目录
[3.Group By优化方向:](#3.Group By优化方向:)
[1.使用索引优化group by](#1.使用索引优化group by)
前言
在之前的文章《一条SQL使用order by,引发IO问题》中,针对Using Filesort我们探讨了MySQL的排序策略与优化方向,今天,我们将介绍另一种会导致慢SQL的常见情况,即"Using temporary",本文我们将带领大家详细探讨此类问题的原因及如何优化。
**一.**场景案例
在介绍具体内容之前,我们先来看个模拟的案例:
device表(id,device_name,device_type,time)有10万条数据,device_type有50种,device_name有5万种,这两个字段均没有索引。
分别按照device_name与device_type进行group by,两类SQL施加相同的并发压力进行观察。
select device_name,count(*) as c from device group by device_name limit 0,5;
select device_type,count(*) as c from device group by device_type limit 0,5;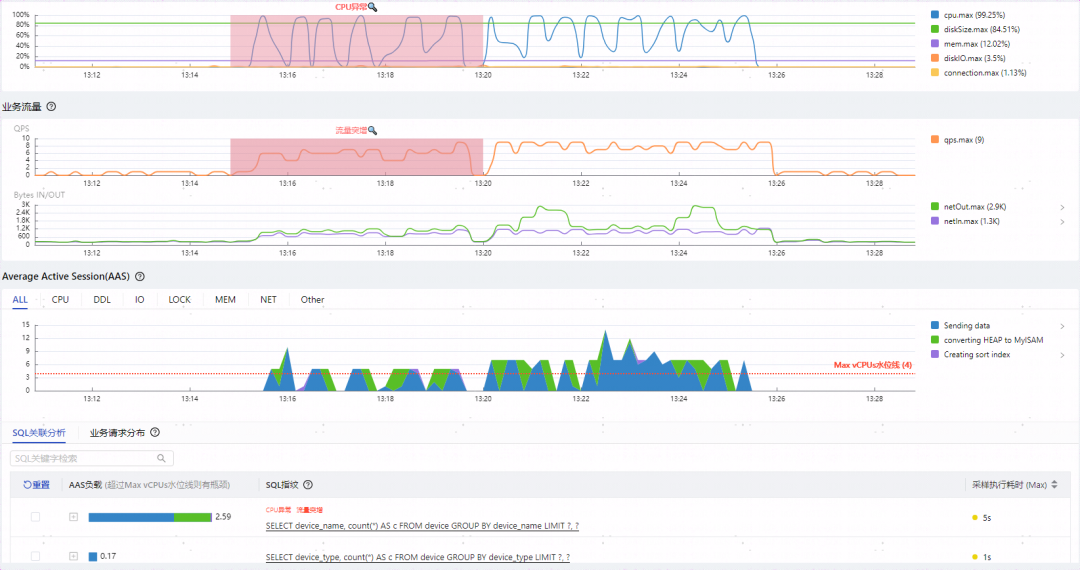

如上图所示可以观察到几个特点:
-
两类SQL总QPS虽然只有10,但是却将CPU打满,影响到整个实例的性能
-
group by device_name执行时间达到了5秒,性能堪忧
-
CPU打满的根因归到了group by device_name
-
group by device_name比group by device_type多出了绿色代表的converting HEAP to MySIAM事件(5.7开始是converting HEAP to ondisk),而且所占比重不小
-
两者执行计划相同,都是全表扫描,扫描行数相同,EXTRA字段都是Using temporary; Using filesort
看到这里有些新手同学可能会有些疑问:
-
扫描行数一样,执行计划一样,为什么group by device_name要慢很多?
-
多出的converting HEAP to MySIAM是什么意思?
-
Using temporary代表什么含义?
-
如何优化此类问题?
接下来将通过介绍Using temporary内部临时表相关机制来解答这些问题。
二、什么是内部临时表?
要了解内部临时表,需要先知道临时表,临时表是一种会话级别的数据库对象,它只存在于创建它的数据库连接活动期间。与常规的持久化表不同,临时表在连接关闭或服务器重启后自动消失。MySQL临时表从创建方式上可以分为两种:
-
外部临时表 :用户通过显式的命令执行
create temporary table创建的临时表。 -
内部临时表:与外部临时表对应,并不是用户使用显示命令创建的临时表,而是数据库优化器为了协助复杂SQL的执行而自行创建的临时表,用户可以通过explain命令,在Extra列中,看是否有Using temporary,如果有就是用了内部临时表。
三、哪些场景会使用内部临时表?
