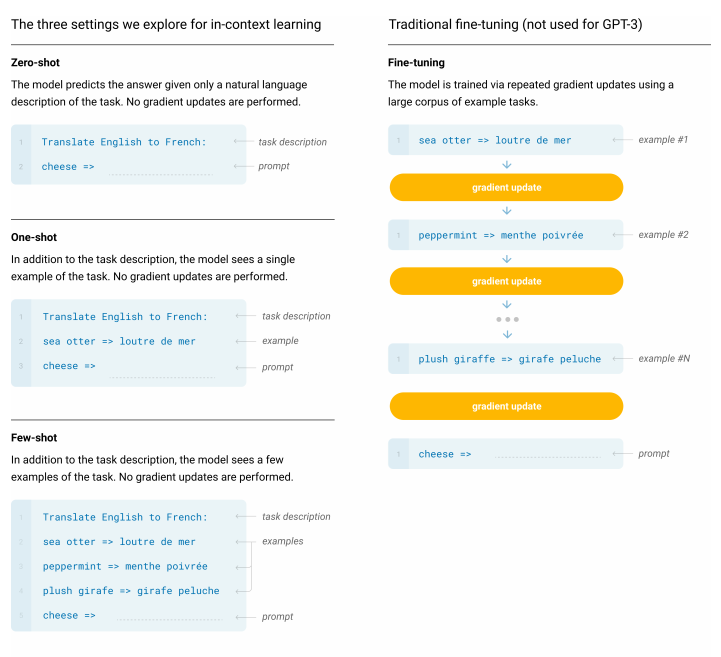
"Zero-Shot (0S) is the same as one-shot except that no demonstrations are allowed, and the model is only given a natural language instruction describing the task. This method provides maximum convenience, potential for robustness, and avoidance of spurious correlations"
"Few-Shot (FS) is the term we will use in this work to refer to the setting where the model is given a few demonstrations of the task at inference time as conditioning"
few - shot (FS)是我们在这项工作中使用的术语,指的是在推理时给模型一些任务演示作为条件反射的设置
"for a typical dataset an example has a context and a desired completionn (for example
an English sentence and the French translation), and few-shot works by giving K examples of context and completion, and then one final example of context, with the model expected to provide the completion."
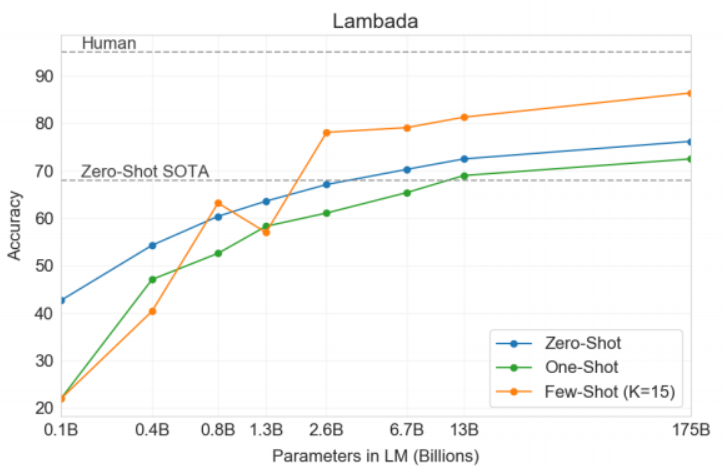
语言建模与Cloze(完形)任务:GPT-3在Penn Tree Bank(PTB)数据集上的测试表现出色。作者指出,GPT-3在传统语言建模任务上取得了显著进步,达到了新的零样本学习的最优表现(SOTA)。在LAMBADA数据集上,GPT-3的表现尤为突出,尤其是在少样本设置下,它的准确率提高了18%。
原文:
"LAMBADA is also a demonstration of the flexibility of few-shot learning as it provides a way to address a problem that classically occurs with this dataset"
"GPT-3 achieves 86.4% accuracy in the few-shot setting, an increase of over 18% from the previous state-of-the-art."
"GPT-3 achieves 64.3% accuracy on TriviaQA in the zero-shot setting, 68.0% in the one-shot setting, and 71.2% in the few-shot setting, the last of which is state-of-the-art relative to fine-tuned models operating in the same closed-book setting."
"Zero-shot GPT-3, which only receives on a natural language description of the task, still underperforms recent unsupervised NMT results. However, providing only a single example demonstration for each translation task improves performance by over 7 BLEU."
