此表的每一行都显示了合并第二个模块列中列出的任务模块时的模型性能。第一行(ID-0)用作vanilla多任务基线,具有单独的任务头进行比较。每个指标的最佳结果用粗体标记,亚军结果在每列中用下划线标记。
安全规划路线图。由于与感知相比,预测更接近于规划,我们首先研究了我们框架中的两种预测任务,即运动预测和占用预测。在实验10-12中,只有当两个任务同时引入时(实验12),与没有任何中间任务的简单端到端规划相比,规划L2和碰撞率的指标才能达到最佳结果(实验10,图1(c.1))。因此,我们得出结论,这两个预测任务都是安全规划目标所必需的。退一步,在实验7-9中,我们展示了两种预测的协同效应。当这两个任务紧密集成时,它们的性能都会得到提高(实验9,-3.5%minADE,-5.8%minFDE,-1.3MR(%),+2.4IoU-f(%)和+2.4VPQ-f(百分比)),这表明了同时包含代理和场景表示的必要性。同时,为了实现卓越的运动预测性能,我们在实验4-6中探索了感知模块如何做出贡献。值得注意的是,结合跟踪和建图节点可以显著改善预测结果(-9.7%minADE,-12.9%minFDE,-2.3MR(%))。我们还提出了实验1-3,该实验表明,训练感知子任务共同导致与单个任务相当的结果。此外,与朴素多任务学习(实验0,图1(b))相比,实验12在所有基本指标上都明显优于它(-15.2%minADE,-17.0%minFDE,-3.2MR(%)),+4.9IoU-f(%)+5.9 VPQ-f.(%),-0.15m avg.L2,-0.51 avg.Col.(%)),显示了我们以规划为导向的设计的优越性。
3.2. 模块化结果
按照感知预测规划的顺序,我们报告了与nuScenes验证集的现有技术相比,每个任务模块的性能。请注意,UniAD使用一个经过训练的网络联合执行所有这些任务。每个任务的主要指标在表中用灰色背景标记。
感知结果。对于表3中的多目标跟踪,与MUTR3D104和ViP3D30相比,UniAD分别产生了+6.5和+14.2 AMOTA(%)的显著改善。此外,UniAD实现了最低的ID切换得分,显示了每个轨迹的时间一致性。对于表4中的在线建图,UniAD在分割车道方面表现良好(与BEVFormer相比,IoU(%)增加了7.4),这对于运动模块中的下游代理道路交互至关重要。由于我们的跟踪模块遵循端到端的范式,它仍然不如具有复杂关联的检测方法(如Immortal Tracker93)进行跟踪,我们的建图结果在特定类别上落后于以前的面向感知的方法。我们认为,UniAD将使最终规划受益于感知信息,而不是用完整的模型能力优化感知。
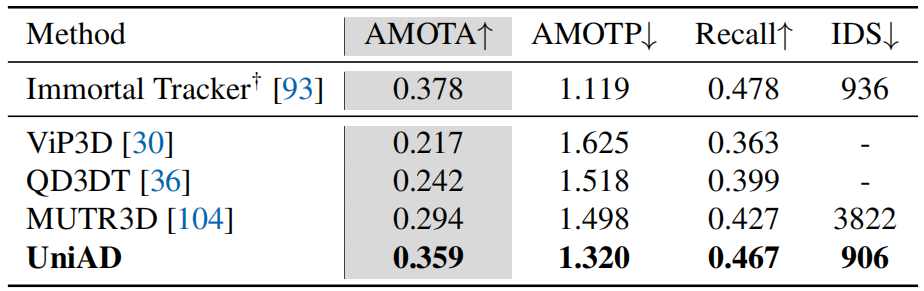
表3. 多目标跟踪。UniAD在所有指标上都优于之前的端到端MOT技术(仅限图像输入)。†:通过后关联的检测方法进行跟踪,用BEVFormer重新实现,以进行公平比较。
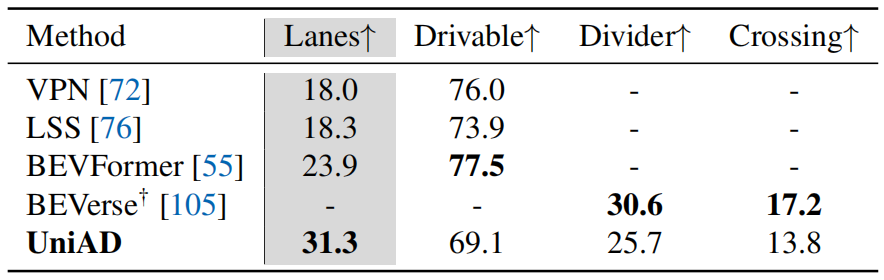
表4. 在线建图。UniAD具有全面的道路语义,与最先进的面向感知的方法相比具有竞争力。我们报告了细分IoU(%)。†:用BEVFormer重新实现。
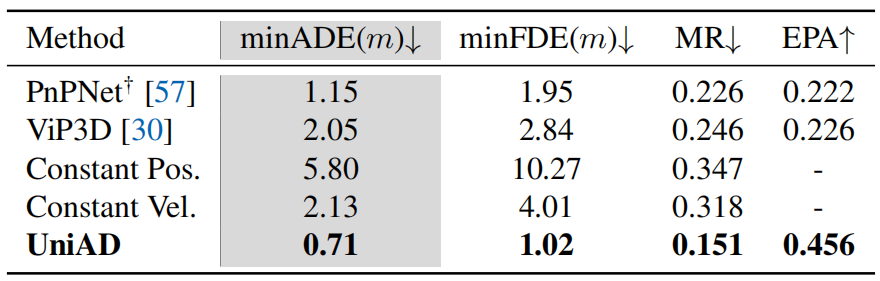
表5. 运动预测。UniAD明显优于以前基于视觉的端到端方法。我们还报告了两种具有恒定位置或速度的车辆建模设置作为比较。†:用BEVFormer重新实现。
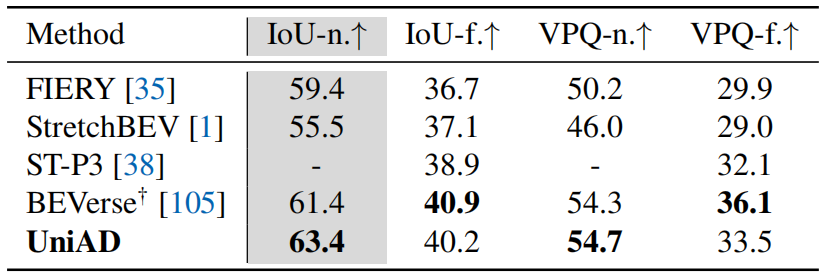
表6. 占用预测。UniAD在附近地区得到了显著改善,这对规划更为关键。"n"和"f"分别表示近(30×30m)和远(50×50m)评估范围。†:经过重型增强训练。
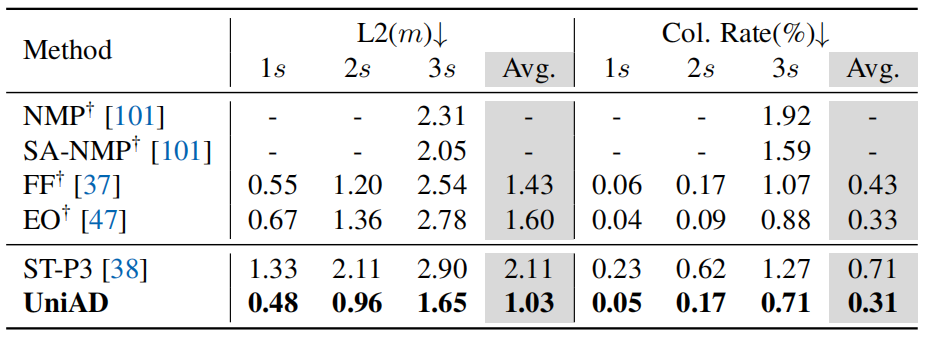
表7. 规划。UniAD在所有时间间隔内实现了最低的L2误差和碰撞率,在大多数情况下甚至优于基于LiDAR的方法(†),验证了我们系统的安全性。
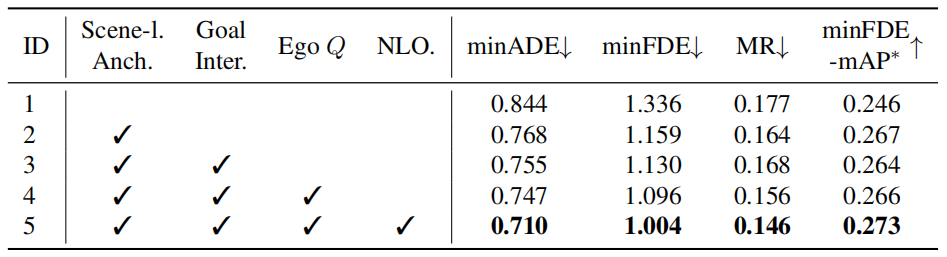
表8.运动预测模块中设计的消融。所有组件都有助于实现最终性能。"Scene-l.Anch."表示旋转的场景级锚点。"Goal Inter"是指代理目标点交互。"Ego Q"代表自车查询,"NLO."是非线性优化策略。*:同时考虑检测和预测准确性的指标,我们在补充中提供了详细信息。
预测结果。运动预测结果如表5所示,其中UniAD明显优于之前的基于视觉的端到端方法。与PnPNet视觉57和ViP3D30相比,minADE的预测误差分别降低了38.3%和65.4%。就表6中报告的占用预测而言,UniAD在附近地区取得了显著进展,与FIERY35和BEVerse105相比,在大幅增强的情况下,IoU附近(%)的占用分别为+4.0和+2.0。
规划结果。受益于自车查询和占用中丰富的时空信息,与ST-P338相比,UniAD在规划视野的平均值方面将规划L2错误和碰撞率分别降低了51.2%和56.3%38。此外,它明显优于几个基于激光雷达的同行,这通常被认为对感知任务具有挑战性。
3.3. 定性结果
图3显示了一个复杂场景中所有任务的结果。自车在行驶时会注意到前方车辆和车道的潜在移动。在补充中,我们展示了更具挑战性的场景的可视化,以及面向规划的设计的一个有前景的案例,即在先前的模块中出现了不准确的结果,而后续的任务仍然可以恢复,例如,尽管物体有较大的航向角偏差或在跟踪结果中未能检测到,但规划的轨迹仍然是合理的。此外,我们分析了UniAD的失效案例主要发生在大型卡车和拖车等长尾场景下,如补充文件所示。
3.4. 消融研究
MotionFormer中的设计效果。表8显示,第2.2节中描述的所有拟议组件都有助于minADE、minFDE、Miss Rate和minFDE mAP指标的最终性能。值得注意的是,旋转的场景级锚点显示出显著的性能提升(-15.8%minADE,-11.2%minFDE,+1.9 minFDE mAP(%)),表明以场景为中心的方式进行运动预测至关重要。代理目标点交互通过面向规划的视觉特征增强了运动查询,周围的代理可以进一步从考虑自车的意图中受益。此外,非线性优化策略通过在端到端场景中考虑感知不确定性来提高性能(-5.0%minADE,-8.4%minFDE,-1.0MR(%),+0.7minFDE mAP(%))。
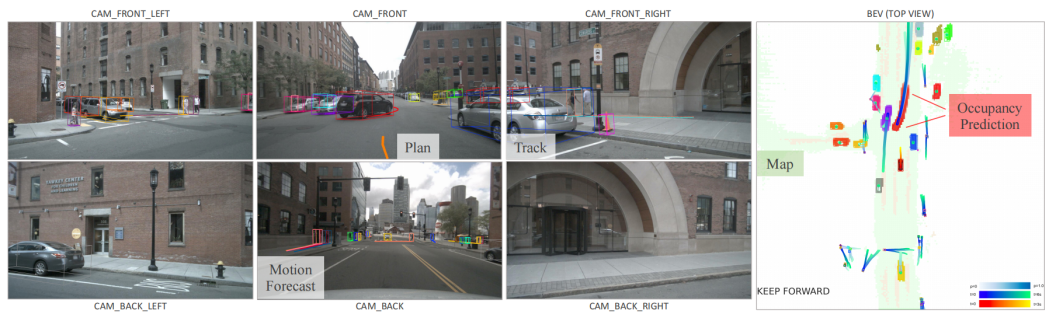
图3. 可视化结果。我们在环绕视图图像和BEV中显示了所有任务的结果。运动和占用模块的预测是一致的,在这种情况下,自车正在向前方黑色汽车让步。每个代理都有独特的颜色。分别选择运动预测中的前1和前3个轨迹在图像视图和BEV上进行可视化。
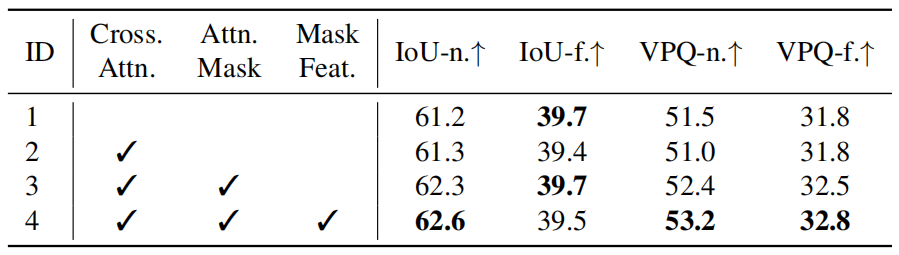
表9。占用预测模型中设计的消融。与掩码的交叉关注和掩码特征的重用有助于提高预测。"Cross.Atn."和"Attn.Mask"分别代表像素代理交互中的交叉注意力和注意力掩码。"Mask Feat."表示掩码功能的重用,用于实例级占用。
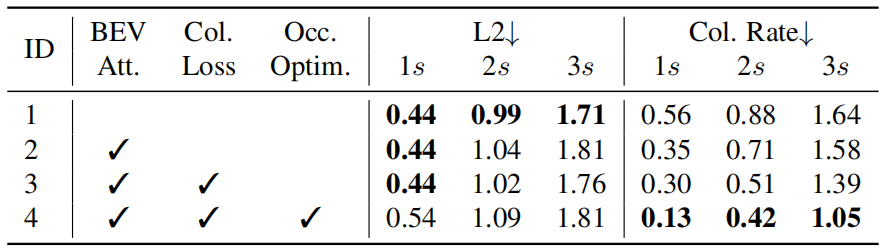
表10. 规划模块中的设计消融。结果证明了前面每项任务的必要性。"BEV Att."表示关注BEV特征。"Col. Loss"表示碰撞损失。"Occ.Optim."是占用优化策略。
OccFormer中的设计效果。如表9所示,与无注意力基线(实验1)相比,在没有局部约束的情况下(实验2)对所有代理处理每个像素会导致性能稍差。占用引导注意力掩码解决了这个问题,并带来了收益,特别是对于附近的区域(实验3,+1.0 IoU-n(%),+1.4 VPQ-n。(%))。此外,重用掩码特征Mt而不是代理特征来获取占用特征进一步提高了性能。
Planner中设计的效果。我们在表10的规划器中提供了拟议设计的消融,即参加BEV特征、碰撞损失训练和占用优化策略。与之前的研究37,38类似,为了安全起见,较低的碰撞率比简单的轨迹模拟(L2度量)更可取,并且在UniAD中应用所有部件后,碰撞率会降低。
4. 结论和今后的工作
我们讨论了自动驾驶算法框架的系统级设计。提出了一种面向规划的管道,以实现规划的最终目标,即UniAD。我们对感知和预测中每个模块的必要性进行了详细分析。为了统一任务,提出了一种基于查询的设计来连接UniAD中的所有节点,受益于环境中代理交互的更丰富表示。大量实验从各个方面验证了所提出的方法。
局限性和未来的工作。协调这样一个具有多个任务的综合系统并非易事,需要大量的计算能力,尤其是经过时间历史训练的计算能力。如何为轻量级部署设计和管理系统值得未来探索。此外,是否将更多的任务(如深度估计、行为预测)以及如何将其嵌入系统中,也是值得未来研究的方向。
致谢。这项工作部分得到了国家重点研发计划(2022ZD0160100)的支持,部分得到了上海市科学技术委员会(21DZ1100100)和国家自然科学基金(62206172)的支持。
References
1 Adil Kaan Akan and Fatma G¨uney. StretchBEV: Stretching future instance prediction spatially and temporally. In ECCV, 2022. 7, 14
2 Mayank Bansal, Alex Krizhevsky, and Abhijit Ogale. Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst. arXiv preprint arXiv:1812.03079, 2018. 15
3 Hans Georg Bock and Karl-Josef Plitt. A multiple shooting algorithm for direct solution of optimal control problems. IFAC Proceedings Volumes, 1984. 4, 5
4 Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, Bernhard Firner, Beat Flepp, Prasoon Goyal, Lawrence D Jackel, Mathew Monfort, Urs Muller, Jiakai Zhang, Xin Zhang, Jake Zhao, and Zieba Karol. End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316, 2016. 15
