REF:多模态融合下家居机器人高精度SLAM 与区域分割方法研究
1. 人工智能基础概念
-
人工神经网络(Artificial Neural Network,ANN):理论基础建立在生物神经系统的数学抽象与非线性函数逼近能力之上,目标是通过非线性变换逼近复杂函数关系,数学框架可视为一个参数化函数的优化问题,网络通过层级化的非线性映射构建从输入到输出的预测模型,其层级结构可视为特征空间的逐层变换,每一层将输入数据映射到新的表征空间,最终通过线性分类器或回归器完成预测。
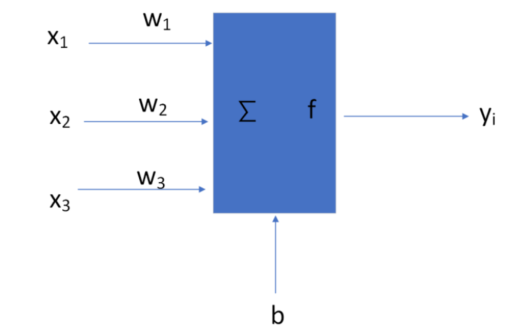
-
损失函数:为网络提供了明确的优化目标,将预测结果与真实值之间的差异量化为标量指标,网络参数通过最小化损失函数优化,常见损失函数包括均方误差和交叉熵:
-
均方误差(MSE):通过平方差衡量回归任务的误差
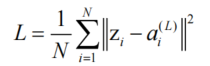
-
交叉熵(Cross-Entropy):通过概率分布差异评估分类性能
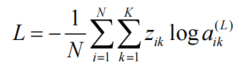
-
-
反向传播算法:通过链式法则计算损失对参数的梯度,将损失函数的梯度从输出层逐层反向传播至输入层:
-
计算前向传播计算输出层误差:
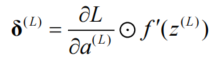
-
反向传播误差至隐藏层:
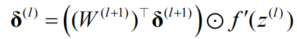
-
计算参数梯度:
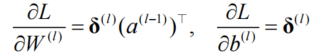
-
-
卷积神经网络(Convolutional Neural Network, CNN):是一种专为处理网格结构数据(如图像、语音)设计的深度学习模型,其核心创新在于突破传统全连接网络的局限性。不同于人工神经网络的全连接结构,CNN 受生物视觉系统启发,通过局部感受野将每个神经元的连接范围限制在输入数据的局部区域大幅减少参数数量
-
层次化特征学习:是 CNN 区别于传统机器学习模型的本质特征,浅层卷积核捕获的低级特征(如边缘、角点)通过深层网络的逐级组合,逐渐抽象为高级语义模式(如车轮、人脸轮廓),当特征传递至末端的全连接层时,空间信息被压缩为向量表示,并通过 Softmax 等函数映射到类别概率空间,完成从像素到语义的跨越。