"On the more difficult Winogrande dataset, we do find gains to in-context learning: GPT-3 achieves 70.2% in the zero-shot setting, 73.2% in the one-shot setting, and 77.7% in the few-shot setting."
"On LAMBADA, the few-shot capability of language models results in a strong boost to accuracy.GPT-3 achieves 86.4% accuracy in the few-shot setting, an increase of over 18% from the previous state-of-the-art."
"For both Fr-En and De-En, few shot GPT-3 outperforms the best supervised result we could find but due to our unfamiliarity with the literature and the appearance that these are un-competitive benchmarks we do not suspect those results represent true state of the art."
对于法语到英语(Fr-En)和德语到英语(De-En)的翻译任务,在"few-shot"条件下,GPT-3 的表现超过了他们找到的最佳监督学习结果(supervised result)。但是,作者对相关文献(翻译领域的研究)并不太熟悉,同时他们也注意到这些基准测试(benchmarks)似乎并不是当前最具竞争力的。因此,他们不认为 GPT-3 的这些结果是真正的"最先进水平"(state of the art)。
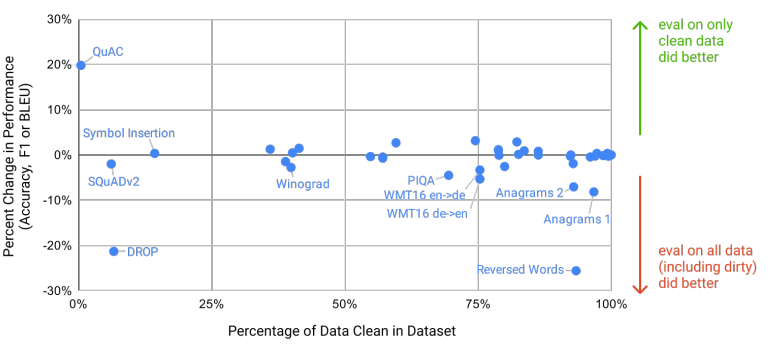
"We develop systematic tools to measure data contamination and quantify its distorting effects. Although we find that data contamination has a minimal effect on GPT-3's performance on most datasets, we do identify a few datasets where it could be inflating results, and we either do not report results on these datasets or we note them with an asterisk, depending on the severity."
"While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples."
"By contrast, humans can generally perform a new language task from only a few examples or from simple instructions -- something which current NLP systems still largely struggle to do."
"Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting."
"At the same time, we also identify some datasets where GPT-3's few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora."
"Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general."
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task.
While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples.
虽然在体系结构中通常与任务无关,但这种方法仍然需要特定于任务的数千或数万个示例的微调数据集。
By contrast, humans can generally perform a new language task from only a few examples or from simple instructions -- something which current NLP systems still largely struggle to do.
Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art finetuning approaches.
Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting.
For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
At the same time, we also identify some datasets where GPT-3's few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora.
Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans.
最后,我们发现GPT-3可以生成新闻文章的样本,人类评估者很难将其与人类撰写的文章区分开来。
We discuss broader societal impacts of this finding and of GPT-3 in general.
我们讨论了这一发现和GPT-3的更广泛的社会影响。
4. 为什么不需要梯度更新或微调⭐
全文翻译摘要有利于更清晰的知道这篇论文干了什么事情;
看了上面的摘要,我有一个问题,那就是:为什么不需要梯度更新或微调
论文当中提到:
'Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting.",
"For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model."
"Recent years have featured a trend towards pre-trained language representations in NLP systems, applied in increasingly flexible and task-agnostic ways for downstream transfer."
"There exists a very wide range of possible useful language tasks, ... it is difficult to collect a large supervised training dataset, especially when the process must be repeated for every new task."
"There is evidence that suggests that the generalization achieved under this paradigm can be poor because the model is overly specific to the training distribution and does not generalize well outside it."
"Humans do not require large supervised datasets to learn most language tasks -- a brief directive in natural language (e.g. "please tell me if this sentence describes something happy or something sad") or at most a tiny number of demonstrations (e.g. "here are two examples of people acting brave; please give a third example of bravery") is often sufficient to enable a human to perform a new task."