5 Thibault Buhet, ´Emilie Wirbel, and Xavier Perrotton. PLOP: Probabilistic polynomial objects trajectory planning for autonomous driving. In CoRL, 2020. 15
6 Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In CVPR, 2020. 6
7 Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop mlbased planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810, 2021. 4
8 Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020. 3, 5, 14, 15, 17
9 Sergio Casas, Cole Gulino, Renjie Liao, and Raquel Urtasun. Spagnn: Spatially-aware graph neural networks for relational behavior forecasting from sensor data. In ICRA, 2020. 14
10 Sergio Casas, Wenjie Luo, and Raquel Urtasun. Intentnet: Learning to predict intention from raw sensor data. In CoRL, 2018. 14
11 Sergio Casas, Abbas Sadat, and Raquel Urtasun. Mp3: A unified model to map, perceive, predict and plan. In CVPR, 2021. 2, 5, 14, 15
12 Yuning Chai, Benjamin Sapp, Mayank Bansal, and Dragomir Anguelov. Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction. In CoRL, 2020. 15, 19
13 Raphael Chekroun, Marin Toromanoff, Sascha Hornauer, and Fabien Moutarde. GRI: General reinforced imitation and its application to vision-based autonomous driving. arXiv preprint 2111.08575, 2021. 15
14 Dian Chen, Vladlen Koltun, and Philipp Kr¨ahenb¨uhl. Learning to drive from a world on rails. In ICCV, 2021. 2, 15
15 Dian Chen and Philipp Kr¨ahenb¨uhl. Learning from all vehicles. In CVPR, 2022. 1, 2, 15
16 Dian Chen, Brady Zhou, Vladlen Koltun, and Philipp Kr¨ahenb¨uhl. Learning by cheating. In CoRL, 2020. 2, 15
17 Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In CVPR, 2022. 5
18 Bowen Cheng, Alex Schwing, and Alexander Kirillov. Perpixel classification is not all you need for semantic segmentation. In NeurIPS, 2021. 5
19 Kashyap Chitta, Aditya Prakash, and Andreas Geiger. NEAT: Neural attention fields for end-to-end autonomous driving. In ICCV, 2021. 2, 15
20 Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE TPAMI, 2022. 1, 15
21 Felipe Codevilla, Matthias M¨uller, Antonio L´opez, Vladlen Koltun, and Alexey Dosovitskiy. End-to-end driving via conditional imitation learning. In ICRA, 2018. 2, 15
22 Felipe Codevilla, Eder Santana, Antonio M L´opez, and Adrien Gaidon. Exploring the limitations of behavior cloning for autonomous driving. In ICCV, 2019. 2, 15
23 Michael Crawshaw. Multi-task learning with deep neural networks: A survey. arXiv preprint arXiv:2009.09796, 2020. 2
24 Alexander Cui, Sergio Casas, Abbas Sadat, Renjie Liao, and Raquel Urtasun. Lookout: Diverse multi-future prediction and planning for self-driving. In ICCV, 2021. 15
25 Nemanja Djuric, Henggang Cui, Zhaoen Su, Shangxuan Wu, Huahua Wang, Fang-Chieh Chou, Luisa San Martin, Song Feng, Rui Hu, Yang Xu, Alyssa Dayan, Sidney Zhang, Brian C. Becker, Gregory P. Meyer, Carlos VallespiGonzalez, and Carl K. Wellington. Multixnet: Multiclass multistage multimodal motion prediction. In IV, 2021. 14
26 Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. In CoRL, 2017. 2
27 Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles R Qi, Yin Zhou, Zoey Yang, Aur´elien Chouard, Pei Sun, Jiquan Ngiam, Vijay Vasudevan, Alexander McCauley, Jonathon Shlens, and Dragomir Anguelov. Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset. In ICCV, 2021. 13
28 Sudeep Fadadu, Shreyash Pandey, Darshan Hegde, Yi Shi, Fang-Chieh Chou, Nemanja Djuric, and Carlos VallespiGonzalez. Multi-view fusion of sensor data for improved perception and prediction in autonomous driving. In WACV, 2022. 14
29 Jiyang Gao, Chen Sun, Hang Zhao, Yi Shen, Dragomir Anguelov, Congcong Li, and Cordelia Schmid. Vectornet: Encoding hd maps and agent dynamics from vectorized representation. In CVPR, 2020. 14
30 Junru Gu, Chenxu Hu, Tianyuan Zhang, Xuanyao Chen, Yilun Wang, Yue Wang, and Hang Zhao. ViP3D: End-toend visual trajectory prediction via 3d agent queries. In CVPR, 2023. 2, 6, 7, 14, 20
31 Chunrui Han, Jianjian Sun, Zheng Ge, Jinrong Yang, Runpei Dong, Hongyu Zhou, Weixin Mao, Yuang Peng, and Xiangyu Zhang. Exploring recurrent long-term temporal fusion for multi-view 3d perception. arXiv preprint arXiv:2303.05970, 2023. 2
32 Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016. 21
33 Noureldin Hendy, Cooper Sloan, Feng Tian, Pengfei Duan, Nick Charchut, Yuesong Xie, Chuang Wang, and James Philbin. Fishing net: Future inference of semantic heatmaps in grids. arXiv preprint arXiv:2006.09917, 2020. 14
34 Anthony Hu, Gianluca Corrado, Nicolas Griffiths, Zak Murez, Corina Gurau, Hudson Yeo, Alex Kendall, Roberto Cipolla, and Jamie Shotton. Model-based imitation learning for urban driving. In NeurIPS, 2022. 15
