摘要:本博客详细介绍了如何在 Ubuntu 22.04 系统上安装和配置深度学习环境 ,包括 NVIDIA 驱动 、CUDA Toolkit 、cuDNN 、Miniconda 及 PyTorch 等关键组件。文章从安装前的注意事项 开始,逐步讲解了如何切换国内软件源 以提升下载速度,接着讲述了系统更新 和基本依赖项 的安装。随后,重点介绍了 NVIDIA 驱动 的自动与手动安装方法,并通过详细的步骤指导读者完成 CUDA Toolkit 和 cuDNN 的下载 、安装 及验证 。最后,文章演示了通过 Miniconda 创建 Python 虚拟环境 ,并安装深度学习框架 (如 PyTorch 和 TensorFlow ),同时通过简单的代码测试确保 GPU 加速功能 正常工作。整个过程旨在帮助读者顺利构建一个稳定 、高效的深度学习开发环境。
前言
在撰写本篇博客时,Ubuntu 24.04 已经发布,同时 NVIDIA 官方也推出了适用于该系统的 CUDA 12.6 版本。然而,经过测试后发现,很多深度学习框架与 Ubuntu 24.04 的兼容性仍然存在问题,导致在安装 PyTorch 等库时频频出错。同时,Ubuntu 系统自身的软件更新也时常出现无法解决的问题。因此,为了保证系统的稳定性和深度学习环境的兼容性,我们最终选择了使用 Ubuntu 22.04 作为服务器的操作系统。这也是目前很多云服务器的默认配置,实际使用中,确实遇到的问题少了很多。
在本教程中,我们将详细介绍如何在 Ubuntu 22.04 上安装和配置深度学习环境,包括 NVIDIA 驱动、CUDA、cuDNN 以及 PyTorch 等深度学习框架。希望这篇教程能够帮助你顺利搭建出一个稳定、高效的深度学习开发环境。

1. 开始安装前
在安装和配置深度学习环境之前,有一些重要的注意事项和准备工作需要了解,尤其对于刚接触 Ubuntu 的用户来说,避免因操作失误而导致系统不稳定或不可用。以下内容将详细介绍在安装过程中需要注意的要点和如何优化 Ubuntu 系统的下载速度。
1.1 安装要领和注意事项
在安装和配置深度学习环境时,有几点关键事项需要特别注意:
-
避免不必要的系统更新和升级:虽然保持系统更新是良好的做法,但在某些情况下,升级系统或内核可能会导致与已安装的 NVIDIA 驱动程序或 CUDA 版本不兼容,从而导致深度学习环境无法正常运行。因此,在安装深度学习环境之前,建议不要随意升级系统和内核,尤其是在一切运行正常的情况下。
-
主打稳定:在配置深度学习环境时,优先考虑稳定性。选择稳定版本的软件和驱动程序,避免使用最新或实验性的版本,除非确实需要那些新特性。
-
不要频繁更换软件源:虽然更换国内的镜像源可以加快软件包的下载速度,但频繁更换源可能导致依赖冲突或更新问题。因此,选择一个稳定且速度快的源后,尽量保持一致。

注意 :请有此觉悟!!!如果你发现无论怎么安装显卡驱动总是出错,或者CUDA安装失败,那要么是最新版的ubuntu系统,要么就是升级了内核导致兼容不了,版本不匹配。此时如果是小白,重装原始ubuntu,或许比你自己折腾更快、更省事。事实就是,系统合适照步骤基本一步到位成功,系统不行搜一堆没用的教程,折腾死去活来也弄不好。在ubuntu中,贪新只能试坑!
1.2 切换软件源
由于 Ubuntu 默认的镜像服务器可能在国内下载速度较慢,建议切换到速度更快的国内镜像源,如阿里云或清华大学的镜像源。以下是具体的操作步骤:
-
打开软件源配置文件:
在 Ubuntu 中,软件源的配置文件位于
/etc/apt/sources.list中。可以通过以下命令打开该文件:bashsudo nano /etc/apt/sources.list执行上述命令后,系统会要求输入管理员密码。输入后,你将进入
nano编辑器,并看到当前的源配置文件内容。
-
替换默认源:
在编辑器中,将默认的源地址替换为你想使用的镜像源。例如,如果选择使用阿里云的镜像源(也可清华源,见下面),可以将文件内容替换为以下内容:
plaintextdeb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse替换完成后,编辑器中内容应类似如下界面:

注意 :在测试过程中,清华源的速度似乎更快。我们可以改为使用清华源,貌似企业用的阿里云比较多,同样的方法是将上述内容替换为如下清华源的配置:
plaintextdeb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse清华源配置后的界面如下所示:

-
保存并退出编辑器:
完成替换后,按
Ctrl + O保存文件,然后按Enter确认保存。接着,按Ctrl + X退出编辑器。 -
更新软件包列表:
为了使新的软件源生效,接下来需要更新软件包列表。执行以下命令:
bashsudo apt update更新过程完成后,你可以看到软件包列表已经更新,如下图所示:

