文章目录
- 一、寻找入口
-
- [1.1 查看请求](#1.1 查看请求)
- [1.2 搜索参数](#1.2 搜索参数)
- [1.3 分析发起调用](#1.3 分析发起调用)
- [1.4 断点](#1.4 断点)
- [1.5 Hook](#1.5 Hook)
- [1.6 其他](#1.6 其他)
- 二、调试分析
-
- [2.1 格式化](#2.1 格式化)
- [2.2 断点调试](#2.2 断点调试)
- [2.3 反混淆](#2.3 反混淆)
- 三、模拟执行
-
- [3.1 Python 改写和模拟执行](#3.1 Python 改写和模拟执行)
- [3.2 JS 模拟执行 + API](#3.2 JS 模拟执行 + API)
- [3.3 浏览器模拟执行](#3.3 浏览器模拟执行)
- [四、JavaScript 逆向爬取实战](#四、JavaScript 逆向爬取实战)
-
- [4.1 列表页](#4.1 列表页)
- [4.2 详细页](#4.2 详细页)

总的来说,JavaScript 逆向可以分为三大部分:寻找入口,调试分析和模拟执行。
- 寻找入口: 这是非常关键的一步,逆向在大部分情况下就是找一些加密参数到底是怎么来的,比如请求中的 token ,sign 等参数到底在哪里构造的, 这个关键逻辑可能写在某个关键的方法里面或者隐藏在某个关键的变量里面。一个网站加载了很多 JS 文件,那么怎么从这么多 JS 代码里面找到关键的位置,那就是一个关键的问题,这就是寻找入口
