代码随想录训练营 Day53打卡 图论part04
一、卡码110. 字符串接龙
本题与力扣127题是一样的,所以这里使用力扣127题。
字典 wordList 中从单词 beginWord 到 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
每一对相邻的单词只差一个字母。
对于 1 <= i <= k 时,每个 si 都在 wordList 中。注意, beginWord 不需要在 wordList 中。
sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
示例 :
输入 :beginWord = "hit", endWord = "cog", wordList = "hot","dot","dog","lot","log","cog"
输出 :5
解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
从这个图中可以看出 abc 到 def的路线 不止一条,但最短的一条路径上是4个节点。
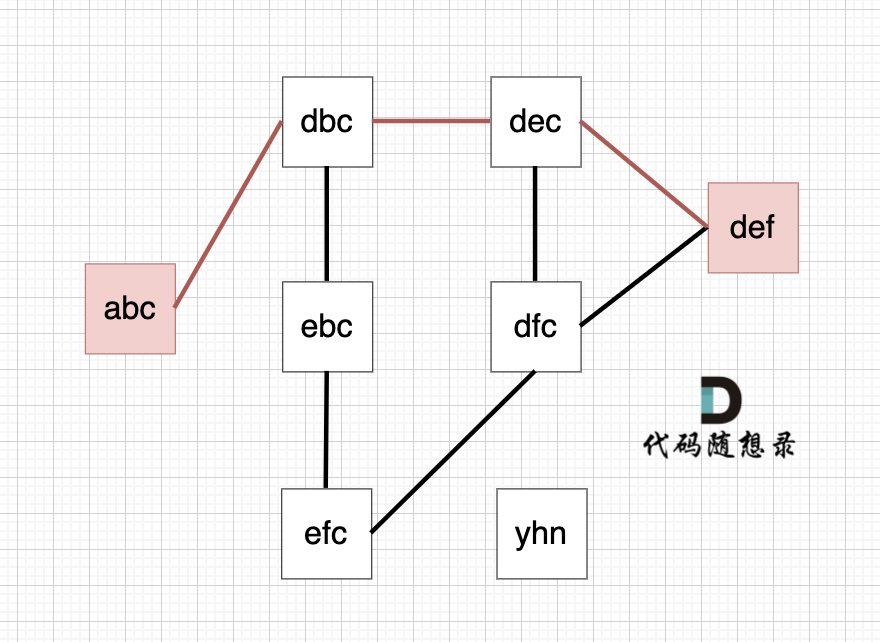
1. 建立映射和标号:
- 目的:为了方便表示单词及其关系,我们需要为每个单词分配一个唯一的 ID。
- 操作:将 beginWord 和 wordList 中的所有单词都加入到一个映射中,称为wordId。通过哈希表的方式,将每个单词映射到它的 ID。
- 无解检查:如果 endWord 不在这个映射中,则直接返回无解,因为没有路径可以到达目标。
2. 优化建图:
-
朴素思路的不足:如果直接枚举每一对单词并判断它们是否仅差一个字符,这种方法在处理较大规模的单词表时效率太低,时间复杂度为 O(N² * L),其中 N 是单词数,L 是单词长度。
-
虚拟节点优化:
-- 核心思想:引入虚拟节点来减少建图的复杂度。
-- 虚拟节点的创建:对于每个单词 word,我们用通配符 * 替换单词的每个字符。例如,单词 hit 对应的虚拟节点是 * it、h * t、hi *。
-- 连接规则:每个单词都会向它对应的虚拟节点连接,即该单词和虚拟节点之间互相连通。如果两个单词通过某个虚拟节点连接,那么它们必然可以通过一次字符替换相互转换。
3. 广度优先搜索 (BFS):
-
BFS的意义:在图中寻找从 beginWord 到 endWord 的最短路径。
-
队列初始化:将起始单词加入 BFS 队列,开始广度优先搜索。
-
终止条件:一旦我们搜索到终点 endWord,则说明我们找到了最短路径。
4. 距离的调整:
-
双倍距离:由于我们引入了虚拟节点,因此路径的长度会比实际的多一倍。每次经过一个虚拟节点到另一个单词节点,会增加 2 个单位的距离。
-
最终结果:我们实际的最短路径长度应为距离的一半,再加 1(因为起点要计入路径中)。
总结:
- 通过虚拟节点的引入,我们将原先 O(N²) 的判断复杂度降低到了 O(N * L),因为每个单词的虚拟节点数量为
L,即单词的长度,这样在遍历的时候仅需要处理相邻的虚拟节点。 - 广度优先搜索保证我们找到的路径是最短的。
- 返回值需要经过调整来反映真实的最短路径长度。
代码实现
python
class Solution:
def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
# 辅助函数,用于为一个单词添加唯一ID
def addWord(word: str):
if word not in wordId: # 如果单词还没有记录
nonlocal nodeNum # 使用nonlocal表示要修改外部作用域中的变量
wordId[word] = nodeNum # 将单词与其ID关联
nodeNum += 1 # 每添加一个新单词,增加ID的数量
# 辅助函数,用于建立单词之间的连接
# 将每个单词的一个字符替换为通配符 "*",然后将该通配符单词与原单词连接
def addEdge(word: str):
addWord(word) # 先为这个单词添加一个唯一ID
id1 = wordId[word] # 获取该单词的ID