该类场景大多是需要进行聚合操作,MySQL使用临时表存储聚合数据,以下场景可能使用内部临时表,具体还需查看执行计划确认。
-
UNION
-
Group BY
-
使用TEMPTABLE算法、UNION查询、聚合的视图
-
表连接中ORDER BY的列不在驱动表中的
-
DISTINCT查询并且加上ORDER BY
-
SQL中用到SQL_SMALL_RESULT修饰时
-
复杂的派生表等
**四、**内部临时表如何存储?
有同学可能会问MySQL的内部临时表是存放在内存还是磁盘?其实都有可能,总共有三种存储方式:
1)使用内存
需要存储数据量不超过配置项tmp_table_size与max_heap_table_size的值。
2)先使用内存,再转化成磁盘文件
当内存无法满足内部临时表存储的数据量时,MySQL会将临时表从内存转到磁盘文件,如果临时数据量庞大可能会导致磁盘容量的异常占用。
下图是group by device_name的toptimizer_trace路径:
-
MySQL先创建了内存的临时表,其location为memory (heap)
-
然后发现内存不够用,又将数据转到了磁盘,location变成了disk(MyISAM/InnoDB),即通过特定引擎存储到磁盘文件表,此处默认引擎类型不同版本间有差异
-
另外通过row_limit_estimate可以知道当前内存临时表可存放的行数

3)直接使用磁盘文件
使用SQL_BIG_RESULT 的修饰时会直接使用磁盘文件;另一种是临时表字段中存在 BLOB 或 TEXT 列时也会直接放弃使用内存临时表。
那我们平时针对临时表问题,如何进行监控与评估?
监控指标主要关注两个全局status:
-
created_tmp_tables :每创建一个临时表时会累加1。
-
created_tmp_disk_tables:每一次由内存临时表转为磁盘临时表时会累加1。
**评估方式:**created_tmp_disk_tables/ created_tmp_tables 比值越大说明磁盘临时表的占比越高,性能越差。
**五、**如何优化内部临时表?
1.内部临时表通用的优化方向:
-
减少查询不必要的字段:减小临时表单行数据大小,进而提升内存临时表可存放的数据行数。
-
调大临时表内存参数:修改系统变量 tmp_table_size 和 max_heap_table_size 的值,让临时表可以使用更多的内存。此处不能盲目调整,需要评估根因SQL使用临时表实际需要的内存大小(row_length*行数),如果略微上调参数即可满足临时表数据量要求可以选择调参验证,如果需要的内存与现有配置相差较大,则需要评估服务器整体内存使用情况,避免OOM。
-
强制直接使用磁盘临时表:如果临时表的数据不可避免的会很大,可以考虑直接使用磁盘内部临时表,省掉内存临时表转换为磁盘临时表的过程。
2.Union优化方向:
考虑是否需要去重,如果不需要的话可以使用Union ALL代替Union,避免使用内部临时表。
3.Group By优化方向:
-
MySQL8.0之前GroupBy会附带排序,如果没有排序要求可以添加order by null。
-
借助索引进行Group by聚合操作,可以避免使用内部临时表。
我们再回到开始的案例看下如何优化