- 调试分析: 找到入口后,比如我们可以定位到某个参数可能是在某个方法里面执行了的,那么里面的逻辑究竟是怎样的,里面调用了多少加密算法,经过了多少变量赋值和转换等,这些需要我们先把整体思路整理清楚,以便于我们后面进行模拟调用或者逻辑改写。在这个过程中,我们主要借助于浏览器的调试工具进行断点调试分析,或者借助一些反混淆工具进行代码的反混淆
- 模拟执行: 经过调试分析之后,我们差不多已经搞清楚整个逻辑了,但我们最终目的还是写爬虫,怎么爬取到数据才是根本,因此这里就需要对整个加密过程进行逻辑复写或者模拟执行,以把整个加密流程模拟出来,比如输入一些已知变量,调用之后我们就可以拿到一些 token 内容,再用这个 token 进行数据爬取即可
一、寻找入口
1.1 查看请求
一般来说,我们都是先分析想要的数据到底从哪里来的,数据肯定是某个请求返回的,可以打开浏览器开发者工具,打开 Network 面板,然后点击搜索按钮去搜索;
我们可以看到对应的搜索结果,点击搜索到的结果,我们可以定位到响应结果的位置,找到对应的响应后,就会知道是哪个请求发起的了;
1.2 搜索参数
一般来说,请求带有加密参数,常见有 sign 或者 token;要构造请求首先需要获取加密参数,最简单有效的方法就是通过全局搜索,参数名大多数情况下就是一个普通的字符串,如 token 我们可以通过搜索 token,token:,token :,"token" 等等;
通过一步步分析定位对应的 JavaScript 文件中,通过断点来判断是否正确;
1.3 分析发起调用
上述搜索参数是一种查找入口的方式,这是从源码级别上直接查找,但是当搜索得到的结果过多时,效果自然就会很差,我们可以通过分析发起请求来获取逻辑;