到这里,你已经成功地切换了 Ubuntu 的软件源,下载速度将显著提升,为后续的安装和配置过程做好了准备。
2. 更新系统列表和安装基本依赖项
在开始安装深度学习环境之前,我们需要确保系统是最新的,并安装一些必要的基本依赖项。这些步骤能够确保后续的安装过程顺利进行,同时避免由于依赖项缺失而引发的问题。
2.1 更新系统列表
首先,确保系统软件包列表是最新的,并且安装了所有可用的更新。为此,你需要执行以下命令:
bash
sudo apt update
sudo apt upgrade -ysudo apt update:更新系统的软件包列表,使其包含最新的软件包信息。sudo apt upgrade -y:升级系统中已经安装的软件包。
在执行这些命令时,系统会下载并安装所有可用的更新。你可能会看到类似以下的输出:
2.2 安装基本依赖项
接下来,我们需要安装一些基本的构建工具。这些工具包括 gcc、g++、make 等,它们在编译和安装某些软件包时是必须的。输入以下命令以安装这些工具:
bash
sudo apt install build-essential gcc g++ make -ybuild-essential:包含编译软件所需的核心工具,包括编译器、链接器等。gcc和g++:GNU C 和 C++ 编译器。make:一个控制编译过程的工具,通常用于编译从源代码生成可执行文件的过程。
安装完成后,你应该会看到类似于以下的安装输出:
这些基本工具的安装为后续安装 NVIDIA 驱动程序、CUDA 和其他深度学习库奠定了基础。
3. 安装 NVIDIA 驱动程序
安装 NVIDIA 驱动程序是为了确保你的 GPU 能够与操作系统正常通信,并能够被深度学习框架(如 TensorFlow、PyTorch 等)正确识别和利用。我们将使用 ubuntu-drivers 工具来自动检测和安装适合你 GPU 的驱动程序。
3.1 自动安装 NVIDIA 驱动程序
首先,打开终端并输入以下命令来自动检测并安装合适的 NVIDIA 驱动程序:
bash
sudo ubuntu-drivers autoinstall这个命令会自动检测你系统中安装的 GPU,并选择合适的驱动程序版本进行安装。
你可能会看到类似于以下的输出:
注意 :有时在安装过程中可能会遇到驱动安装失败或冲突的情况。如果出现这种问题,建议首先卸载未成功安装的驱动程序,然后重新尝试安装。以下命令用于卸载之前安装失败的驱动程序(下面的535是驱动型号,你需要看一眼命令行中显示的具体型号修改代码 ),如果上面没有提示出错就不要卸载:
bash
sudo apt-get remove --purge nvidia-dkms-535
sudo apt-get remove --purge nvidia-driver-535这些命令将彻底移除指定的 NVIDIA 驱动程序版本。(看清楚,别装好又卸载了)
3.2 手动选择并安装驱动(可选)
这一步非必须的,如果上面那个代码的自动安装不成功,或者你需要选择特定版本的驱动程序,可以通过以下步骤进行手动安装,如果成功这里不需要再操作:
-
打开"软件和更新"应用。在 Ubuntu 的启动栏中找到这个应用,图标如下:

-
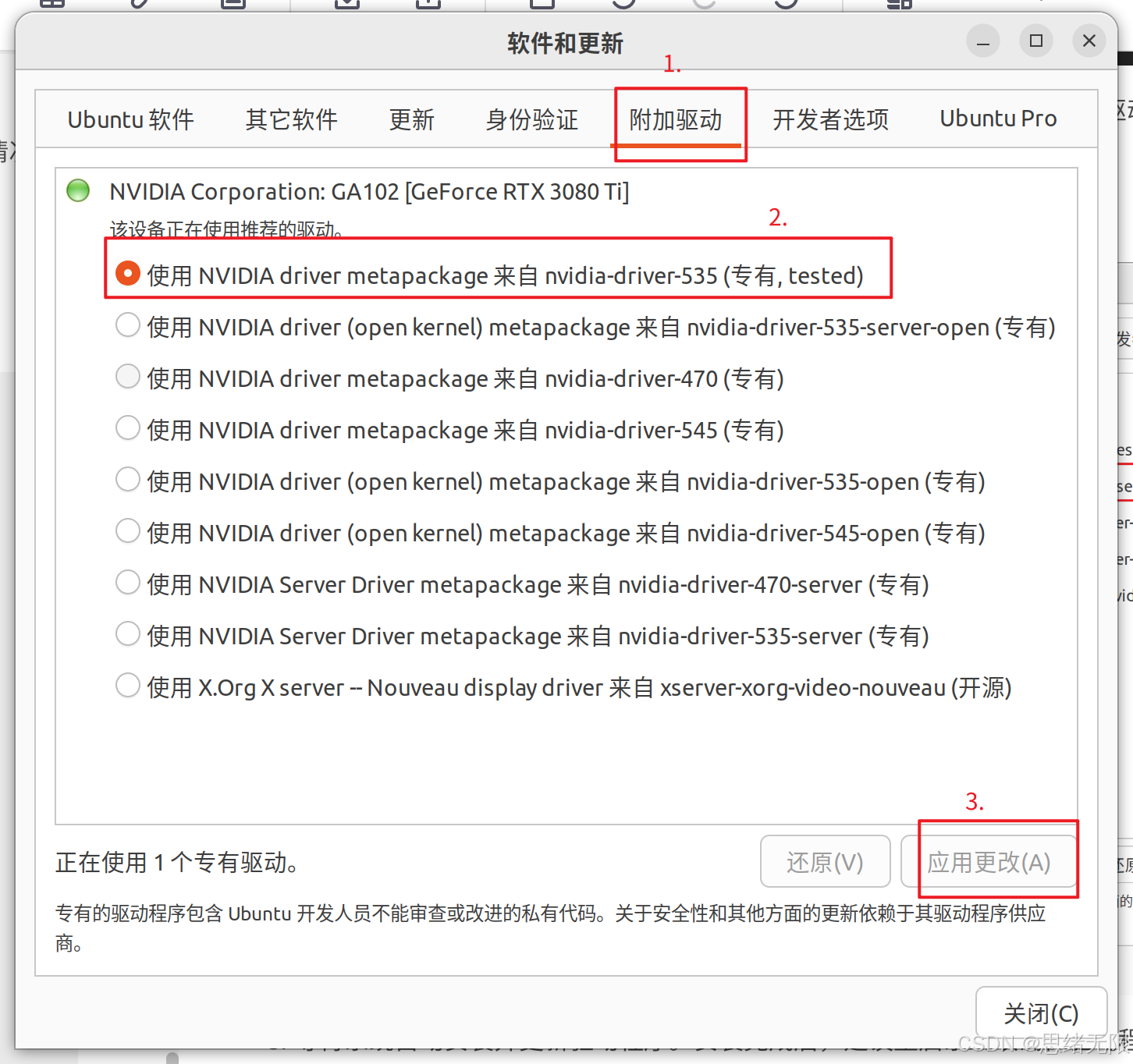
进入"软件和更新"应用后,选择"附加驱动"选项卡。系统会自动检测可用的驱动程序,并显示在列表中。通常情况下,你会看到几个可供选择的 NVIDIA 驱动版本。
选择
nvidia-driver-535-server,这里你的驱动号可能不太一样,但类似选择nvidia-diriver-xxx(不是带server后缀的),然后点击"应用更改"。
- 等待系统自动安装并更新驱动程序。安装完成后,重启系统以确保驱动程序生效。
3.3 验证驱动安装
无论是用的3.1还是3.2的方法,都需重启电脑。系统重启后,打开终端并输入以下命令检查 NVIDIA 驱动程序是否正确安装:
bash
nvidia-smi如果驱动安装成功,你会看到类似如下的输出,显示 GPU 的详细信息,包括型号、驱动版本等:
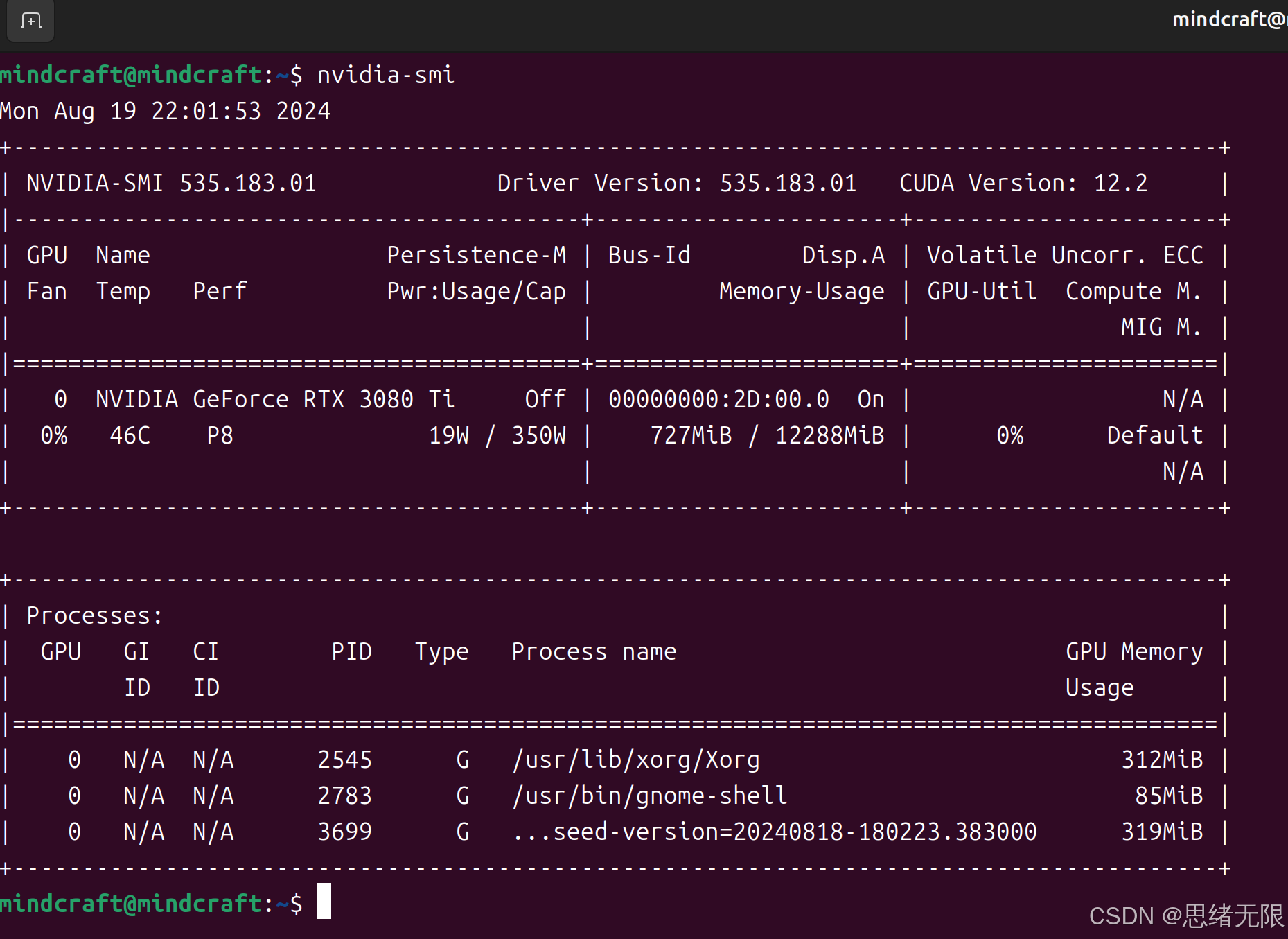
注意:请记住上面的CUDA Version ,我这里是12.2,后面我们安装的CUDA Toolkit需要保持一致。通过以上步骤,你的 NVIDIA 驱动程序应该已经正确安装,并准备好用于深度学习环境。
4. 安装 CUDA Toolkit
CUDA Toolkit 是 NVIDIA 提供的并行计算平台和编程模型,能够让开发者充分利用 GPU 进行高效计算。在安装 CUDA Toolkit 之前,确保已经正确安装了 NVIDIA 驱动程序。以下是详细的安装步骤。
4.1 下载并安装 CUDA Toolkit
首先,访问 NVIDIA CUDA 下载页面 并选择以下选项:
- 操作系统:Linux
- 架构:x86_64
- 发行版:Ubuntu
- 版本:选择与 Ubuntu 22.04 最接近的版本
- 安装方式:deb (local)
按照网站上的提示逐步选择适合你自己电脑的选项。值得注意的是,虽然 CUDA 有最新版本,但为了确保与深度学习框架的兼容性,建议使用与目标框架兼容的版本。在本文中,我们选择安装 CUDA 12.2。
当进入下载页面后通常是CUDA的当前最新版本,为了保证后续的深度学习环境的库的兼容性,这里安装早前版本的CUDA,如下图所示。