1.使用索引优化group by
案例SQL是一个简单的Group BY语句,最直接的优化方式是添加索引,让MySQL利用B+树索引的有序性来加速聚合计算。
alter table device add index idx_name(device_name);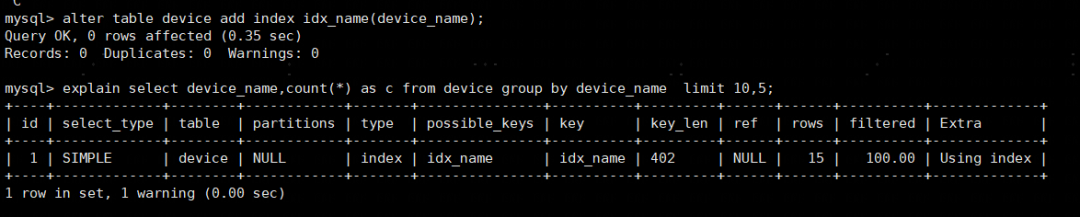
添加索引后 的执行计划
可以看到不再全表扫描,而是使用索引,同时EXTRA字段不再是Using temporary; Using filesort,SQL执行时间也回到ms级别。
 添加索引后的性能表现
添加索引后的性能表现
cpu使用率从99%降低到了10%以下,SQL执行时间变成了1秒以内,不再有converting HEAP to MySIAM/desk 事件。
2.优化临时表内存配置参数****
并不是所有场景都能很好的使用索引,有些同学会关注不使用索引的情况下如何优化参数,我们依然拿开始的案例来分析参数调优。

我们回顾下上面慢SQL的optimizer_trace,MySQL默认tmp_table_size和 max_heap_table_size是的16MB,从打印的trace可知临时表每行411字节共能存放40820行数据;而前面提到device表里device_name的种类是5万种,如果全用内存的话需要411*50000≈19.6MB。
那我们将临时表内存配置参数调整到20M再看下效果:

调大临时表参数后的optimizer_trace
可以发现调整后针对group by device_name语句可以存放51025条数据,不再需要磁盘临时表。
我们来观察下相同压力调整参数后的效果:cpu使用率从99%降低到了25%以下,SQL执行时间变成了1秒以内,不再有converting HEAP to MySIAM/desk 事件,性能提升效果5倍以上。
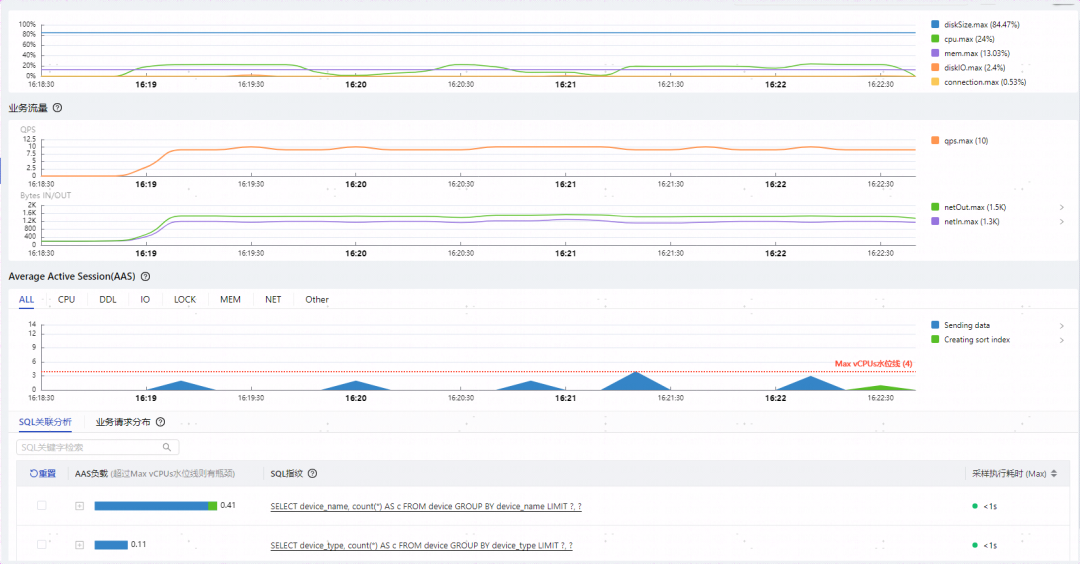
调大临时表参数后的性能表现
六、总结
内部临时表是MySQL用来辅助复杂SQL聚合计算使用的,会优先占用内存。可用内存大小受会话级参数 tmp_table_size 和 max_heap_table_size同时限制,内存不够时会将内存临时表转化为磁盘临时表,也可以通过SQL_SMALL_RESULT修饰来强制只使用磁盘临时表。
常用的优化方式有调整内存参数、大数据量时强制只使用磁盘临时表、Group By等SQL借助索引进行聚合、使用Union ALL替代UNion等。大家可以检查一下业务SQL临时表是否合理,给SQL提提速。
*************************************************************************************************************
实用小工具分享~
本文中我们使用的性能诊断工具是DBdoctor,有SQL性能审核、实例巡检、根因诊断、锁分析等功能,目前可永久免费使用,可关注DBdoctor官网(www.dbdoctor.cn)了解更多详细信息。一键安装包下载链接如下:
https://jhktob.oss-cn-beijing.aliyuncs.com/DBdoctorV3.2.3_20240820_x86.tar.gz