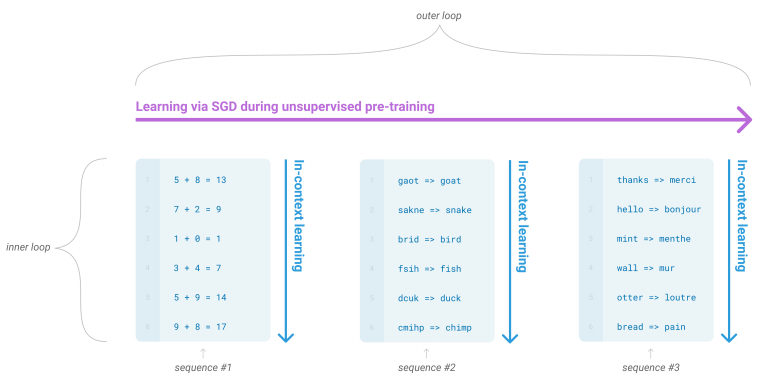
"We use the term "in-context learning" to describe the inner loop of this process, which occurs within the forward-pass upon each sequence. "
模型规模扩展与性能提升 :
随着Transformer模型规模的不断扩展,语言模型的能力显著提高。例如,最早的 100 亿参数模型发展到 G P T − 3 的 亿参数模型发展到GPT-3的 亿参数模型发展到GPT−3的 1750 亿参数,每次模型扩展都显著提高了其在语言生成和下游NLP任务中的表现。作者强调,模型的扩展不仅仅提升了模型的文本生成能力,还改善了其在各种NLP任务中的泛化性能。
论文特别指出:
"Each increase has brought improvements in text synthesis and/or downstream NLP tasks, and there is evidence suggesting that log loss, which correlates well with many downstream tasks, follows a smooth trend of improvement with scale"
"The sequences in this diagram are not intended to be representative of the data a model would see during pre-training, but are intended to show that there are sometimes repeated sub-tasks embedded within a single sequence."
图1.2: "Larger models make increasingly efficient use of in-context information" 这张图展示了大规模模型在少样本学习中的显著提升。作者测试了不同规模模型在简单任务中的in-context学习表现,任务要求模型去掉单词中的随机符号。随着模型规模的增加,模型利用上下文信息完成任务的能力显著增强。该图表明,较大规模的模型在in-context learning任务中表现出更陡峭的学习曲线,这意味着它们能更高效地从上下文中获取信息。
原文解释:
"The steeper "in-context learning curves" for large models demonstrate improved ability to learn a task from contextual information. We see qualitatively similar behavior across a wide range
of tasks."
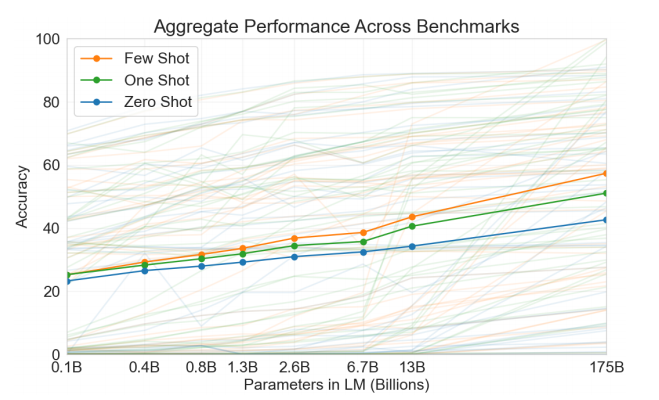
图1.3: "Aggregate performance for all 42 accuracy-denominated benchmarks"
"Our basic pre-training approach, including model, data, and training, is similar to the process described in RWC+19, with relatively straightforward scaling up of the model size, dataset size and diversity, and length of training. Our use of in-context learning is also similar to RWC+19, but in this work we systematically explore different settings for learning within the context."
"Fine-Tuning (FT) has been the most common approach in recent years, and involves updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task. Typically thousands to hundreds of thousands of labeled examples are used. The main advantage of fine-tuning is strong performance on many benchmarks. The main disadvantages are the need for a new large dataset for every task, the potential for poor generalization out-of-distribution MPL19, and the potential to exploit spurious features of the training data GSL+18, NK19, potentially resulting in an unfair comparison with human performance."
