摘要:本文主要介绍基于源码部署 Datavines 和执行检查作业,内容主要分为以下几个部分:
- 平台介绍
- 快速部署
- 运行数据质量检查作业
Datavines 的目标是成为更好的数据可观测性领域的开源项目,为更多的用户去解决元数据管理和数据质量管理中遇到的问题。在此我们真诚欢迎更多的贡献者参与到社区建设中来,和我们一起成长,携手共建更好的社区。
https://github.com/datavane/datavines
https://github.com/datavane/datavines/issues
https://github.com/datavane/datavines/pulls
平台介绍
Datavines 是一站式开源数据可观测性平台,提供元数据管理、数据概览报告、数据质量管理,数据分布查询、数据趋势洞察等核心能力,致力于帮助用户全面地了解和掌管数据,让您做到心中有数.
快速部署
环境准备
在安装 Datavines 之前请确保你的服务器上已经安装下面软件
Git,确保git clone的顺利执行JDK,确保jdk >= 8Maven, 确保项目的顺利打包(当然你也可以在本地打包以后上传至服务器)MySQL, 确保版本>=5.7
下载代码
shell
git clone https://github.com/datavane/datavines.git
cd datavines数据库准备
Datavines 的元数据是存储在关系型数据库中,目前支持 MySQL ,下面以 MySQL 为例说明安装步骤:
- 创建数据库
datavines - 执行
script/sql/datavines-mysql.sql脚本进行数据库的初始化
项目构建
打包并解压
shell
mvn clean package -Prelease
cd datavines-dist/target
tar -zxvf datavines-1.0.0-SNAPSHOT-bin.tar.gz解压完成以后进入目录
cd datavines-1.0.0-SNAPSHOT-bin编辑配置信息
cd conf
vi application.yaml修改数据库信息
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/datavines?useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456如果你是使用 Spark 做为执行引擎,并且是提交到 yarn 上面去执行的,那么需要在 common.properties 中配置 yarn 相关的信息
-
standalone 模式
yarn.mode=standalone