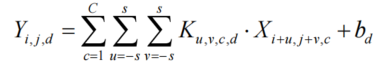
-
稀疏梯度传递:最大池化层在反向传播时,仅将梯度回传至前向传播中取最大值的位置,这种稀疏梯度传递方式保留了池化操作的特性
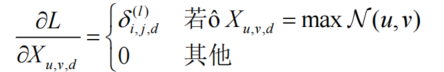
-
Dropout 技术:针对过拟合问题,通过随机屏蔽神经元输出,强制网络发展冗余的特征提升泛化能力,这些训练细节的优化与模型结构设计共同作用,使得 CNN 在 ImageNet 等大规模图像数据集上展现出超越传统方法的性能。

-
注意力机制(Attention Mechanism):一种模拟人类认知过程中选择性关注重要信息的计算模型,理论框架围绕信息选择与动态聚焦展开,核心在于突破传统神经网络对输入数据的平等处理方式,模仿人类认知过程中对关键信息的选择性强化,通过数学建模将输入元素的重要性差异转化为可学习的权重分配,从而在复杂数据中自动捕捉有意义的关联模式:
-
注意力打分:计算所有键的相似度
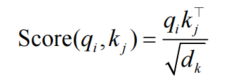
-
确定分布:使用 Softmax 函数将相似度转换为概率分布,归一化的权重矩阵如同一个动态滤波器,决定哪些值向量需要被放大或抑制

-
加权求和:计算得到的上下文向量,既包含原始值信息,又融入了跨元素的关联强度
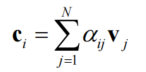
-
-
自注意力机制:通过让查询、键、值均来自同一输入序列,将动态权重分配的能力扩展到序列内部的长距离依赖建模,这种特性使得自注意力成为Transformer 模型的核心组件,通过参数矩阵实现输入到查询、键、值的可学习映射
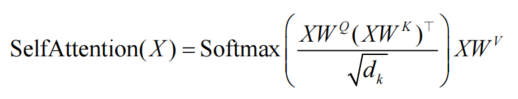
-
多头注意力机制:并行执行多组独立的注意力计算,每组使用不同的线性变换矩阵,相当于在多个子空间中探索特征关联,最后通过注意力头输出来拼接结果增强模型对不同抽象层次特征的捕获能力
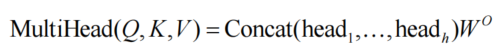
-