"Few-Shot (FS) is the term we will use in this work to refer to the setting where the model is given a few demonstrations of the task at inference time as conditioning RWC+19, but no weight updates are allowed. As shown in Figure 2.1, for a typical dataset an example has a context and a desired completion (for example an English sentence and the French translation), and few-shot works by giving K examples of context and completion, and then one final example of context, with the model expected to provide the completion. We typically set K in the range of 10 to 100 as this is how many examples can fit in the model's context window (nctx = 2048). The main advantages of few-shot are a major reduction in the need for task-specific data and reduced potential to learn an overly narrow distribution from a large but narrow fine-tuning dataset. "
"One-Shot (1S) is the same as few-shot except that only one demonstration is allowed, in addition to a natural language description of the task, as shown in Figure 1. The reason to distinguish one-shot from few-shot and zero-shot (below) is that it most closely matches the way in which some tasks are communicated to humans. For example, when asking humans to generate a dataset on a human worker service (for example Mechanical Turk), it is common to give one demonstration of the task."
"Zero-Shot (0S) is the same as one-shot except that no demonstrations are allowed, and the model is only given a natural language instruction describing the task. This method provides maximum convenience, potential for robustness, and avoidance of spurious correlations (unless they occur very broadly across the large corpus of pre-training data), but is also the most challenging setting."
"To train the larger models without running out of memory, we use a mixture of model parallelism within each matrix multiply and model parallelism across the layers of the network."
"The panels above show four methods for performing a task with a language model -- fine-tuning is the traditional method, whereas zero-, one-, and few-shot, which we study in this work, require the model to perform the task with only forward passes at test time. We typically present the model with a few dozen examples in the few shot setting. Exact phrasings for all task descriptions, examples and prompts can be found in Appendix G."
GPT-3在语言建模任务上的表现尤为出色。通过对Penn Tree Bank (PTB) 数据集的评估,GPT-3打破了之前的最佳记录,达到了新的状态-of-the-art (SOTA)。由于PTB是一个传统的语言建模数据集,它没有明确区分用于单样本或少样本评估的示例,因此此处仅进行了零样本评估。
"We calculate zero-shot perplexity on the Penn Tree Bank (PTB) MKM+94 dataset measured in RWC+19. We omit the 4 Wikipedia-related tasks in that work because they are entirely contained in our training data, and we also omit the one-billion word benchmark due to a high fraction of the dataset being contained in our training set. PTB escapes these issues due to predating the modern internet. Our largest model sets a new SOTA on PTB by a substantial margin of 15 points, achieving a perplexity of 20.50."
我们在RWC+19中测量的Penn Tree Bank (PTB) MKM+94数据集上计算了零射击困惑度。我们在这项工作中省略了4个与维基百科相关的任务,因为它们完全包含在我们的训练数据中,我们也省略了10亿单词的基准测试,因为我们的训练集中包含了很大一部分数据集。由于早于现代互联网,PTB逃避了这些问题。我们最大的模型将PTB上的新SOTA设置为15点,达到20.50的困惑度。
"When presented with examples formatted this way, GPT-3 achieves 86.4% accuracy in the few-shot setting, an increase of over 18% from the previous state-of-the-art."
"GPT-3 achieves 78.1% accuracy in the one-shot setting and 79.3% accuracy in the few-shot setting, outperforming the 75.4% accuracy of a fine-tuned 1.5B parameter language model ZHR+19 but still a fair amount lower than the overall SOTA of 85.6% achieved by the fine-tuned multi-task model ALUM."
StoryCloze
论文如下:
We next evaluate GPT-3 on the StoryCloze 2016 dataset MCH+16, which involves selecting the correct ending sentence for five-sentence long stories. Here GPT-3 achieves 83.2% in the zero-shot setting and 87.7% in the few-shot setting (with K = 70). This is still 4.1% lower than the fine-tuned SOTA using a BERT based model LDL19 but improves over previous zero-shot results by roughly 10%.
"On TriviaQA, we achieve 64.3% in the zero-shot setting, 68.0% in the one-shot setting, and 71.2% in the few-shot setting. The zero-shot result already outperforms the fine-tuned T5-11B by 14.2%, and also outperforms a version with Q&A tailored span prediction during pre-training by 3.8%. The one-shot result improves by 3.7% and matches the SOTA for an open-domain QA system which not only fine-tunes but also makes use of a learned retrieval mechanism over a 15.3B parameter dense vector index of 21M documents LPP+20.GPT-3's few-shot result further improves performance another 3.2% beyond this."