我这里选择12.2的版本,你注意看好自己的版本。如下图所示:
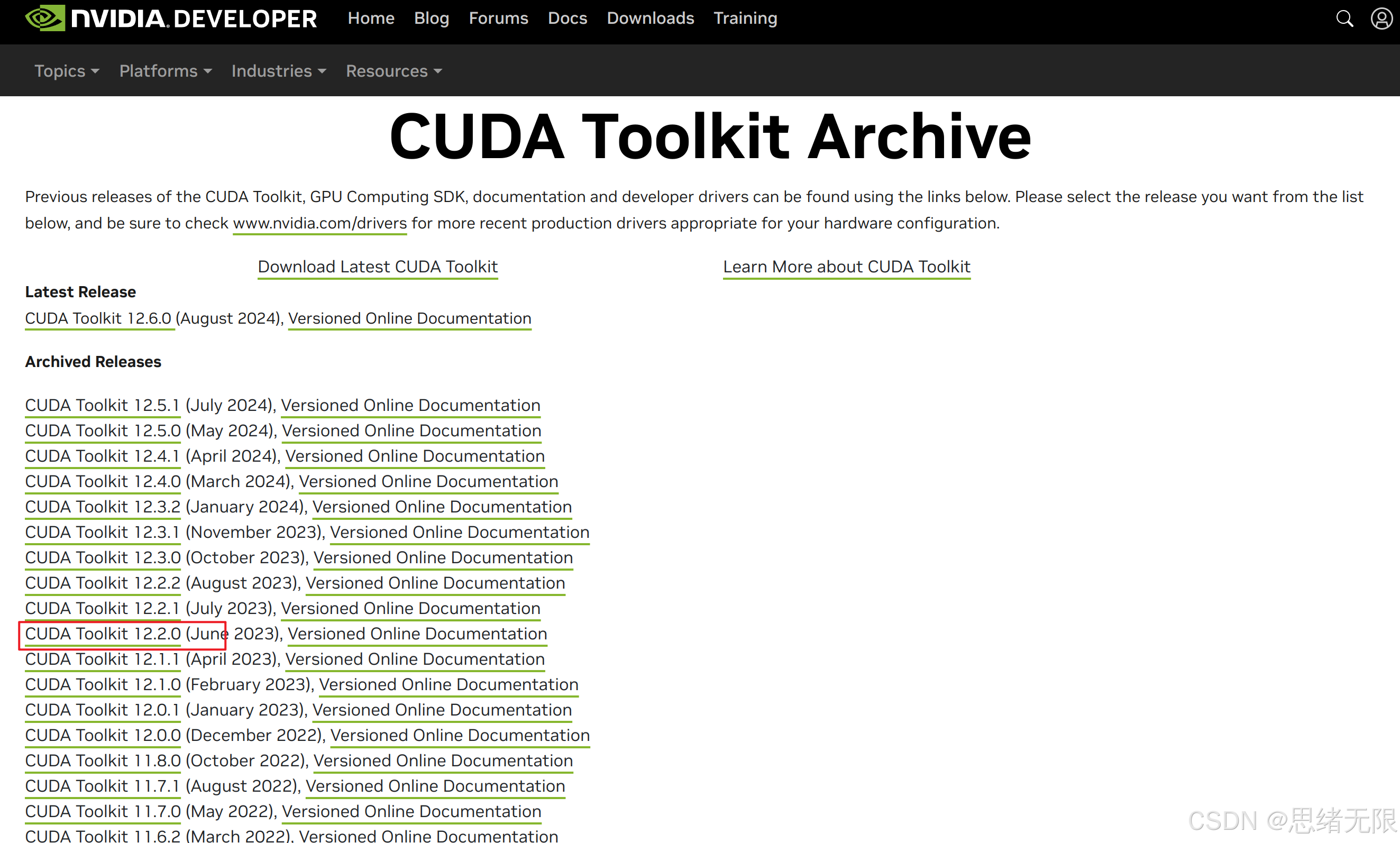
这里按照操作系统的版本选择如下:

选择以上选项后,你会看到一系列安装命令。依次运行以下命令来下载和安装 CUDA:
bash
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda-repo-ubuntu2204-12-2-local_12.2.0-535.54.03-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-2-local_12.2.0-535.54.03-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-2-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda每个命令的具体功能如下:
- 下载并安装 CUDA 仓库的配置文件:这有助于确保从正确的仓库下载 CUDA 相关的软件包。
- 下载安装包并安装:下载并安装 CUDA 的本地包,确保 CUDA 版本与系统兼容。
- 更新系统的软件包列表:确保最新的 CUDA 软件包能够被系统识别并安装。
上面的命令就是从 NVIDIA CUDA 下载页面 上复制出来的,你需要使用的是选定选项后官网给出的命令,如下图所示:
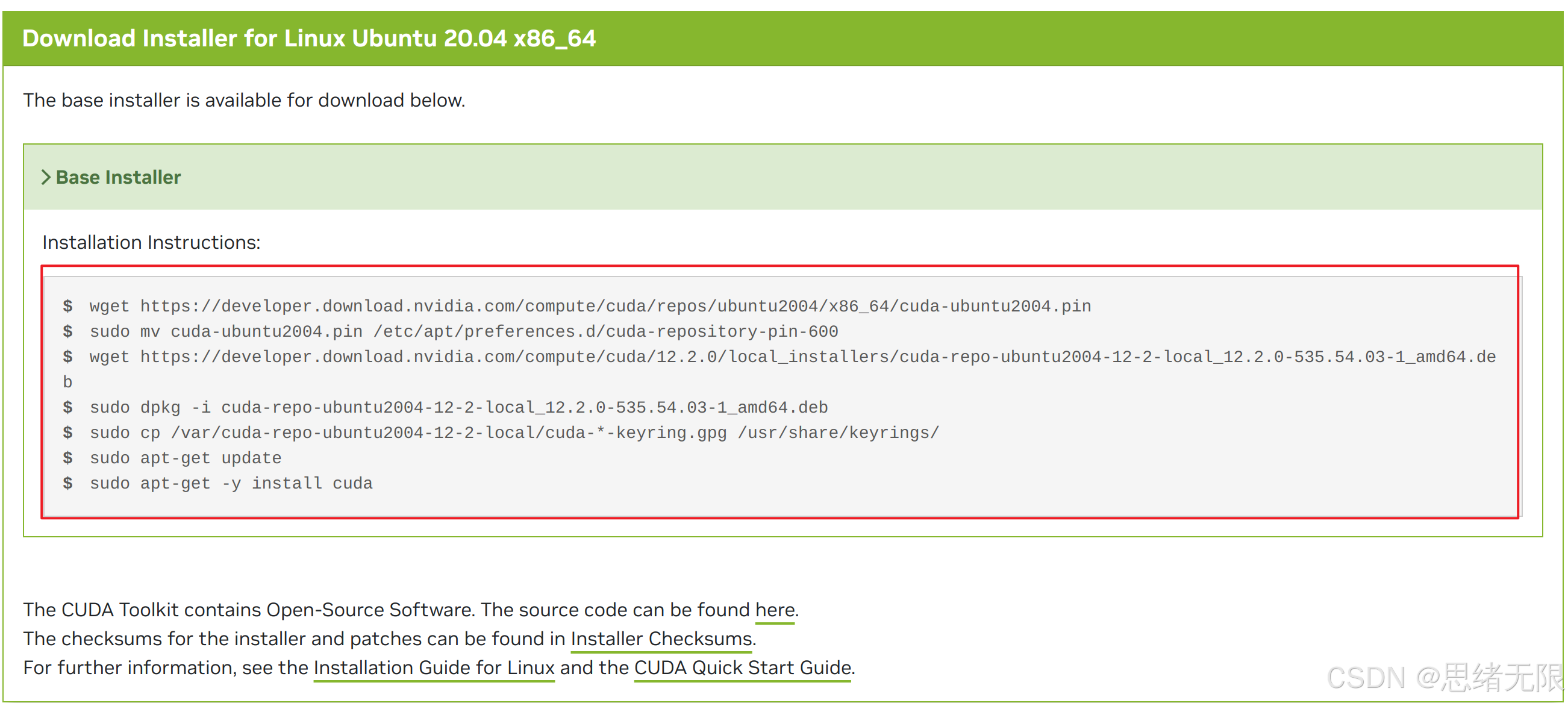
逐条复制官网上的命令(注意:下面的步骤你应该跟我一样逐条复制官网上的命令执行,因为版本如果不同,命令有些差别),这里我执行以上命令的效果如下:
-
下载 CUDA 配置文件:
bashwget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
-
移动配置文件到指定目录:
bashsudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
-
下载 CUDA 安装包:
bashwget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda-repo-ubuntu2204-12-2-local_12.2.0-535.54.03-1_amd64.deb
-
安装下载的 CUDA 包:
bashsudo dpkg -i cuda-repo-ubuntu2204-12-2-local_12.2.0-535.54.03-1_amd64.deb
-
复制 GPG 密钥到系统的受信任密钥列表中:
bashsudo cp /var/cuda-repo-ubuntu2204-12-2-local/cuda-*-keyring.gpg /usr/share/keyrings/
-
更新软件包列表并安装 CUDA:
bashsudo apt-get update sudo apt-get -y install cuda
4.2 配置环境变量
CUDA 安装完成后,需要将 CUDA 的路径添加到系统的环境变量中。这一步可以通过修改 .bashrc 文件来实现:
bash
echo 'export PATH=/usr/local/cuda-12.2/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc这些命令会将 CUDA 的二进制文件路径和库路径添加到系统的 PATH 和 LD_LIBRARY_PATH 中,并立即生效。

4.3 验证 CUDA 安装
要验证 CUDA 是否正确安装,可以使用以下命令检查 CUDA 的版本信息:
bash
nvcc -V如果 CUDA 安装成功,你将看到类似如下的输出,显示 CUDA 的版本号和其他详细信息:
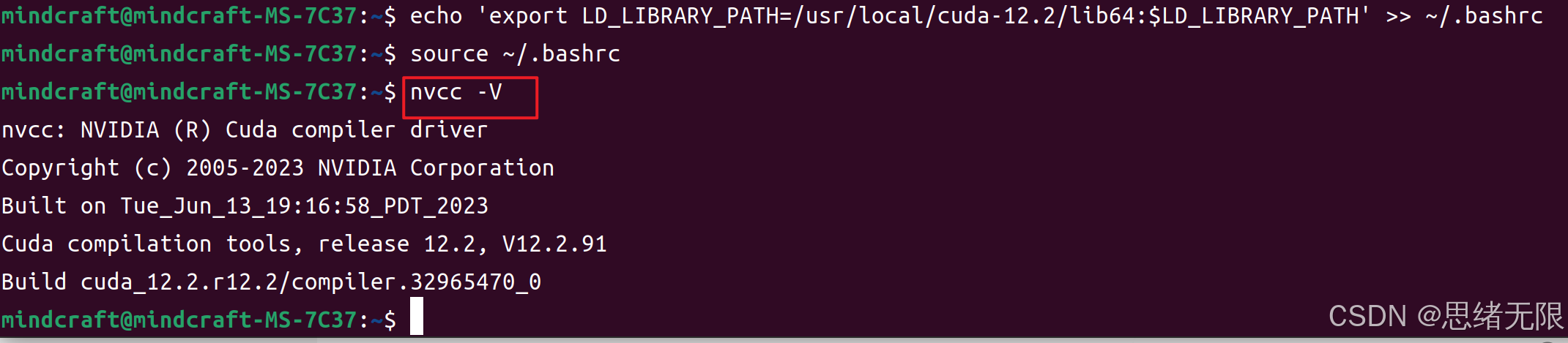
到此为止,你已经成功安装了 CUDA Toolkit 并将其配置为系统环境的一部分。接下来,我们将继续安装 cuDNN 以完成深度学习环境的配置。
5. 安装 cuDNN
cuDNN(CUDA Deep Neural Network library)是一个用于加速深度学习框架(如 TensorFlow 和 PyTorch)在 GPU 上运行的高性能库。安装 cuDNN 是深度学习环境搭建的重要一步。以下是安装和配置 cuDNN 的详细步骤。
5.1 下载 cuDNN
首先,访问 NVIDIA cuDNN 下载页面 并选择适合你 CUDA 版本的 cuDNN 下载。请注意,你需要登录 NVIDIA 开发者账户才能下载 cuDNN。
-
访问 cuDNN 下载页面:进入 cuDNN 下载页面,点击"Download cuDNN",如下图所示:

-
选择合适的 cuDNN 版本 :进入下载页面后,你通常会看到当前最新版本的 cuDNN。为了保证与深度学习框架的兼容性,建议选择与已安装的 CUDA 版本相匹配的 cuDNN 版本。点击页面右下角的"Archived cuDNN Releases",以选择一个稍早版本的 cuDNN。

-
选择具体的 cuDNN 版本:在存档版本页面中,选择适合你 CUDA 版本的 cuDNN 版本。在本例中,我们选择的是与 CUDA 12.2 兼容的 cuDNN 8.6.0 版本。

-
下载 Ubuntu 版本的 cuDNN :根据你使用的 Ubuntu 版本下载合适的 cuDNN 包。在本例中,我们选择了适用于 Ubuntu 22.04 的 cuDNN 安装包,"for CUDA 11.x"表示用于CUDA11的版本,这里也不建议用太新的。

在这个页面,点击"Download cuDNN"按钮开始下载。需要登录你的 NVIDIA 账户,如果还没有账户,可以点击注册。

5.2 安装 cuDNN
下载完成后,使用以下步骤安装 cuDNN。
注意 :找到你下载的文件位置(有可能在"下载"文件夹),我这里是在根目录,如下,可以右击选择"在终端打开",这时终端就会打开到这个文件所在的位置,方便我们后面执行安装。
-
安装
.deb文件 :使用dpkg命令安装下载的 cuDNN.deb文件。首先,进入下载文件所在的目录,然后运行以下命令(注意看你的文件名称修改,不要盲目复制):bashsudo dpkg -i cudnn-local-repo-ubuntu2204-8.6.0.163_1.0-1_amd64.deb安装过程可能会输出以下内容:

-
添加 GPG 密钥 :安装
.deb文件后,接下来需要将 GPG 密钥添加到系统的受信任密钥列表中。这一步可以通过以下命令完成(注意看你的命令行提示的文件名称,不要盲目复制):bashsudo cp /var/cudnn-local-repo-ubuntu2204-8.6.0.163/cudnn-local-FAED14DD-keyring.gpg /usr/share/keyrings/执行这条命令后,你会看到以下输出:

-
更新并安装 cuDNN 包:更新你的包列表并安装 cuDNN 包:
bashsudo apt-get update sudo apt-get install libcudnn8 libcudnn8-dev libcudnn8-samples首先输入第一条的更新,如下:

然后输入第二条,系统会下载并安装必要的 cuDNN 包,输出类似以下内容:

5.3 验证 cuDNN 安装
安装完成后,你可以通过以下步骤来验证 cuDNN 是否安装正确。
-
检查 cuDNN 版本:在终端中输入以下命令,检查 cuDNN 的版本信息:
bashcat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2这条命令将会输出 cuDNN 的主版本号、次版本号和补丁版本号,如下所示:

如果看到类似的输出,并且版本号与预期的版本号相符,说明 cuDNN 已经成功安装并且配置正确。具体含义如下:
CUDNN_MAJOR表示 cuDNN 的主版本号(例如 8)。CUDNN_MINOR表示 cuDNN 的次版本号(例如 6)。CUDNN_PATCHLEVEL表示 cuDNN 的补丁版本号(例如 0)。
5.4 验证 CUDA 和 cuDNN 的安装
总结一下,为了确保 CUDA 和 cuDNN 已经正确安装,你可以分别检查它们的版本信息。
-
检查 CUDA 版本:
bashnvcc -V这条命令会显示 CUDA 的版本号和相关信息。
-
再次检查 cuDNN 版本:
bashcat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2这将再次验证 cuDNN 的安装是否正确。
到此,CUDA 和 cuDNN 已经成功安装,并且系统已经为深度学习任务做好了准备。
6. 安装 Python 和深度学习框架
在安装完 NVIDIA 驱动、CUDA 和 cuDNN 后,接下来就是安装 Python 及相关的深度学习框架,如 TensorFlow 和 PyTorch。我们推荐使用 Anaconda 或 Miniconda 来管理 Python 环境,这样可以有效避免环境冲突,并简化包管理。以下是详细步骤。

6.1 安装 Miniconda
Miniconda 是一个轻量级的 Anaconda 发行版,包含 Python 和 Conda 包管理工具。通过它,你可以很方便地创建和管理独立的 Python 环境。以下是安装步骤:
-
下载 Miniconda 安装脚本:
首先,从 Miniconda 的官方网站下载安装脚本。你可以使用
wget命令直接下载最新的 Miniconda 安装包:bashwget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh下载完成后,你会看到如下的输出:

-
验证安装脚本(可选):
为了确保下载的脚本没有被篡改,你可以验证脚本的哈希值。运行以下命令以计算 SHA-256 校验和:
bashsha256sum Miniconda3-latest-Linux-x86_64.sh这条命令会生成一个 SHA-256 哈希值。你可以将其与 Miniconda 官方网站上提供的哈希值进行比对,以确保文件的完整性。

-
运行安装脚本:
下载并验证完安装脚本后,运行以下命令来启动 Miniconda 的安装过程:
bashbash Miniconda3-latest-Linux-x86_64.sh安装脚本将引导你完成 Miniconda 的安装,界面如下:

-
通过安装过程:
执行安装脚本后,会提示你阅读许可协议。按
Enter键滚动到协议末尾,然后输入yes同意许可协议。
接着,它会询问你安装的位置。默认安装路径是你的主目录下的
~/miniconda3。你可以直接按Enter接受默认路径,或者输入自定义路径。
-
初始化 Miniconda:
安装过程结束后,系统会询问是否将 Miniconda 初始化为默认 shell 环境。建议你选择
yes,以便 Miniconda 自动配置你的环境。bashDo you wish the installer to initialize Miniconda3 by running conda init? [yes|no] [no] >>> yes
-
激活 Miniconda:
安装和初始化完成后,你可以通过以下命令激活 Miniconda 环境:
bashsource ~/.bashrc你也可以手动激活 Miniconda:
bashconda activate
-
测试安装:
为了验证 Miniconda 是否正确安装,可以使用以下命令检查 Conda 的版本:
bashconda --version你应该看到 Conda 的版本号,类似于以下输出:

6.2 创建 Python 环境
现在 Miniconda 已经成功安装并配置好,可以开始创建一个 Python 环境,并在其中安装深度学习框架。
-
创建 Python 环境:
你可以使用以下命令创建一个新的 Python 环境。例如,我们创建一个 Python 3.8 的环境并命名为
deep_learning:bashconda create -n env_rec=3.10
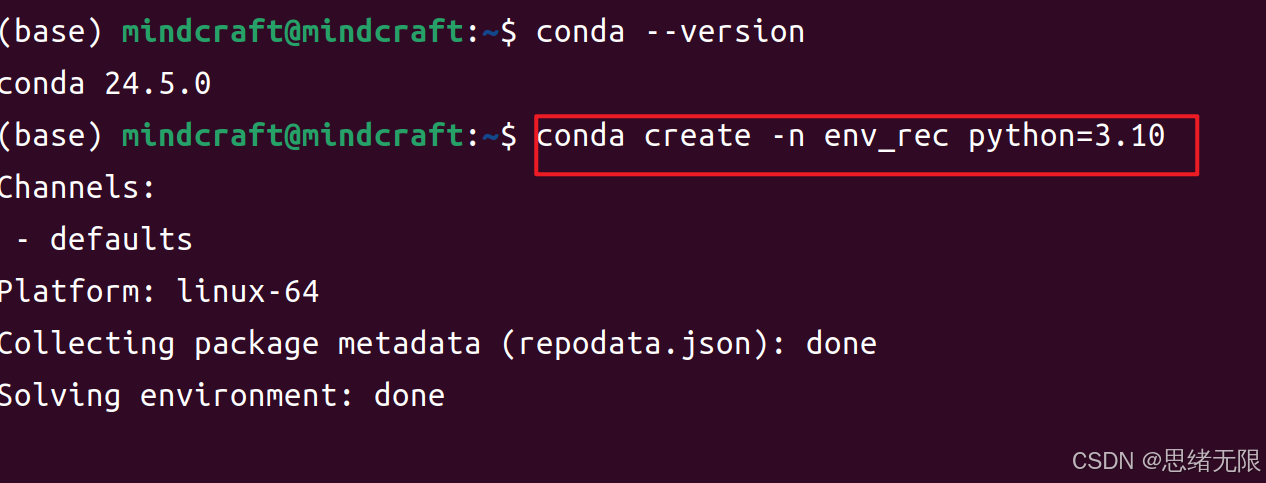
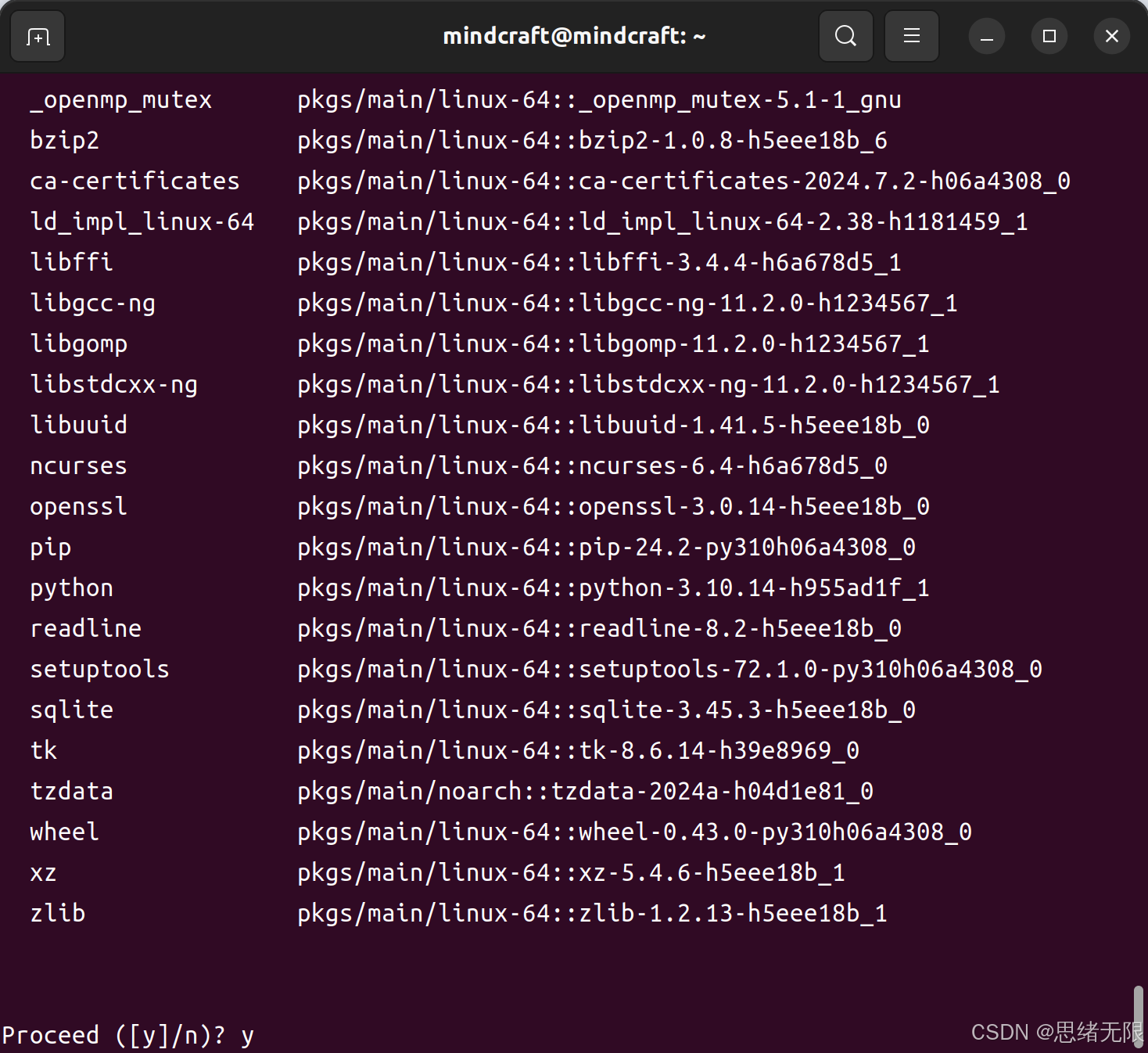
