什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选?
答:Bert 的模型由多层双向的Transformer编码器组成,由12层组成,768隐藏单元,12个head,总参数量110M,约1.15亿参数量。NLU(自然语言理解)任务效果很好,单卡GPU可以部署,速度快,V100GPU下1秒能处理2千条以上。
ChatGLM-6B, LLaMA-7B模型分别是60亿参数量和70亿参数量的大模型,基本可以处理所有NLP任务,效果好,但大模型部署成本高,需要大显存的GPU,并且预测速度慢,V100都需要1秒一条。
所以建议:
\1. NLU相关的任务,用BERT模型能处理的很好,如实体识别、信息抽取、文本分类,没必要上大模型;
\2. NLG任务,纯中文任务,用ChatGLM-6B,需要处理中英文任务,用 chinese-llama-plus-7b 或者 chinese-alpaca-plus-7b-hf
ChatGLM-6B与LLaMA-7B的区别?
答:ChatGLM-6B是用的GLM模型结构,prefix LM,它的attention mask部分,prefix部分的token是互相能看到,模型设计之初考虑NLU任务和NLG任务。
GLM 模型结构:
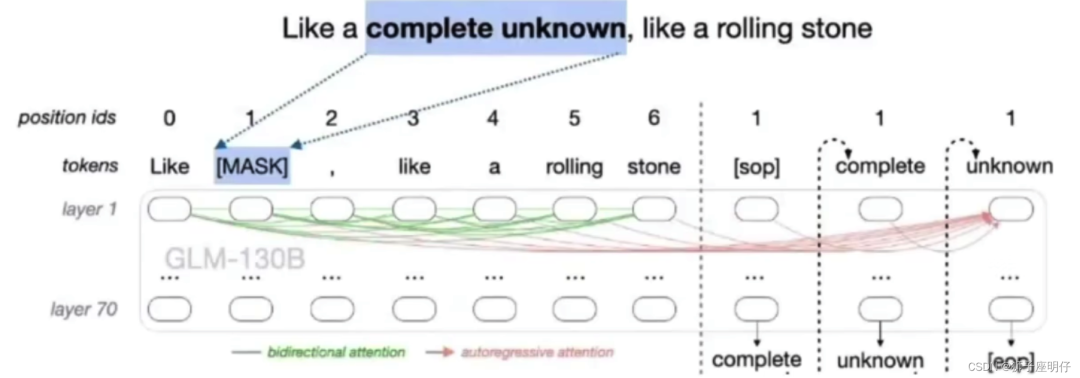
LLaMA-7B是GPT模型结构,causal LM,它的attention mask部分,只有后面的token能看到前面的token,单向的从左到右,decoder only。
当前的主流大模型,除了T5是双向结构,GLM是prefix LM, 其他的全部是causal LM。
指令微调的作用?
答:有以下好处:
\1. 对齐人类意图,能够理解自然语言对话(更有人情味)
\2. 经过微调(fine-tuned),定制版的GPT-3在不同应用中的提升非常明显。OpenAI表示,它可以让不同应用的准确度能直接从83%提升到95%、错误率可降低50%。解小学数学题目的正确率也能提高2-4倍。(更准)
\3. 踩在巨人的肩膀上、直接在1750亿参数的大模型上微调,不少研发人员都可以不用再重头训练自己的AI模型了。(更高效)
关于指令微调的作用理解,补充一下下面的情形就理解了。
我们有个大模型训练好了,能力也很强,但是有个问题,模型不一定知道人类想干什么。举个例子:
假如我们问 GPT 一个问题: 世界上最高的山是哪座山?我
们想要的回答是: 喜马拉雅山。
但是预训练数据集中的数据可能是: "世界上最高的山是哪座山? 哪位小朋友知道呢, 告诉老师有小红花哦"
所以 GPT 很可能回复 "哪位小朋友知道呢, 告诉老师有小红花哦",因为预训练阶段就是要求 GPT 去预测下一个词(next-word prediction)的任务。这时候就体现了微调的必要性。
微调方法是啥?如何微调?