在请求框中有一个 Initiator,在这里可以查看当前请求构造的相关逻辑,这个请求都经过了哪些调用,也就是调用发起方的一步步执行流程,通过单机右侧 @ 内容,可以直接定位到相关位置源码;
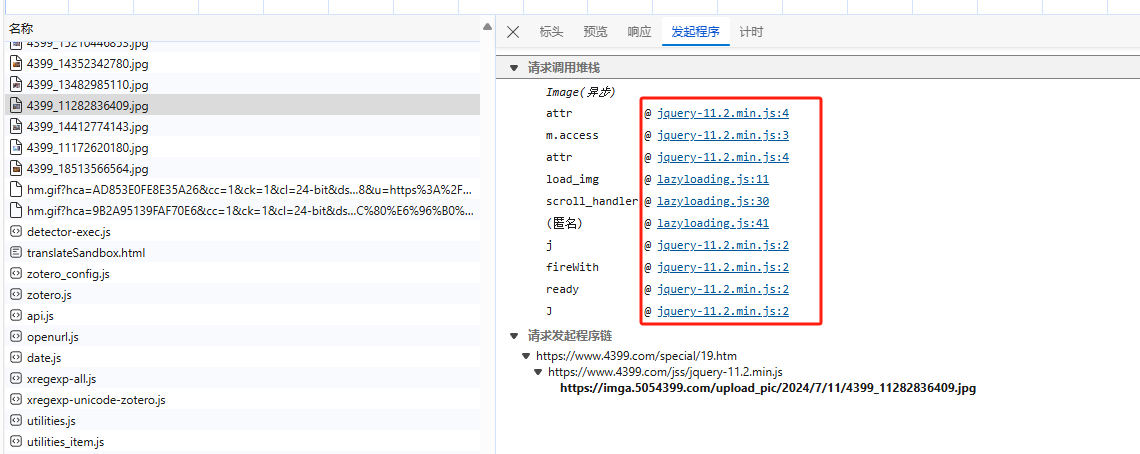
1.4 断点
另外我们还可以通过断点进行入口查找,比如 XHR 断点, DOM 断点,事件断点等。我们可以在开发者工具中的 Sources 面板里面添加设置;
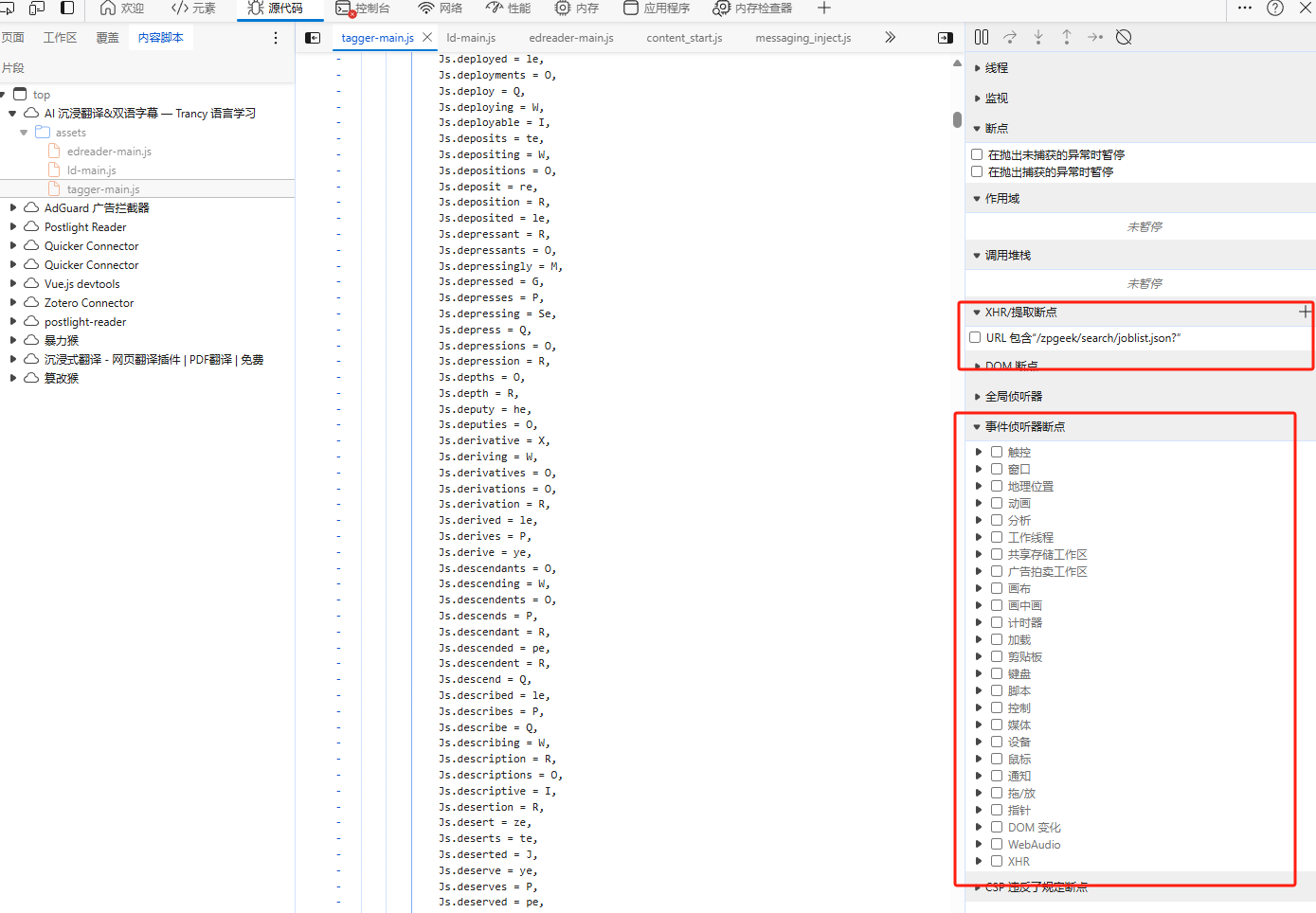
1.5 Hook
Hook 也是一个非常常用的查找入口的功能。有时候,一些代码搜索或者断点并能很有效的找到对应的入口位置,这时候就可以使用 Hook 了,比如说我们可以对一些常用的加密和编码算法,常用的转换操作都进行一些 Hook , 比如说 Base64编码, Cookie 的赋值, JSON 的序列化等;比较方便的 Hook 方式就是通过 TamporMonkey 这个插件实现,使用它我们不仅可以方便的自定义脚本执行时间点,也可以引入一些额外的脚本辅助 Hook 进行代码编写;
1.6 其他
以上便是一些常见的分析入口的方法,当然还有很多其他方法,比如使用 Pyppeteer, PlayWright 里面内置的 API 实现那一些数据拦截和过滤功能, 也可以使用一些抓包软件对一些请求进行拦截和分析,还可以使用一些第三方工具或浏览器来辅助分析
二、调试分析
2.1 格式化
一般来说,许多的 JavaScript 代码都是经过打包和压缩的,多数情况下,我们可以使用 Sources 面板下 JavaScript 窗口左下角的格式化按钮对代码进行格式化;