35 Anthony Hu, Zak Murez, Nikhil Mohan, Sof´ıa Dudas, Jeffrey Hawke, Vijay Badrinarayanan, Roberto Cipolla, and Alex Kendall. FIERY: Future instance prediction in bird'seye view from surround monocular cameras. In ICCV, 2021. 4, 7, 14, 20
36 Hou-Ning Hu, Yung-Hsu Yang, Tobias Fischer, Trevor Darrell, Fisher Yu, and Min Sun. Monocular quasi-dense 3d object tracking. IEEE TPAMI, 2022. 7
37 Peiyun Hu, Aaron Huang, John Dolan, David Held, and Deva Ramanan. Safe local motion planning with selfsupervised freespace forecasting. In CVPR, 2021. 7, 8, 15
38 Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. ST-P3: End-to-end visionbased autonomous driving via spatial-temporal feature learning. In ECCV, 2022. 2, 4, 5, 7, 8, 14, 15, 20
39 Zhiyu Huang, Haochen Liu, Jingda Wu, and Chen Lv. Differentiable integrated motion prediction and planning with learnable cost function for autonomous driving. arXiv preprint arXiv:2207.10422, 2022. 15
40 Boris Ivanovic, Amine Elhafsi, Guy Rosman, Adrien Gaidon, and Marco Pavone. MATS: An interpretable trajectory forecasting representation for planning and control. In CoRL, 2021. 15
41 Xiaosong Jia, Li Chen, Penghao Wu, Jia Zeng, Junchi Yan, Hongyang Li, and Yu Qiao. Towards capturing the temporal dynamics for trajectory prediction: a coarse-to-fine approach. In CoRL, 2022. 14, 19
42 Xiaosong Jia, Liting Sun, Masayoshi Tomizuka, and Wei Zhan. Ide-net: Interactive driving event and pattern extraction from human data. IEEE RA-L, 2021. 14
43 Xiaosong Jia, Liting Sun, Hang Zhao, Masayoshi Tomizuka, and Wei Zhan. Multi-agent trajectory prediction by combining egocentric and allocentric views. In CoRL, 2021. 3
44 Xiaosong Jia, Penghao Wu, Li Chen, Hongyang Li, Yu Liu, and Junchi Yan. HDGT: Heterogeneous driving graph transformer for multi-agent trajectory prediction via scene encoding. arXiv preprint arXiv:2205.09753, 2022. 3
45 Alexey Kamenev, Lirui Wang, Ollin Boer Bohan, Ishwar Kulkarni, Bilal Kartal, Artem Molchanov, Stan Birchfield, David Nist´er, and Nikolai Smolyanskiy. Predictionnet: Real-time joint probabilistic traffic prediction for planning, control, and simulation. In ICRA, 2022. 15
46 Alex Kendall, Jeffrey Hawke, David Janz, Przemyslaw Mazur, Daniele Reda, John-Mark Allen, Vinh-Dieu Lam, Alex Bewley, and Amar Shah. Learning to drive in a day. In ICRA, 2019. 15
47 Tarasha Khurana, Peiyun Hu, Achal Dave, Jason Ziglar, David Held, and Deva Ramanan. Differentiable raycasting for self-supervised occupancy forecasting. In ECCV, 2022. 7, 15
48 Dahun Kim, Sanghyun Woo, Joon-Young Lee, and In So Kweon. Video panoptic segmentation. In CVPR, 2020. 20
49 Jinkyu Kim, Reza Mahjourian, Scott Ettinger, Mayank Bansal, Brandyn White, Ben Sapp, and Dragomir Anguelov. Stopnet: Scalable trajectory and occupancy prediction for urban autonomous driving. arXiv preprint arXiv:2206.00991, 2022. 3
50 Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Doll´ar. Panoptic segmentation. In CVPR, 2019. 3
51 Youngwan Lee, Joong-won Hwang, Sangrok Lee, Yuseok Bae, and Jongyoul Park. An energy and gpu-computation efficient backbone network for real-time object detection. In CVPR Workshop, 2019. 21
52 Feng Li, Hao Zhang, Shilong Liu, Lei Zhang, Lionel M Ni, and Heung-Yeung Shum. Mask dino: Towards a unified transformer-based framework for object detection and segmentation. In CVPR, 2023. 5
53 Lingyun Luke Li, Bin Yang, Ming Liang, Wenyuan Zeng, Mengye Ren, Sean Segal, and Raquel Urtasun. End-to-end contextual perception and prediction with interaction transformer. In IROS, 2020. 14
54 Yanwei Li, Yilun Chen, Xiaojuan Qi, Zeming Li, Jian Sun, and Jiaya Jia. Unifying voxel-based representation with transformer for 3d object detection. In NeurIPS, 2022. 14
55 Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. BEVFormer: Learning bird's-eye-view representation from multi-camera images via spatiotemporal transformers. In ECCV, 2022. 2, 7, 15, 18, 19, 21
56 Zhiqi Li, Wenhai Wang, Enze Xie, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, Ping Luo, and Tong Lu. Panoptic segformer: Delving deeper into panoptic segmentation with transformers. In CVPR, 2022. 3, 5, 15, 17, 19
57 Ming Liang, Bin Yang, Wenyuan Zeng, Yun Chen, Rui Hu, Sergio Casas, and Raquel Urtasun. Pnpnet: End-to-end perception and prediction with tracking in the loop. In CVPR, 2020. 1, 2, 7, 14, 20
58 Tingting Liang, Hongwei Xie, Kaicheng Yu, Zhongyu Xia, Zhiwei Lin, Yongtao Wang, Tao Tang, Bing Wang, and Zhi Tang. BEVFusion: A simple and robust lidar-camera fusion framework. In NeurIPS, 2022. 2