答:当前主流微调方法分为:Fine-tune和prompt-tune
\1. fine-tune,也叫全参微调,bert微调模型一直用的这种方法,全部参数权重参与更新以适配领域数据,效果好。
\2. prompt-tune, 包括p-tuning、lora、prompt-tuning、adaLoRA等delta tuning方法,部分模型参数参与微调,训练快,显存占用少,效果可能跟FT(fine-tune)比会稍有效果损失,但一般效果能打平。
链家在BELLE的技术报告《A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model》中实验显示:FT效果稍好于LoRA。
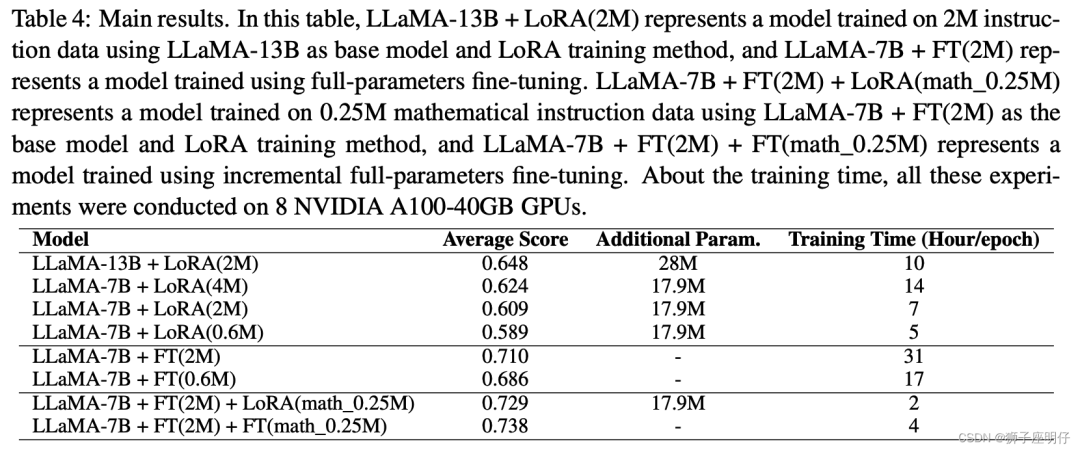
peft的论文《ADAPTIVE BUDGET ALLOCATION FOR PARAMETER- EFFICIENT FINE-TUNING》显示的结果:AdaLoRA效果稍好于FT。
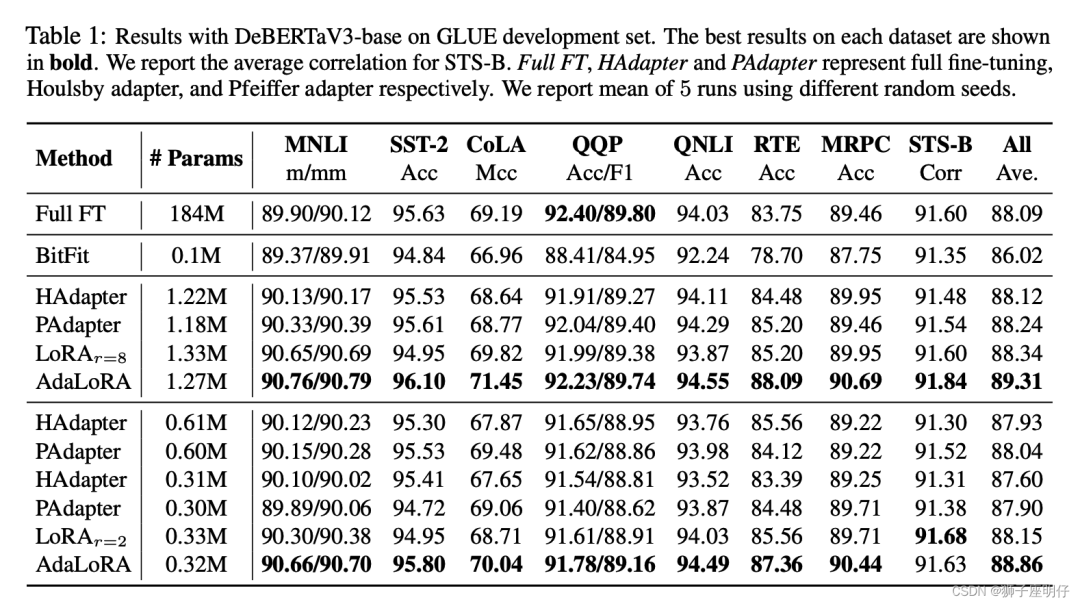
关于lora微调多补充几点:
\1. 基础模型的选择对基于LoRA微调的有效性有显著影响。
\2. 训练集越多效果越好
\3. LoRA微调的方法在模型参数越大时体现的优势越明显
此结论参考技术报告《A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model》。
LoRA微调方法为啥能加速训练?