除此之外,有一些网站的 HTML 和 JavaScript 是混杂在一起的,我们可以使用 JavaScript Beautifier 相关工具,Online JavaScript beautifier ,可以得到格式化后的代码;
2.2 断点调试
代码格式化后,我们就进入了正式的调试流程,基本操作是给想要调试的代码添加断点,同时在对应的面板里观察对应变量的值;
2.3 反混淆
在某些情况下,我们还可能会遇到一些混淆方式,比如控制流扁平化,数组移位等等,对于一些特殊的混淆,可以尝试使用 AST 技术来对代码进行还原
三、模拟执行
经过一系列的调试,现在我们已经可以理清其中的逻辑了, 接下来就是一些调用执行的过程了。
3.1 Python 改写和模拟执行
由于 Python 简单易用,同时也能够模拟调用执行 JS ,如果整体逻辑不复杂的话,我们可以尝试使用 Python 来把整个加密流程完整的实现一遍。如果整体流程相对复杂,我们可以尝试使用 Python 来模拟调用 JS 来执行
3.2 JS 模拟执行 + API
由于整个逻辑是 JS 实现的,使用 Python 来执行 JS难免会有一些不太方便的地方。而 Node.js 天生就有对 JS 的支持。为了更通用的实现 JS 的模拟调用, 我们可以用 express 来模拟调用 JS, 同时将其暴露成一个 API , 从而可以实现跨语言调用
3.3 浏览器模拟执行
由于整个逻辑是运行在浏览器里面的,我们当然也可以将浏览器当做整个执行环境。比如使用 Selenium ,PlayWright 等来尝试执行一些 JS 代码,得到一些返回结果