59 Xiaodan Liang, Tairui Wang, Luona Yang, and Eric Xing. Cirl: Controllable imitative reinforcement learning for vision-based self-driving. In ECCV, 2018. 15
60 Xiwen Liang, Yangxin Wu, Jianhua Han, Hang Xu, Chunjing Xu, and Xiaodan Liang. Effective adaptation in multi-task co-training for unified autonomous driving. In NeurIPS, 2022. 1
61 Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. In ICCV, 2017. 19
62 Jerry Liu, Wenyuan Zeng, Raquel Urtasun, and Ersin Yumer. Deep structured reactive planning. In ICRA, 2021.15
63 Yicheng Liu, Jinghuai Zhang, Liangji Fang, Qinhong Jiang, and Bolei Zhou. Multimodal motion prediction with stacked transformers. In CVPR, 2021. 3
64 Zhijian Liu, Haotian Tang, Alexander Amini, Xingyu Yang, Huizi Mao, Daniela Rus, and Song Han. BEVFusion: Multi-task multi-sensor fusion with unified bird's-eye view representation. In ICRA, 2023. 2, 14
65 Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2018. 20
66 Wenjie Luo, Bin Yang, and Raquel Urtasun. Fast and furious: Real time end-to-end 3d detection, tracking and motion forecasting with a single convolutional net. In CVPR, 2018. 1, 14, 20
67 Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In 3DV, 2016. 19
68 Mobileye. Mobileye under the hood. https://www.mobileye.com/ces-2022/, 2022. 1, 2
69 Nigamaa Nayakanti, Rami Al-Rfou, Aurick Zhou, Kratarth Goel, Khaled S Refaat, and Benjamin Sapp. Wayformer: Motion forecasting via simple & efficient attention networks. arXiv preprint arXiv:2207.05844, 2022. 3
70 Jiquan Ngiam, Benjamin Caine, Vijay Vasudevan, Zhengdong Zhang, Hao-Tien Lewis Chiang, Jeffrey Ling, Rebecca Roelofs, Alex Bewley, Chenxi Liu, Ashish Venugopal, David Weiss, Ben Sapp, Zhifeng Chen, and Jonathon Shlens. Scene transformer: A unified multi-task model for behavior prediction and planning. In ICLR, 2022. 3, 15
71 Nvidia. NVIDIA DRIVE End-to-End Solutions for Autonomous Vehicles. https://developer.nvidia.com/drive, 2022. 1, 2
72 Bowen Pan, Jiankai Sun, Ho Yin Tiga Leung, Alex Andonian, and Bolei Zhou. Cross-view semantic segmentation for sensing surroundings. IEEE RA-L, 2020. 7
73 Dennis Park, Rares Ambrus, Vitor Guizilini, Jie Li, and Adrien Gaidon. Is pseudo-lidar needed for monocular 3d object detection? In ICCV, 2021. 21
74 Jinhyung Park, Chenfeng Xu, Shijia Yang, Kurt Keutzer, Kris Kitani, Masayoshi Tomizuka, and Wei Zhan. Time will tell: New outlooks and a baseline for temporal multiview 3d object detection. arXiv preprint arXiv:2210.02443, 2022. 2
75 Neehar Peri, Jonathon Luiten, Mengtian Li, Aljoˇsa Oˇsep, Laura Leal-Taix´e, and Deva Ramanan. Forecasting from lidar via future object detection. In CVPR, 2022. 14, 20
76 Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In ECCV, 2020. 7
77 Dean A Pomerleau. Alvinn: An autonomous land vehicle in a neural network. In NeurIPS, 1988. 15
78 Aditya Prakash, Kashyap Chitta, and Andreas Geiger. Multi-modal fusion transformer for end-to-end autonomous driving. In CVPR, 2021. 2, 15
79 Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, and Nando de Freitas. A generalist agent. arXiv preprint arXiv:2205.06175, 2022. 1
80 Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. In CVPR, 2019. 19
81 Nicholas Rhinehart, Rowan McAllister, Kris Kitani, and Sergey Levine. PRECOG: Prediction conditioned on goals in visual multi-agent settings. In ICCV, 2019. 15
82 Abbas Sadat, Sergio Casas, Mengye Ren, Xinyu Wu, Pranaab Dhawan, and Raquel Urtasun. Perceive, predict, and plan: Safe motion planning through interpretable semantic representations. In ECCV, 2020. 1, 2, 14, 15
83 Hao Shao, Letian Wang, Ruobing Chen, Hongsheng Li, and Yu Liu. Safety-enhanced autonomous driving using interpretable sensor fusion transformer. In CoRL, 2022. 15
84 Shaoshuai Shi, Li Jiang, Dengxin Dai, and Bernt Schiele. Motion transformer with global intention localization and local movement refinement. In NeurIPS, 2022. 3
85 Yining Shi, Jingyan Shen, Yifan Sun, Yunlong Wang, Jiaxin Li, Shiqi Sun, Kun Jiang, and Diange Yang. Srcn3d: Sparse r-cnn 3d surround-view camera object detection and tracking for autonomous driving. arXiv preprint arXiv:2206.14451, 2022. 14
86 Haoran Song, Wenchao Ding, Yuxuan Chen, Shaojie Shen, Michael Yu Wang, and Qifeng Chen. Pip: Planning-informed trajectory prediction for autonomous driving. In ECCV, 2020. 15
87 Tesla. Tesla AI Day. https://www.youtube.com/watch?v=ODSJsviD_SU, 2022. 2
88 Sebastian Thrun and Arno B¨ucken. Integrating grid-based and topological maps for mobile robot navigation. In AAAI, 1996. 14
