前言
这里介绍一篇笔者在去年ACL上发表的一篇文章,使用了空间语义约束来提高多模态分类的效果,类似的思路笔者也在视频描述等方向进行了尝试,也都取得了不错的效果。这种建模时对特征进行有意义的划分和约束对模型还是很有帮助的,在这里主要分享一下这个思路。
本文选择的方向是多模态情感检测,是一个标准的多模态分类场景。有已有方法主要关注特征融合,忽视了模态异质性带来的挑战。模态异质性可能导致以下问题:1)引入冗余视觉特征;2)特征转移;3)数据标注不一致,增加情感理解的难度。由于第三点和这个任务强相关,不具备通用性,故省略。
为了解决这些问题,我们设计了一个带有稀疏注意力的文本引导融合模块,减少冗余视觉特征的影响。其次,我们通过情感一致性约束任务校准特征转移。大量实验表明我们得改进有效并取得最佳结果。
论文:https://aclanthology.org/2023.acl-long.287.pdf
代码(直接邮箱就行,一直没顾上整理):https://github.com/airsYuan/Tackling-Modality-Heterogeneity
1. 引言
多模态情感检测旨在从文本、图像等多模态内容中探索情感(见下图)。随着社交媒体的快速发展,这项技术在理解个体、人物或主题的情感方面应用广泛,吸引了学术界和工业界的关注。本文聚焦于在社交媒体中检测多模态帖子的情感。

现有研究主要集中在模态融合,但忽视了模态异质性带来的问题。模态异质性主要由模态差距引起,可能导致冗余视觉特征、特征转移和标注不一致等问题,增加了情感理解的难度。
为了系统解决这些问题,我们提出了多视角校准网络(MVCN),从三个不同视角出发:1)文本引导融合模块减少冗余视觉特征;2)情感一致性约束任务校准特征转移;3)自适应损失校准策略处理不一致的标注标签。
2. 方法
MVCN的架构如下图所示,主要包括文本引导融合模块和两个并行子任务:情感分类和基于情感一致性约束。
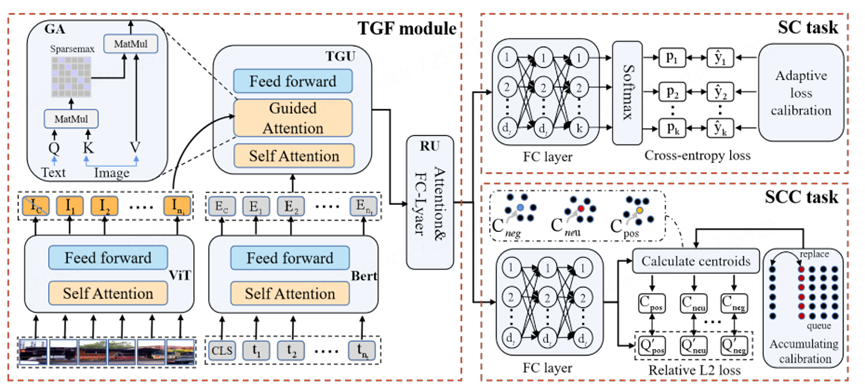
2.1 文本引导融合模块
该模块由单模态编码器、文本引导单元和归约单元组成。我们使用预训练的BERT模型作为文本编码器,ViT模型作为图像编码器。文本引导单元通过稀疏注意力机制消除冗余视觉特征,捕获与情感相关的图像关键部分。
具体来说,文本引导融合模块包含以下组件:
-
单模态编码器:使用BERT模型提取文本特征,使用ViT模型提取图像特征。
-
文本引导单元(TGU):通过自注意力生成文本感知特征,再通过稀疏注意力获取文本引导的视觉稀疏特征,最后应用前馈神经网络处理这些特征。这里用了两个注意力机制:
-
利用文本特征来关注视觉特征,从而获取由文本引导的视觉特征。
-
采用sparsemax进行注意力权重的归一化,以获得稀疏的后验注意力权重,使得冗余的视觉特征权
归约单元(RU):通过堆叠注意力层和全连接层对多模态特征进行降维,得到情感分类的多模态表示。
2.2 情感一致性约束(SCC)
SCC任务通过聚集多模态特征来校准特征转移。我们提出相对L2损失来度量距离,避免数据分布完全消除。此外,累积校准策略扩大计算空间,减少样本变化,确保训练稳定性。
具体步骤包括:
-
估计情感中心:利用标签信息计算正面、中性和负面情感中心。
-
采用相对L2优化距离:我们设计了相对距离来优化SCC任务,将语义一致的数据彼此拉近。注意,这里不能直接用L2损失,不然会让模型失去泛化性,导致效果非常差。
-