Transformer架构:一种基于自注意力机制的序列建模架构,通过自注意力机制的统一视角,将序列元素间的所有交互建模为可并行计算的矩阵运算,从而同时解决了效率与长程建模的难题,具体采用编码器-解码器结构作为基础架构,通过堆叠多层相同模块实现特征的层次化提炼,编码器的每一层本质上是"自注意力+前馈网络"的复合函数
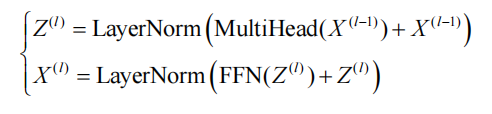
其中:
-
X:输入
-
MultiHead:多头注意力机制对输入进行并行注意力计算
-
FFN:前馈神经网络,对Z进行非线性变换
-
2. SLAM建图
-
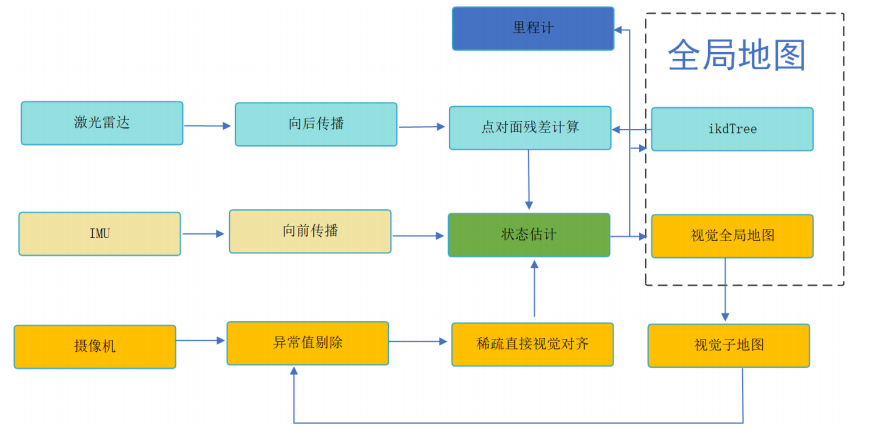
FAST-LIVO 系列(包括 FAST LIVO 与 FAST-LIVO2)基于激光-视觉-惯性紧耦合架构,通过稀疏直接法实现高精度位姿估计与地图构建,基于迭代误差卡尔曼滤波(IEKF),通过不同的优化技术改进:
-
Fast-LIVO1 直接法视觉观测,从激光雷达扫描点云中筛选出部分点作为视觉特征点
-
Fast-LIVO2:使用概率体素地图VoxelMap替换原先的 IKD-Tree ,并扩展了视觉观测模型优化 VoxelMap
-
-
改进直接法视觉观测模型:通过光流法提供全局运动初值约束,结合直接法细化局部对齐,形成几何-光度双重校验机制,显著提升视觉观测的鲁棒性
3. 目标检测
-
传统YOLOv7:作为 YOLO 系列中集大成,在速度与精度方面(检测精度与推理速度)取得了较好的平衡,适合纯检测任务,架构围绕特征高效提取-多尺度融合-动态预测的递进式流程展开,包含三大模块:
-
骨干网络(Backbone):负责基础特征捕获
-
特征融合模块(Neck):双向跨尺度信息交互网络,强化跨层级信息交互
-
检测头(Head):目标定位与分类的精准输出
-
-
改进YOLOv7
-
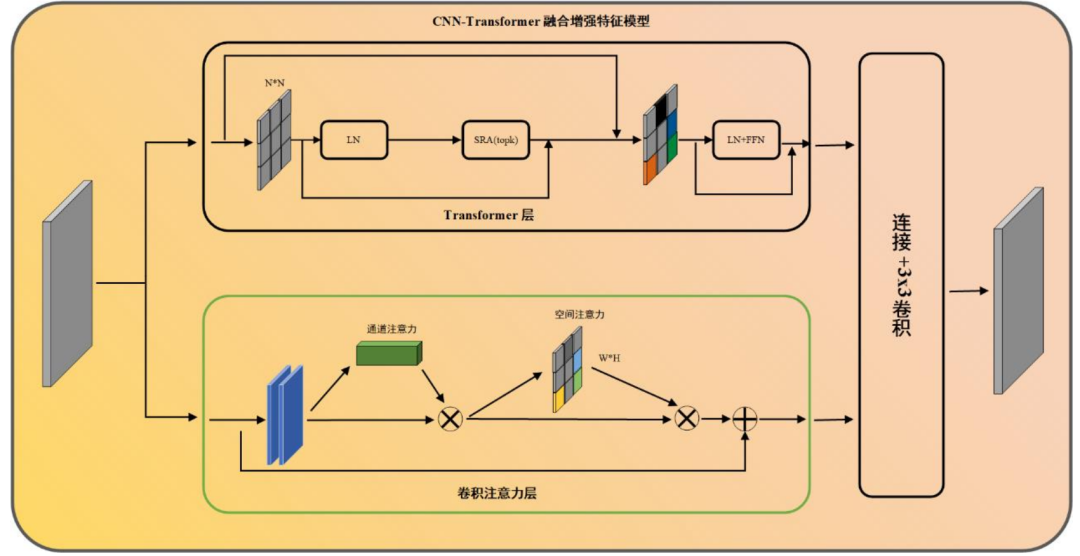
骨干网络优化:采用了 CNN-Transformer 混合增强特征模块(CTHEFM),增强模型的特征提取能力
-
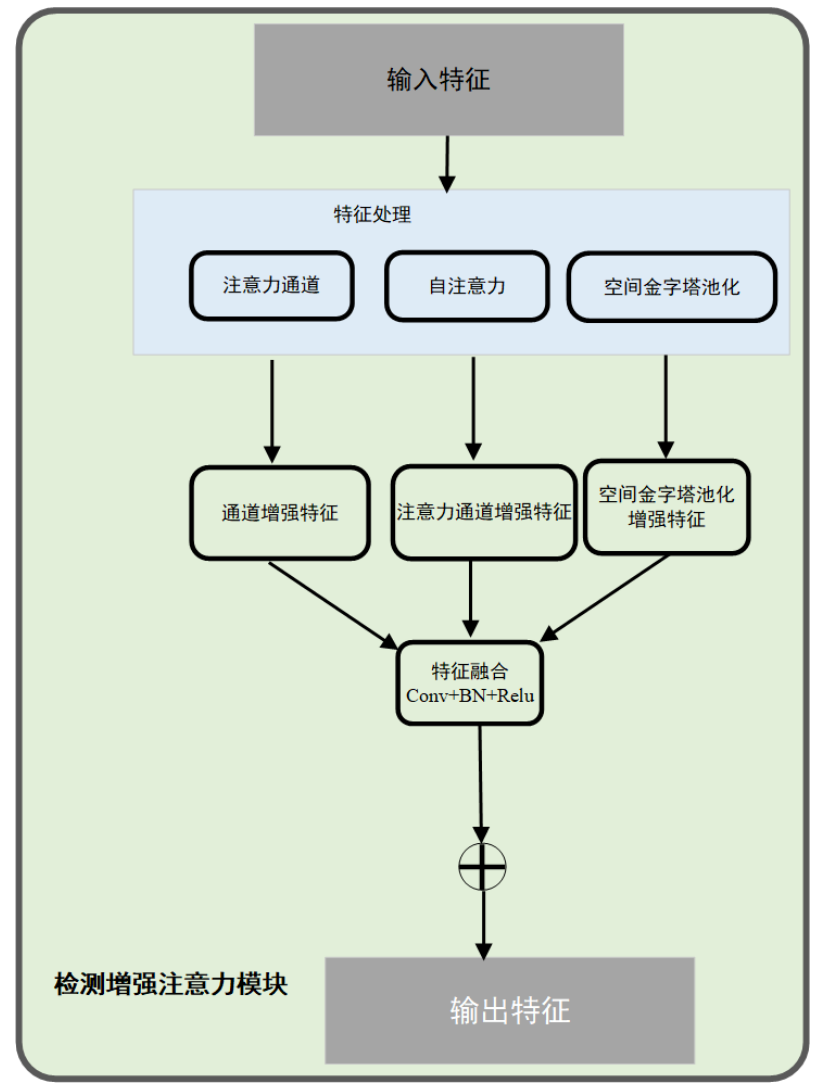
检测头优化:在检测头前引入检测增强注意力模块(DEAM),提升通道敏感性、空间上下文建模能力及多尺度特征适应性
-