89 Marin Toromanoff, Emilie Wirbel, and Fabien Moutarde. End-to-end model-free reinforcement learning for urban driving using implicit affordances. In CVPR, 2020. 15
90 Balakrishnan Varadarajan, Ahmed Hefny, Avikalp Srivastava, Khaled S Refaat, Nigamaa Nayakanti, Andre Cornman, Kan Chen, Bertrand Douillard, Chi Pang Lam, Dragomir Anguelov, and Benjamin Sapp. Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction. arXiv preprint arXiv:2111.14973, 2021.19
91 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017. 4
92 Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In ICML, 2022. 1
93 Qitai Wang, Yuntao Chen, Ziqi Pang, Naiyan Wang, and Zhaoxiang Zhang. Immortal tracker: Tracklet never dies. arXiv preprint arXiv:2111.13672, 2021. 6, 7
94 Bob Wei, Mengye Ren, Wenyuan Zeng, Ming Liang, Bin Yang, and Raquel Urtasun. Perceive, attend, and drive: Learning spatial attention for safe self-driving. In ICRA, 2021. 15
95 Penghao Wu, Li Chen, Hongyang Li, Xiaosong Jia, Junchi Yan, and Yu Qiao. Policy pre-training for autonomous driving via self-supervised geometric modeling. In ICLR, 2023. 2
96 Pengxiang Wu, Siheng Chen, and Dimitris N Metaxas. Motionnet: Joint perception and motion prediction for autonomous driving based on bird's eye view maps. In CVPR, 2020. 14
97 Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline. In NeurIPS, 2022. 2, 15
98 Jinrong Yang, En Yu, Zeming Li, Xiaoping Li, and Wenbing Tao. Quality matters: Embracing quality clues for robust 3d multi-object tracking. arXiv preprint arXiv:2208.10976, 2022. 14
99 Ye Yuan, Xinshuo Weng, Yanglan Ou, and Kris M Kitani. Agentformer: Agent-aware transformers for sociotemporal multi-agent forecasting. In ICCV, 2021. 3
100 Fangao Zeng, Bin Dong, Tiancai Wang, Xiangyu Zhang, and Yichen Wei. Motr: End-to-end multiple-object tracking with transformer. In ECCV, 2021. 3, 15
101 Wenyuan Zeng, Wenjie Luo, Simon Suo, Abbas Sadat, Bin Yang, Sergio Casas, and Raquel Urtasun. End-to-end inter-pretable neural motion planner. In CVPR, 2019. 1, 2, 7, 14, 15
102 Wenyuan Zeng, Shenlong Wang, Renjie Liao, Yun Chen, Bin Yang, and Raquel Urtasun. Dsdnet: Deep structured self-driving network. In ECCV, 2020. 15
103 Jimuyang Zhang and Eshed Ohn-Bar. Learning by watching. In CVPR, 2021. 15
104 Tianyuan Zhang, Xuanyao Chen, Yue Wang, Yilun Wang, and Hang Zhao. MUTR3D: A Multi-camera Tracking Framework via 3D-to-2D Queries. In CVPR Workshop, 2022. 3, 6, 7, 14
105 Yunpeng Zhang, Zheng Zhu, Wenzhao Zheng, Junjie Huang, Guan Huang, Jie Zhou, and Jiwen Lu. BEV-erse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving. arXiv preprint
arXiv:2205.09743, 2022. 1, 2, 4, 7, 14, 20, 21
106 Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu, and Luc Van Gool. End-to-end urban driving by imitating a reinforcement learning coach. In ICCV, 2021. 2, 15
107 Hang Zhao, Jiyang Gao, Tian Lan, Chen Sun, Benjamin Sapp, Balakrishnan Varadarajan, Yue Shen, Yi Shen, Yuning Chai, Cordelia Schmid, Congcong Li, and Dragomir Anguelov. TNT: Target-driven trajectory prediction. In CoRL, 2020. 14
108 Jinguo Zhu, Xizhou Zhu, Wenhai Wang, Xiaohua Wang, Hongsheng Li, Xiaogang Wang, and Jifeng Dai. Uniperceiver-moe: Learning sparse generalist models with conditional moes. In NeurIPS, 2022. 1
109 Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. In ICLR, 2020. 3, 4, 15, 17
附录
A. 任务定义 ······················· 13
B. 每项任务的必要性 ··········· 14
C. 相关工作 ······················· 14
C.1 联合感知和预测 ············ 14
C.2 联合预测和规划 ············ 15
C.3 端到端运动规划 ············ 15
D. 符号 ····························· 15
E. 实施细节 ······················· 15
E.1 检测和跟踪 ·················· 15
E.2 在线地图绘制 ··············· 15
E.3 运动预测 ····················· 17
E.4 占用预测 ····················· 17
E.5 规划 ··························· 18
E.6 训练详情 ····················· 18
F. 实验 ····························· 19
F.1 协议 ···························· 19
F.2 度量标准 ······················ 20
F.3 模型复杂性和计算成本 ···· 20
F.4 模型尺寸 ······················ 20
F.5 定性结果 ······················ 21
A. 任务定义
检测和跟踪 。检测和跟踪是自动驾驶的两个关键感知任务,我们专注于在3D空间中表示它们,以方便下游使用。3D检测负责在每个时间戳定位周围物体(坐标、长度、宽度、高度等);跟踪旨在跨时间戳找到不同对象之间的对应关系并将其在时间上相关联(即为每个代理分配一致的跟踪ID)。在本文中,我们在某些情况下使用多目标跟踪来表示检测和跟踪过程。最终输出是每帧中的一系列相关3D框,它们对应的特征 QA 被转发给运动模块。此外,请注意,我们有一个名为"自车查询"的特殊查询,用于下游任务,该查询不会包含在预测真值匹配过程中,它会相应地回归自车的位置。
在线建图 。地图直观地体现了环境的几何和语义信息,在线建图是用车载传感器数据(在我们的例子中是多视图图像)分割有意义的道路元素,作为离线标注高清(HD)地图的替代品。在UniAD中,我们将在线地图分为四类:车道、可行驶区域、分隔带和人行横道,并在鸟瞰图(BEV)中对其进行分割。与 QA 类似,地图查询 QM 将在运动预测模块中进一步用于对代理-地图交互进行建模。