答:有如下几个原因:
\1. 只更新了部分参数:比如LoRA原论文就选择只更新Self Attention的参数,实际使用时我们还可以选择只更新部分层的参数;
\2. 减少了通信时间:由于更新的参数量变少了,所以(尤其是多卡训练时)要传输的数据量也变少了,从而减少了传输时间;
\3. 采用了各种低精度加速技术,如FP16、FP8或者INT8量化等。
这三部分原因确实能加快训练速度,然而它们并不是LoRA所独有的,事实上几乎都有参数高效方法都具有这些特点。LoRA的优点是它的低秩分解很直观,在不少场景下跟全量微调的效果一致,以及在预测阶段不增加推理成本。
如何训练自己的大模型?
答:如果我现在做一个sota的中文GPT大模型,会分2步走:1. 基于中文文本数据在LLaMA-65B上二次预训练; 2. 加CoT和instruction数据, 用FT + LoRA SFT。
提炼下方法,一般分为两个阶段训练:
第一阶段:扩充领域词表,比如金融领域词表,在海量领域文档数据上二次预训练LLaMA模型;
第二阶段:构造指令微调数据集,在第一阶段的预训练模型基础上做指令精调。还可以把指令微调数据集拼起来成文档格式放第一阶段里面增量预训练,让模型先理解下游任务信息。
当然,有低成本方案,因为我们有LoRA利器,第一阶段和第二阶段都可以用LoRA训练,如果不用LoRA,就全参微调,大概7B模型需要8卡A100,用了LoRA后,只需要单卡3090就可以了。
第一阶段数据格式:
[
{
"content":"中华人民共和国最高人民法院 驳 回 申 诉 通 知 书(2022)最高法刑申122号 袁某银、袁某财:你们因原审被告人袁德银故意伤害一案,对江苏省南京市溧水区人民法院(2014)溧刑初字第268号刑事判决、南京市中级人民法院(2015)宁刑终字第433号刑事裁定不服,以被害人朱宽荣住院期间的CT(136678号)报告并未显示其左侧4、5、6、7、8肋骨骨折,出院记录及137470号、143006号CT报告均系伪造,江苏省高级人民法院(2019)苏刑申172号驳回申诉通知书对137470号CT报告的形成时间认定错误为由,向本院提出申诉,请求撤销原判,依法重新审理本案。