"For both Fr-En and De-En, few shot GPT-3 outperforms the best supervised result we could find but due to our unfamiliarity with the literature and the appearance that these are un-competitive benchmarks we do not suspect those results represent true state of the art. For Ro-En, few shot GPT-3 performs within 0.5 BLEU of the overall SOTA which is achieved by a combination of unsupervised pretraining, supervised finetuning on 608K labeled examples, and backtranslation LHCG19b."
"Scaling is relatively smooth with the gains to few-shot learning increasing with model size, and few-shot GPT-3 175B is competitive with a fine-tuned RoBERTA-large."
QuAC 数据集 : 在 QuAC (Question Answering in Context)数据集上,GPT-3 表现最差,比 ELMo 基线 低了 13 个 F1 分数。这个数据集需要建模结构化对话行为和师生互动的回答选择,这对 GPT-3 来说是个难点。
DROP 数据集 : 在 DROP (Discrete Reasoning Over Paragraphs)数据集中,测试离散推理和阅读理解中的算术推理能力。GPT-3 在 few-shot 设置下,超过了论文中的 微调 BERT 基线,但仍然远远落后于人类表现和一些使用符号系统增强神经网络的最先进方法。
"Since our training dataset is sourced from the internet, it is possible that our model was trained on some of our benchmark test sets. Accurately detecting test contamination from internet-scale datasets is a new area of research without established best practices."
"We then evaluate GPT-3 on these clean benchmarks, and compare to the original score. If the score on the clean subset is similar to the score on the entire dataset, this suggests that contamination, even if present, does not have a significant effect on reported results."
"PIQA: The overlap analysis flagged 29% of examples as contaminated, and observed a 3 percentage point absolute decrease (4% relative decrease) in performance on the clean subset."
"GPT-3 samples still sometimes repeat themselves semantically at the document level, start to lose coherence over sufficiently long passages, contradict themselves, and occasionally contain non-sequitur sentences or paragraphs. "
"Within the domain of discrete language tasks, we have noticed informally that GPT-3 seems to have special difficulty with "common sense physics", despite doing well on some datasets (such as PIQA BZB+19) that test this domain. Specifically GPT-3 has difficulty with questions of the type "If I put cheese into the fridge, will it melt?". "
"GPT-3's in-context learning performance has some notable gaps on our suite of benchmarks, as described in Section 3, and in particular it does little better than chance when evaluated one-shot or even few-shot on some "comparison" tasks, such as determining if two words are used the same way in a sentence, or if one sentence implies another (WIC and ANLI respectively),"
"GPT-3 has several structural and algorithmic limitations, which could account for some of the issues above. We focused on exploring in-context learning behavior in autoregressive language models because it is straightforward to both sample and compute likelihoods with this model class. As a result our experiments do not include any bidirectional architectures or other training objectives such as denoising. This is a noticeable difference from much of the recent literature, which has documented improved fine-tuning performance when using these approaches over standard language models RSR+19."
"Thus our design decision comes at the cost of potentially worse performance on tasks which empirically benefit from bidirectionality. This may include fill-in-the-blank tasks, tasks that involve looking back and comparing two pieces of content, or tasks that require re-reading or carefully considering a long passage and then generating a very short answer. "
"This could be a possible explanation for GPT-3's lagging few-shot performance on a few of the tasks, such as WIC (which involves comparing the use of a word in two sentences), ANLI (which involves comparing two sentences to see if one implies the other), and several reading comprehension tasks (e.g. QuAC and RACE). "
"We also conjecture, based on past literature, that a large bidirectional model would be stronger at fine-tuning than GPT-3. Making a bidirectional model at the scale of GPT-3, and/or trying to make bidirectional models work with few- or zero-shot learning, is a promising direction for future research, and could help achieve the "best of both worlds"."
Our current objective weights every token equally and lacks a notion of what is most important to predict and what is less important.
我们目前的目标是平等地对每个标记进行加权,并且缺乏预测哪些是最重要的,哪些是不重要的概念。
scaling pure self-supervised prediction is likely to hit limits, and augmentation with a different approach is likely to be necessary. Promising future directions in this vein might include learning the objective function from humans ZSW+19a, fine-tuning with reinforcement learning, or adding additional modalities such as images to provide grounding and a better model of the world CLY+19.