这个命令将创建一个新的虚拟环境,并安装 Python 3.8 版本。安装完成后,可以通过以下命令激活该环境:
bash
conda activate env_rec-
安装深度学习框架:
在激活环境后,可以使用
pip或conda安装你所需的深度学习框架,例如 PyTorch 或 TensorFlow。以下是安装 PyTorch 的示例:
访问 PyTorch 官网 获取安装命令,为了兼容性避免出错,可以进到早前版本,通常如下:
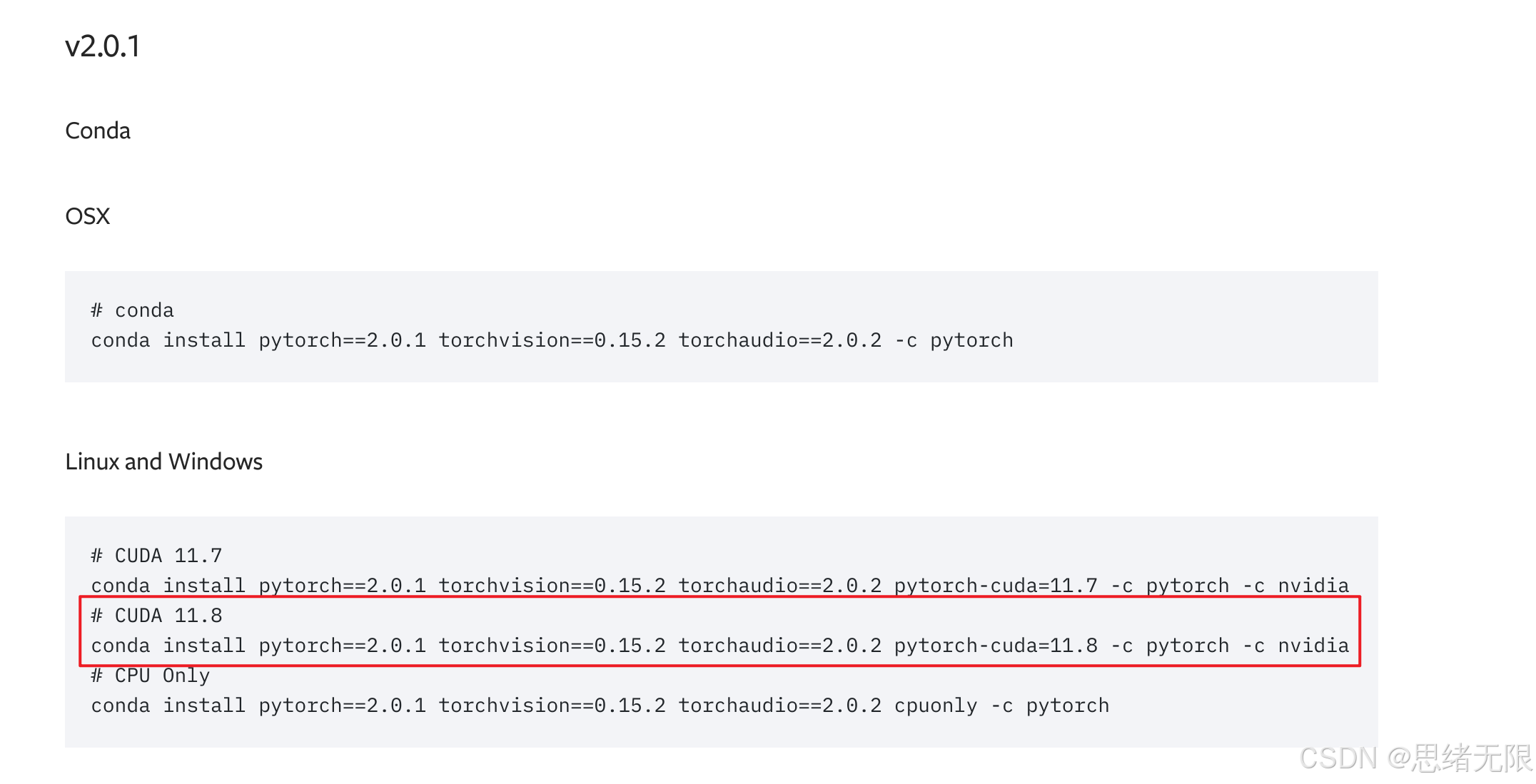
使用pip安装的命令如下:
bash
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118你也可以选择使用 Conda 安装:
bash
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
安装完成后,可以通过启动Python,在命令行输入
bash
python然后依次输入以下命令验证安装是否成功:
python
import torch
print(torch.cuda.is_available())
print(torch.cuda.device_count())这段代码将会返回你的 GPU 可用性和数量,如果返回 True 和正确的数量,说明 PyTorch 已经成功安装并能使用 GPU。
6.3 清理和退出虚拟环境
当你完成工作后,可以退出当前的虚拟环境:
bash
conda deactivate这将返回到系统的默认 Python 环境。如果你不再需要某个虚拟环境,可以使用以下命令将其删除:
bash
conda remove -n env_rec --all这会彻底删除名为 env_rec 的虚拟环境。
通过以上步骤,Ubuntu 系统已经配置好了深度学习的开发环境,包含了 GPU 支持的 CUDA、cuDNN、Miniconda 以及常用的深度学习框架。