本院依法组成合议庭认真审查后认为,原审认定原审被告人袁德银因邻里纠纷,殴打被害人朱宽荣致其左胸多发肋骨骨折,构成轻伤二级,其行为构成故意伤害罪,并无不当。关于你们提出的原审认定被害人朱宽荣轻伤二级的证据系伪造的申诉理由。首先,根据你们提供的136678号CT报告,朱宽荣于2015年2月12日入院时经CT检查被诊断为左侧多发肋骨骨折,该份CT报告虽未明确骨折的具体位置,但与出院记录记载的"左侧多发肋骨骨折(4、5、6、7、8)"并不矛盾。根据《人体损伤程度鉴定标准》的规定,肋骨骨折2处以上即构成轻伤二级,故鉴定意见认定朱宽荣的损伤构成轻伤二级并无不当。其次,你们主张出院记录、137470号和143006号CT报告系伪造,但并未提供证据证实。即使排除这两份CT报告,也不影响对本案事实的认定。再次,我院对申诉进行复查的对象是已经发生法律效力的判决、裁定,本案的生效裁判是(2014)溧刑初字第268号刑事判决和(2015)宁刑终字第433号刑事裁定,江苏省高级人民法院作出的驳回申诉通知书不属于我院复查的范围。综上,本院认为,你们的申诉不符合《中华人民共和国刑事诉讼法》第二百五十三条规定的应当重新审判的情形,予以驳回。望你们尊重人民法院的生效裁判,自觉服判息诉。特此通知。二〇二二年十二月十四日"
}
]第二阶段的数据样例:
[
{
"instruction": "酒驾撞人要判多久?",
"input": "",
"output": "《刑法》第一百三十三条规定:违反交通运输管理法规,因而发生重大事故,致人重伤、死广或者使公私财产遭受重大损失的,处三年以下有期徒刑或者拘役;交通运输肇事后逃逸,致人重伤的,处三年以上七年以下有期徒刑。交通肇事后逃逸致人死亡的,处七年以上有期徒刑。"