yarn.application.status.address=http://%s:%s/ws/v1/cluster/apps/%s #第一个%s需要被替换成yarn的ip地址
yarn.resource.manager.http.address.port=8088 -
ha 模式
yarn.mode=ha
yarn.application.status.address=http://%s:%s/ws/v1/cluster/apps/%s
yarn.resource.manager.http.address.port=8088
yarn.resource.manager.ha.ids=192.168.0.1,192.168.0.2
启动服务
cd bin
sh datavines-daemon.sh start mysql查看日志,如果日志里面没有报错信息,并且能看到
[INFO] 2022-04-10 12:29:05.447 io.datavines.server.DatavinesServer:[61] - Started DatavinesServer in 3.97 seconds (JVM running for 4.69) 的时候,证明服务已经成功启动。
访问前端页面
在浏览器输入: 服务器IP:5600 ,就会跳转至登录界面,输入账号密码 admin/123456

运行数据质量检查作业
创建数据源
进入首页后,点击右上角 创建数据源 按钮,输入数据源的名称,然后选择数据源类型。以 MySQL 为例,输入 MySQL 的连接信息,点击 测试连接 按钮。如果成功,请单击 保存 。
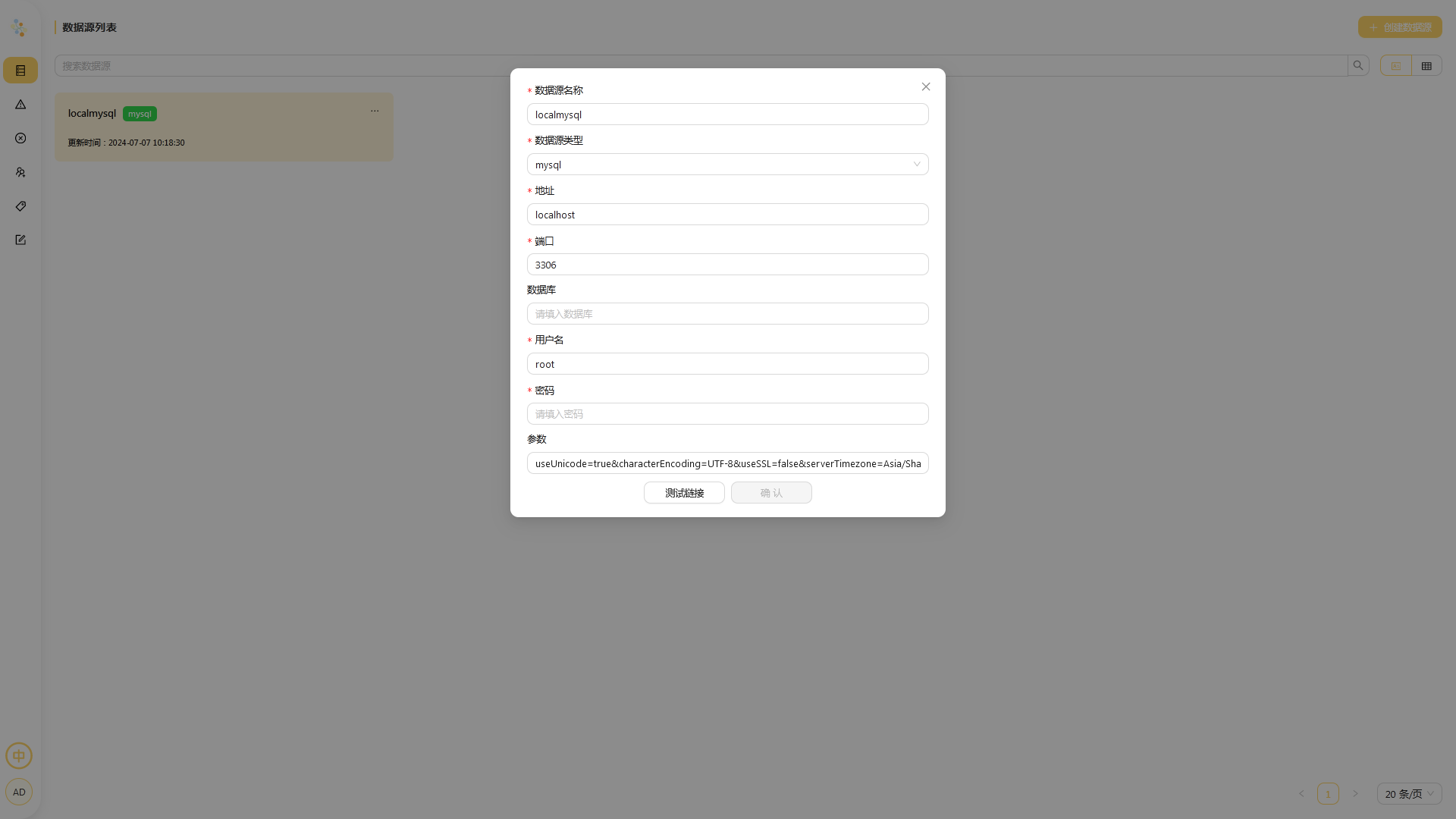
进入数据源

点击并进入数据源,找到 作业管理 页面
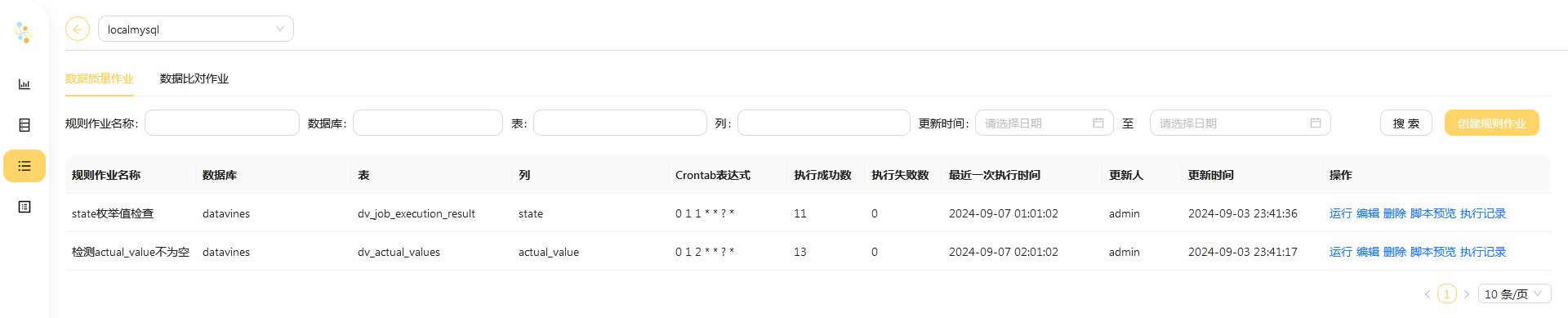
创建检查作业
-
点击
创建规则作业按钮,选择数据质量作业 -
进入规则的配置页面
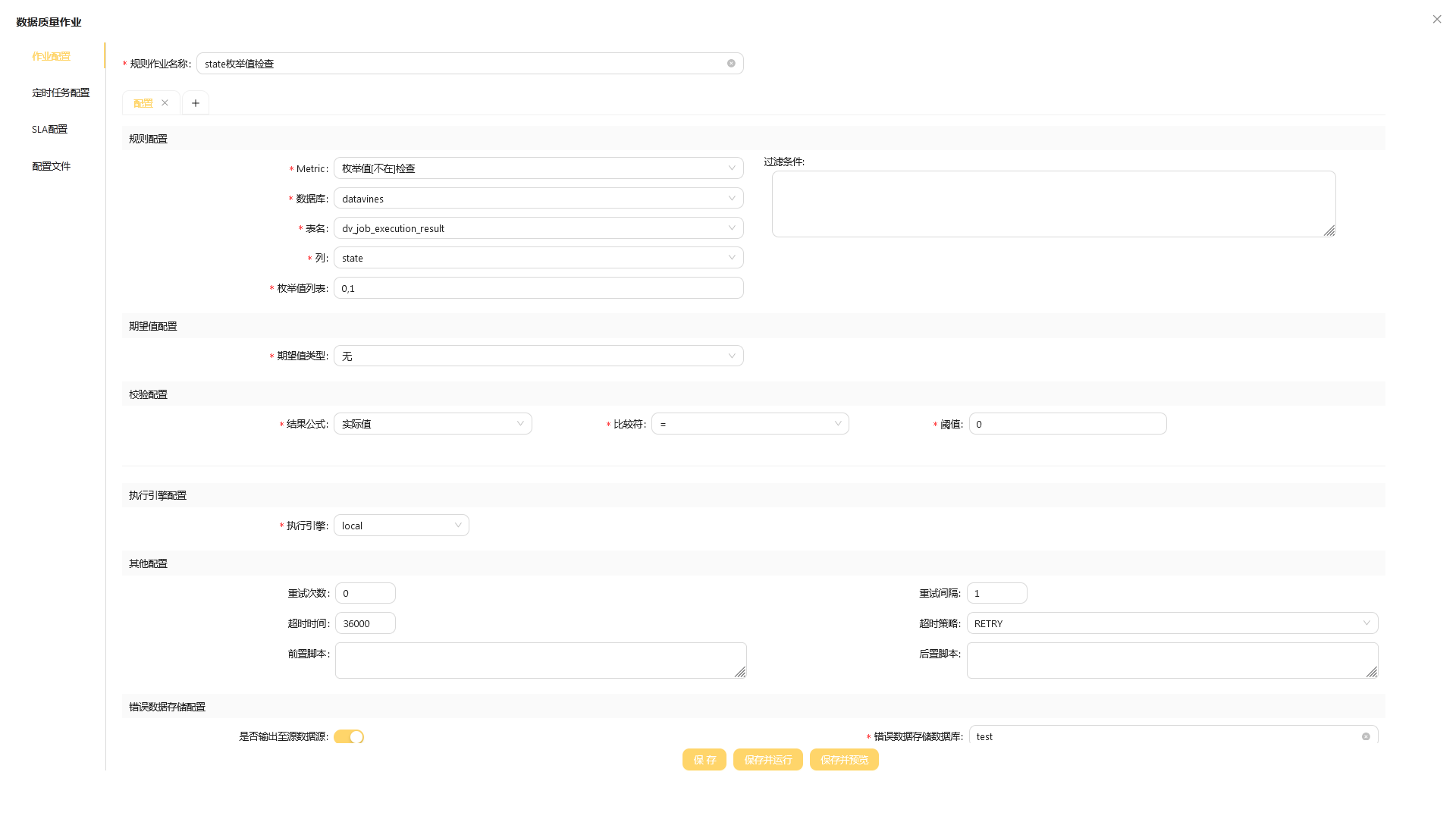
-
进行规则配置
- 选择
枚举值[不在]检查规则 - 依次选择数据库、表和列
- 输入枚举数组
[0,1]
- 选择
-
进行期望值配置
- 如果没有期望值则选择
无
- 如果没有期望值则选择
-
进行校验配置
- 选择
实际值检查公式、>比较符并输入阈值10 - 这样就构成
【实际值 > 10】公式 ,公式成立时表示检查结果为成功,否则是失败。
- 选择
-
进行错误数据配置
- 选择保存在源数据源中,填写已创建好的数据库
-
完成配置后点击
保存并运行来执行检查作业。
查看规则作业的信息
在 作业列表 找到刚刚创建并执行的检查作业。