累积校准策略:为了进一步优化SCC任务,我们提出了一种累积校准策略。Batch更新的局限性在于计算中心点会频繁更新,而Batch的样本数量(N=16)不足以估计准确的中心点导致训练非常不稳定。为了解决这个问题,我们使用一个辅助的表征模块来提前生成足够的表示(N=3600+)作为估计中心点的候选样本。然后通过一个队列来存储所有的特征表示。该队列在训练过程中也会动态更新,通过用当前Batch替换队列中最早的一个Batch来实现速度较慢的中心点更新,这样训练起来非常稳定。
实验
在本节中,我们将介绍实验设置和结果,并进行消融研究和可视化分析。实验在三个公共数据集上进行:MVSA-Single、MVSA-Multiple和HFM。
3.1 基线模型
为了充分验证MVCN的性能,我们选择了单模态和多模态基线模型。
-
单模态基线:对于文本模态,我们选择CNN、Bi-LSTM和BERT作为基线模型。对于图像模态,选择了ResNet和ViT。
-
多模态基线:对于MVSA数据集,比较的基线模型包括MultiSentiNet、HSAN、Co-MN-Hop6、MGNNS和CLMLF。对于HFM数据集,我们比较了Concat的两个变体、MMSD以及D&R Net。
3.4 主要结果
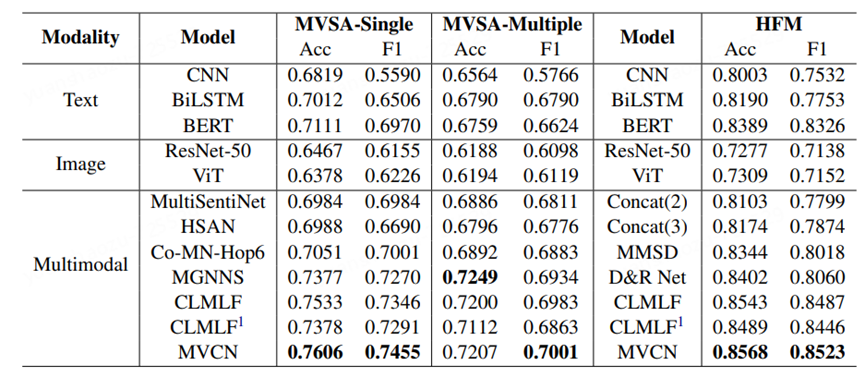
实验结果如上表所示。多模态模型由于融合了更多信息,超越了单模态模型。总体而言,MVCN比其他方法有显著的性能提升,这表明了从不同角度解决模态异质性的必要性。特别地,我们发现MVCN在MVSA-Single数据集上的表现优于其他两个数据集,可能是由于数据多样性不足,小数据集更容易受到模态异质性问题的影响。
3.5 消融研究
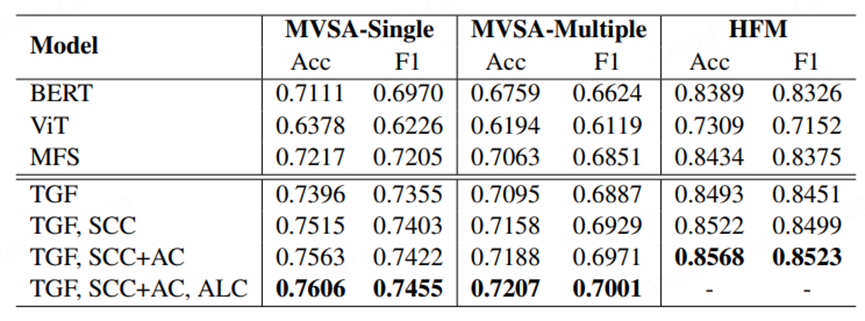
为了研究每个模块的有效性,我们在上表中进行了消融研究。首先,与均等融合图像和文本特征的MFS模型相比,TGF模块显著提升了情感检测性能。情感一致性约束(SCC)模型显著提升了整体效果,验证了这一方法的重要性。通过将SCC与更准确稳定的质心相结合的累积校准(AC)策略,性能进一步得到了持续提升。然而,需要注意的是,SCC的优化不能使用绝对距离,否则效果会大幅下降,这一点在论文中已有讨论。
分析
4.1 可视化
稀疏注意力可视化

为了验证TGF模块中Sparse-Attention的优势,我们进行了注意力热图的可视化分析。结果显示,Sparse-Attention能够捕捉与情感相关的图像关键部分,同时减弱冗余视觉特征的负面影响。例如,图(a)中,模型更加关注图像中的"生病的狗",因为它反映了负面情感。这证明了模型可以聚焦于图像中的情感区域,避免无关对象的干扰,进一步强调了消除冗余视觉特征的必要性。
特征分布可视化
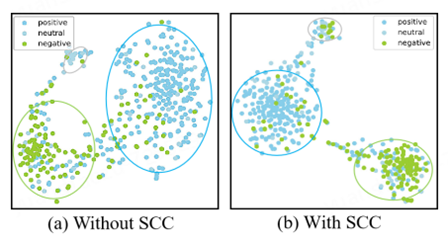
为了直观展示具有AC策略的SCC任务的优越性,我们在MVSA-Single数据集上进行了特征分布的可视化分析。通过T-SNE2算法对特征进行降维,我们得到了二维特征向量的分布图(上图)。从图(b)可以看出,SCC任务使同一类别的样本聚集在其对应的质心周围。而图(a)显示,当移除SCC任务时,数据聚集程度明显下降。这表明,SCC任务通过考虑情感标签,从更全局的角度约束分布,更好地校准特征偏移,从而提升了模型性能。
结论
在本文中,我们通过采用特征约束方法显著提升了多模态分类的性能。在笔者的探索过程中,这一思路不仅在多模态分类任务中表现出色,还具有广泛的应用潜力。这类方法可以同样适用于其他需要强特征表示的任务,从而增强模型的效果,为这类任务的性能优化提供了一个可能的思路。