},
{
"instruction":"偷狗被派出所抓到,会怎么处理?",
"input":"",
"output":"取决于偷盗的狗的价值,可能按盗窃罪的罪名处理。如果价值达到犯罪标准,就构成盗窃罪,要承担刑事责任;如果不到犯罪标准,就是治安处罚、罚款或者拘留治安处罚这会涉嫌构成盗窃。如果不到一千元,则不会构成犯罪。如果超过一千元,则可能会是构成犯罪的。"}
]给一个法律模型训练的参考示例:
https://github.com/pengxiao-song/LaWGPT
训练中文大模型有啥经验?
答:链家技术报告《Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation》中,介绍了开源模型的训练和评估方法:
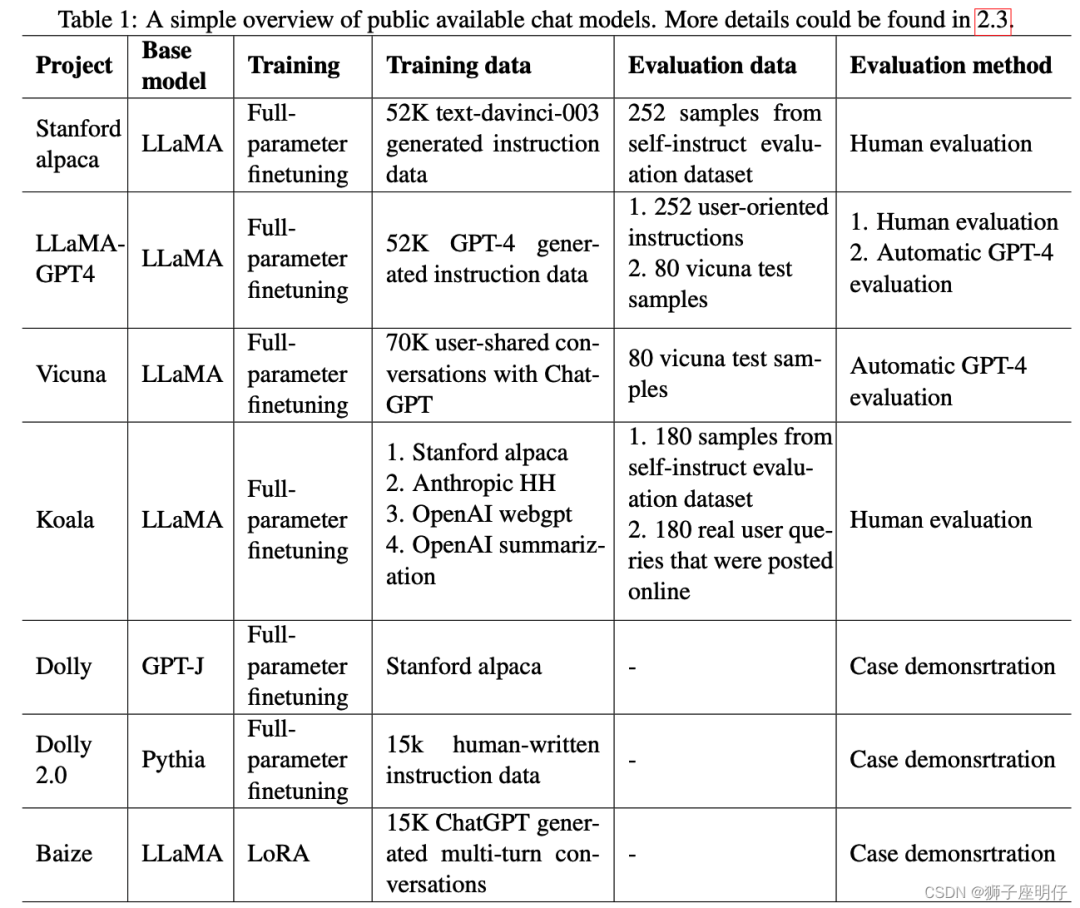
还对比了各因素的消融实验:
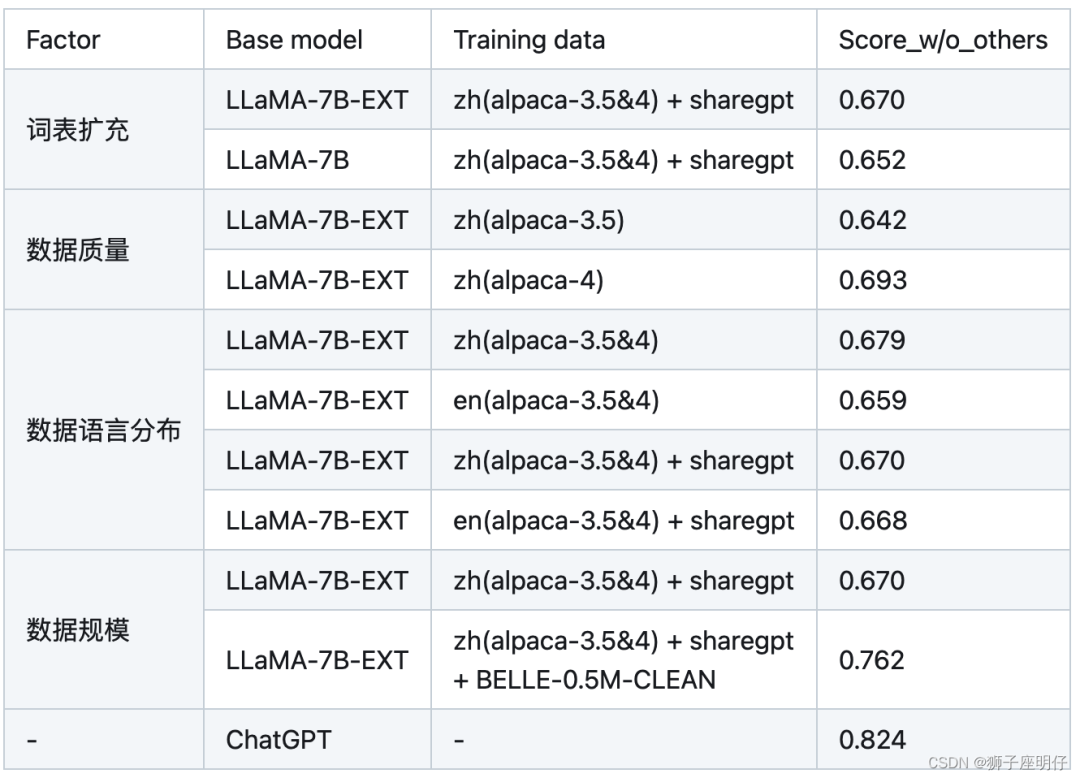
消融实验结论:
\1. 扩充中文词表后,可以增量模型对中文的理解能力,效果更好
\2. 数据质量越高越好,而且数据集质量提升可以改善模型效果
\3. 数据语言分布,加了中文的效果比不加的好
\4. 数据规模越大且质量越高,效果越好,大量高质量的微调数据集对模型效果提升最明显。解释下:数据量在训练数据量方面,数据量的增加已被证明可以显著提高性能。值得注意的是,如此巨大的改进可能部分来自belle-3.5和我们的评估数据之间的相似分布。评估数据的类别、主题和复杂性将对评估结果产生很大影响
\5. 扩充词表后的LLaMA-7B-EXT的评估表现达到了0.762/0.824=92%的水平
他们的技术报告证明中文大模型的训练是可行的,虽然与ChatGPT还有差距。这里需要指出后续RLHF也很重要,我罗列在这里,抛砖引玉。
微调需要多少条数据?