运动预测 。在感知和规划之间,预测在整个自动驾驶系统中起着重要作用,以确保最终的安全。通常,运动预测是一个独立开发的模块,利用检测到的边界框和HD图预测代理的未来轨迹。边界框是大多数当前运动数据集中的真值注释27,这在机载场景中是不现实的。而在本文中,运动预测模块将先前编码的稀疏查询(即 QA 和 QM )和密集 BEV 特征 B 作为输入,并为每个代理预测未来 T 个时间步中的K个合理轨迹。此外,为了与我们的端到端和以场景为中心的场景兼容,我们根据每个代理的当前位置将轨迹预测为偏移。在最后一次解码 MLP 之前的代理特征,已经对历史和未来信息进行了编码,将被发送到占用模块,以进行场景级的未来理解。对于自车查询,它也预测了未来的自我运动(实际上提供了一个粗略的规划估计),规划者利用该特征来生成最终目标。
占用预测 。占用网格图是一种离散的 BEV 表示,其中每个单元都有一个信念,指示它是否被占用,占用预测任务旨在发现网格图在未来如何随着多个代理动态的 To 时间步而变化。作为对基于稀疏代理的运动预测的补充,占用预测在整个场景级别上得到了密集表示。为了研究场景如何随着稀疏代理知识而演变,我们提出的占用模块将观察到的 BEV 特征 B 和代理特征 Gt 作为输入。在多步代理场景交互(详见附录E)后,通过占用特征和密集场景特征之间的矩阵乘法生成实例级概率图 O ^ A t ∈ R N a × H × W \hat{O}^t_A∈\mathbb{R}^{N_a×H×W} O^At∈RNa×H×W。为了在保持代理身份的情况下形成用于占用评估和下游规划的整个场景占用 O ^ t ∈ R H × W \hat{O}^t∈\mathbb{R}^{H×W} O^t∈RH×W,我们简单地使用像素级 argmax 合并每个时间步的实例级概率,如8所示。
规划 。作为最终目标,规划模块考虑了所有上游结果。行业中的传统规划方法通常是基于规则的,由"if-else"状态机根据各种场景制定,这些场景用先前的检测和预测结果进行描述。在我们的基于学习的模型中,我们以上游的自车查询和密集的 BEV 特征 B 为输入,预测总 T p T_p Tp时间步长的一条轨迹 τ ^ \hat{τ} τ^。然后,利用上游预测的未来占用 O ^ \hat{O} O^ 对轨迹 τ ^ \hat{τ} τ^ 进行优化,以避免碰撞并确保最终安全。
B. 每项任务的必要性
在感知方面,PnPNet57和ViP3D30中的循环跟踪已被证明可以补充时空特征,并为隔离的代理提供历史跟踪,避免下游规划的灾难性决策。借助高清地图30,57,82101和运动预测,规划朝着更高层次的智能化方向变得更加准确。然而,这些信息的构建成本很高,而且很容易过时,这增加了对没有高清地图的在线建图的需求。至于预测,运动预测10,29,41,42,107生成长期的未来行为,并以稀疏航路点输出的形式保留代理身份。尽管如此,将不可微的盒子表示整合到后续的规划模块中仍然存在挑战30,57。最近的一些文献研究了另一种类型的预测任务,称为占用预测88,以成本图的形式辅助端到端规划。然而,由于缺乏代理身份和占用动态,因此对社会互动进行建模以进行安全规划是不切实际的。与运动预测相比,建模多步密集特征的大量计算消耗也导致了更短的时间范围。因此,为了从两种互补的安全规划预测任务中受益,我们在UniAD中结合了以代理为中心的运动和整个场景占用。
C. 相关工作
C.1. 联合感知和预测
提出了感知和预测的联合学习,以避免传统模块化独立流水线中的级联误差。与单独的运动预测任务类似,它通常有两种类型的输出表示:代理级边界框和场景级占用网格图。开创性的工作FaF66预测未来的盒子,并聚合过去的信息以生成轨迹。IntentNet10将其扩展到对意图的推理,25,28进一步以精细的方式预测未来的状态。一些人首先利用检测,并在第二预测阶段利用代理特征9,53,75。注意到历史信息被忽略了,PnPNet57通过估计跟踪关联得分来丰富它,以避免检测跟踪范式54,64,85,98采用的不可微优化过程。然而,所有这些方法在检测中都依赖于非最大抑制(NMS),这仍然会导致信息丢失。ViP3D30与我们的工作密切相关,它采用104中的代理查询进行预测,并将HD地图作为另一个输入。我们在代理跟踪查询中遵循30,104的哲学,但也对目标轨迹进行了非线性优化,以缓解潜在的不准确感知问题。此外,我们引入了一种自车查询,以更好地捕捉动态环境中的自我行为,并结合在线地图,以防止高清地图的定位风险或高昂的建设成本。
另一种表示方式,即占用网格图,将BEV图离散化为网格单元,该网格单元包含指示其是否被占用的信念。Wu等人96估计了一个密集的运动场,但它无法捕捉到多模态行为。Fishing Net33还预测了具有多个传感器的确定性未来BEV语义分割。为了解决这个问题,P382提出了未来语义占用的非参数分布,FIERY35为多视图相机设计了第一个范式。一些方法通过更复杂的不确定性建模来提高FIERY的性能1,38,105。值得注意的是,这种表示可以很容易地扩展到避免碰撞的运动规划11,38,82,同时它失去了代理身份特征,并给计算带来了沉重的负担,这可能会限制预测范围。相比之下,我们利用代理级信息进行占用预测,并通过统一这两种模式来确保准确和安全的规划。
C.2. 联合预测与规划
PRECOG81提出了一种循环模型,该模型对自车的目标位置进行条件预测,而PiP86则考虑了完整的假设规划轨迹来生成代理的运动。然而,在现实世界中,制定一个粗略的未来轨迹仍然具有挑战性,为此62提出了一个深度结构化的模型,从同一组可学习的成本中得出预测和规划。39,40将预测模型与经典优化方法相结合。同时,一些运动预测方法通过同时产生其未来轨迹来隐含地包括规划任务12,45,70。同样,我们在以场景为中心的运动预测模块中编码了自车的可能行为,但利用可解释的占用图来进一步优化规划以保持安全。
C.3. 端到端运动规划
自Pomerleau77使用直接预测控制信号的单个神经网络以来,端到端运动规划一直是一个活跃的研究领域。后续研究取得了巨大进展,特别是在具有更深层次网络的闭环模拟4、多模态输入2,21,78、多任务学习20,97、强化学习13,14,46,59,89和从某些特权知识中提取16,103,106方面。然而,对于这种从传感器数据直接生成控制输出的方法,考虑到其鲁棒性和安全性保证,从合成环境到实际应用的转换仍然是一个问题22,38。因此,研究人员的目标是明确地设计网络的中间表示以促进安全,其中预测场景如何演变引起了广泛的兴趣。一些工作19,34,83联合解码规划和BEV语义预测以提高可解释性,而PLOP5采用多项式公式为自车和邻居提供平滑的规划结果。Cui等人24介绍了一种具有不同未来预测集的应急规划器,LAV15用所有车辆的轨迹训练规划器,以提供更丰富的训练数据。NMP101及其变体94估算成本量,以选择除确定性未来感知之外成本最低的规划。尽管它们有可能在两个模块之间产生不一致的结果,但成本图设计对于在复杂场景中恢复最终规划是直观的。受101的启发,最近的作品11,37,38,82102提出了利用学习到的占用预测和手工制作的惩罚来构建成本的模型。然而,他们的表现在很大程度上依赖于基于人类经验和轨迹采样分布的定制成本47。与这些方法相反,我们利用自我运动信息,而无需复杂的成本设计,并首次尝试在端到端模型中同时结合跟踪模块和两种类型的预测表示。
D. 符号
我们在表11中提供了本文中提到的符号及其形状的查找表,以供参考。
E. 实施细节
E.1. 检测与跟踪
我们继承了BEV Former55的大部分检测设计,该设计采用BEV编码器将图像特征转换为BEV特征B,并采用可变形DETR头109对B进行检测。为了进一步进行端到端跟踪,而不需要大量的后关联,我们引入了另一组名为跟踪查询的查询,如MOTR100中所述,它根据分配的跟踪ID连续跟踪先前观察到的实例。我们将在下面详细介绍跟踪过程。
训练阶段:在每个训练序列的开始(即第一帧),所有查询都被视为检测查询并预测所有新生对象,这实际上与BEVFormer相同。匈牙利算法将检测查询与真值相匹配8。它们将通过查询交互模块(QIM)存储和更新,作为MOTR100之后的跟踪查询,用于下一个时间戳。在下一个时间戳中,跟踪查询将根据相应的跟踪ID直接与部分真值对象匹配,检测查询将与剩余的真值对象(新生对象)匹配。为了稳定训练,我们采用3D IoU度量来过滤匹配的查询。只有那些具有大于特定阈值(实践中为0.5)的真值框的3D IoU的预测才会被存储和更新。
推理阶段:与训练阶段不同,序列的每一帧都是按顺序发送到网络的,这意味着跟踪查询的存在时间可能比训练时间更长。在推理阶段出现的另一个差异是关于查询更新的,我们使用分类分数来过滤查询(在实践中,检测查询为0.4,跟踪查询为0.35),而不是3D IoU度量,因为真值不可用。此外,为了避免短时间遮挡造成的轨迹中断,我们在推理阶段为轨迹使用了生命周期机制。具体来说,对于每个跟踪查询,只有当其相应的分类分数连续一段时间(实践中为2秒)小于0.35时,它才会被视为完全消失并被删除。
E.2. 在线建图
根据56,我们将地图查询集分解为thing查询和stuff查询。thing查询模型实例的地图元素(即车道、边界和人行横道),并通过二分匹配与真值进行匹配,而stuff查询仅负责语义元素(即可驾驶区域),并使用类固定分配进行处理。我们将thing查询的总数设置为300,可驾驶区域只有1个stuff查询。此外,我们堆叠了6个位置解码器层和4个掩模解码器层(我们遵循56中的这些层的结构)。我们根据经验选择位置解码器后的thing查询,作为我们的地图查询 QM 的下游任务。

表11. 本文中的符号和超参数查找表。某些符号中的上标 t 表示OccFormer的第 t 个块,为简单起见,在描述中省略了。
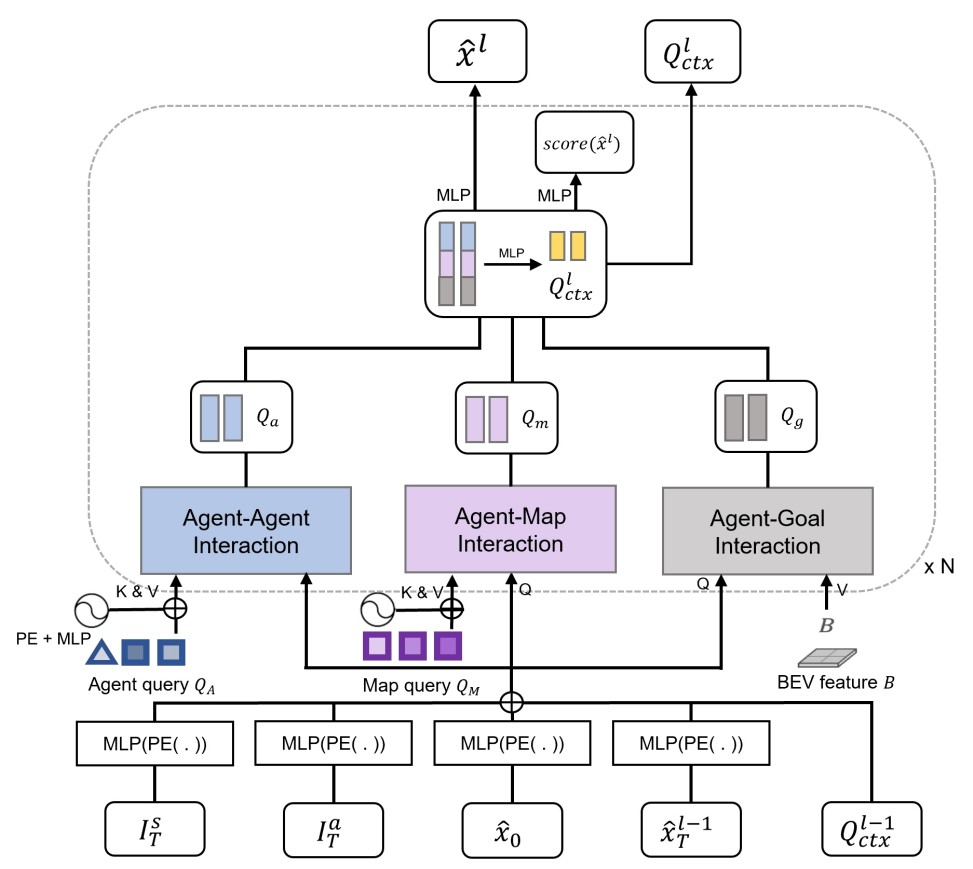
图4. MotionFormer . 它由N个堆叠的代理、代理地图和代理目标交互transformer组成。代理-代理和代理-地图交互模块是用标准的transformer解码器层构建的。代理目标交互模块是在可变形交叉注意力模块109的基础上构建的。 I T s I^s_T ITs:场景级锚点的终点, I T a I^a_T ITa:所包含的代理级锚点的端点, x ^ 0 \hat{x}_0 x^0:代理的当前位置, x ^ T l − 1 \hat{x}^{l-1}T x^Tl−1:来自上一层的预测目标点, Q c t x l − 1 Q^{l-1}{ctx} Qctxl−1:来自前一层的查询上下文。
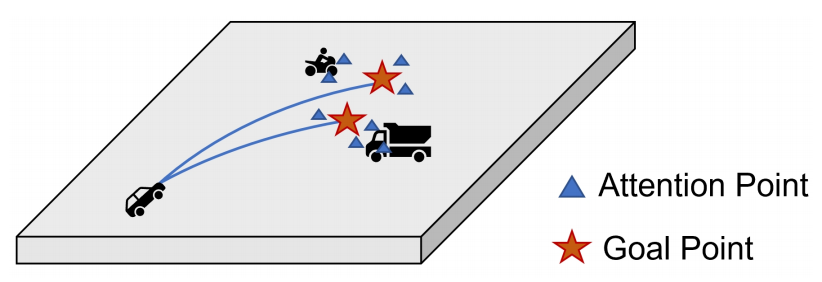
图5. 代理目标交互模块示意图。BEV视觉特征在每个代理的目标点附近进行采样,并具有可变形的交叉注意力。
E.3. 运动预测