chars = list(word) # 将单词转换为字符数组
for i in range(len(chars)): # 遍历单词中的每个字符
tmp = chars[i] # 记录原字符
chars[i] = "*" # 替换该字符为通配符 "*"
newWord = "".join(chars) # 形成新的"通配符"单词
addWord(newWord) # 给这个通配符单词添加唯一ID
id2 = wordId[newWord] # 获取通配符单词的ID
edge[id1].append(id2) # 将原单词的ID和通配符单词的ID连接起来
edge[id2].append(id1) # 反向连接,保证是无向图
chars[i] = tmp # 恢复原来的字符
wordId = dict() # 创建一个字典,用于存储每个单词及其唯一ID
edge = collections.defaultdict(list) # 创建邻接表,存储每个单词的邻居
nodeNum = 0 # 用于给每个单词分配唯一的节点编号
# 为字典中的每个单词建立图中的边
for word in wordList:
addEdge(word)
addEdge(beginWord) # 为起始单词添加边
if endWord not in wordId: # 如果目标单词不在字典中,无法转换
return 0
# 初始化最短距离数组,初始值为无穷大
dis = [float("inf")] * nodeNum
beginId, endId = wordId[beginWord], wordId[endWord] # 获取起点和终点单词的ID
dis[beginId] = 0 # 起点单词的距离初始化为0
# BFS队列,初始化时将起始单词的ID加入队列
que = collections.deque([beginId])
while que:
x = que.popleft() # 从队列中取出当前处理的单词ID
if x == endId: # 如果当前单词ID就是目标单词的ID,说明找到了最短路径
return dis[endId] // 2 + 1 # 返回实际的步数(每次步进都是2个节点,所以除以2加1)
for it in edge[x]: # 遍历当前单词的所有邻接单词
if dis[it] == float("inf"): # 如果该单词还未被访问过
dis[it] = dis[x] + 1 # 更新到该单词的最短距离
que.append(it) # 将该单词加入队列,继续BFS
return 0 # 如果没有找到转换路径,返回0二、卡码105. 有向图的完全可达性
题目描述
给定一个有向图,包含 N 个节点,节点编号分别为 1,2,...,N。现从 1 号节点开始,如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
输入描述第一行包含两个正整数,表示节点数量 N 和边的数量 K。 后续 K 行,每行两个正整数 s 和 t,表示从 s 节点有一条边单向连接到 t 节点。
输出描述如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
输入示例4 4
1 2
2 1
1 3
2 4
输出示例1
提示信息
从 1 号节点可以到达任意节点,输出 1。
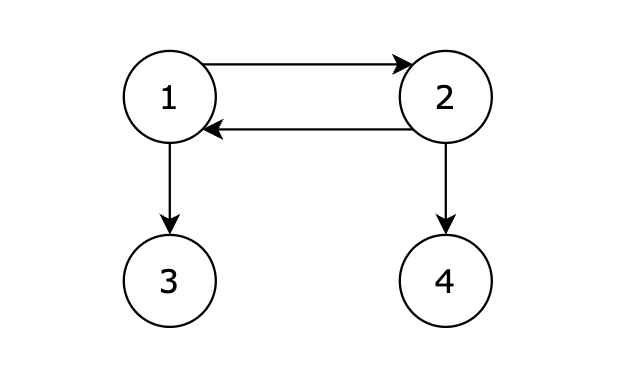
本题是一个有向图搜索全路径的问题。为了判断是否可以从 1 号节点到达图中的所有节点,可以使用深度优先搜索(DFS)。我们只需从节点 1 开始,通过 DFS 遍历所有可以到达的节点,最后检查是否所有节点都被访问过。如果所有节点都被访问过,输出 1;否则,输出 -1。
- 图的构建: 我们使用邻接表来表示图,其中 graphi 表示从节点 i 出发可以到达的所有节点列表。
- DFS 遍历: 定义了一个递归的 dfs 函数,从 1 号节点开始,递归遍历所有可以到达的节点,并标记它们为已访问。
- 检查是否能访问所有节点:在 DFS 结束后,检查 visited 数组是否所有节点(从 1 到 N)都被标记为 True,如果是,表示可以到达所有节点,返回 1,否则返回 -1。