答:取决于预训练数据和微调任务的数据分布是否一致,分布一致,100条就够,分布差异大就需要多些数据,千条或者万条以上为佳。
自己的任务复杂或者下游任务行业比较冷门,如药品名称识别任务,则需要较多监督数据。还有微调大模型时,一遍是记不住的。100条的微调数据,epochs=20才能稳定拟合任务要求。
涌现能力是啥原因?
答:根据前人分析和论文总结,大致是2个猜想:
\1. 任务的评价指标不够平滑;
\2. 复杂任务 vs 子任务,这个其实好理解,比如我们假设某个任务 T 有 5 个子任务 Sub-T 构成,每个 sub-T 随着模型增长,指标从 40% 提升到 60%,但是最终任务的指标只从 1.1% 提升到了 7%,也就是说宏观上看到了涌现现象,但是子任务效果其实是平滑增长的。
如何在已有LoRA模型上继续训练?
答:我理解此问题的情形是:已有的lora模型只训练了一部分数据,要训练另一部分数据的话,是在这个lora上继续训练呢,还是跟base 模型合并后再套一层lora,或者从头开始训练一个lora?
我认为把之前的LoRA跟base model 合并后,继续训练就可以,为了保留之前的知识和能力,训练新的LoRA时,加入一些之前的训练数据是需要的。另外,每次都重头来成本高。
大模型怎么评测?
答:当前superGLUE, GLUE, 包括中文的CLUE 的benchmark都在不太合适评估大模型。可能评估推理能力、多轮对话能力是核心。
论文《C-EVAL: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models》提出了中文大语言模型评估基准:C-EVAL,有一定借鉴意义。
github链接:https://github.com/SJTU-LIT/ceval
论文:https://arxiv.org/pdf/2305.08322v1.pdf
benchmark:https://cevalbenchmark.com/static/leaderboard.html
大模型的honest原则是如何实现的?模型如何判断回答的知识是训练过的已知的知识,怎么训练这种能力?
答:大模型需要遵循的helpful,honest, harmless的原则。
可以有意构造如下的训练样本,以提升模型准守honest原则,可以算trick了:
\1. 微调时构造知识问答类训练集,给出不知道的不回答,加强honest原则;
\2. 阅读理解题,读过的要回答,没读过的不回答,不要胡说八道。
各个专业领域是否需要各自的大模型来服务?
答:是,各行各业的大模型是趋势。
大模型有推理能力吗?
答:大模型有推理能力。有下面2个方面的体现:
\1. ChatGPT拥有in-context correction的能力,即如果说错了,给出矫正,ChatGPT能"听懂"错在哪儿了,并向正确的方向修正。in-context correction要比in-context learning难了太多,描述越详细清楚,ChatGPT回答得越好。要知道,越详细的描述,在预训练的文本里越难匹配到的。
\2. 在询问ChatGPT互联网上并不存在内容的时候,能给出较好答案(如用ChatGPT学建模);ChatGPT能通过信息猜你心中的想法;你可以制定一个全新的游戏规则让ChatGPT和你玩,ChatGPT可以理解。
预训练和微调哪个阶段注入知识的?
答:预训练阶段注入知识的,微调是在特定任务训练,以使预训练模型的通用知识跟特定任务的要求结合,使模型在特定任务上表现更好。
我想让模型学习某个领域或行业的知识,是应该预训练还是应该微调?
答:可以使用预训练和微调相结合的方式,先用篇章数据进行预训练以获取广泛的知识,再用问答对数据进行微调,使模型更好的学习到特定领域的知识。
当然,GPT大模型的预训练和微调,从实现方式来讲是没有什么差别的,都是decoder only的语言模型训练并更新参数,如果样本集小,没有大量的篇章文档数据,我认为只进行微调也能注入知识的,不必太纠结预训练。而且特定领域跟预训练模型的分布差别不大,也不用二次预训练。
多轮对话任务如何微调模型?