为了更好地说明细节,我们提供了一个如图4所示的图表。我们的MotionFormer采用 I T a I^a_T ITa、 I T s I^s_T ITs、 x ^ 0 \hat{x}_0 x^0、 x ^ T l − 1 ∈ R K × 2 \hat{x}^{l-1}T∈\mathbb{R}^{K×2} x^Tl−1∈RK×2来嵌入查询位置,并采用 Q c t x l − 1 Q^{l-1}{ctx} Qctxl−1 作为查询上下文。具体来说,通过 k-means 算法在所有代理的训练数据中对锚点进行聚类,我们设置 K=6,这与我们的输出模态兼容。为了预先嵌入场景级别,根据每个代理的当前位置和航向角(表示为 I T s I^s_T ITs),将锚点 I T a I^a_T ITa 旋转并平移到全局坐标系中,如方程式(12)所示
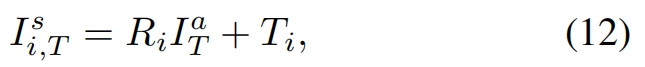
其中 i 是代理的索引,为简洁起见,稍后省略。为了促进从粗到细的范式,我们还采用了从上一层 x ^ T l − 1 \hat{x}^{l-1}T x^Tl−1 预测的目标点。同时,代理的当前位置在模态上广播,表示为 x ^ 0 \hat{x}0 x^0。然后,对每个先验位置知识应用 MLPs 和正弦位置嵌入,并将其总结为查询位置 Q p o s ∈ R K × D Q{pos}∈\mathbb{R}^{K×D} Qpos∈RK×D,其形状与查询上下文 Q c t x Q{ctx} Qctx 相同。 Q p o s Q_{pos} Qpos 和 Q c t x Q_{ctx} Qctx 一起构建了我们的运动查询。我们在 MotionFormer 中将 D 设置为256。
如图4所示,我们的MotionFormer由三个主要的transformer块组成,即代理-代理、代理-地图和代理-目标交互模块。代理-代理、代理-地图交互模块由标准的transformer解码器层构建,这些层由多头自注意力(MHSA)层和多头交叉注意力(MHCA)层、前馈网络(FFN)以及其间的几个残差和归一化层组成8。除了代理查询 QA 和地图查询 QM 外,我们还将位置嵌入添加到那些具有正弦位置嵌入和MLP层的查询中。代理-目标交互模块基于可变形交叉注意力模块109构建,其中采用先前预测轨迹 ( R i x ^ i , T l − 1 + T i ) (R_i\hat{x}^{l−1}_{i,T}+T_i) (Rix^i,Tl−1+Ti)中的目标点作为参考点,如图5所示。具体来说,我们将采样点的数量设置为每个轨迹4个,每个代理6个轨迹,如上所述。每个交互模块的输出特征被连接起来,并用 MLP 层投影到维度 D=256。然后,我们使用高斯混合模型来构建每个代理的轨迹,其中 x ^ l ∈ R K × T × 5 \hat{x}_l∈R^{K×T×5} x^l∈RK×T×5。我们在UniAD中将预测时间范围 T 设置为 12(6秒)。请注意,我们只将最后一个维度的前两个维度(即 x 和 y)作为最终的输出轨迹。此外,还预测了每种模态的得分 ( s c o r e ( x ^ l ) ∈ R K ) (score(\hat{x}_l)∈R^K) (score(x^l)∈RK)。我们将整个模块堆叠 N 次,在实践中 N 设置为 3。
E.4. 占用预测
考虑到上游模块的BEV特征,我们首先用卷积层对其进行/4的降采样,以实现高效的多步预测,然后将其传递给我们提出的OccFormer。OccFormer由图6所示的 To 顺序块组成,其中 To=5 是时间范围(包括当前和未来的帧),每个块负责生成一个特定帧的占用。与缺乏代理级知识的先前工作不同,我们提出的方法在展开未来表示时结合了密集场景特征和稀疏代理特征。密集场景特征来自最后一个块的输出(或当前帧的观察特征),并通过卷积层进一步缩小(/8),以减少像素代理交互的计算。稀疏代理特征是从跟踪查询 QA、代理位置 PA 和运动查询 QX 的级联中得出的,然后将其传递给特定于时间的MLP以获得时间敏感性。我们进行像素级的自注意力,以模拟一些快速变化的场景中所需的长期依赖性,然后通过将场景的每个像素关注到相应的代理来进行场景代理合并。为了增强代理和像素之间的位置对齐,我们使用一个注意力掩码来限制交叉注意力,该掩码是通过掩码特征和缩小的场景特征之间的矩阵乘法生成的,其中掩码特征是通过用MLP对代理特征进行编码而产生的。然后,我们将关注的密集特征上采样到与输入 F t − 1 ( / 4 ) F^{t-1}(/4) Ft−1(/4)相同的分辨率,并将其与 F t − 1 F^{t-1} Ft−1 相加作为稳定性的残差连接。得到的特征 F t F^t Ft 既被发送到下一个块,也被发送到卷积解码器,用于以原始BEV分辨率(/1)预测占用。我们重用掩码特征并将其传递给另一个MLP以形成占用特征,因此实例级占用是通过占用特征和解码的密集特征 F d e c t ( / 1 ) F^t_{dec}(/1) Fdect(/1)之间的矩阵乘法生成的。请注意,用于掩码特征的MLP层、用于占用特征的MLP层和卷积解码器在所有 To 块中共享,而其他组件在每个块中都是独立的。在OccFormer中,所有密集特征和代理特征的尺寸均为256。
E.5. 规划
如图7所示,我们的规划器采用跟踪和运动预测模块生成的自车查询,分别用蓝色三角形和黄色矩形表示。这两个查询以及命令嵌入都使用MLP层进行编码,然后是跨模态维度的最大池层,在该层中选择并聚合最突出的模态特征。BEV特征交互模块由标准transformer解码器层构建,并堆叠了N层,其中我们在这里设置N=3。具体来说,它将密集BEV特征与聚合规划查询交叉处理。更多定性结果见附录F.5,显示了该模块的有效性。为了嵌入位置信息,我们将规划查询与学习位置嵌入相融合,将BEV特征与正弦位置嵌入相结合。然后,我们用MLP层对规划轨迹进行回归,记为 τ ^ ∈ R T p × 2 \hat{τ}∈R^{T_p×2} τ^∈RTp×2。这里我们设置 T p = 6 T_p=6 Tp=6(3秒)。最后,我们设计了用于避障的碰撞优化器,该优化器将预测的占用 O ^ \hat{O} O^ 和轨迹 τ ^ \hat{τ} τ^ 作为输入,如主论文中的方程(10)所示。我们设置 d=5,σ=1.0,λcoord=1.0,λobs=5.0。
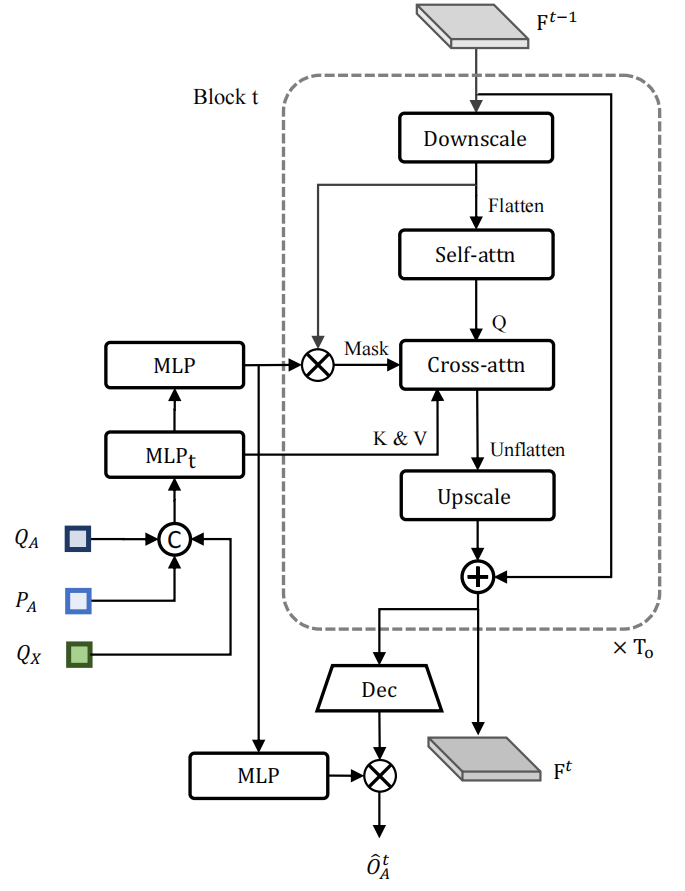
图6. OccFormer . 它由 To 顺序块组成,其中 To 是时间范围(包括当前和未来帧),每个块负责生成一个特定帧的占用。我们结合了从上游跟踪查询 QA、代理位置 PA 和运动查询 QX 编码的密集场景特征和稀疏代理特征,将代理级知识注入到未来的场景表示中。我们通过在每个块末尾的代理级特征和解码的密集特征之间进行矩阵乘法,形成实例级占用 O ^ A t \hat{O}^t_A O^At。
E.6. 训练详情
联合学习 。UniAD分为两个阶段进行训练,我们发现这两个阶段更稳定。在第一阶段,我们预先训练感知任务,包括跟踪和在线建图,以稳定感知预测。具体来说,我们将相应的预训练BEVFormer55权重加载到UniAD中,以实现快速收敛,包括图像主干、FPN、BEV编码器和检测解码器,但对象查询嵌入除外(由于额外的自车查询)。我们停止图像骨干中的梯度反向传播以降低内存成本,并训练UniAD 6个迭代周期,跟踪和在线建图损失如下:
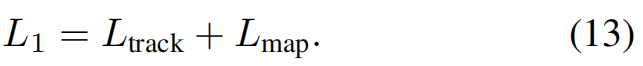
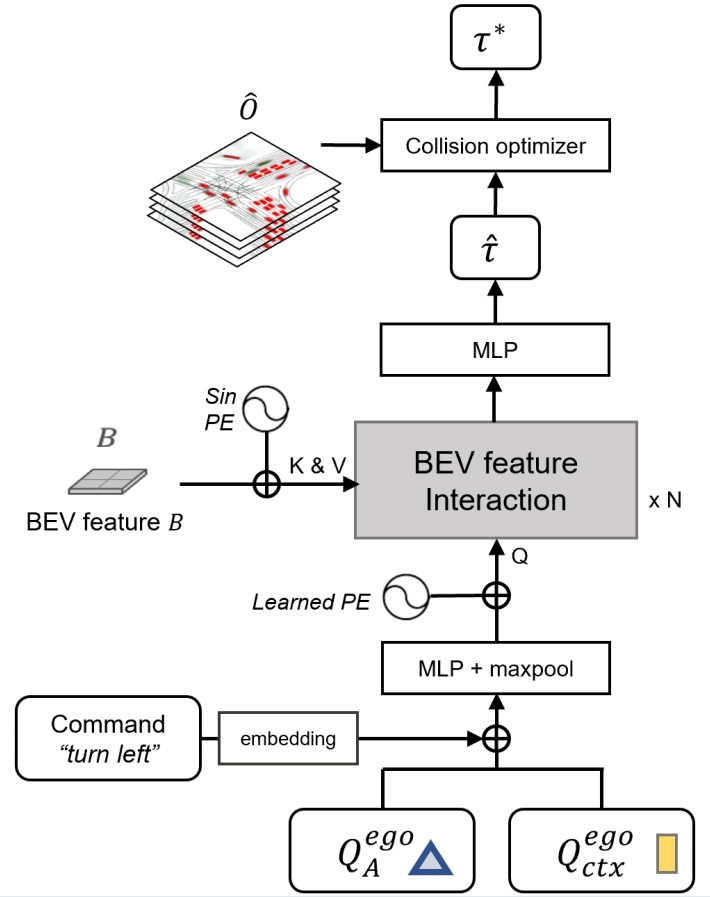
图7. 规划器 . Q A e g o Q^{ego}A QAego 和 Q c t x e g o Q^{ego}{ctx} Qctxego 分别是来自跟踪和运动预测模块的自车查询。与高级命令一起,它们用MLP层编码,然后是跨模态维度的最大池化层,在该层中选择并聚合最突出的模态特征。BEV特征交互模块由标准transformer解码器层构建,并堆叠了N层。
在第二阶段,我们也保持图像骨干的冻结状态,并额外冻结用于从图像视图到BEV的视图转换的BEV编码器,以进一步减少更多下游模块的内存消耗。UniAD现在接受了所有任务损失的训练,包括跟踪、建图、运动预测、占用预测和20个周期的规划(对于主论文中的各种消融研究,它接受了8个周期的训练以提高效率):

下面分别描述 L1 和 L2 的每个项内的详细损失和超参数。在两个阶段,用于跟踪和BEV特征聚合的每个训练序列(每一步)的长度为5(在消融研究中为3)。
检测和跟踪损失 。根据BEVFormer55,每个配对结果都采用匈牙利损失,这是类标签的焦点损失61和3D框定位的 l 1 l_1 l1 的线性组合。在匹配策略方面,来自新查询的候选对象通过二分匹配与真值对象配对,来自跟踪查询的预测继承了先前帧中分配的真值索引。具体来说, L t r a c k = λ f o c a l L f o c a l + λ l 1 L l 1 L_{track}=λ_{focal}L_{focal}+λ_{l_1}L_{l_1} Ltrack=λfocalLfocal+λl1Ll1,其中 λ f o c a l = 2 λ_{focal}=2 λfocal=2, λ l 1 = 0.25 λ_{l_1}=0.25 λl1=0.25。
在线建图损失 。如56所述,这包括车道、分隔带和轮廓的thing损失,也包括可驾驶区域的stuff损失。其中,焦点损失负责分类,L1损失负责thing边界框,Dice损失和GIoU损失80负责分割。具体来说, L m a p = λ f o c a l L f o c a l + λ l 1 L l 1 + λ g i o u + λ d i c e L d i c e L_{map}=λ_{focal}L_{focal}+λ_{l_1}L_{l_1}+λ_{giou}+λ_{dice}L_{dice} Lmap=λfocalLfocal+λl1Ll1+λgiou+λdiceLdice,其中 λ f o c a l = λ g i o u = λ d i c e = 2 λ_{focal}=λ_{giou}=λ_{dice}=2 λfocal=λgiou=λdice=2, λ l 1 = 0.25 λ_{l_1}=0.25 λl1=0.25。