四、JavaScript 逆向爬取实战
目标网站:Scrape | Movie
目标:获取列表页和详细页信息
4.1 列表页
列表页请求构造中有三个参数,只有 token 需要获取;
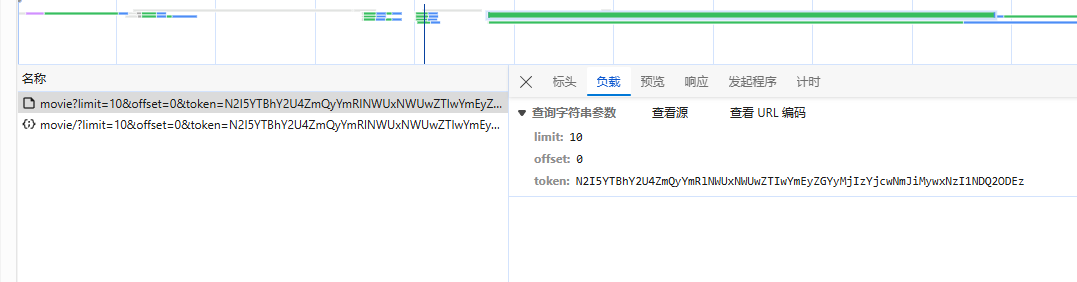
通过请求的发起程序 Initiator 可以观察得到在调用栈的 onFetchData 中获得的
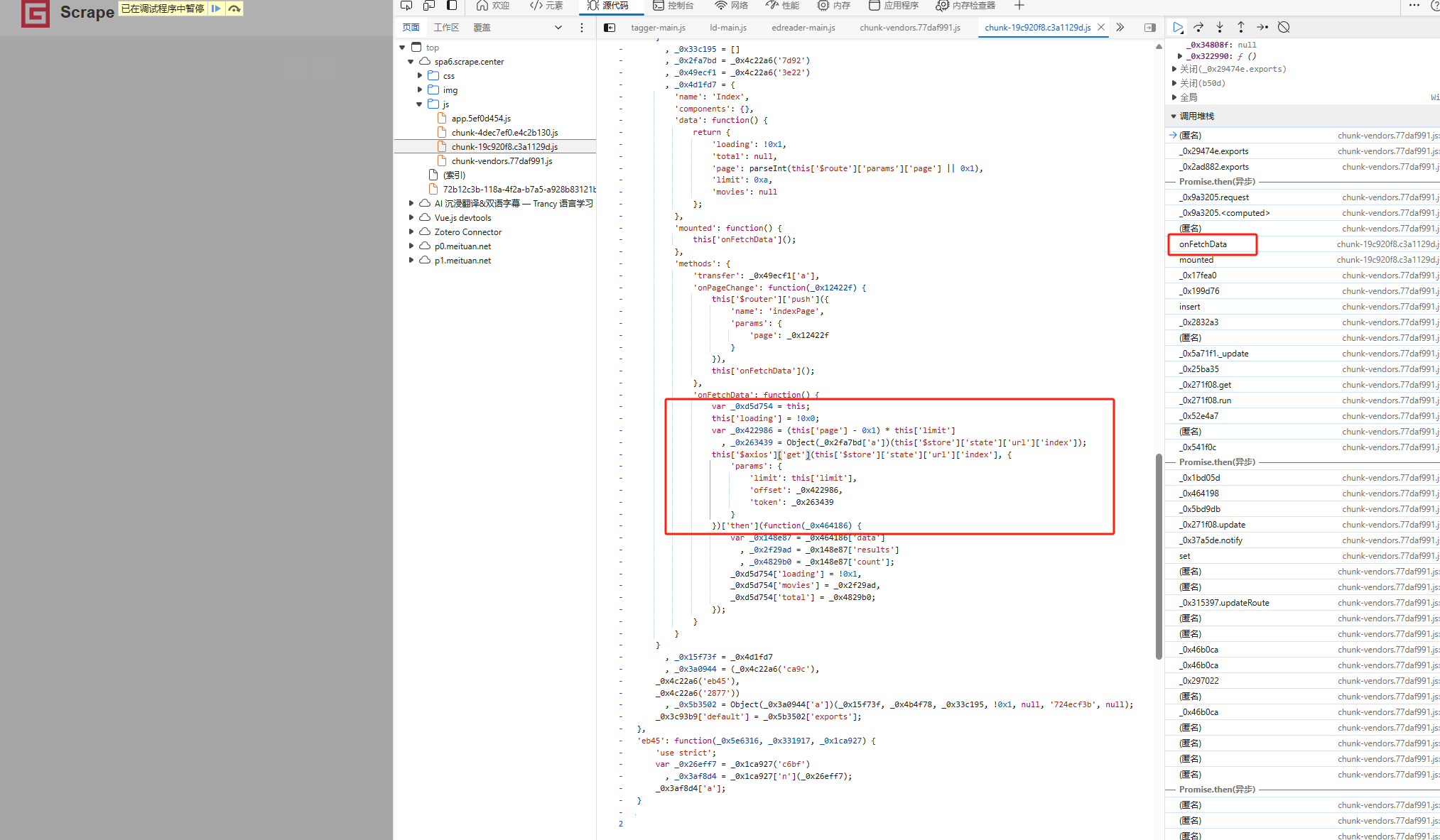
通过分析断点分析,关键代码如图所示
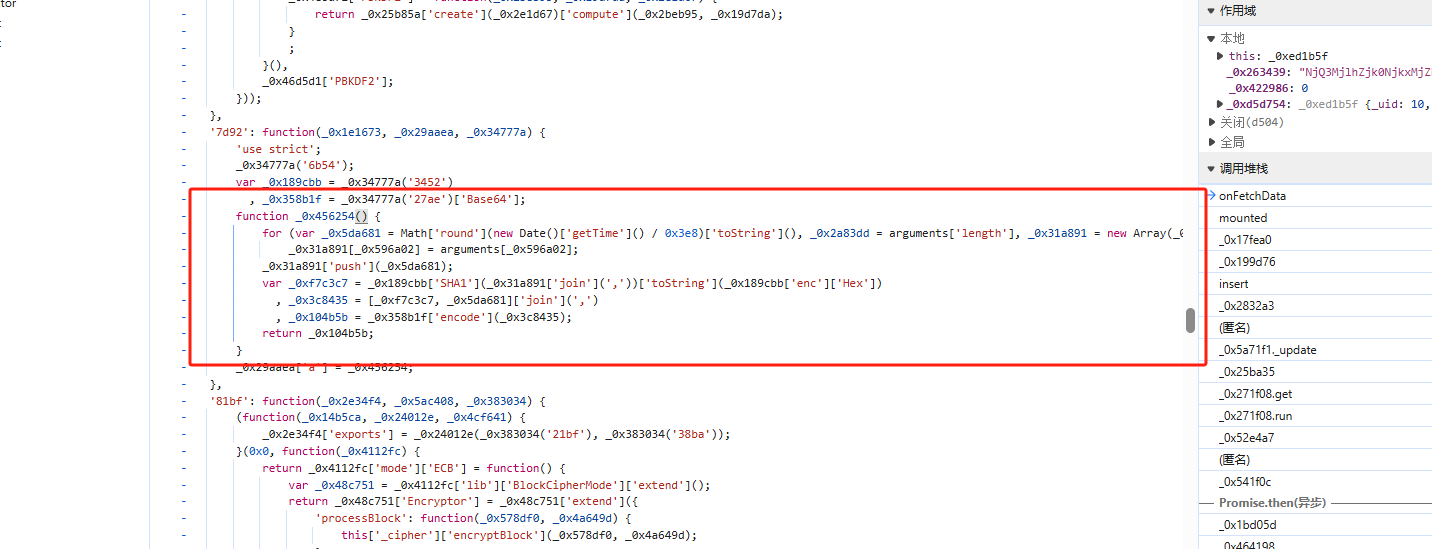
获取列表页代码如下所示
python
import hashlib
import time
import requests
import base64
def get_token():
timestamp = str(int(time.time()))
str1 = f'/api/movie,{timestamp}'.encode('utf-8')
str2 = (hashlib.sha1(str1).hexdigest() + f',{timestamp}').encode('utf-8')
final = base64.b64encode(str2).decode('utf-8')
return final
def get_page(offset):
url = f"https://spa6.scrape.center/api/movie/?limit=10&offset={offset}&token={get_token()}"