答:跟正常的指令微调方法一样,只是组织数据的时候把历史聊天记录拼接起来,作为上下文信息喂给模型。
{"prompt": "长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "response": "用电脑能读数据流吗?水温多少", "history": []}
{"prompt": "95", "response": "上下水管温差怎么样啊?空气是不是都排干净了呢?", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"]]}
{"prompt": "是的。上下水管都好的", "response": "那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"], ["95", "上下水管温差怎么样啊?空气是不是都排干净了呢?"]]}微调后的模型出现能力劣化,灾难性遗忘是怎么回事?
答:所谓的灾难性遗忘:即学习了新的知识之后,几乎彻底遗忘掉之前习得的内容。这在微调ChatGLM-6B模型时,有同学提出来的问题,表现为原始ChatGLM-6B模型在知识问答如"失眠怎么办"的回答上是正确的,但引入特定任务(如拼写纠错CSC)数据集微调后,再让模型预测"失眠怎么办"的结果就答非所问了。
我理解ChatGLM-6B模型是走完 "预训练-SFT-RLHF" 过程训练后的模型,其SFT阶段已经有上千指令微调任务训练过,现在我们只是新增了一类指令数据,相对大模型而已,微调数据量少和微调任务类型单一,不会对其原有的能力造成大的影响,所以我认为是不会导致灾难性遗忘问题。
有几个trick方法可以改善此现象:
\1. 调整微调训练参数,微调初始学习率不要设置太高,lr=2e-5或者更小,可以避免此问题,不要大于预训练时的学习率。
\2. 微调训练集设置:应该选择多个有代表性的任务,每个任务实例数量不应太多(比如几百个)否则可能会潜在地导致过拟合问题并影响模型性能 。
\3. 应该平衡不同任务的比例,并且限制整个数据集的容量(通常几千或几万),防止较大的数据集压倒整个分布。
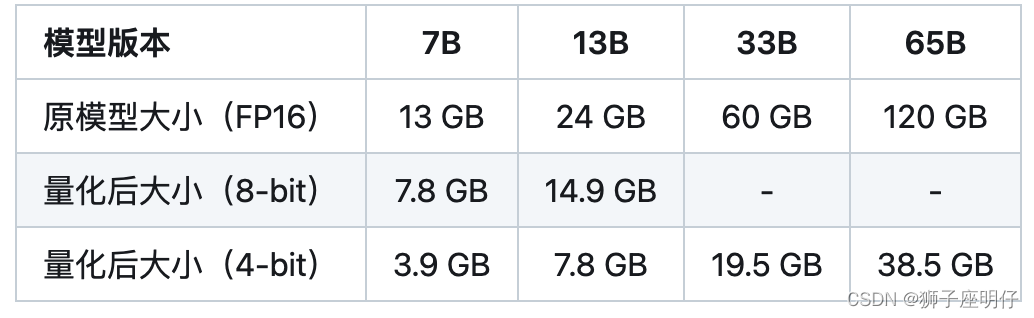
微调模型需要多大显存?
有哪些大模型的训练集?
答:预训练数据集togethercomputer/RedPajama-Data-1T「红睡衣」开源计划总共包括三部分:
\1. 高质量、大规模、高覆盖度的预训练数据集;
\2. 在预训练数据集上训练出的基础模型;
\3. 指令调优数据集和模型,比基本模型更安全、可靠。
预训练数据集RedPajama-Data-1T已开源,包括七个子集,经过预处理后得到的token数量大致可以匹配Meta在原始LLaMA论文中报告的数量,并且数据预处理相关脚本也已开源。
完整的RedPajama-Data-1T数据集需要的存储容量为压缩后3TB,解压后5TB。
CoT微调数据集:Alpaca-CoT 里面包括常用的alpaca,CoT等数据集,有中文的。
模型生成时的参数怎么设置?