运动预测损失 。与大多数先前的方法一样,我们将多峰轨迹建模为高斯混合,并使用多路径损失12,90,其中包括分类得分损失 L c l s L_{cls} Lcls 和负对数似然损失项 L n l l L_{nll} Lnll,λ 表示相应的权重: L m o t i o n = λ c l s L c l s + λ r e g L n l l L_{motion}=λ_{cls}L_{cls}+λ_{reg}L_{nll} Lmotion=λclsLcls+λregLnll,其中 λ c l s = λ r e g = 0.5 λ_{cls}=λ_{reg}=0.5 λcls=λreg=0.5。为了确保轨迹的时间平滑性,我们首先预测代理在每个时间步的速度,并随着时间的推移将其累积,以获得它们的最终轨迹41。
占用预测损失 。实例级占用预测的输出是每个代理的二进制分割,因此我们采用二进制交叉熵和Dice损失67作为占用损失。形式上, L o c c = λ b c e L b c e + λ d i c e L d i c e L_{occ}=λ_{bce}L_{bce}+λ_{dice}L_{dice} Locc=λbceLbce+λdiceLdice,其中 λ b c e = 5 λ_{bce}=5 λbce=5, λ d i c e = 1 λ_{dice}=1 λdice=1。此外,由于像素代理交互模块中的注意力掩码可以被视为一种粗略的预测,我们采用相同形式的辅助占用损失来监督它。
规划损失 。安全是规划中最关键的因素。因此,除了简单的模仿 l 2 l_2 l2 损失外,我们还采用了另一种碰撞损失,使规划的轨迹远离障碍物,如下所示:
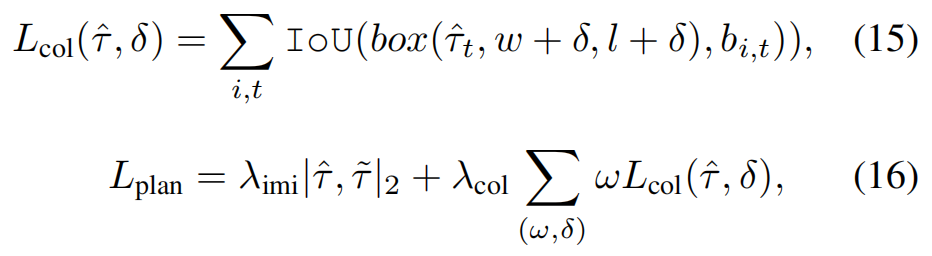
其中 λ i m i = 1 λ_{imi}=1 λimi=1, λ c o l = 2.5 λ_{col}=2.5 λcol=2.5, ( ω , δ ) (ω,δ) (ω,δ)是一个考虑额外安全距离的权重值对,框 ( τ ^ t , ω + δ , l + δ ) (\hat{τ}t,ω+δ,l+δ) (τ^t,ω+δ,l+δ)表示自我边界框,在时间戳 t 时大小增加,以保持更大的安全距离, b i , t b{i,t} bi,t表示场景中预测的每个代理。在实践中,我们将 ( ω , δ ) (ω,δ) (ω,δ) 设置为(1.0,0.0),(0.4,0.5),(0.1,1.0)。
F. 实验
F.1. 协议
我们遵循BEVFormer55中的大多数基本训练设置,两个阶段的批处理大小为1,学习率为 2×10−4,骨干学习率乘数为0.1,AdamW优化器65的权重衰减为 1×10−2。BEV尺寸的默认尺寸为 200×200,涵盖X轴和Y轴的BEV范围51.2m,51.2m,间隔为0.512m。与特征维度相关的更多超参数如表11所示。实验使用16个NVIDIA Tesla A00 GPU进行。
F.2. 指标
多目标跟踪 。根据标准评估协议,我们使用AMOTA (平均多目标跟踪精度)、AMOTP (平均多对象跟踪精度),Recall 和 IDS(身份切换)来评估UniAD在nuScenes数据集上的3D跟踪性能。AMOTA和AMOTP是通过整合所有召回的MOTA(多目标跟踪精度)和MOTP(多目标追踪精度)值来计算的:
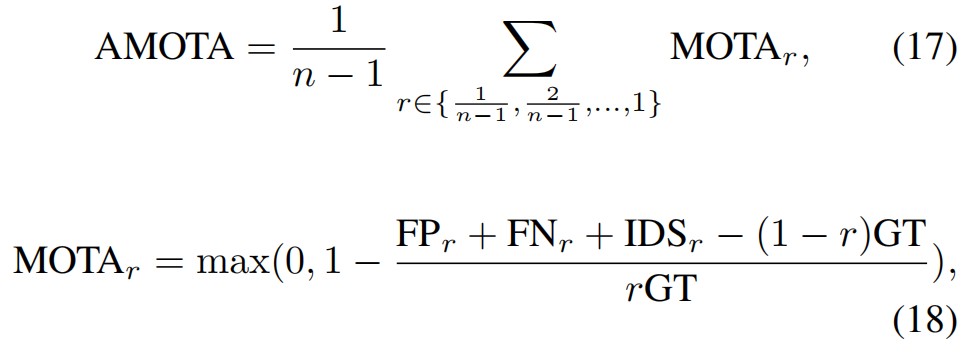
其中 FPr、FNr 和 IDSr分别表示在相应召回率 r 下计算的假阳性、假阴性和身份转换的数量。GT代表此帧中真值对象的数量。AMOTP可以定义为:
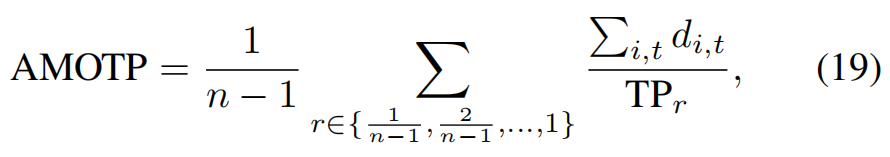
其中 d i , t d_{i,t} di,t 表示匹配跟踪 i 在时间戳 t 处的位置误差(在x和y轴上),TPr 是相应召回率 r 处的真阳性数。
在线建图 。我们为在线建图任务分为四类,即车道、边界、人行横道和可驾驶区域。我们计算网络输出和真值图之间每个类的联合交集(IoU)度量。
运动预测 。一方面,遵循标准的运动预测协议,我们采用传统的度量,包括minADE (最小平均位移误差)、minFDE (最小最终位移误差)和MR (漏检率)。与先前的工作57,66,75类似,这些指标仅在匹配的TP内计算,我们在所有实验中将匹配阈值设置为1.0m。对于MR,我们将未命中FDE阈值设置为2.0m。另一方面,我们还采用了最近提出的端到端指标,即EPA(端到端预测准确性)30和minFDE AP75。对于EPA ,我们使用与ViP3D30中相同的设置进行公平比较。对于minFDE AP,为了简单起见,我们没有将真值分为多个箱(静态、线性和非线性移动子类别)。具体来说,只有当物体的感知位置及其最小FDE在距离阈值(分别为1.0m和2.0m)内时,它才会被计为AP(平均精度)计算的TP。与先前的工作类似,我们将汽车、卡车、工程车辆、公共汽车、拖车、摩托车和自行车合并为车辆类别,并在车辆类别上评估实验中提供的所有运动预测指标。
占用预测 。我们在整个场景级别和实例级别评估了预测占用的质量35105。具体来说,IoU 测量整个场景的分类分割,这是实例无关的,而视频全景质量(VPQ)48考虑了每个实例随时间的存在和一致性。VPQ度量计算如下:
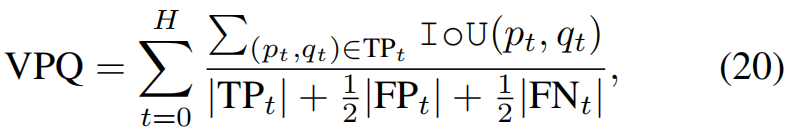
其中 H 是未来视界,我们设置 H=4(这导致 To=5,包括当前时间戳),如35,105所示,覆盖2Hz的2.0秒连续数据。TPt、FPt和FNt分别是时间戳t处的真阳性、假阳性和假阴性的集合。这两个指标在两个不同的BEV范围内进行评估,在自车周围30m×30m的近距离 ("-n")和100m×100m的远距离("-f")。我们在两个指标上一起评估当前步骤(t=0)和未来4个步骤的结果。
规划 。我们采用与ST-P338中相同的度量,即不同时间戳的L2错误率和****冲突率。
F.3. 模型复杂性和计算成本
我们在Nvidia Tesla A100 GPU上测量了UniAD的复杂性和运行时间,如表13所示。虽然任务的解码器部分带来了一定数量的参数,但与原始的BEVFormer检测器(ID.1)相比,计算复杂度主要来自编码器部分。我们还与最近的BEVerse105进行了比较。UniAD拥有更多的任务,实现了卓越的性能,并且具有较低的FLOPs------这表明预算负担得起增加的计算成本。
F.4. 模型尺寸
我们提供了UniAD在不同模型尺度下的三种变体,如表12所示。用于图像视图特征提取的选定图像主干分别是UniAD-S、UniAD-B和UniAD-L的ResNet-5032、ResNet-101和VoExpressRoute 2-9951。由于模型尺度(图像编码器)主要影响BEV特征质量,我们可以观察到,随着骨干网的增大,感知得分会提高,这可能会带来更好的预测和规划性能。

表12. UniAD.*的三种变体之间的比较:使用额外深度数据进行预训练73。
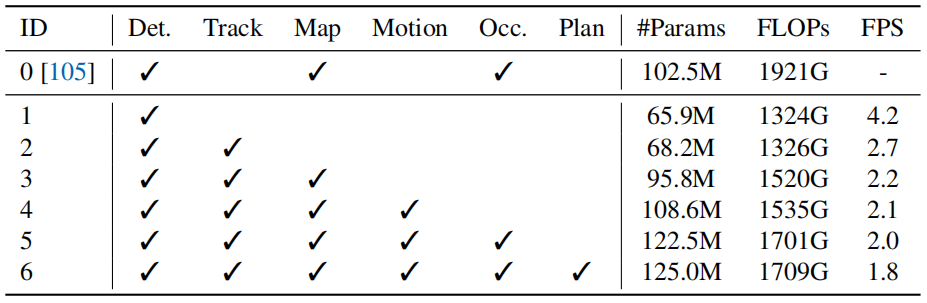
表13. 包含不同模块的计算复杂性和运行时间。ID.1类似于原始的BEVFormer55,ID.0(BEVerse Tiny)105是一个MTL框架。
F.5. 定性结果
注意力掩码可视化。为了研究内部机制并展示其可解释性,我们在规划器中可视化了交叉注意力模块的注意力掩码。如图8所示,渲染了预测的跟踪边界框、规划轨迹和真值高清地图以供参考,并在其上叠加了注意力掩码。从左到右,我们按时间顺序显示两个连续的帧,但导航命令不同。我们可以观察到,规划的轨迹会根据命令而发生很大变化。此外,我们非常关注目标车道以及屈服于自车的关键因素。
不同场景的可视化。我们为更多场景提供可视化,包括在城市地区巡航(图9)、临界情况(图10)和避障场景(图11)。图12显示了我们面向规划的设计的一个有希望的证据,其中在先前的模块中出现了不准确的结果,而后期的任务仍然可以恢复。同样,我们在环绕视图图像、BEV以及来自规划器的注意力掩模中显示了所有任务的结果。还提供了演示视频(https://opendrivelab.github.io/UniAD/)供参考。
失效案例。对于自动驾驶算法了解其弱点并指导未来的工作至关重要,这里我们介绍了UniAD的一些失效案例。UniAD的失效案例主要是在一些长尾场景下,所有模块都受到影响,如图13和图14所示。

图8. 导航命令和注意力掩码可视化的有效性。在这里,我们演示了如何根据导航命令来注意力。我们在规划模块中渲染了BEV交互模块的注意力掩码、预测的跟踪边界框以及规划的轨迹。导航命令打印在左下角,HD地图仅供参考。从左到右,我们按时间顺序显示两个连续的帧,但导航命令不同。我们可以观察到,规划的轨迹会根据命令而发生很大变化。此外,我们非常关注目标车道以及屈服于自车的关键因素。
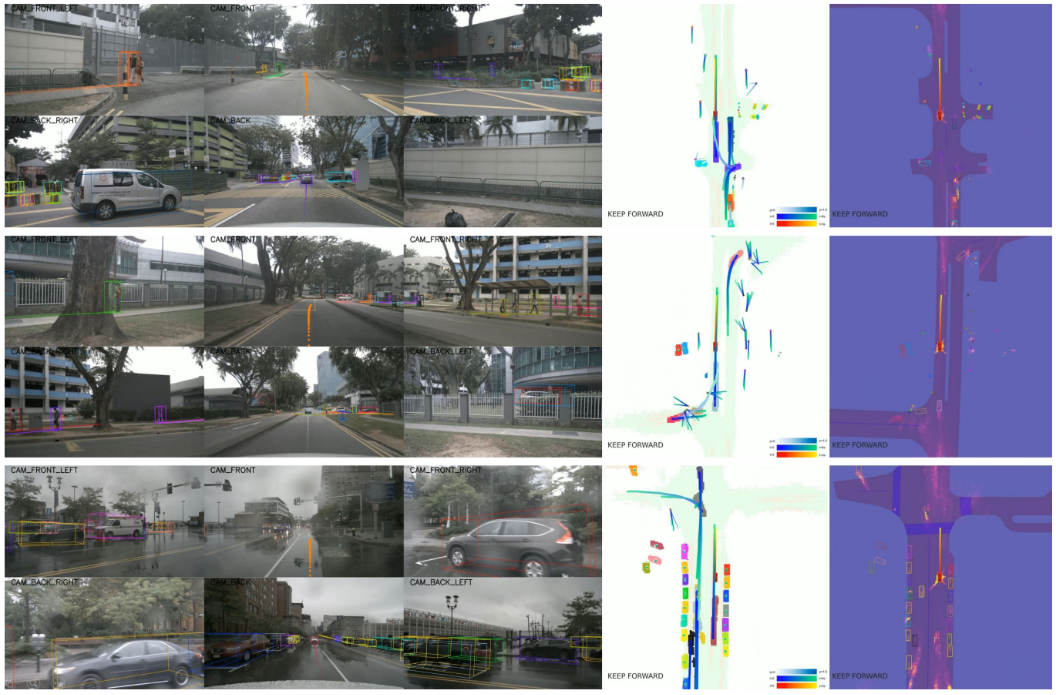
图9. 城市巡航可视化。UniAD可以生成高质量的可解释感知和预测结果,并做出安全的操作。前三列显示了六个摄像头视图,后两列分别是规划模块的预测结果和注意力掩码。每种代理都有独特的颜色。分别选择运动预测中的前1和前3个轨迹在图像视图和BEV上进行可视化。
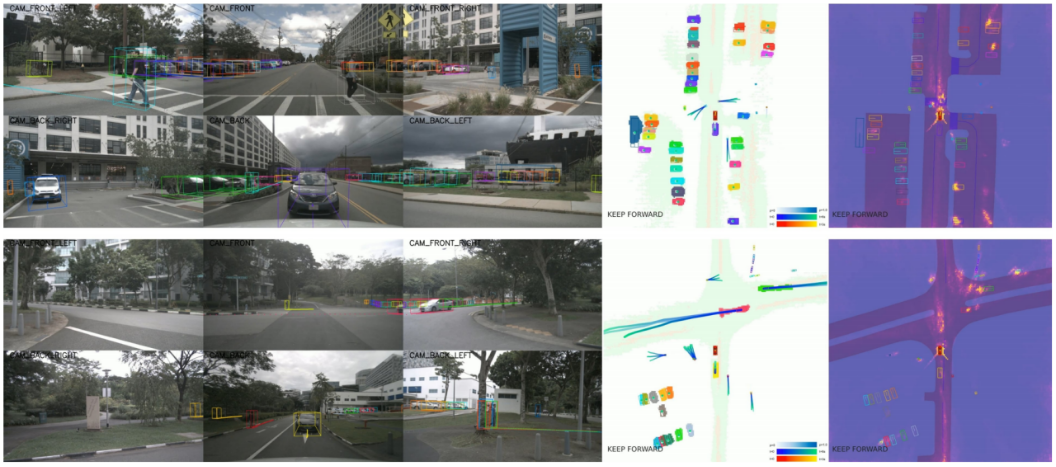
图10. 关键案例可视化。这里我们演示两个关键案例。第一种情况(上图)显示,自车正在向两名过马路的行人让路,第二种情况(下图)显示,自车正在向一辆快速行驶的汽车让路,并在十字路口附近等待在没有保护的情况下直行。我们可以观察到,人们非常关注最关键的因素,即行人和快速行驶的车辆,以及预期的目标位置。

图11. 避障可视化。在这两种情况下,自车会小心地变道以避开障碍车辆。从注意力掩码上,我们可以观察到我们的方法不仅关注前方和后方的道路,还关注障碍物。
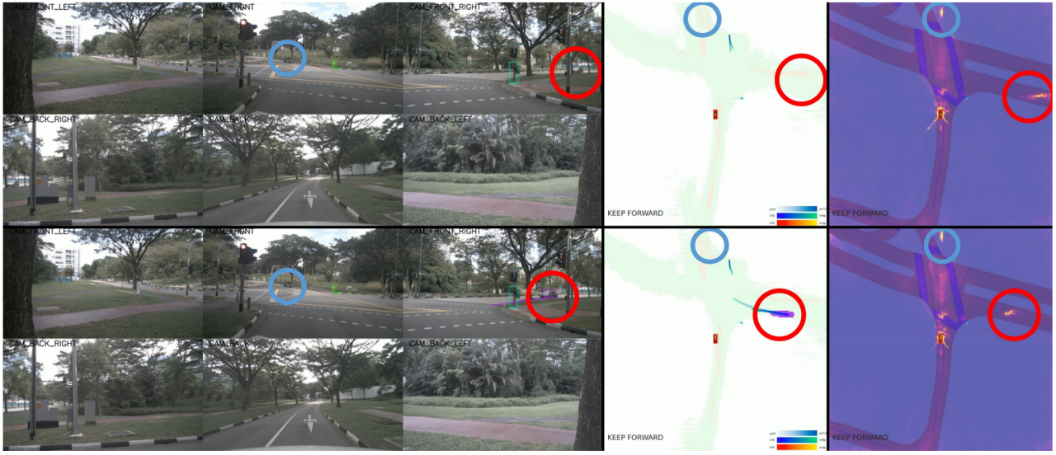
图12. 从感知失败中恢复规划的可视化。我们展示了一个有趣的案例,在前面的模块中出现了不准确的结果,而后面的任务仍然可以恢复。第一行和第二行代表同一场景中的两个连续帧。红圈中的车辆正从远处高速驶向十字路口。观察到跟踪模块首先错过了它,然后在后一帧捕获了它。蓝色圆圈表示一辆静止的汽车屈服于交通,在两帧中都没有看到。有趣的是,这两辆车对规划器的注意力掩码都表现出强烈的反应,尽管在前面的模块中都错过了。这意味着我们的规划器仍然关注那些关键但遗漏的代理,这在以前的碎片化和非统一的驱动系统中很难解决,并证明了UniAD的鲁棒性。
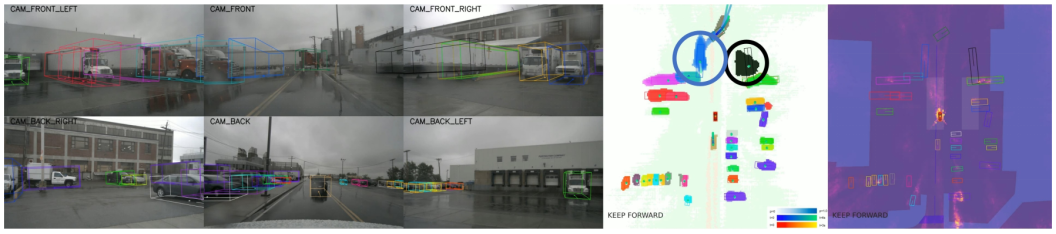
图13. 失效案例1。在这里,我们展示了一个长尾场景,一辆带白色集装箱的大型拖车占据了整条路。我们可以观察到,我们的跟踪模块无法检测到前拖车的准确尺寸和路边车辆的航向角。

图14. 失效案例2。在这种情况下,规划器对狭窄街道上的车辆过于谨慎。黑暗环境是自动驾驶中长尾场景的一种关键类型。应用较小的碰撞损失权重和更多的边界规定可能会缓解这个问题。