"Any socially harmful activity that relies on generating text could be augmented by powerful language models. Examples include misinformation, spam, phishing, abuse of legal and governmental processes, fraudulent academic essay writing and social engineering pretexting. Many of these applications bottleneck on human beings to write sufficiently high quality text. Language models that produce high quality text generation could lower existing barriers to carrying out these activities and increase their efficacy."
"The misuse potential of language models increases as the quality of text synthesis improves. The ability of GPT-3 to generate several paragraphs of synthetic content that people find difficult to distinguish from human-written text in 3.9.4 represents a concerning milestone in this regard."
随着文本合成质量的提高,语言模型的误用可能性也在增加。GPT-3能够生成几个段落的合成内容,人们很难将其与3.9.4中的人工文本区分开来,这是这方面的一个重要里程碑。
幂律可以用一个公式来表示:
y = k ⋅ x − α y = k \cdot x^{-\alpha} y=k⋅x−α
● y 和 x 是两个相关联的变量;
● k 是常数;
● α 是幂律的指数,通常为正数。
幂律关系说明随着某个变量(如模型规模 x x x)增加,另一个变量(如模型的损失值 y y y)会以非线性但可预测的方式变化。
原文引用:
"Several efforts have also systematically studied the effect of scale on language model performance. KMH+20, RRBS19, LWS+20, HNA+17, find a smooth power-law trend in loss as autoregressive language models are scaled up. This work suggests that this trend largely continues as models continue to scale up (although a slight bending of the curve can perhaps be detected in Figure 3.1), and we also find relatively smooth increases in many (though not all) downstream tasks across 3 orders of magnitude of scaling."
"Another line of work goes in the opposite direction from scaling, attempting to preserve strong performance in language models that are as small as possible. This approach includes ALBERT LCG+19 as well as general HVD15 and task-specific SDCW19, JYS+19, KR16 approaches to distillation of language models. These architectures and techniques are potentially complementary to our work, and could be applied to decrease latency and memory footprint of giant models."
"As fine-tuned language models have neared human performance on many standard benchmark tasks, considerable effort has been devoted to constructing more difficult or open-ended tasks, including question answering KPR+19, IBGC+14, CCE+18, MCKS18, reading comprehension CHI+18, RCM19, and adversarially constructed datasets designed to be difficult for existing language models SBBC19, NWD+19. In this work we test our models on many of these datasets."
"We presented a 175 billion parameter language model which shows strong performance on many NLP tasks and benchmarks in the zero-shot, one-shot, and few-shot settings, in some cases nearly matching the performance of state-of-the-art fine-tuned systems, as well as generating high-quality samples and strong qualitative performance at tasks defined on-the-fly."
"Despite many limitations and weaknesses, these results suggest that very large language models may be an important ingredient in the development of adaptable, general language systems."
Tom Brown, Ben Mann, Prafulla Dhariwal, Dario Amodei, Nick Ryder, Daniel M Ziegler 和 Jeffrey Wu 实现了大规模模型、训练基础设施和模型并行策略。这表明,他们负责了 GPT-3 的核心基础设施,确保了如此大规模模型的训练可行。
原文引用 :
"Tom Brown, Ben Mann, Prafulla Dhariwal, Dario Amodei, Nick Ryder, Daniel M Ziegler, and Jeffrey Wu implemented the large-scale models, training infrastructure, and model-parallel strategies."
预训练实验
Tom Brown, Dario Amodei, Ben Mann 和 Nick Ryder 负责了 GPT-3 的预训练实验,他们的工作确保了模型在大规模数据集上的有效训练。
原文引用 :
"Tom Brown, Dario Amodei, Ben Mann, and Nick Ryder conducted pre-training experiments."
数据准备
Ben Mann 和 Alec Radford 负责了 GPT-3 的数据集的收集、过滤和去重工作,并进行了重叠分析,确保训练数据集的质量和多样性。
原文引用 :
"Ben Mann and Alec Radford collected, filtered, deduplicated, and conducted overlap analysis on the training data."
下游任务的实现
Melanie Subbiah, Ben Mann, Dario Amodei, Jared Kaplan, Sam McCandlish, Tom Brown, Tom Henighan 和 Girish Sastry 实现了下游任务和用于支持它们的软件框架,包括创建合成任务。这些下游任务是评估 GPT-3 性能的重要部分,确保了它在各种任务中的表现。
原文引用 :
"Melanie Subbiah, Ben Mann, Dario Amodei, Jared Kaplan, Sam McCandlish, Tom Brown, Tom Henighan, and Girish Sastry implemented the downstream tasks and the software framework for supporting them, including creation of synthetic tasks."