答:生成模型预测调参建议:
1.建议去调整下 top_p, num_beams, repetition_renalty, temperature, do_sample=True;
\2. 数据生成有重复,调高repetition_renalty;
\3. 生成任务表达单一的,样本也不多的,可适当调低 temperature,生成的样子跟训练集的比较像;如果要复现训练集的效果,temperature=0.01即可。
以上是经验参数,具体调参根据任务而定,不是固定的。
参数解释:
top_p=0.9,
#Moderately increase the probability threshold of nucleus sampling to increase the quantity of candidate tokens and increase generation diversity.
temperature=1.0,
#The previous low temperature parameter could lead to a severe polarization in the probability distribution of generated words, which degenerates the generation strategy into greedy decoding.
do_sample=True,
#do_sample parameter is set to False by default. After setting to True, the generation methods turn into beam-search multinomial sampling decoding strategy.
no_repeat_ngram_size=6,
#Configure the probability of the next repeating n-gram to 0, to ensure that there are no n-grams appearing twice. This setting is an empirical preliminary exploration.
repetition_penalty=1.8,
#For words that have appeared before, in the subsequent prediction process, we reduce the probability of their reoccurrence by introducing the repetition_penalty parameter. This setting is an empirical preliminary exploration.ChatGPT为啥用RL,PPO的作用是啥?
答:这是个开放性问题,目前在处理讨论中。
先说明RL后模型效果是提高的:
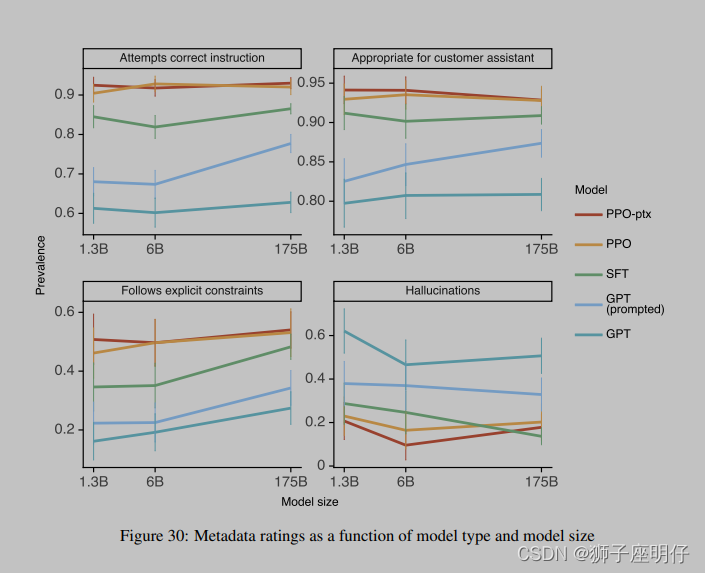
引用一下最近 Yoav 在他 gh-gist (很多干货)里面的观点,感兴趣的可以看下原文:https://gist.github.com/yoavg/6bff0fecd65950898eba1bb321cfbd81
\1. 多样性角度:RL 能提供更多样的回答,因为对于 Supervised Learning(SL),模型训练时只要稍微偏离训练样本就会受到惩罚,而实际上人类语言是会用各种不同方式表达相同意思,SL 这样就会让模型感到困惑,特别是泛化理解能力较好的模型。
\2. 负反馈角度:监督学习里只有正反馈,而 RL 可以提供负反馈信号,从形式学习理论来看,负反馈信号会更好些(说实话没看懂)。
\3. 自我知识感知角度:最有说服力的一条,首先按照现在 ChatGPT 主要应用场景,其中有一大类问题为"知识获取型",这块和 RL 训练关系比较大。
因为对于此类问题,我们希望模型能给出一个真实有信服力的答案,同时不知道地时候拒绝回答,不要鬼扯。
模型最好能根据自己内部知识来回答,也就是知道自己知道什么,和不知道什么。这就需要用 RL 来训了,因为监督学习会教模型撒谎。
为什么呢,因为 SL 中间会出现两种情况:
模型本身有相关知识,知道答案,那么训练过程中就是给答案和问题联系起来,之后也能看到类似问题给出相关知识回答,还会觉得泛化性好,这是好的情况
模型本身没有相关知识,相当于学习了之前完全不知道的知识,因为数据量比较少,可能只是单纯地去记住少量数据,那么之后遇到类似问题,模型实际上没有相关知识,但模型还是会倾向于去回答,那么就只能去胡编乱造了,这就是为什么 SL 会教模型撒谎的解释
这里也放下John Schulman在UCB的talk:https://www.youtube.com/watch?v=hhiLw5Q_UFg,感兴趣的同学可以看下。
原文链接:https://blog.csdn.net/mingzai624/article/details/130735366
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。