resp = requests.get(url)
return resp.json()
if __name__ == '__main__':
resp = get_page(10)
print(resp)4.2 详细页
详细页有两个加密,一个是 url加密,一个是 token 加密;在这里我们先解决 url 加密
在这里详细页进行了 url 加密,通过查看页面源码,可以看到在没有点击之前,详细页链接的 href 里面就带有加密后的 url 了,因此这个加密请求是在 Ajax 请求完成之后生成了,而且可以肯定的是由 JavaScript 生成的;
在这里可以通过勾选 Sources 面板中 事件侦听器断点中的 XHR 中的 readystatechange 来获取 Ajax 得到响应时的事件,删除其他断点,刷新页面;
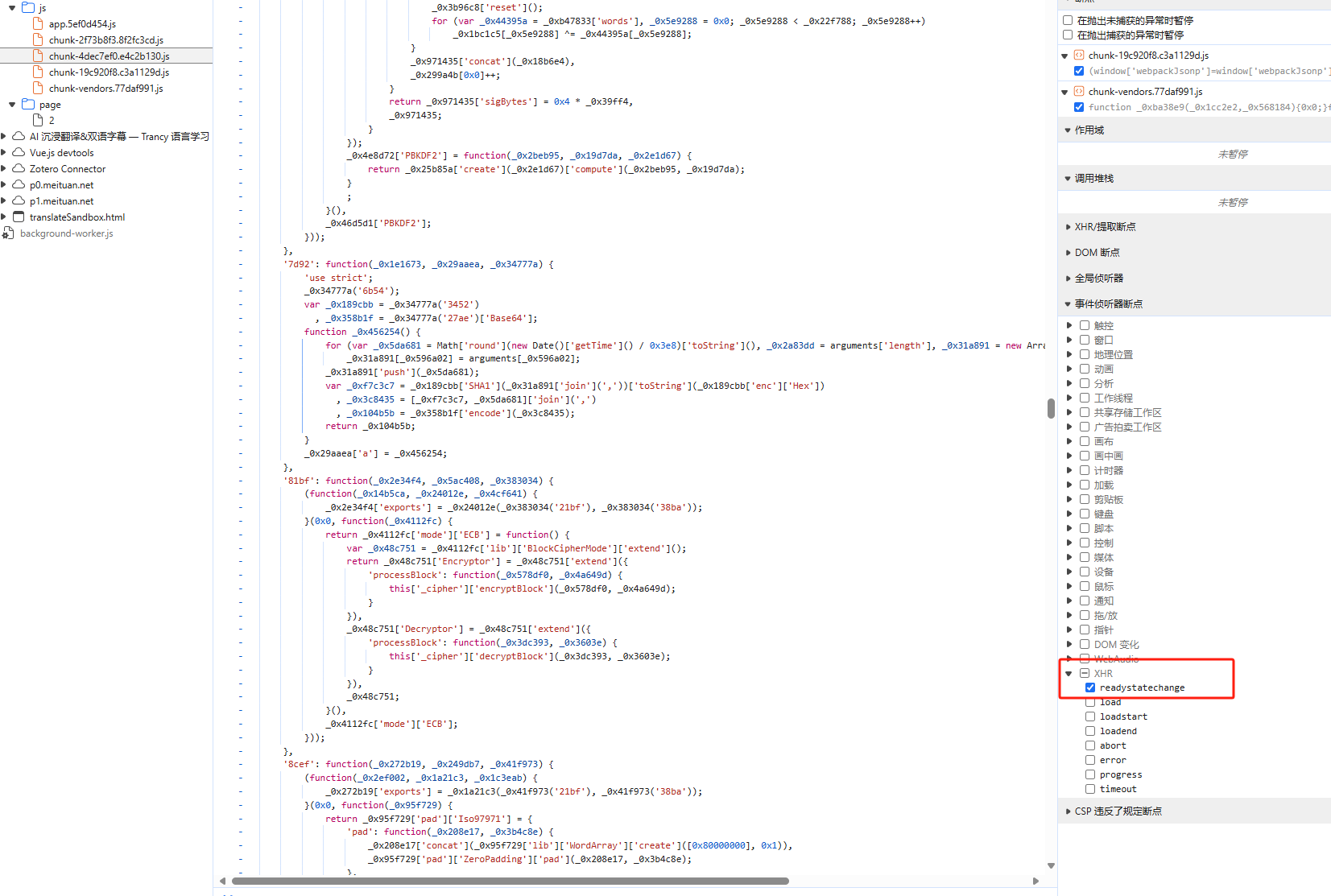
通过一步步调试,进而发现请求的构造,但是这样会非常非常繁琐,我们可以通过发现规律的方式来快速找到目标代码;
通过观察加密后的 url ,可以发现加密部分结尾基本都有 =,可以推测采用 Base64 进行编码,而使用 Base64 编码基本会使用到 window.btoa 方法,所以我们可以使用 Hook 的方式定位代码;
js
// ==UserScript==
// @name HookBase64
// @namespace asdsadasd
// @version 2024-08-15
// @description try to take over the world!