缩放定律与模型规模预测
Jared Kaplan 和 Sam McCandlish 首先预测了超大规模语言模型应该会继续提高性能,并应用缩放定律来预测和指导模型和数据的扩展决策。
原文引用 :
"Jared Kaplan and Sam McCandlish initially predicted that a giant language model should show continued gains, and applied scaling laws to help predict and guide model and data scaling decisions for the research."
"We used the following datasets to train our models: a version of the Common Crawl dataset that was filtered to improve quality, which we refer to as CC, WebText2, Books1, Books2, and Wikipedia."
数据集的使用方式: 这些数据集被混合使用,但并不是按大小的比例进行采样。质量较高的数据集被更频繁地采样,以提高训练效率。例如,Common Crawl 和 Books2 的采样频率较低,而 Wikipedia 则被多次采样。
论文原文描述:
"The datasets are not sampled in proportion to their size, with higher-quality datasets being sampled more frequently, and lower-quality datasets less frequently."
"Since the training data is collected from a wide variety of sources, including publicly available internet corpora, there is some risk of contamination, where the model has seen the test set during training."
2. 《Language Models are Unsupervised Multitask Learners》
"We train on the WebText dataset, which we created by scraping web pages that were linked to from Reddit posts with a score of at least 3. This resulted in a dataset of over 8 million documents."
数据集的使用方式: 模型在 WebText 上进行无监督训练,并在多个任务上评估模型的零样本性能。WebText 是经过严格过滤的数据集,删除了重复内容和像 Wikipedia 这样的来源,以确保数据集的质量。WebText 用于训练,其他数据集则用于测试模型的泛化能力和零样本表现。
论文原文描述:
"We evaluate our model's zero-shot performance on a wide range of datasets, including PTB, WikiText-2, WikiText103, enwik8, and text8."
3. 《Improving Language Understanding by Generative Pre-Training》
"We use the BooksCorpus dataset for training the language model. It contains over 7,000 unique unpublished books from a variety of genres including Adventure, Fantasy, and Romance."
监督微调使用了 SNLI、MultiNLI、RACE、Quora 问题对等数据集。
论文原文描述:
"We fine-tune our model on various supervised datasets such as SNLI, MultiNLI, and RACE to adapt it to specific tasks like natural language inference and question answering."
"Our training procedure consists of two stages. The first stage is learning a high-capacity language model on a large corpus of text. This is followed by a fine-tuning stage, where we adapt the model to a discriminative task with labeled data."
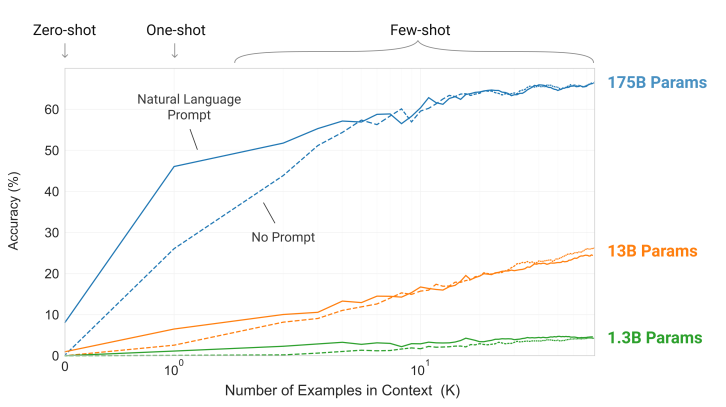 这张图展示了大规模模型在少样本学习中的显著提升。作者测试了不同规模模型在简单任务中的in-context学习表现,任务要求模型去掉单词中的随机符号。随着模型规模的增加,模型利用上下文信息完成任务的能力显著增强。该图表明,较大规模的模型在in-context learning任务中表现出更陡峭的学习曲线,这意味着它们能更高效地从上下文中获取信息。
这张图展示了大规模模型在少样本学习中的显著提升。作者测试了不同规模模型在简单任务中的in-context学习表现,任务要求模型去掉单词中的随机符号。随着模型规模的增加,模型利用上下文信息完成任务的能力显著增强。该图表明,较大规模的模型在in-context learning任务中表现出更陡峭的学习曲线,这意味着它们能更高效地从上下文中获取信息。