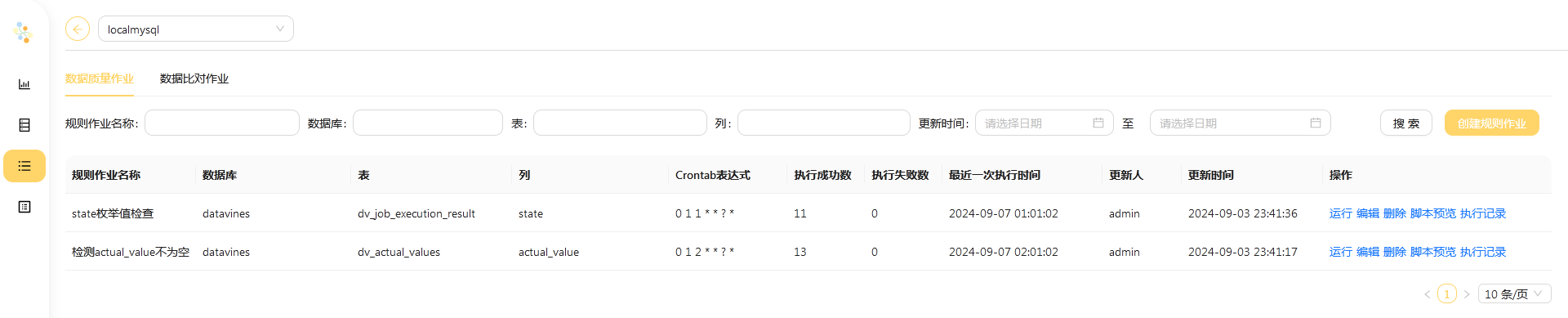
点击 执行记录 页面, 你可以看到执行历史列表。
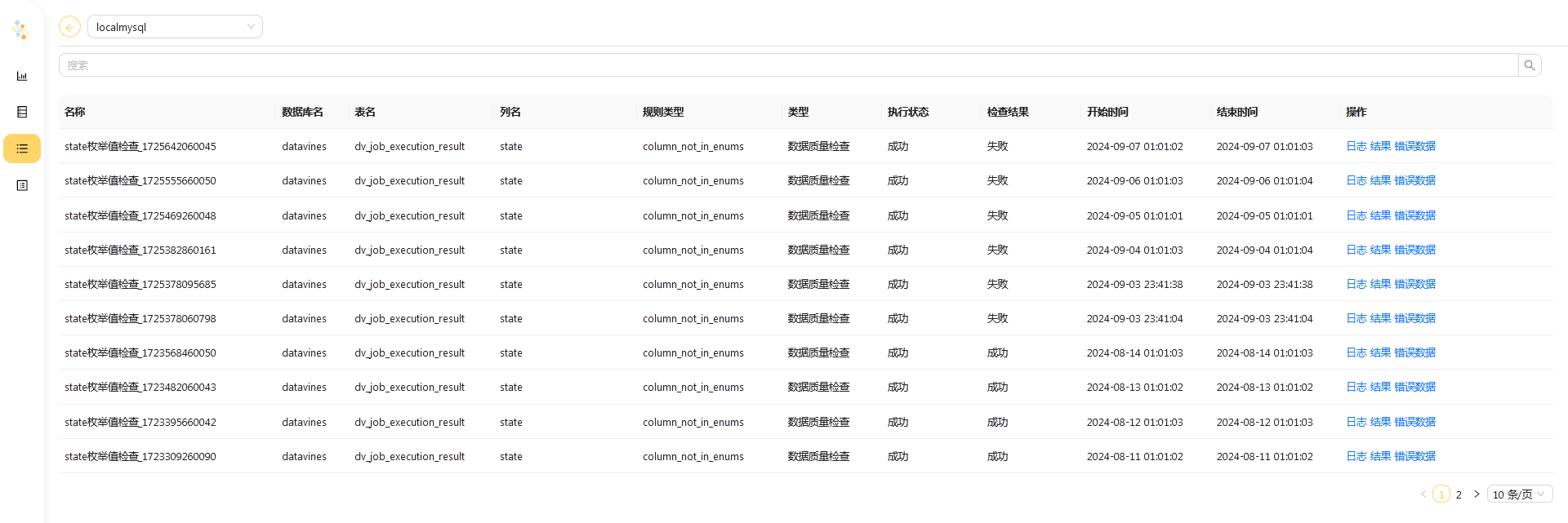
点击 日志 按钮,你可以看到规则执行的日志信息。

点击 结果 按钮,你可以看到规则执行的检查结果。

点击 错误数据 按钮,你可以看到规则执行的错误数据。
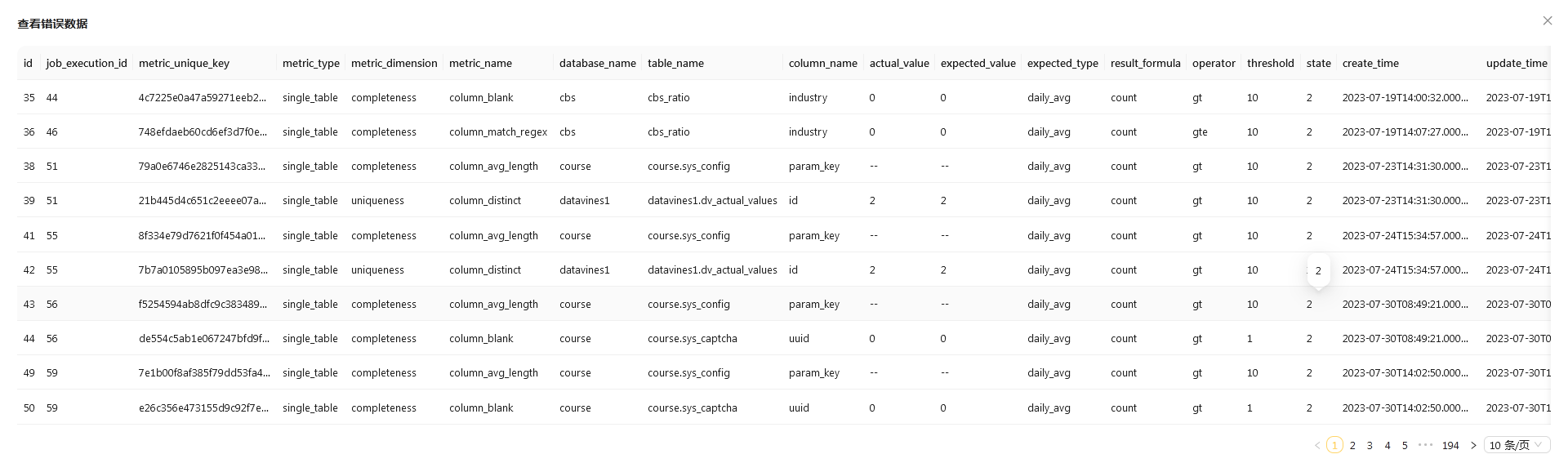
结束语
本文详细介绍了Datavines平台的部署安装到运行的整个过程,每个环节图文并茂,相信很多小伙伴都跃跃欲试了,动起来吧,更多精彩等着你来挖掘。
关于Datavane
Datavane 是一个专注于大数据领域的开源组织(社区),由一群大数据领域优秀的开源项目作者共同创建,旨在帮助开源项目作者更好的建设项目、为大众提供高质量的开源软件,宗旨是:只为做一个好软件。目前已经聚集了一批优质的开源项目,涉及到数据集成、大数据组件管理、数据质量等。
在 Datavane 社区中,所有的项目都是开源开放的,代码质量和架构设计优质的潜力项目。社区保持开放中立、协作创造、坚持精品,鼓励所有的开发者、用户和贡献者积极参与我们的社区、共同合作,创新创造,建设一个更加强大的开源社区。
Github : https://github.com/datavane