// @author zhouyi
// @match https://spa6.scrape.center/
// @grant none
// ==/UserScript==
(function() {
'use strict';
// Your code here...
function hook(object, attr){
var func = object[attr];
object[attr] = function(){
console.log('hooked', object, attr);
var ret = func.apply(object, arguments);
debugger;
return ret;
}
}
hook(window, 'btoa')
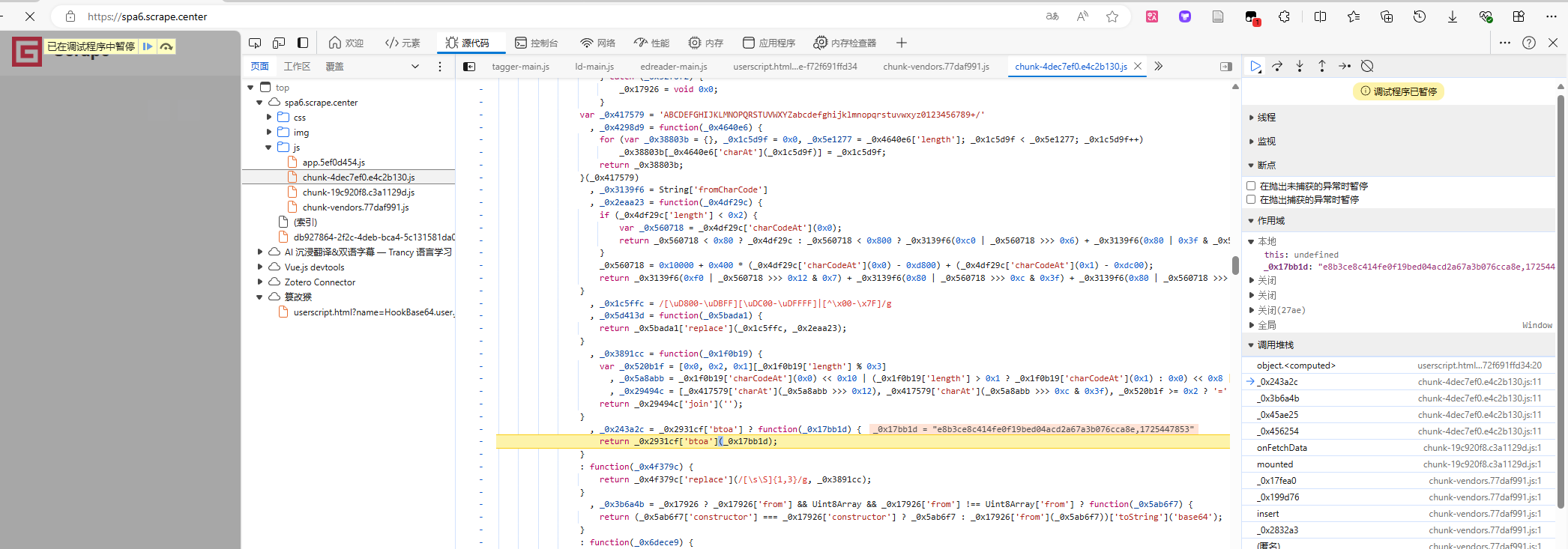
})();Hook后,刷新页面,可以发现定点,通过观察作用域的值可以发现,第一个并不是目标的加密 url
点击暂停键回复脚本执行,可以发现第二个是目标加密 url,而加密的核心代码如下
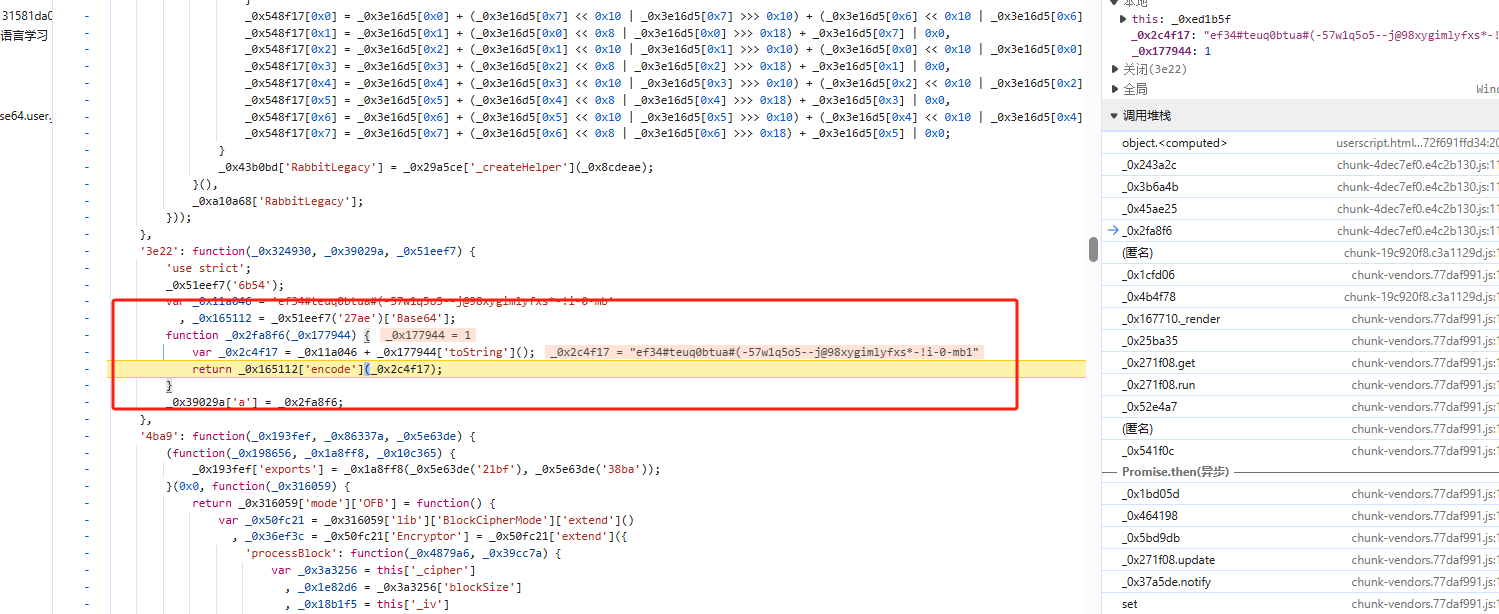
其通过一个固定字符串搭配 1,2,3 等序号的方式构造一个字符串,然后利用字符串去 Base64 编码获取最后的字符串;固定代码为 ef34#teuq0btua#(-57w1q5o5--j@98xygimlyfxs*-!i-0-mb,序号在列表页获取到的 json 数据之中;
第二个便是 token 的构造,观察发现,除了 /api/movie 被替换成 /api/movie/{加密后的url部分} 外,其他并无变化;
python
import hashlib
import time
import requests
import base64
def get_token(encrypt_url):
timestamp = str(int(time.time()))
str1 = f'/api/movie/{encrypt_url},{timestamp}'.encode('utf-8')
str2 = (hashlib.sha1(str1).hexdigest() + f',{timestamp}').encode('utf-8')
final = base64.b64encode(str2).decode('utf-8')
return final
def get_url(id):
encrypt_url = ('ef34#teuq0btua#(-57w1q5o5--j@98xygimlyfxs*-!i-0-mb' + str(id)).encode('utf-8')
encrypt_url = base64.b64encode(encrypt_url).decode('utf-8')
url = f"https://spa6.scrape.center/api/movie/{encrypt_url}/?token={get_token(encrypt_url)}"
resp = requests.get(url)
return resp
if __name__ == '__main__':
resp = get_url(1)
print(resp.json())