- 时间复杂度:由于我们遍历了所有节点和所有边,时间复杂度为 O(N + K),即节点数和边数的总和。
代码实现
python
def can_reach_all_nodes(N, edges):
# 构建图的邻接表表示
graph = [[] for _ in range(N + 1)] # 使用邻接表存储有向图
for s, t in edges:
graph[s].append(t) # 从节点 s 到节点 t 的有向边
# 标记每个节点是否被访问过
visited = [False] * (N + 1)
def dfs(node):
# 深度优先搜索函数
visited[node] = True # 标记当前节点已访问
for neighbor in graph[node]:
if not visited[neighbor]: # 如果相邻节点未访问,继续递归
dfs(neighbor)
# 从节点 1 开始 DFS
dfs(1)
# 检查是否所有节点都被访问过(忽略 0 号节点)
if all(visited[1:]):
return 1 # 如果所有节点都能访问,返回 1
else:
return -1 # 否则返回 -1
# 输入读取
N, K = map(int, input().split()) # 读取节点数量 N 和边的数量 K
edges = [tuple(map(int, input().split())) for _ in range(K)] # 读取 K 条边
# 输出结果
print(can_reach_all_nodes(N, edges))三、卡码106. 岛屿的周长
题目描述
给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿是被水包围,并且通过水平方向或垂直方向上相邻的陆地连接而成的。
你可以假设矩阵外均被水包围。在矩阵中恰好拥有一个岛屿,假设组成岛屿的陆地边长都为 1,请计算岛屿的周长。岛屿内部没有水域。
输入描述第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述输出一个整数,表示岛屿的周长。
输入示例5 5
0 0 0 0 0
0 1 0 1 0
0 1 1 1 0
0 1 1 1 0
0 0 0 0 0
输出示例14
提示信息
岛屿的周长为 14。
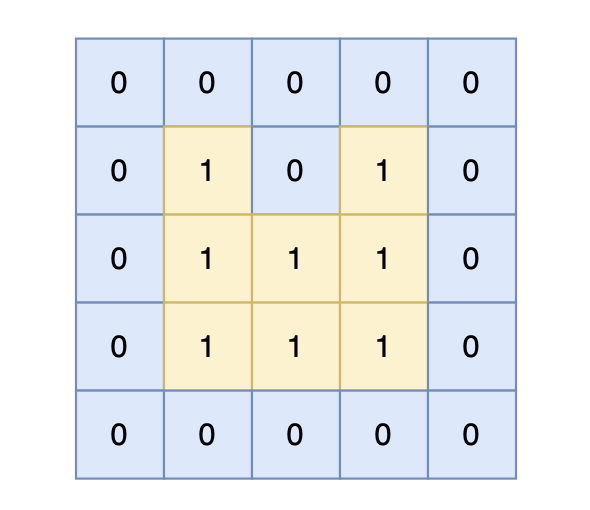
基本思路是遍历每个陆地格子并检查它的四个方向,判断该方向是否为边界或水域。如果是,则将该边计入周长贡献。
- dx 和 dy:这两个列表用于表示四个方向的偏移量,分别是右、下、左、上。dx 表示行的变化,dy 表示列的变化。
- n 和 m:分别是网格的行数和列数。
- 双重循环遍历:遍历网格的每一个格子,检查是否为陆地格子(值为 1)。
- 四个方向检查:对于每一个陆地格子,检查它的上下左右四个方向是否越界或是水域(值为 0)。如果是,则该方向会为周长贡献 1。
- 周长计算:每当找到一条边是边界或水域,就将 cnt 增加 1,最后将 cnt 加到总的周长 ans 中。
代码实现
python
class Solution:
# 定义四个方向,分别为右、下、左、上
dx = [0, 1, 0, -1]
dy = [1, 0, -1, 0]
def islandPerimeter(self, grid: list[list[int]]) -> int:
n, m = len(grid), len(grid[0]) # 获取网格的行数和列数
ans = 0 # 用于记录周长
# 遍历每个格子
for i in range(n):
for j in range(m):
if grid[i][j] == 1: # 如果是陆地
cnt = 0
# 检查四个方向
for k in range(4):
tx = i + self.dx[k]
ty = j + self.dy[k]
# 如果该方向越界或者是水域
if tx < 0 or tx >= n or ty < 0 or ty >= m or grid[tx][ty] == 0:
cnt += 1
ans += cnt # 将该格子的周长贡献加入总周长
return ans